
基于特征标签的电力计量大数据深度挖掘研究
2023-12-18 05:54:08王奕萱李翼铭徐二强李会君李明亮
电子设计工程 2023年24期
王奕萱,李翼铭,徐二强,李会君,李明亮
(1.国网河南省电力公司营销服务中心(计量中心),河南郑州 450052;2.国网河南省电力公司,河南郑州 450052;3.河南九域腾龙信息工程有限公司,河南郑州 450052)
电力系统所存储的数据量巨大,而对于大量数据分析处理的常用方式便是数据挖掘,其应用领域非常广泛,如火电厂优化、配电网故障识别、水电厂运转等,因此数据挖掘在电力计量领域的应用频率逐渐提升。尤其随着电力公司存储数据量的不断增加,对于数据挖掘的要求也越来越高,因此对于电力计量数据挖掘的研究受到相关领域研究人员的广泛关注。
文献[1]提出了基于蚁群算法的非结构化大数据深度挖掘方法,利用蚁群参数实现信息挖掘,但此方式运用到电力计量中适用性差。文献[2]提出了基于EPR 的智慧电厂大数据深度挖掘方法,通过机理算法和EPR,结合专家数据库以及可视化等手段对燃煤火电厂的大数据进行深度挖掘,但此方式只在燃煤火电厂中适用,应用范围受限。
结合上述分析,该文提出了基于特征标签的电力计量大数据深度挖掘方法。
1 电力计量大数据特征标签生成
为了实现电力计量大数据深度挖掘,该文对电力计量大数据进行处理,生成特征标签,特征标签的生成位置处于大数据平台和上层业务应用之间,作为中间层的关键组件[3-4]。
利用模糊C-均值聚类算法生成特征标签,假设设定聚类个数为K,隶属度因子为m,随机初始化矩阵为U,代入通过模糊C-均值聚类算法,则存在:
其中,通过计算模糊C 均值求得C的迭代函数:
求得迭代函数后,根据迭代函数获取特征标签的聚类中心以及隶属度因子,并进行收敛度判断,若目标函数的变化值小于预设阈值,则输出聚类结果,并根据聚类结果求出聚类迭代值,计算公式如下:
随后,利用电力计量数据的数据源计算平台生成特征标签,该计算平台支持对大量数据进行分布式计算,并提供数据库查询的功能[5-6]。随后建立大数据治理组件,该组件含有三层结构,分别为数据层、分析层、标签层。通过大数据治理组件完成对特征标签的初步生成。电力计量大数据特征标签生成过程如图1 所示。
近些年,反贪调查和公安、国安机关的侦查工作相比,在技术层面的差距非常之大,制约了反贪工作的效率和权威。由此,强化调查领域的技术支持成为重点工作。可以预见的是,在不久的将来,职务犯罪调查将会围绕高新技术进行调查模式的重构。在这个意义上,技术发展的必然性与社会发展的必然性出现了重合,逐步形成了技术的社会化机制。作为调查主体的调查人员却未能与科学技术一样被列为重点建设的目标,也就意味着人文技术调查地位的衰弱。实际上,暗藏在调查中的技术路径选择之争已经初露端倪,并已存在于感官的社会构建之中。但这样的路径之争并非现实的社会构建,作为两种重心不同的调查技术路径选择,至少在理论上值得分析。
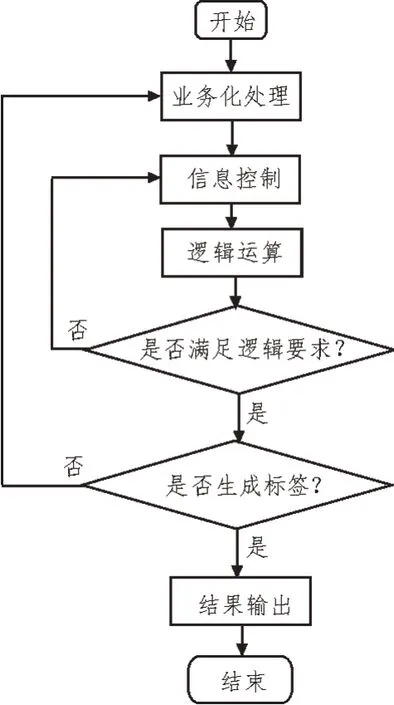
图1 电力计量大数据特征标签生成过程
观察图1 可知,对于电力计算的大数据深度挖掘过程中,需要建立多个特征标签,因此将规则引擎作为特征标签的生产机器,从而产生大量特征标签,并通过标签识别中心完成对特征标签的管理与规划[7-8]。其具体过程如下:
特征标签业务化,主要是通过用户来设置特征标签的生成条件,并赋予修改、检阅特征标签的功能。同时进行特征标签的逻辑检查,其生成条件主要根据电力计量大数据中所需要挖掘的数据制定,工作人员只需管理特征标签的生成以及大数据的维护。
规则引擎作为特征标签的生产机器,是由特征标签业务化后产生的数据实体生成的,在特征标签的开发中进行规则的制定、图形化控制等,规则引擎作为生产特征标签的装置,可对特征标签的生成规则进行设定,针对于不同用途的特征标签,其生成规则也不同,根据生成规则触发生成条件,完成对多种特征标签的制作[9-10]。
标签识别中心可进行特征标签衍生组合的逻辑运算,在工作人员进行设定操作后,将已有的简单特征标签升级成更高级、复杂、有价值的特征标签[11-12]。利用智能化计算进行自动分析对电力计量大数据特征标签进行需求排序。以数值形式表示特征标签的属性。在特征标签制作完成后,需要对其进行价值判断,价值较低的特征标签不能用于对电力计量大数据的挖掘,因此需要建立价值函数来判断特征标签的价值[13-14]。由以下公式计算:
其中,Zi表示第i个标签的价值,当J值大于1时,则认为该特征标签价值较高,可利用其对电力计量大数据进行深度挖掘。生成的特征标签主要有以下几方面作用:
数据抽取,对电力计量中的大数据进行抽取,并根据特征标签进行分类,通过判断工作人员设定的挖掘需求来抽取不同的大数据[15]。
数据转换,用于对电力计量系统中的所有数据进行转换操作,以此及时发现数据源存在的问题,过滤无效信息,利用错误信息建立错误标签。
数据辨识,利用智能化计算对数据进行自动分析,辨识特征标签。
2 电力计量大数据深度挖掘
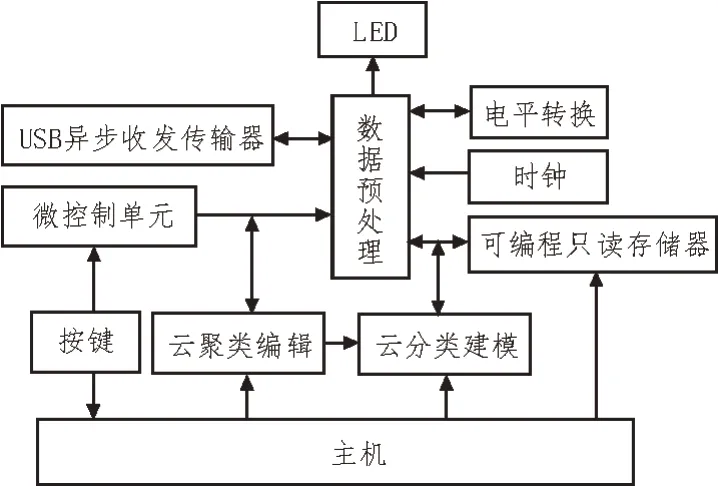
图2 数据挖掘架构
根据图2 可知,USB 异步收发传输器和电平转换实现数据预处理,利用微控制单元实现数据分类,内部配置可编程只读存储器,更好地存储数据。
数据预处理主要是通过特征标签的数据转换功能对电力计量大数据进行预处理操作。在预处理中,利用CK 算法对无效、错误数据进行筛查,根据CK 算法的最小原则对电力计量大数据进行归类处理,确定中心点,在中心点以下排列的数据变为无效数据,无效数据筛选阈值如下:
其中,m为中心点数值;u为判断目标数据[16]。
云聚类编辑主要是指将预处理后的数据进行聚类编辑,根据数据价值从高到低排列数据,结合电力计量大数据深度挖掘的要求进行聚类数据分类,并将分类后的数据传输至数据挖掘架构。
云分类建模结合预处理后的数据,将分类结果传输至数据挖掘架构,数据挖掘架构通过数据融合将分类模块与聚类数据结合,生成挖掘模块,将所生成的挖掘模块传输至挖掘点,进行深度挖掘。
数据挖掘架构结合了云储存性能以及云数据挖掘作业流引擎,对云数据挖掘流程的全部操作应用至数据挖掘架构过程,达到对电力计量大数据的深度挖掘标准,并在挖掘模块中运用图表形式进行可视化表述。
利用特征标签完成对电力计量大数据的深度挖掘,具体过程如下:
首先确定挖掘对象,通过数据抽取得到需要深度挖掘的大数据,明确挖掘后数据的用途。进而进行数据准备,对从电力计量底层中提取到的数据进行预处理,通过CK 算法对无效数据、错误数据进行筛查,并选择特征标签的数据转换功能对错误数据建立错误标签,防止挖掘错误,确保数据的准确性。随后进行云分类建模,选择合适的建模方式对大数据模型进行调整改善,以此提升挖掘精确度与效率。最后将挖掘结果制作成图表呈现给工作人员。
3 实验研究
为了验证该文提出的基于特征标签的电力计量大数据深度挖掘方法的实际应用效果,将其与传统的基于蚁群算法的非结构化大数据深度挖掘方法和基于ERP 的智慧电厂大数据深度挖掘方法进行实验对比。
选用的主机操作系统为Linux 系统,对信息进行配置,系统内存为16 GB,硬盘为2 TB,采用的编程语言为C++语言,开发环境为Hadoop 环境。实验环境如图3 所示。
图3 实验环境
三种方法挖掘的数据量实验结果如表1 所示。
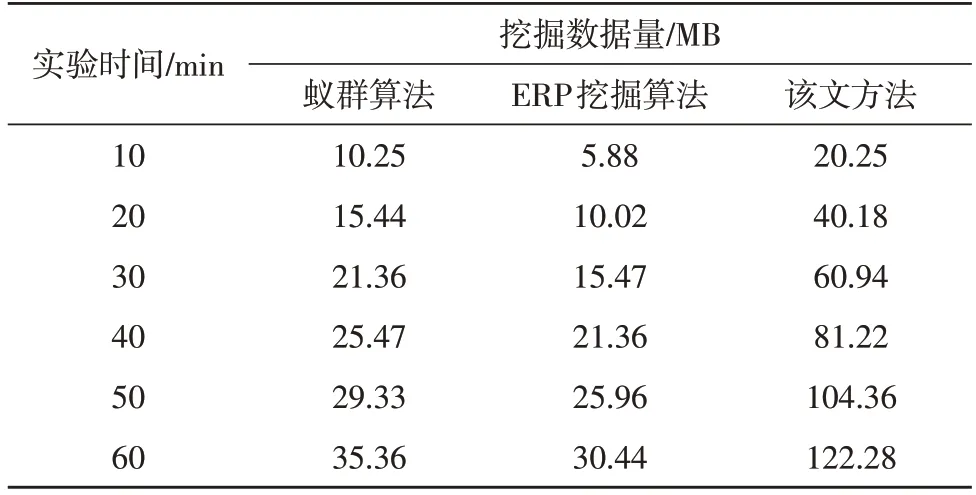
表1 挖掘数据量实验结果
根据表1 可知,随着挖掘时间的增加,三种挖掘方法的挖掘量在不断增加,该文提出的挖掘方法的挖掘数据量要远远高于传统方法。原因是利用该文通过特征标签对数据进行挖掘,在挖掘过程中能够很好地对信息进行分类,通过信息编辑完成数据处理,从而实现低成本、高信息吞吐的挖掘目的。传统的挖掘方法在挖掘过程中难以考虑电力程序逻辑关系,受到输送方式限制,无法挖掘大量数据。
电力计量大数据在挖掘过程中容易受到外界干扰,导致挖掘信息不稳定,降低鲁棒性,为进一步探究挖掘方法的可行性,针对挖掘过程的稳定性进行实验对比,实验结果如图4 所示。
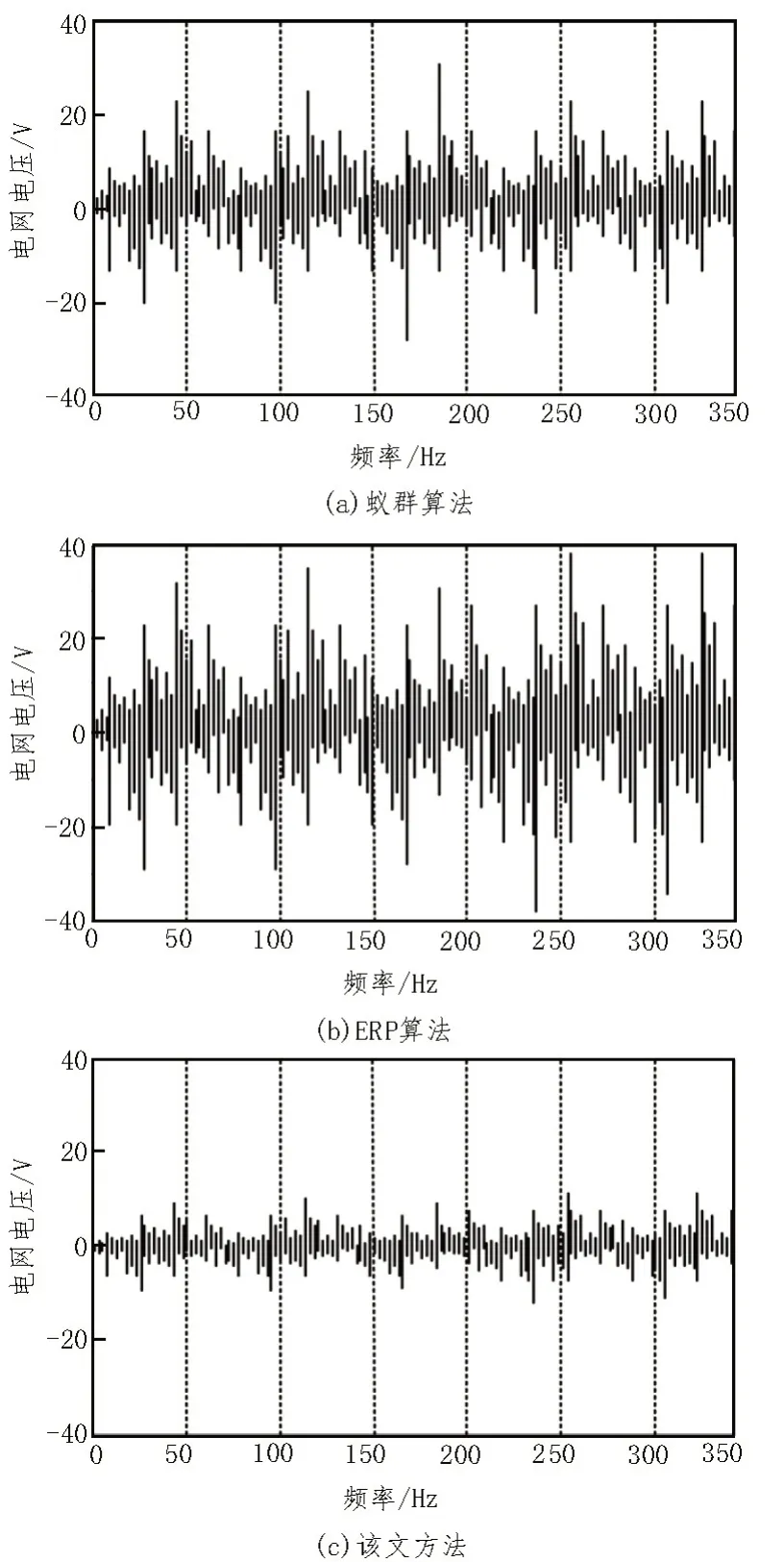
图4 挖掘稳定性实验结果
根据图4 可知,该文提出的挖掘方法在挖掘过程中具有很好的稳定性,信息处理结果更加准确。原因在于该文提出的挖掘方法通过数据分析消除数据,解决信息孤岛问题,通过对设备和电网运行的状态分析,感知信息的运行动态,从而确保挖掘稳定性。挖掘准确率实验结果如表2 所示。

表2 挖掘准确率实验结果
根据表2 可知,该文提出的挖掘方法挖掘准确率更高,挖掘能力更强。
4 结束语
电力系统的高速发展使得电力计量数据增多,对电力计量大数据的深度挖掘成为了电力领域的研究方向之一,传统方式对于电力计量大数据的挖掘仍有缺陷,为了有效解决该问题,该文提出了基于特征标签的电力计量大数据深度挖掘方法,通过引入特征标签更好地实现信息分类,以此实现电力计量大数据的深度挖掘,此方法有效弥补了传统方式的不足,并可为此方面的研究提供参考。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子测试(2017年15期)2017-12-18 07:19:27
电力与能源(2017年6期)2017-05-14 06:19:37
公民与法治(2016年10期)2016-05-17 04:12:58
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
计算机工程(2015年8期)2015-07-03 12:20:27
电子设计工程(2015年6期)2015-02-27 12:04:53
