
融合机载LiDAR 和植被指数的自适应单木提取方法
2023-12-19 13:14王宏涛白伟森
光学精密工程 2023年22期
代 震, 何 荣, 王宏涛, 白伟森
(河南理工大学 测绘与国土信息工程学院,河南 焦作 454000)
1 引言
树高、植被范围等是极为重要的植被信息数据,常常被应用于森林反演、生物量估计等方面[1]。然而传统获取植被信息的方法多是通过测高仪等进行野外测量,耗费人力物力且无法应对大面积森林区域。随着无人机(Unmanned Aerial Vehicle,UAV)载荷能力的增加,搭载可见光相机,可获取高精度影像,包含物体的纹理、光谱和物体间拓扑关系等二维表层信息,准确识别地物类型[2-4];搭载激光雷达系统(Light Detection And Ranging,LiDAR)能够穿透植被冠层获取植被冠层表面和林下地形,从而快速获取植被树高胸径等深层信息[5-7]。
无人机影像数据可生成精细的数字正射影像(Digital Orthophoto Model,DOM),利用可见光植被指数对DOM 进行分割,获取精确的植被范围[8-9]。其中,汪小钦等[10]依据归一化植被指数原理构建可见光波段差异植被指数,结果表明该指数提取精度可达90%以上;周涛等[11]针对绿色植被比重较大的城市区域,提出了一种差异增强植被指数(Differential Enhanced Vegetation Index,DEVI),加强了绿色植被绿波段反射率同时大于红、蓝波段的特性;Shen 等[12]结合多光谱数据与RGB 影像,估算森林结构属性,但由于植被作物混杂,很难区分光谱相近的目标地物。
树高的获取主要通过构建冠层高度模型(Canopy Height Model,CHM),模型的精确性尤为重要。虽然无人机影像数据可生成包含各类地物的空间位置和高度特征的密集点云,但杨勇强等[13]通过无人机影像数据展现了不同郁闭度下的天山云杉单木分割效果,其在高郁闭度的林区精度欠佳。而Yang 等[14]通过无人机LiDAR数据提取植被冠层高度模型,能够轻松获取准确的空间信息,即使是在密集林区,也能穿透枝叶获取部分的林下地形,生成的冠层高度模型误差更小。张海清等[15]通过LiDAR 点云提取准确冠层模型,分析不同坡度下CHM 的畸变程度,结合数字表面模型校正冠层高度,确定了精细CHM的必要性。
然而,可见光影像对植被信息的提取存在局限性,只能提供植被表面的光谱纹理信息,难以区分相同地形条件下的垂直植被结构,且光谱信号存在饱和现象[16];生成的CHM 具有精确空间结构,却容易受到贴合地面的低矮植被影响,降低最终提取植被信息的精度。针对上面问题,李佳等[17]结合无人机影像中的颜色与高程信息,将公园绿地植被进一步细分,能克服植被提取局限但精度相对不足;肖冬娜等[18]分别融合不同植被指数与CHM,对人工种植的火龙果树进行单木分割,聚焦于每株植被的冠幅轮廓,排除树下低矮植被的干扰。基于此类思想,本文结合两种数据来源的优势,将CHM 与可见光植被指数进行融合,构建具有颜色信息和空间结构的CHM+DEVI 图像,并通过分类回归树算法(Classification and Regression Tree,CART)[19]对植被垂直结构自适应细分,针对乔木区域进行单木分割。
分水岭算法是单木分割最常见的算法,Meyer 等[20]在1990年首次提出了基于标记的分水岭算法(Mark-Controlled Watered Segmentation,MCWS),避免了噪声对影像的过分割;马学条等[21]通过形态学开闭重建来清除图像中的噪声点,修正不合理值,进一步削弱过分割现象。MCWS 缺点是图像分割效果与标记选取密切相关,因此精确的标记选取尤为重要,徐伟萌等[22]利用高斯滤波平滑影像,通过自适应阈值分割算法提取区别于种子点的块状区域,获得更为准确的标记范围,提高了算法精度;Xu 等[23]修正局部最大值算法,以此获取更为合理的提取标记,最终提高个体树冠检测精度。
以上述的融合图像对单木分割方法进行改进,利用形态学重建算法修正融合图像,构建训练样本,采用CART 算法分离出乔木、灌木和草地,在乔木区域采用局部最大值算法进行标记[24],通过提高标记选取区域的准确性,达到提高分水岭算法精度的目的。确定四个样方区域,对比4 种单木分割算法的分割精度,将提取的植被信息与实测数据进行精度验证,证明算法能够在剥离混杂植被影响的前提下进一步提取单木,获得较为准确的植被信息。
2 原理与方法
仅仅通过LiDAR 点云或植被指数获取的植被信息都有其局限性,在植被混杂区域存在较大的精度误差,难以运用到实际生活中。本文结合两种数据的独特优势,构建一种包含颜色信息和空间结构的融合数据,并以此提取植被,方法及流程如图1 所示。
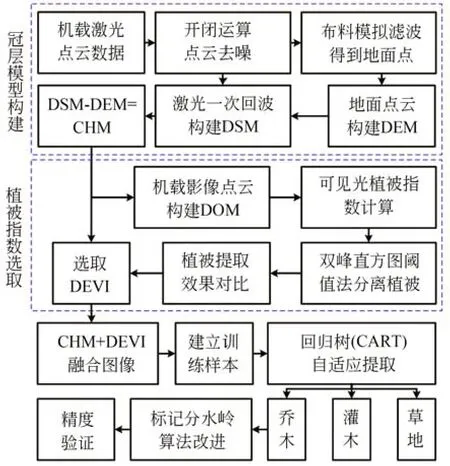
图1 总体流程图Fig.1 Overall flow chart
首先以机载激光点云通过布料模拟滤波算法得到地面点云,采用不规则三角网生成数字高程模型(Digital Elevation Model,DEM),结合激光一次回波生成的数字表面模型(Digital Surface Model,DSM)构建包含空间信息的CHM,以无人机影像数据得到高精度的DOM,计算可见光植被指数,在比较不同植被指数精度后选择差异增强算法计算包含颜色信息的DEVI 指数。然后融合CHM 和DEVI,生成同时具有空间结构和颜色信息的CHM+DEVI 图像,以此对标记控制分水岭算法进行改进。融合图像后进行形态学重建,去除小的突刺和融合的不平滑区域;建立相应的训练样本,通过分类回归树算法,分割地面范围并自适应提取植被为乔木、灌木和草地,对乔木区域采用局部最大值算法探测树顶点,作为前景标记,非乔木区域赋为后景标记,标记图像进行分水岭变换得到分割结果。为验证植被信息的估算精度,将该方法提取的树木棵树、树高与实测数据分别进行精度分析。
2.1 可见光植被指数选取
植被指数是指对遥感图像的两个及两个以上的光学波段进行组合运算,放大不同地物类别之间的差异性,从而达到有效区分地物的作用。在已有植被指数中,大多数是利用可见光与近红外范围的波段进行组合运算,主要包括干旱或碳衰减指数、窄带绿度指数、宽带绿度指数、冠层氮指数、光利用率指数、冠层含水量指数与叶绿素指数等七大类。其中可见光植被指数,是利用健康绿色植被的光谱反射特性呈现绿波段反射率同时大于红、蓝波段反射率这一特点,处理更容易获取的RGB 影像。但是仅基于可见光波段构造的植被指数相对较少,各自的适用范围也不同,部分可见光植被指数的计算公式如表1 所示。

表1 可见光植被指数Tab.1 Visible vegetation index
通过无人机影像数据得到的高清数字正射影像,包含准确的RGB 三色波段,根据表1 可见光植被指数公式在ENVI 中进行计算,得到各指数结果,如图2(a)~图2(d)。同时采用人机交互的方式,将影像逐像元分成植被与非植被区域,植被区域像元个数为327 728,非植被区域像元个数为67 200,由于各可见光植被指数都无法分辨山火灼烧后的植被范围,整体提取精度都受到影响,提取的植被区域的精度评价如表2 所示。以相应的植被指数构建直方图,采用双峰法确定准确的阈值,分割图像得到植被和非植被区域,如图2(e)~图2(h)。根据表2,MGRVI 的统计直方图不属于双峰直方图,无法用双峰直方图法确定阈值;图2 圈中的区域,RGRI、NGRDI 较大范围出现过度分割现象,VDVI 较小区域出现欠分割现象。分析发现,对比另两种指数,DEVI 和VDVI 能形成良好的直方图双峰图像,获得的分割阈值更为准确;另一方面,实验数据的采集时间是夏季,绿色植被较多,而DEVI 可显著增强绿色植被绿波段反射率同时大于红、蓝波段反射率这一特性,比VDVI 具有更强的针对性,因此选用DEVI 进行后续实验,该指数植被提取效果最好,且双峰直方图阈值的范围更容易确定,保持在0.9 到1 之间。

表3 标记分水岭算法单木分割精度评价Tab.3 Accuracy evaluation of single tree segmentation in MCWS algorithm

图2 可见光植被指数选取图Fig.2 Selection of visible light vegetation index
2.2 CHM+DEVI 图像融合
数据预处理时,机载激光数据和影像数据来自于不同的无人机系统,初始设置难以统一。解决方法是将无人机影像进行空三处理,生成大量密集点云,与激光点云通过迭代最近点算法(Iterative Closest Point,ICP )进行配准,在三维空间上进行旋转、平移,得到两者误差最小的配准结果。点云是后续一系列数字产品的基础,匹配好点云数据的空间地理坐标,能够降低精度误差,保证生成的CHM 和DEVI 图像空间三维坐标、分辨率一致。
融合思路:矢量化经可见光植被指数计算RGB 影像得到的提取结果,进行形态学重建处理去除不合理值,在matlab 中将其与激光点云数据经CHM 分割得到的矢量数据进行交集融合处理,得到完全融合后的CHM+DEVI 图像。
融合效果对比如图3 所示,在高清影像中通过人机交互划分出准确的草地和乔木范围,并在DEVI 指数、CHM 和融合图像中叠加显示。可以明显看到,林区植被的垂直分层现象中,DEVI 植被指数提取结果无法分辨出乔木层、灌木层和草地的区别,三者是同一灰度显示(图3(f)),而其中裸地与植被的辨别区分十分容易,可以精准的分离植被和地面范围(图3(b));CHM 中包含空间信息,起伏的地形坡度变化容易与草地高程产生混淆,如图3(c)虚线标识范围,部分草地会误判成地面,降低该区域的植被提取精度,而其准确的林下高程信息可以有效分离垂直植被结构(图3(g));两种来源数据在一定程度上是互补的,融合的CHM+DEVI 图像明显增加草地区域(图3(d)),提高地面分割精度,同时能够区分出区域植被乔木层、灌木层和草地(图3(h)),精准描绘部分单木冠幅轮廓,显示出来的结果更加贴合真实林区地貌。

图3 融合效果对比图Fig.3 Comparison of fusion effects
2.3 分类回归树自适应提取
对融合后的图像进行处理,构建训练样本集,采用分类回归树进行计算,在不同的实验区,所构建的决策树模型会有不同的自适应变化,以更贴合对应林区的地形地物条件。CART 算法由Breiman 于1984年提出,是采用二分循环分割的方法,递归地构建二叉决策树的过程。算法针对分支属性的度量指标是Gini 系数,根据Gini 系数对未分类的训练样本集进行二分分割,每次分割后形成一个节点和两个分支,不断迭代循环,直至当前待分类的样本集被判定为叶节点或满足停止分裂的条件,最后生成一个简洁明了的决策树模型。
设S为大小为m、分类属性为n的样本集,用来定义n个不同分类Ci(i=1,2,…,n),则Gini 系数的计算公式为:
针对样本集S,选取属性H作为分支条件,将样本集S分裂为条件H的子样本集S1,与其余样本组成的样本集S2,条件Gini 系数为:
Gini 增益系数表示在一个条件下,信息不确定性减少的程度,以增益系数最大的属性作为决策树根节点属性,公式为:
2.4 标记分水岭算法改进
直接使用分水岭算法易出现过度分割现象,尤其是经过融合后的CHM+DEVI 图像,叠加两种图像后的噪声数量较大。因此需要采用图像去噪算法,实验发现,普通算法大多仅仅能滤除一些噪声,针对融合后产生的不合理值效果欠佳。本文采用形态学开闭重建运算处理数据,去除噪声并修正区域极大值与极小值,其中基于重建的开操作能够去除小的突刺和树冠间的牵连,重建的闭操作能够填补小的像素空洞。
大小为1 的标记图像P关于模板图像G的测地膨胀和测地腐蚀定义为:
大小为n的标记图像P关于模板图像G的测地膨胀和测地腐蚀的定义为:
来自标记图像P对模板图像G的膨胀形态学重建表示为,腐蚀形态学重建表示为,大小确定的初始图像经过测地膨胀和测地腐蚀后,会在k次迭代后收敛并趋于稳定。公式为:
形态学开闭重建运算主要以原始图像作为模板图像,对原始图像进行腐蚀或膨胀操作,以处理后的图像作为标记图像,最后利用标记图像与模板图像进行重建。开运算重建为先腐蚀后膨胀,闭运算重建为先膨胀后腐蚀,表达式如式(7)所示:
其中,m为结构单元B对图像P的迭代次数。
分水岭算法通过识别图像灰度的细微变化来进行单木分割。主要原理是颠倒各像元的灰度值,图像中的每个像素值都对应地形中的海拔高度,使局部最大值变为局部最小值,以浸没模拟思想从最小值开始注水,随着水位上升,形成的相邻盆地会接壤,在临界处构建坝体,即单木轮廓。标记控制分水岭法将分水岭中自动探测的局部极小值变换为固定值,再进行分水岭变换,去除伪树冠点,减少过度分割,从而更准确地分割单木。
以CHM+DEVI 融合图像对标记控制分水岭分割算法进行改进,改进算法流程如图4。图像实现融合后先进行形态学重建,即基于重建的形态学开闭运算,去除图像噪声并修正不合理值;然后采用分类回归树算法,以包含颜色和高程信息的融合图像构建训练样本集,分割地面范围,自适应提取植被为乔木、灌木和草地;最后在乔木区域采用局部最大值算法探测树顶点,作为前景标记,非植被区域圈为后景标记,以标记图像进行分水岭变换。算法主要通过matlab 实现,标记图像设为unit8 位图像,前景标记赋值为255,后景标记赋为0,然后执行分水岭变换。
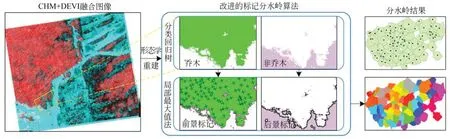
图4 标记分水岭算法改进流程Fig.4 Improvement process of marking watershed algorithm
3 实验与分析
3.1 数据预处理
3.1.1 机载LiDAR 数据和影像数据
试验区位于河南省洛阳市新安县云梦山附近,选取自然树林和人工种植林交叉的区域,采用六旋翼无人机搭载RIEGL VUX-1 激光扫描系统于2022年7 月20 日采集激光点云数据。无人机航高200 m,航带旁向重叠率为70%。同时采用四旋翼无人机搭载高清数码相机采集相同区域的遥感影像,倾斜摄影作业模式,航高150 m,航向重叠度、旁向重叠度均为80%,获取RGB 影像259 张。对初始数据处理得到实验区域的两种点云数据,LiDAR 点云密度为112/m2,影像点云密度为276/m2,如图5 所示。

图5 初始数据生成点云Fig.5 Initial data generation point cloud
两种点云数据经过ICP 算法进行配准后,LiDAR 点云通过布料模拟滤波算法得到研究区地面点云,采用不规则三角网算法构建DEM,激光一次回波只采集物体表面信息,以此构建DSM,两者相减得到冠层高度模型;以影像点云生成高清DOM,根据RGB 信息计算可见光植被指数,得到DEVI 影像。数据预处理中,生成的模型精度均为25 cm,较低的空间分辨率会造成标记分水岭算法过分割,较高也会产生欠分割现象[29]。
3.1.2 地面实测数据
地面实测数据与机载数据同步开展,树高由手持勃鲁莱测高器测量。利用GPS 测量样地单木位置,并人工标记。根据植被水平和垂直分布条件选取4 块样方区域,其中三块位于自然林区,一块位于人工种植区域,采用激光即时定位与制图(Simultaneous Localization and Mapping,SLAM)扫描仪采集样方实际地貌,并按高程显示,如图6 所示。
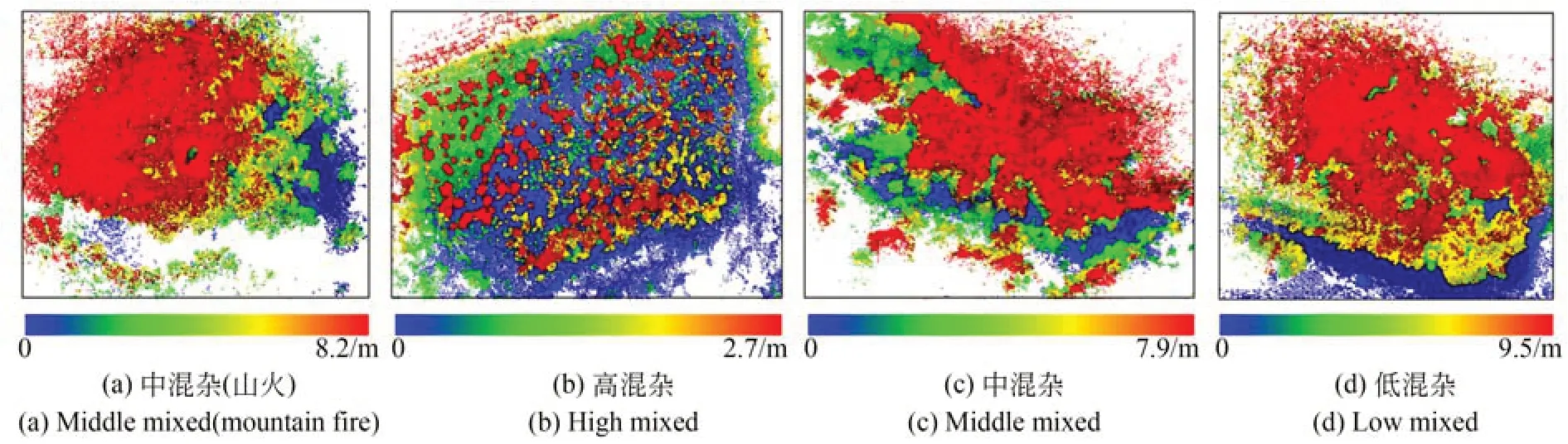
图6 SLAM 高程显示植被层次Fig.6 SLAM elevation displays vegetation hierarchy
样方1 共有野生树木89 棵,主要为栎树,区域内有山火侵蚀的痕迹,中心与边界的冠幅差距较大,植被混杂程度为中等,平均树高约为7.9 m;样方2 共有小型树木153 棵,人工种植痕迹明显,植被主要为梨子树和女贞树,平均树高约为2.2 m,区域内植被混杂程度高;样方3 共有树木73 棵,包含大部分的栎树和少量的山楂,树木间隙低矮植被多有分布,混杂程度为中等,平均树高约为7.6 m;样方4 靠近山体,主要树种为栎树,共有树木162 棵,只有道路边界分布少量灌木和草地,混杂程度低,平均树高约为8.5 m。
3.2 基于训练样本的自适应提取结果
分类回归树是典型的监督分类算法,样本的选择要具有代表性和典型性,在研究区内构建训练样本的好坏程度,直接影响地物分类的最终优劣。研究区位于山脚林区附近,只存在个别低矮建筑物,少部分水域为人工鱼塘,这两种地物不参与分类。区域内地表植被类型复杂多样,地面的样本来自林间小路和部分林中裸地,裸岩石砾地为山丘、山脉等;草地在道路旁、森林边缘和内部空地均有分布;灌木包括多种植被类型,种类复杂难以分辨,但分布广泛;乔木以区域栎树、山楂树等为主,分布于密闭林区。通过对上述地物分布情况进行解译,将研究区分为乔木、灌木、草地和地面4 类地物类型,在此分类体系下,本文对CHM+DEVI 融合图像进行处理,用人机交互的方法选择63 个样本区域作为训练对象,所选样本均匀分布在研究区内,并且代表每一类别的象征区域。
通过训练样本,自适应提取的细分结果如图7(c),不同地物类别用不同颜色进行标识(彩图见期刊电子版),在水平方向上,乔木多分布于密闭林区,草地在道路两侧和森林边缘生长茂盛;分析垂直结构,显示出草地范围包裹灌木层再到乔木层的由低到高植被结构,乔木的冠幅轮廓清晰可见,整体结果符合研究区地形生长条件。同时,试验区紧邻样方1的树林,如图7中虚线所示,存在大面积山火灼烧的痕迹,(a)中可见光植被指数在该区域只提取中心区域的部分植被,无人机影像中火焰灼烧后的土地颜色呈现黑灰色,黑色区域降低了可见光波段的反射率,是植被指数分割失误的根本原因;而融合图像具有CHM 的空间信息,在可见光植被指数大面积失误的同时,仍可以有效分离出植被和地面范围,更进一步表示出乔木和灌木层。

图7 植被细分结果与影响因素Fig.7 Vegetation subdivision results and influencing factors
3.3 植被提取与精度验证
自适应提取出研究区乔木、灌木、草地和地面后,根据乔木区域约束标记分水岭算法,得到最终的植被提取信息。将得到的单木分割信息与高清RGB 图像进行叠加显示,如图8 所示,分别代表研究区4 个样方的单木分割结果,可以明显看出分割效果。

图8 单木分割叠加效果Fig.8 Single tree segmentation overlay effect
图8(a)中准确显示出林间空地,同时靠近道路边界的乔木较为稀疏,山火灼烧较大影响了乔木的冠幅轮廓,缺失的水分使植被生长的枝叶较少;图8(b)中人工种植林间隔较大,大量灌木植被,乔木层与灌木层混杂,单木提取效果比较好,能准确提取出各植被;图8(c)中植被情况与图8(a)相似,但植被生长更加茂盛,树木间隙存在部分低矮植被,自适应提取出乔木区域并对乔木区域分割,明显提高了分割效果;图8(d)中乔木郁闭度较高,树木间隙较少,垂直结构不明显,分割效果也较差,对应本文改进方法的局限性。
将4 个样方植被的棵数与实测数据进行精度评价,具体以查全率R、查准率P、总体准确度F1得分指标评价单木分割精度[30-31],计算公式如下:
其中:TP为正确检测果树棵数;FN为未检测到果树棵数;FP为错误检测果树棵数。
原算法和改进算法的单木分割精度评价结果如表2~表4 所示,样方1、样方2、样方3 和样方4 查全率R分别提高了3.3%,4.6%,4.2% 和1.3%,查准率P分别提高3.5%,6.3%,4.3%和1.8%,准确度F1 分别提高3.4%,5.5%,4.2%和1.6%,总体查全率R提高3.2%,查准率P提高3.9%,F1 得分提高3.5%。分析发现,单木分割准确度的提高程度与样本区域树木混杂程度有关联,样方1 与样方3 相似的树木混杂程度对应接近的F1 提高效果,样方1 中的山火影响并未直接干扰到树木的生长棵树变化。其中,样方2区域主要为人工植被,树木间距较大,产生误判的可能性小,在排除其他混杂植被的干扰后有了更好的单木提取效果;而样方4 的精度提高程度最差,原因是该区域的植被较为茂密且混杂程度低,在相同条件下更难以分割,错分现象也难以改善,改进算法在郁闭单一林区的提高效果不明显。

表4 改进算法单木分割精度评价Tab.4 Accuracy evaluation of single tree segmentation based on improved algorithm
为了更客观、清楚地评判改进算法的优劣性,对本文算法的分割结果与已测试过的其他3种单木分割算法的精度进行比较分析,包括MCWS 算法、点云距离聚类算法和深度学习算法,如图9。分析发现,在4 个样方中,分割精度高低为深度学习算法=改进算法>MCWS 算法>点云距离聚类算法,改进算法与深度学习算法分割精度总体相似,而深度学习受限于训练样本,需要手动选取大量具有代表性的乔木样本,当样方区域干扰因素过多,比如在植被混杂程度高的样方2,深度学习算法的精度就略低于改进算法;同样,在植被混杂度低的样方4 区域,单一树种便于深度学习训练分割,精度就优于改进算法。

图9 多种单木分割算法对比Fig.9 Comparison of multiple single tree segmentation algorithms
最后以实测值树高H与提取值h进行植被信息精度分析,分别计算各研究区实测值与提取值平均高程精度验证结果ΔH[15]:
植被信息提取精度对比分析结果如图10 所示,通过对标记分水岭算法进行改进,在样方1、样方2、样方3 和样方4 中的提取树高精度分别提高了1.7%,6.4%,1.8% 和0.3%。分析发现,改进算法与标记分水岭算法的精度提高效果与各样方乔木层、灌木层及草地混杂程度相关联,样方1 与样方3 乔木、灌木混杂程度相似对应接近的提取效果。其中,样方2 植被垂直分布不均匀,人工种植植被高度较低,更容易受到其他层植被的干扰,因此改进后的提取效果更为明显;样方4 植被郁闭度较大,乔木、灌木及草地的混杂程度最低,改进的效果有限。
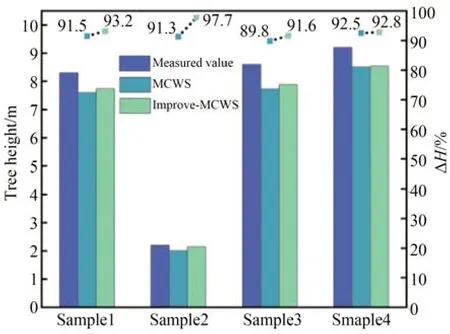
图10 植被提取结果对比精度评价Fig.10 Comparison accuracy evaluation of vegetation extraction results
4 结 论
本文结合LiDAR 点云和可见光植被指数,新构建一种具有颜色信息和空间结构的CHM+DEVI 融合图像,自适应提取研究区的植被垂直结构,并以乔木区域对标记分水岭算法进行改进,研究结果表明:
(1)以融合图像构建训练样本,采用分类回归树算法自适应分割出乔木、灌木、草地和地面。借助可见光植被指数区分草地和地面范围,通过LiDAR 点云三维空间信息分离植被垂直结构,同时改善可见光植被指数在山火区域的局限,有效分离出植被和地面范围,更进一步表示出山火区域乔木和灌木分布。
(2)改进标记分水岭算法的提取精度高于原算法。形态学重建修复融合图像,去除噪声和不合理值;在乔木区域约束标记范围,提高了单木提取的精度;对比4 种单木分割算法在4 个样方中的分割精度,并结合实测数据验证改进算法单木分割效果,总体查全率R提高3.2%,查准率P提高3.9%,F1 得分提高3.5%,平均提取树高提高2.55%,研究区植被混杂程度越高改进算法的提取效果越好。
相比于单独数据的片面植被信息,本方法可以有效综合激光和可见光不同来源数据的优势,获取更广泛、更深层的林地植被信息,对提升林业资源调查的准确性有重要意义。
猜你喜欢
农业工程学报(2022年14期)2022-10-19
林业勘查设计(2022年1期)2022-02-15
地理空间信息(2021年10期)2021-11-14
乡村科技(2021年17期)2021-10-20
安顺学院学报(2021年4期)2021-09-16
林业调查规划(2020年3期)2020-06-03
农业机械学报(2019年6期)2019-06-27
遥感信息(2019年1期)2019-03-22
水土保持研究(2018年5期)2018-10-12
中国农业信息(2018年2期)2018-07-28
