
面向E 级超算系统的众核片上存储层次研究
2023-12-16 10:28方燕飞董恩铭李雁冰何王全漆锋滨
计算机工程 2023年12期
方燕飞,刘 齐,董恩铭,李雁冰,过 锋,王 谛,何王全,漆锋滨
(国家并行计算机工程技术研究中心,北京 100190)
0 概述
随着计算机科学技术的高速发展,处理器计算能力不断提升,超级计算机系统规模不断扩大,高性能计算(High Performance Computing,HPC)开始迈入E 级(Exascale,E 为超级计算机运算单位,意为每秒百亿亿次)时代。在同一芯片内集成大量计算核心的众核处理器[1-4]凭借超高的性能功耗比和性能面积比成为超算领域的主流处理器架构,2022 年12 月 第60 届TOP500[1]榜单上的前10 台超算 系统均采用众核处理器为系统提供主要算力。
随着数据科学和机器学习方法在HPC 应用领域的渗透和深度融合,HPC 应用对超算系统的运算能力和密集数据处理能力都提出了越来越大的需求。而随着工艺和体系结构技术的发展,面向E 级超算系统的众核处理器计算密度不断提升,片上集成的运算核心数量不断增加,众多核心对存储资源的竞争愈加剧烈,众核处理器面临的“访存墙”问题越来越突出。E 级超算众核片上存储层次是缓解E 级系统内众核处理器“访存墙”问题,帮助HPC 应用更好地发挥E 级系统众核处理器强大的计算优势,提升实际应用性能的重要结构。然而,片上存储器在整个处理器上的面积占比超过50%,功耗占比约为25%~45%[2],而且存储容量非常有限。因此,如何充分利用E 级超算系统众核片上面积,合理设计存储层次,并从面向E 级计算的应用与软件层面最大限度地发挥众核片上存储层次的优势,是工业界和学术界的研究热点。
片上存储层次有多种组织方式,传统多核处理器通常采用多级高速缓存(Cache)结构,而嵌入式处理器通常采用便签式存储器(Scratchpad Memory,SPM)结构来缓解“访存墙”问题。Cache 具有硬件自动管理、性能优化显著等优点,但随着晶体管数量的日益增长,Cache 体系结构在现代众核处理器中变得更加复杂,在面积、性能、功耗等方面都面临挑战,而且Cache 具有程序执行时间不可预知、软件不可控等缺点。SPM 作为Cache 的替代或补充,在能源效率、时间可控性和可扩展性等方面具有明显优势,但其缺点是编译器或程序员需要显式地控制数据布局与传输,对于软件优化和用户编程具有很大挑战。为了充分利用Cache 和SPM 的优势,在性能、功耗、面积、可编程性等方面取得更好的平衡,面向E 级超算的众核片上存储层次的结构变得比多核和嵌入式处理器的存储层次都更加丰富且复杂,软硬件及应用层面都有许多关键技术值得研究和突破。
本文按照不同的组织方式将片上存储层次分为多级Cache 结构、SPM 结构和SPM+Cache 混合结构,并总结3 种结构的优缺点。分析国际主流GPU、同构众核、国产众核等面向主流E 级超算系统的众核处理器片上存储层次设计现状与发展趋势,并从众核共享末级Cache(Last Level Cache,LLC)管理与缓存一致性协议、SPM 空间管理与数据移动优化、SPM+Cache 混合结构的全局视角优化等角度综述国际上的存储层次设计与优化相关软硬件技术的研究现状。
1 众核片上存储层次特点分析
在过去的近二十年中,随着集成电路设计与制造技术的快速发展,处理器频率以每年50%~100%的速度增长,然而主存的速度增长每年只有6%~7%[5],处理器与主存速度差异越来越大。为了缓解处理器和主存之间的速度差,在寄存器与主存之间引入了一种比主存速度更快、容量更小的静态随机存取存储器(SRAM)作为临时存储,形成片上层次化存储结构,也称作片上存储层次。E 级超算系统采用包括寄存器、高速缓存、主存、外存的多级存储体系结构。众核处理器作为E 级系统的计算节点,其片上存储结构是E 级超算系统存储体系结构中的一个重要组成部分,是缓解众核处理器“访存墙”问题,帮助HPC 应用更好地发挥众核处理器计算优势,提升实际应用性能的重要结构。在当前主流众核处理器中,片上存储层次形式多样,按照SRAM 的组织方式可以分为多级Cache 结构、SPM 结构和SPM+Cache 的混合结构等。
1.1 多级Cache 结构
在通用处理器上,SRAM 通常被组织为Cache。在通用多核处理器上常有3~4 级Cache,不同层次的Cache,其容量、延时和功率不同,从主存到寄存器,越往上Cache 的层次越低,容量越小,访问延时越低。比如IBM 的Z15[6],每个核心私有L1 数据Cache和指令Cache,一个数据和指令共用的L2 Cache,所有核共享一个大容量的L3 Cache,此外,还有一个更大容量的片外L4 Cache。但随着片上核心数量的不断增加,受功耗面积等制约,多核Cache 的层次在减少,比如下一代IBM Telum[7],将取消L4 和L3 Cache,物理上只支持L1 和L2 Cache,同时借助更高级的技术实现逻辑上的共享L3 Cache。在当前主流的众核处理器上,由于片上核心数量众多,片上互连结构复杂,为更有效挥地发Cache 的作用,众核大多采用2 级Cache 结构,如图1 所示,各核心私有L1 Cache,L2 Cache 作为末 级Cache 被所有 核心共享,而且L2 Cache 大多容量较大,由多个Bank 组成,通过高速NoC 互连实现核心间共享。

图1 众核处理器上的两级Cache 存储结构Fig.1 Two level Cache memory hierarchy on manycore processor
1.2 SPM 结构
Cache 的设计越来越复杂,且受到面积和功耗的限制,而与Cache 相比,SPM 的功耗和面积比Cache低40%以上[5],因此很多众核处理器将片上SRAM组织成由软件管理的便签式存储器。例如早期由IBM、Sony 和 To shiba 共同开发的 Cell[8]处理器,由1 个跟 Power 处理器(PPE)兼容的主处理器和8 个协处理器(即SPE)组成,其中每个SPE 带有256 KB SPM。又 如Adapteva Epiphany[9]的64 核 心众核处理器,每个计算核心带有软件管理的SPM。再如“神威·太湖之光”超算系统采用的申威高性能众核处理器SW26010[10],由4 个控制核心和256 个从核心组成,每个从核心带有160 KB 的SPM。通常,片上的多个计算核心之间通过片上网络(NoC)互连,每个核心除了可以访问本地SPM 之外,还可以通过NoC 访问远程的SPM,并且访问延迟与核心间的距离成正比。众核片上核心访问远程核心SPM通常有两种方式:一种是由底层体系结构支持的共享SPM 方式;另一种是通过RMA 等方式显式地访问远程核心的SPM。前者对用户透明,后者需要调用RMA 接口显式编程。有的处理器上的核心还配备直接内存访问(DMA)引擎,用于在片外内存和本地SPM 之间传输批量数据。图2 显示了基于SPM的众核架构[11]存储结构示意图。每个核心包含一个统一的SPM 用于指令和数据,每个SPM 持有应用程序要使用的全局地址空间的不同部分。虽然SPM可以同时作为代码和数据的片上缓存,但在高性能计算领域,为了减少对代码管理的复杂度,众核处理器通常会在片上提供指令Cache,而只有数据是采用SPM 结构进行缓存,典型的如SW26010。本文后续讨论的众核片上存储层次也默认都是有指令Cache 的。
随着SPM 逐渐被用在GPU、通用处理器及高端处理器上以代替一级数据Cache,在一些高性能计算机体系结构中,甚至采用多级软件管理存储层次代替传统多级Cache 存储层次[12]。
1.3 SPM+Cache 混合结构
由于传统的SPM 控制器不包含任何辅助管理数据的逻辑电路,SPM 中的所有数据必须经由软件显式管理,没有管理逻辑电路带来的额外代价,在相同容量下,SPM 面积和单次访问的能耗都小于Cache。Cache 由于在发生冲突等情况下访问时间会大幅增加,因此Cache 具有不确定性的命中时间,SPM 无法像Cache 那样由硬件自动完成缓冲数据的换入换出操作,因此SPM 不存在访问缺失的情况,始终能够保证一个很小的固定时钟周期数的访问时间,从而保证了程序的确定性。但是SPM 的容量有限,而且由于不能自动完成数据从主存到SPM 的映射,因此对编译器和用户编程带来了很大挑战。表1给出了Cache 与SPM 特点的对比,两者各有优缺点,而且优势互补。

表1 Cache 与SPM 的特点对比Table 1 Comparison of features of Cache and SPM
为了更好地适应不同应用的需求,充分利用Cache 与SPM 的优势,越来越多的众核处理器片上存储结构开始采用SPM+Cache 混合的方式来追求一种平衡设计。NVIDA 公司面向通用计算领域的GPU 上的存储层次就是SPM+Cache 混合的典型代表,从其第二代GPU 架 构Fermi[13]开 始,为了提 升GPU 的计算效率,引入了L1 和L2 Cache,SPM 结构的共享存储器(Shared Memory,SMEM)容量也变得更大,图3 给出了典型的Fermi 架构的存储层次,每个SM 有一个私有的L1 Cache 和SMEM,容量分别为48 KB 或16 KB,所有流式多处理器(SM)共享768 KB L2 Cache。自Fermi 之后的每一代架构都继承了Cache+SPM 的混合结构。NVIDIA GPU 一直保留SMEM 功能,由软件负责实现数据的读写和一致性管理,有利于CUDA 多线程间数据重用,对于图形计算等数据流处理类应用可以挖掘极致的性能。而后引入的两级 Cache 结构,使GPU 在HPC 领域的适应性明显加强,没有使用SMEM 的应用程序以及无法预知数据地址的算法,都可以从L1 Cache 设计中显著获益。

图3 Fermi 存储层次示意图Fig.3 Schematic diagram of Fermi storage hierarchy
1.4 众核片上存储层次结构类型总结
众核处理器系统根据其片上存储层次中是否包含SPM 可以分为4 类:1)没有SPM 的纯Cache 系统;2)只 有SPM 的不可Cache 系 统;3)拥 有SPM 和Cache 的混合系统;4)SPM 和Cache 混合且容量可配置的系统,可以配置成纯SPM 模式、纯Cache 模式、或者SPM 与Cache 混合的模式,而且SPM 与Cache的容量可以有多种组合配置。典型的混合存储结构为核心私有1 级Cache 和SPM(容量可配置),所有核心共享MB 级大容量L2 Cache 的结构。
片上存储层次的设计除了组织方式外,还有一个必须关注的物理部件,即片上高速互连网络NoC(如富士通A64FX[3]、申威众核处理器均设计了NoC)。片上高速网络增强了核间数据交互能力,间接提高了单核心Cache 或者SPM 的数据重用能力,降低了主存访问压力,是硬件高效组织共享末级Cache 和共享SPM 的关键,也是应用算法和系统软件充分共享利用片上资源的重要途径,因此,在片上存储层次的设计与使用中,必须考虑片上网络的结构特点。
2 面向E 级超算的众核处理器片上存储层次
2.1 主流GPGPU 存储层次现状
作为通用加速卡的GPGPU 凭借其卓越的计算能力,已经在HPC 领域扮演着越来越重要的角色。NVIDIA 通用GPU 作为最主流的通用众核加速卡,已经广泛应用于HPC 领域,比如第60 届Top500 排名前10 的超算中有5 台都采用NVIDIA 的GPU 进行加速。而AMD 和Intel 的通用GPU 也分别作为美国的3 台E 级系统上的加速卡为系统提供主要算力。下文将分别分析上述3 个面向HPC 的主流GPU 架构存储层次现状及其发展趋势。
2.1.1 NVIDIA Hopper 架构的存储层次
NVIDIA GPU 的架构从Tesla 到Hopper 已经发展了9 代,为了适应GPU 计算能力的不断提升,其片上存储层次也在不断发展。自Fermi 架构采用SPM+Cache 混合的片上存储结构之后,后续的架构在存储层次上的设计没有较大的变革,其变化主要表现在各级存储在容量上的变化、SMEM 与L1 Cache 结合方式上的变化等。直至第7 代Volta 架构,其片上存储方式较前几代架构又有了比较重大的变化。Volta 架构将数据Cache 与SMEM 从功能上做到一个存储体(memory block)中,使得两种缓存方式均达到了其访问的最好性能。SMEM 与L1 Cache 的总容量为128 KB,且容量可以有多种灵活的配置。第8 代Ampere 架构的片上存储方式继承了Volta 架构的片上存储方式,但将存储空间总大小扩大至192 KB/SM(采用Ampere 架构的典型GPU为A100[14])。A100 的L2 Cache 容量扩展到40 MB,是V100 的7 倍,并且支持驻留优先级设置,可以提高持续访问数据驻留Cache 的权利,从而减小DMA带宽需求。此外,Ampere 增加了异步拷贝指令,可以直接从L2 Cache 以及DRAM 中批量传输数据到SMEM 中,而在前一代架构Volta 中,需要通过一个全局加载指令从L1 Cache 到寄存器中,然后再用Store-Shared 指令从寄存器中传到SMEM 中,图4 展示了Ampere 与Volta 的存储结构变化。从最新一代Hopper 架构H100 和Ampere 架构A100 的对比来看,最近的两代存储架构方面没有大的变化,只是H100的SLM 容量增加到256 KB,且H100 从硬件对TMA(Tensor Memory Accelerator)的功能上做了更多的支持。
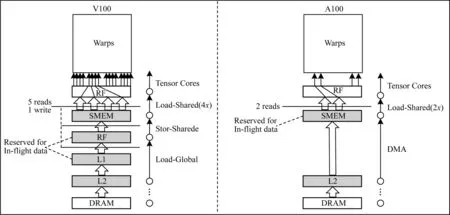
图4 Ampere 与Volta 的存储结构变化Fig.4 Storage structure changes of Ampere and Volta
从NVIDIA 9 代GPU 架构的存储层次发展趋势来看,Cache+SPM 的混合结构是其片上存储层次的一个创新解决方案,混合结构可以更好地兼顾面积、性能、功耗及好用性,以满足不同领域应用的多样化需求。对于某些应用,Cache 仍然是保证系统通用性和应用性能的关键结构,而SPM 结构为某些HPC 应用挖掘极致性能提供了更多可能。对于有些更复杂的应用,则既需要SMEM 也需要Cache,因此支持Cache 与SMEM 容量的灵活配置,可以进一步提高对不同类型应用的适应性。进一步地,为方便程序员或者编译系统挖掘应用数据访问特性,Hopper 架构引入了线程块集群(Thread Block Cluster,TBC)和分布共享内存(Distributed Shared Memory,DSMEM)概念,同一线程块集群内的SM 之间可以共享访问SPM,而无须通过Global Memory 交互数据,从而提高数据交互效率。此外,硬件上提供了只读数据缓存的Read-Only Data Cache 以及异步拷贝指令,都可以进一步降低访存时延、提升带宽利用率,虽然这些设计会增加软件管理和编程复杂度,但是为应用或编译系统充分挖掘片上缓冲性能提供了更多手段。
2.1.2 AMD CDNA2 架构的存储层次
AMD CDNA2 是AMD 在2021 年11 月新发布的GPU 架构,其设计目标是科学计算和机器学习领域的应用。最新TOP500 排名第1 的美国E 级超算系统Frontier 采用的加速卡AMD MI250X 正是基于AMD CDNA2 架构的AMD Instinct MI200 构建的。AMD MI250X 采用MCM 技术封装了两个AMD Instinct MI200 GCD。
每个AMD Instinct MI200 GCD 包含112个计算单元(Compute Unit,CU),最低级别的内存层次结构位于CU 内部,如图5 所示,每个CU 包含一个16 KB L1数据Cache 和64 KB SPM 结构的本地共享存储器,另有一个4 KB 共享SPM 结构的全局共享存储器。整个GCD 共享一个由32 个Slice 构成的16 路组相连结构的L2 Cache,总容量为8 MB。
2.1.3 Intel Xe 架构的存储层次
美国E 级计划中的Aurora 超算系统采用 Intel Xe 架构的GPU,Xe 架构是Intel 继Gen 9 和Gen 11 之后的最新一代GPU 架构。Gen 9 和Gen 11 都是采用3 级Cache 结构,在片上使用共享本地内存(Shared Local Memory,SLM),是一种SPM 结构。作为一级数据缓冲,没有通用的L1 数据Cache。Gen 11 相对Gen 9 在存储层次上的改进特点是将SLM 带入了子Slice 单元,使得SLM 更接近执行单元(EU),以便在同时访问L3 Cache 时减少数据的争用。SLM 更接近EU 也有助于减少延迟并提高效率,如图6 所示。
Intel 的Xe 架构是对前两代Gen 9 和Gen 11 架构上的进一步升级,Intel Xe 架构不仅全面提升了执行单元的规模,从存储层次发展来看,Xe 架构保留了Gen 11 相 对Gen 9 在SLM 上的改 进,即 将SLM 带 入SubSlice,并且Xe 架构相对Gen 11 进一步新增了L1数据Cache。Xe 架构还支持端对端压缩,L2 Cache的容量也有大幅提升。目前发布的Intel Xe 架构GPU Ponte Vecchio 支 持 512 KB 的 SLM 与L1 DCache 动态可配的一级缓冲,二级Cache 增加到64 MB。从不同代系的发展来看,在追求兼顾性能与好用性的目标中,Intel 的GPU 存储层次设计也逐步采用SPM+Cache 的混合结构。
2.2 同构众核系统的片上存储层次
目前TOP500 排名第2 的日本的Fugaku/Post-K超算系统,采用的是富士通A64FX 处理器[3]。
A64FX 处理器采用同构众核处理器体系结构,片上集成52 个同构核心,包括48 个计算核心与4个辅助核心,如图7 所示,所有核心分为4 个组,每组13 个核心,一组核心称为一个CMG。在A64FX 处理器芯片中,多个CMG 通过片上网络连接。富士通的A64FX处理器为了减小芯片大小,采用两级Cache的结构,每个核心私有64 KB 一级Cache,一个CMG 的所有核心共享一个8 MB 二级Cache。A64FX 采用类似于环形拓扑网络的片上网络,以支持CMG 之间的内存一致性协议,从而可以使用多个CMG 执行共享内存程序。

图7 A64FX 片上存储层次Fig.7 On-chip storage hierarchy of A64FX
富岳采用的A64FX 存储层次设计是以应用和编程软件需求牵引的一种协同设计。比如其CMG 内核心数量、一二级Cache 的容量以及Cache line 的大小等参数设置,都是在模拟富岳的重点目标应用程序性能的前提下给出的,在功率、面积和性能之间取得更好的权衡。为了提高目标应用程序的性能,采用增强型的缓存功能设计,比如采用组合聚集操作技术,使间接加载的数据吞吐量加倍,采用二级缓存数据重用优化技术提高缓存带宽。纯Cache 结构具有更好的应用适应性,但同时也面临可扩展性问题。
2.3 新一代国产众核存储层次现状
2.3.1 MT-3000 异构众核处理器存储层次
国防科技大学推出了一款自主设计的面向新一代天河超算系统的异构众核处理器MT-3000[12]。
MT-3000 采用多区域加速架构,其结构如图8 所示,CPU 内包含16 个通用处理器核心和4 个加速域,采用混合存储器层次结构。
MT-3000 的每个通用CPU 核含有支持高速缓存一致性 的两级私有Cache,L1 Cache 被L2 Cache 包含,L2 Cache 容量为512 KB。每个加速域包含24 个控制核心和384 个加速核心,采用两级SPM 结构,其存储层次如图8 所示,每个加速域含有1.5 MB 的域内共享内存(DSM)和48 MB 的高速共享内存(HBSM),其中DSM 只能由加速域内的核心访问,而HBSM 被本加速域的所有核心及通用域的16 个CPU 核共享。片上含有两级高速互连网络,每个加速域内采用全连接网络,而16 个通用核心间通过二维Mesh 网相连,16 个通用核心可以访问4 个加速域的HBSM。MT-3000 加速域支持软件管理的垂直存储一致性,将加速域内的DSM(6 MB)、HBSM(共48 MB)、DDR4 存储(共32 GB)三级存储架构,通过高速DMA 和片上网络连接,提供了高带宽的数据传输和核间数据交互能力。
2.3.2 申威众核处理器存储层次
用于“神威·太湖之光”的申威26010 众核处理器[10,15],片上采用纯数据SPM 的结构。SW26010 包含4 个核组,每个核组有64 个运算核心,每个运算核心私有128 KB SPM。而面向E 级系统的新一代申威众核处理器[16]开始采用SPM+Cache 混合的片上存储结构。该众核处理器包含6 个核组,每个核组有64 个运算核心,每个运算核心有256 KB SRAM,支持SPM与L1 Cache 混合且容量可配置的使用方式,64 个运算核心的SRAM 还可以通过片上NoC 互连组织成共享SPM 空间,片上存储模型如图9 所示。运算核心可以RMA 或者远程load/store 的方式访问同一核组内远程运算核心的SPM 空间,也可以通过DMA 将主存空间数据批量传输到私有或者共享的SPM 空间上。
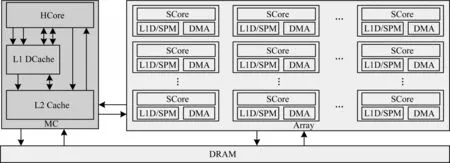
图9 新一代申威众核处理器存储层次Fig.9 The storage hierarchy of the new generation of Shenwei manycore processors
为更好地适应不同数据访问特征的HPC 应用的需求,提升主存数据的访问效率,系统支持主存空间访问可以配置成可Cache 和不可Cache 两种属性。但为了降低编程复杂度,这种属性通常对用户透明,用户程序主存数据默认都是可Cache 的,编译器或者运行时可以利用主存不可Cache 空间结合DMA 进行访存优化,减少维护Cache 一致性的开销。
2.4 面向E 级超算的众核处理器片上存储层次结构类型总结
表2 以众核计算核心的视角总结了各主流众核处理器的片上存储层次。富岳A64FX 同构众核采用两级Cache 结构,MT-3000 异构融合架构中的加速域 采用纯SPM 结 构,而NVIDIA、Intel、AMD的面向E 级系统的GPU 以及申威的最新一代异构众核处理器SW260x0 均采用SPM+Cache 混合的结构。可见目前的HPC 主流众核片上存储层次结构并不单一,这是由多种因素导致的,不同处理器面向的应用领域需求不同,追求的设计目标不同,各自的技术积累也不同。但是,从横向的比较和各处理器自身纵向的发展趋势,以及从HPC 与数据科学、机器学习不断融合发展带来的应用需求变化来看,SPM+Cache 的混合结构最可能成为今后HPC 众核处理器片上存储层次设计的主流选择。另外,从表2 最后一列的分析可以看出,虽然主流GPU 都采用了的SPM+Cache 结构,但每一款GPU的SPM 和Cache 的功能细节也各有不同,例如NVIDIA H100 的L1 只能为Cache CUDA 对应的Local 空间的数据,Global 空间数据只能缓存进L2 Cache。H100 还支持同一TBC 内SM 远程访问共享SPM,新的存储层次特性也给HPC 编程带来新挑战。而AMD MI250X GPU 支持的CU 私有SPM和L1 DCache 是SIMD 单元专用的,如果HPC 程序员要深度优化程序性能,则必须要充分利用好这些存储结构特性。
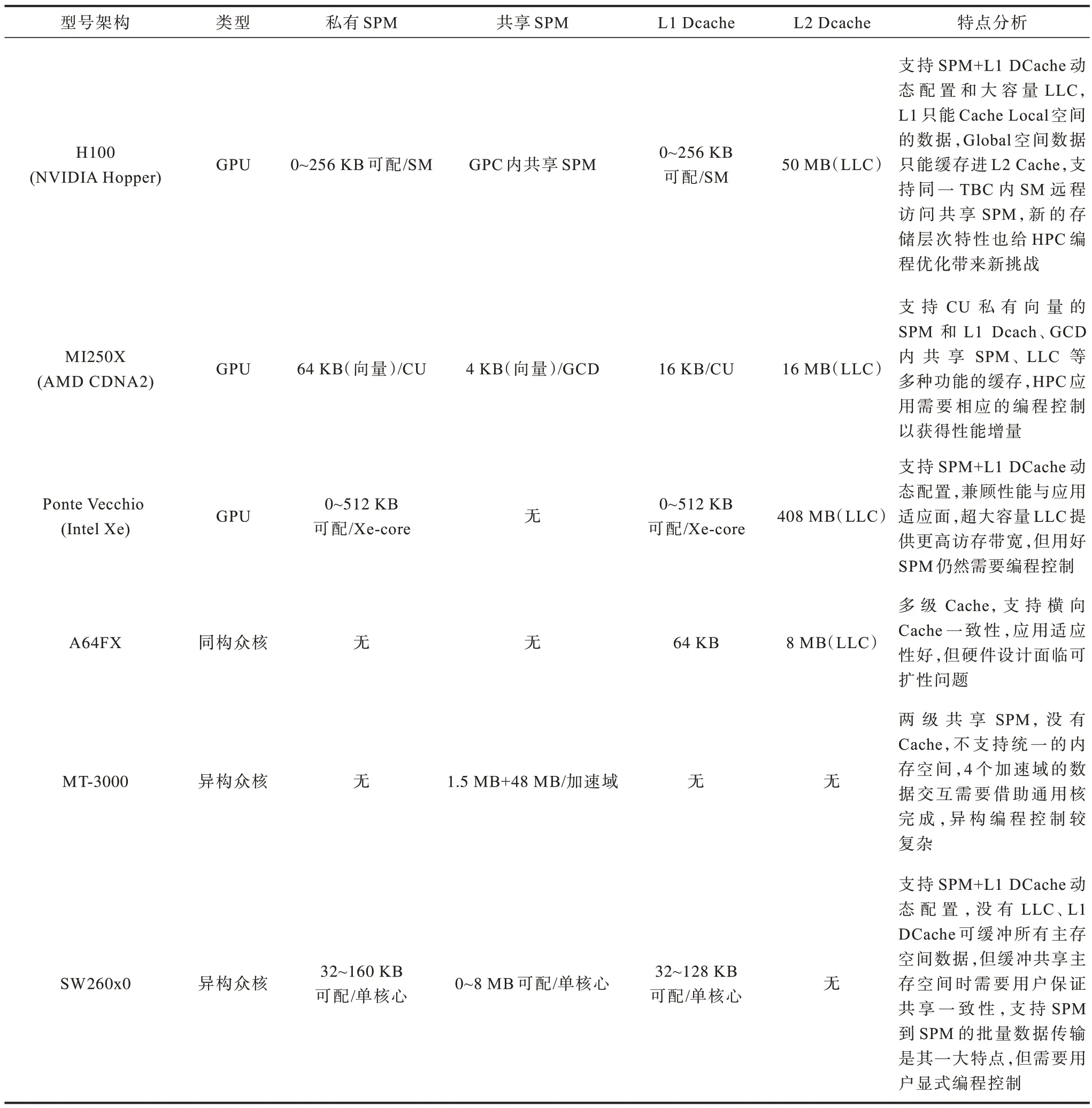
表2 主流众核处理器片上存储层次Table 2 On-chip storage hierarchy on mainstream manycore processor
3 面向众核片上存储层次的优化技术
众核是构建E 级超算系统的主要计算节点,为E级超算系统提供主要算力来源。如何充分发挥众核处理器片上众多核心的计算能力,一方面需要硬件层面开展众核片上存储结构设计,另一方面需要面向E 级计算的应用和软件开展相关优化技术,以充分利用众核片上存储层次特点。当前面向E 级的主流众核处理器采用的片上存储层次结构多样,各具优缺点,本文从多级Cache、SPM 以及SPM+Cache 混合3 种结构分别探讨当前主流软硬件设计与优化技术。
3.1 多级Cache 的优化
随着片上核心数量的不断增大,片上互连结构日趋复杂,要使Cache 结构在片上众多核心竞争的环境下能继续高效工作,必须解决好两方面问题:共享末级Cache(LLC[11])的高效管理问题和Cache 一致性问题。
3.1.1 LLC 的管理策略
众核片上典型的Cache 结构为:核心私有一级Cache,L2 Cache 作为LLC 由所有核心共享。在众核环境下LLC 会同时接收来自于多个线程的访存请求,而线程间的数据访问特征有可能各不相同,大量并发线程间的相互干扰会影响LLC 的使用效率。因此,如何管理片上LLC 资源是影响众核处理器访存性能的关键因素。传统LLC 的替换与插入策略的研究已经比较成熟,包括使用LRU 作为替换策略的插入策略、动态插入策略(DIP)、线程感知的DIP 策略,还有后续提出的静态重引用间隔预测策略、动态重引用间隔预测策略和线程感知的动态重引用间隔预测策略。但是,这些传统的LLC 管理策略在众核系统下已无法高效工作。文献[17-20]提出了在CMP的竞争线程之间动态划分共享LLC 的策略,文献[21-22]则进一步考虑了多线程间的共享数据行为的影响,并将其融入到LLC 的管理策略。上述技术大多针对同构众核系统,而文献[23-24]针对异构众核系统开展了LLC 管理策略研究。文献[25]在前人基础上提出了适合片上异构众核处理器的动态LLC 替换策 略DIPP(Dynamic Insertion/Promotion Policy)。该替换策略核心思想是通过限制GPU 核能够获取的Cache 资源,达到降低程序间的线程干扰,降低程序的失效率和提升系统整体性能的目的。
随着CMP 上处理器核心数量的不断增大,非一致Cache 体系结构(NUCA)成为当前CMP 上大容量低延迟Cache 的主要组织结构。NUCA 结构中的LLC 由于容量较大,通常分为多个Cache 存储体(bank),所有bank 置于芯片中央,通过NoC 在逻辑上组织成一个被所有核心共享的统一的末级Cache。NoC 是组织LLC 的重要互连方式。随着NoC 规模的扩大,一方面,网络延迟正在成为缓存访问延迟的主要来源,另一方面,不同核心之间的通信距离和延迟差距正在增大。这种差距会严重导致网络延迟不平衡,加剧缓存访问延迟的不均匀程度,进而恶化系统性能。文献[26]分别针对无冲突延迟和竞争访问提出了非一致性存储映射和非一致链路分布的设计方法。文献[27]提出了一种新的面向公平性和位置感知的NUCA 方案,以缓解网络延迟不平衡的问题,实现更统一的缓存访问。文献[28]提出一种位置敏感的LLC,通过感知Cache 行位置和利用GPGPU 的核间通信来缓解GPGPU 片上网络瓶颈,减少访存延迟。文献[29]将LLC 淘汰的Cache 块保存在NoC 的路由器上,当有核心请求这块数据时,由NoC 直接响应这个请求。这些研究都充分利用了NoC 的特点,为基于NoC 的NUCA 数据访问的不平衡性问题提供了多种解决方案。
3.1.2 众核片上缓存一致性协议
当多个处理器核的高速缓存保持从主存获取的同一数据对象的本地副本时,即使其中任何一个高速缓存修改了同一数据对象的值,也会导致高速缓存和共享内存之间共享数据的全局视图不一致,这个问题称为缓存一致性。在众核处理器中,为管理共享缓存中的读写操作,以便在所有处理器核心之间维护一致性,而执行的一组特定规则称为缓存一致性协议。缓存一致性协议可分为目录协议[30]和监听协议[31]两大类,基本作用是发现共享数据块的状态。传统的缓存一致性协议设计复杂,开销较大,无法满足众核处理器共享存储系统追求高效、低功耗、可扩展的设计目标。国际上有大量面向片上众核系统低开销可扩展的Cache 一致性协议研究。文献[32]提出了可扩展到千核规模的融合一致性Cache,在统一物理内存的基础上,采用两级目录的融合一致性设计。文献[33]提出了SCD 框架,它依赖于高效的高关联缓存实现一个可扩展到数千个内核的单级目录,精确地跟踪共享集,并且产生可忽略的目录引起的失效。国内也有许多研究者在Cache一致性协议功能扩展和性能优化等方面开展了研究。文献[34]针对共享存储系统提出一种没有目录和间接访问、没有众多一致性状态和竞争的简单高效的Cache 一致性协议VISU,解决了制约目录协议可扩展性的目录开销问题。文献[35-36]提出了一种具有表达力的、区域高效的目录缓存设计,并分别在64、256 核系统上进行了评估。文献[37-38]提出了基于时间的硬件一致性协议,即库缓存一致性(Library Cache Coherence,LCC),它通过暂停对缓存块的写入,直到它们被所有共享者自失效为止,从而实现顺序一致性。
当可伸缩一致性在通用芯片多处理器中得到广泛研究时,GPU 体系结构具有一系列新的挑战。引入传统的目录协议会给现有的GPU 应用程序增加不必要的一致性通信开销。此外,这些协议增加了GPU 存储系统的验证复杂性。文献[39]描述了一个基于时间的GPU 一致性框架,称为时间一致性(TC),它利用系统中的全局同步计数器来开发一个简化的GPU 一致性协议。同步计数器使所有一致性转换(如缓存块失效)能够同步发生,从而消除所有一致性通信和协议争用,达到减少GPU 一致性的开销的目的。文献[40]提出CPU-GPU 硬件缓存一致性不要同时实现统一共享内存和高GPU 性能的思想。文献[41]针对CPU-GPU 系统开发了异构系统一致性协议(HSC),以缓解GPU 内存请求的一致性带宽效应。文献[42]提出一种软件辅助硬件一致性(SAHC)来扩展Cache 一致性以适应异构处理器。系统软件通常具有跨CPU 和GPU 共享数据模式的语义知识。这些高级知识可用于在异构处理器中跨面向吞吐量的GPU 和对延迟敏感的CPU 提供缓存一致性。SAHC 提出了一种混合软硬件机制,该机制仅在需要时才使用硬件一致性,同时使用软件知识过滤掉大部分不必要的一致性通信。
从上述研究可以看出,众核上的Cache 一致性协议设计工作围绕可扩展和低开销的设计目标,针对典型数据共享模式和众核处理器体系结构开展软硬件协同设计,提出的大多是一种有裁减的弱一致性协议。
3.2 SPM 结构的优化
SPM 结构的特点是完全将数据的布局与传输交给软件,面向SPM 结构的众核程序的编程与优化,必须解决好程序数据的布局与传输两个关键环节。
3.2.1 基于SPM 的堆栈空间管理
在只有SPM 结构的众核系统上,软件必须显式地管理每个核心本地SPM 的进出数据,包括全局数据、堆空间数据、栈空间数据的管理。当核心对应的所有数据都能在本地SPM 上放下时,程序执行效率非常高。当核心程序对应的数据总量超出本地SPM容量时,必须进行显式数据管理才能使SPM 发挥出较好的性能。对全局数据而言,用户通常可以将其分为两种,一种是可以完整放入SPM 中的变量,另一种是无法放入SPM 空间的全局数据(数据容量超过SPM 空间,或者SPM 空间已满),用户可以在程序需要数据之前通过DMA 引入数据到SPM,在不再需要数据之后将其返回到全局内存。当程序的全局数组总容量超过SPM 空间时,程序员需要考虑哪些数组布局在SPM,哪些数组布局在主存并通过DMA 进行传输。对于C/C++程序来说,全局静态数据是可以在编译时确定容量的,而其栈空间或者堆空间数据其大小是可变的,并且与输入数据有关,用户通常没有有效的方式来管理堆数据和栈数据。由于堆栈数据的访问是程序中内存访问的重要部分,因此必须有高效的堆栈管理手段来发挥SPM 的性能。
基于SPM 的存储层次对程序员提出了很高的要求,需要对算法和片上存储层次特点都有非常准确的把握,而且程序实现起来工作量也很大。为此,国际上开展了许多面向软件管理的存储层次的编译优化研究,一类是面向SPM 的静态分配技术[43-45],通过采用启发式或者整数线性规划等算法,确定哪些数据布局进SPM,哪些放置在主存中,还有一类是动态分配技术[46-49],包括软件Cache 技术、基于图着色算法的SPM 分配与自动DMA 技术等。文献[50-54]专门针对众核系统面向SPM 的堆栈空间管理开展了长期深入的研究。在栈空间管理方面,他们最初提出了局存容量受限的众核处理器上的栈数据管理的方案[50],支持在SPM 上的任意空间上管理任何任务的栈数据,并正确管理所有栈指针,但是其管理开销较高,并且管理没有得到优化。在此技术上,文献[54]对栈数据管理做了进一步优化,并减少其管理开销。在堆空间管理方面,文献[51-52]提出了一种半自动的、可扩展的堆数据管理框架,通过提供简单直观的编程接口来帮助用户实现自动管理堆数据,隐藏了软件缓存堆数据的复杂性。之后又在文献[53]中进一步提出一种全自动、高效的堆数据管理框架,通过一个编译和运行时系统,实现在有限的本地内存众核体系结构中自动管理无限大小的堆数据。文献[48]在上述框架基础上进一步开展了3 种通用优化,使得堆管理框架更加高效。
3.2.2 基于SPM 的片上数据移动
为了更好地发挥SPM 的结构优势,HPC 领域的主流众核系统片上存储结构设计通常会提供DMA来加强SPM 与主存间数据的传输效率,同时利用NoC 实现片上众多核心间SPM 的互连,增大单核心可见的SPM 容量。SPM 的容量、DMA 访存带宽、NoC 通信带宽都是众核系统实现核心数据高效传输与访问的重要资源,复杂的众核应用需要通过对核心数据进行合理高效的划分、映射与传输,才能实现上述片上资源的高效率用。比如通过循环变换等技术可以增加SPM 数据的重用率,减少数据进出SPM的频率。核心间基于NoC 的数据传输带宽要比从主存到SPM 的DMA 带宽高很多,可以结合应用访存特征合理分配数据与任务,使得多核心间可通过远程内存访问(Remote Memory Access,RMA)命令或者RLD/RST 共享SPM 上的数据,发挥NoC 的优势,提升SPM 数据在片上的重用率,这些方法都可以降低应用程序对单个核心的SPM 容量需求,缓解DMA访存压力。上述工作对用户编程和编译器优化提出了巨大挑战。国际上有许多工作围绕SPM 结构特点开展高效性与好编程性的研究,从不同角度提出了许多面向SPM 高效编程的优化方案、框架、运行时库及编译优化,为用户开发高效的SPM 众核程序提供编程优化指导或者编译优化支持。
文献[55]针对SPM 用于多线程应用程序时遇到的挑战,提出了协调数据管理(CDM),这是一个编译时框架,可以自动识别共享/私有变量,并将这些变量及这些变量的拷贝(如果需要)一起放置到合适的片内或片外存储器中,同时考虑NoC 争用。另外,还开发了一个精确的整数线性规划(ILP)公式以及一个迭代的、可伸缩的算法,用于将多线程应用程序中的数据变量放置在多个核心SPM 上。文献[56]提出了一个用于优化异构多核体系结构上SPM 和主存之间的多线程数据传输的编译时框架MSDTM,该框架通过应用程序分析和依赖性检查来确定数据传输操作的分配,并通过所设计的性能模型来推导数据传输的最佳粒度。文献[57]提出一个名为UniSPM 的框架,使用低开销的递归启发式算法来解决NP-hard 的映射问题,为基于NoC 的SPM多核多阶段多线程应用程序提供统一的线程和数据映射框架。文献[58]针对众核平台存储层次特点提出了一种基于运行支持库的OpenMP 数组私有化的编译优化方法,对可重用数据进行私有化,充分利用有限的SPM 资源减少DMA 通信,以提升程序执行效率。文献[59]针对“神威·太湖之光”超算系统上支持DMA 的SPM 存储结构,提出了一种基于带宽感知的OpenCL 程序循环平铺方法,对传统的仅带宽和仅容量考虑的循环平铺方法进行了改进,有效提升了带宽利用率和SPM 重用。文献[60]基于SPM提出了一种新的GPU 资源管理方法EXPARS,通过将寄存器文件扩展到SPM 内存,通过未被充分利用的SPM 来支持额外的寄存器分配,在逻辑上提供了一个更大的寄存器文件。文献[61]针对申威众核处理器核心的SPM 存储结构特点,开展了基础函数库的内存延迟优化,提出一种有效的自动数据转换方法和一种表查找方法来优化基础函数库的访存延迟。
3.3 SPM+Cache 混合结构下的全视角优化
相比纯Cache 或者纯SPM 结构的存储层次,混合结构具有两者的优势。原本SPM 结构下最棘手的程序堆栈空间管理问题在混合结构下可以得到很好的缓解——堆栈空间可以直接放在主存,基于Cache 进行缓存。而原本引起严重Cache 冲突的数据可以优先布局进SPM,或者利用DMA 加SPM 缓冲的方式避免数据进入Cache。因此,混合结构下存储层次的优化,重点在于如何联合Cache 和SPM 开展全视角优化以获得一加一大于二的性能。
国际上针对混合结构的片上存储层次优化开展了一系列研究。文献[62]利用DMA 实现SPM 数据的动态换入换出,从而避免了传统动态优化技术利用数据Cache 实现数据搬运可能造成的对数据Cache 的污染问题,并利用类似虚拟内存管理的思想,将部分动态申请且频繁引起数据Cache 冲突的堆栈数据和堆数据的连续虚地址空间重定位到SPM中获得系统性能和能耗的收益。文献[63]研究了6 种不同的SPM 分配算法来优化混合SPM 缓存结构的性能或能耗,并通过实验证明感知Cache 的SPM分配比不感知Cache 的SPM 分配具有更好的性能或能耗的结论。文献[4]认为在混合体系结构中可将频繁使用的数据分配给SPM 以进行快速检索来降低对缓存的访问频率,因此可将混合SPM+Cache 的Cache 行更主动地置于低功耗模式,在不显著降低性能的情况下减少更多的泄漏能量。文献[57]提出一种编译器技术将应用程序数据对象映射到SPMCache,以整个程序优化为目标,根据SPM 和Cache大小以及应用程序的动态需求进行数据分配。文献[64]提出一种Cache 和SPM 参数可动态配置的可重构片上统一存储器(RcfgMem),通过动态调整Cache 的关联度和SPM 的容量等片上存储资源的参数,可以适应不同的应用程序或同一应用程序在不同阶段对存储层次的需求,在不损失系统性能的前提下达到降低系统能耗的目的。文献[65]通过一种软硬协同的方式支持SPM 到主存的映射,实现SPM与主存间的自动隐式数据传输,减轻用户显式调用DMA 传递数据的编程负担,并通过支持重映射和利用SPM 压缩存储机制提升SPM 空间的利用率,同时又避免了Cache 结构下访问TLB 所需的延迟开销和Cache 不命中开销。
4 未来展望
在众核体系结构日益复杂的趋势下,众核片上存储层次的设计与优化使用面临许多关键技术挑战,需要开展软硬件协同设计。下文从硬件、软件和算法3 个层面的未来发展进行展望:
1)硬件设计层面。随着E 级系统众核处理器上集成的核心数量越来越多,片上互连能力越来越复杂,传统的多级Cache 或者SPM 将无法满足新兴众核结构上存储层次的发展需求,众核处理器片上存储层次会越来越丰富。从存储层次结构发展趋势上来看,Cache 与SPM 混合的结构因其更好的应用适应性而更可能成为未来众核片上存储层次的主流结构。而如何基于片上网络实现众核心间SPM 的数据共享、数据批量传输以及可扩展的Cache 横向一致性都将是未来片上存储结构的重要研究方向。总之,面向超大规模E 级系统的众核处理器片上存储层次的设计需围绕系统的整体设计目标开展,未来非常有必要针对大量目标应用场景进行数据访问特征分析,并结合片外内存访问带宽、片上网络结构、片上可用面积、整体功耗控制等条件开展平衡设计。
2)软件设计层面。从编译优化角度来看,可以对应用程序核心数据容量、数据访问粒度和重用情况开展分析,并建立好的访存收益评估模型,为数据分配合理的实际地址空间(SPM 或者主存)以及为主存数据访问选择高效的传输方式(DMA、RMA、Cache 模式);在编程语言设计角度,可以为专家级用户提供显式的存储层次描述手段,方便用户直接控制核心数据的布局与传输,或者指导编译器开展相应的编译优化与程序变换工作,从而提升众核片上存储层次的易编程性与高效性;在编程框架设计角度,可以针对领域应用特征,开发多平台统一的编程框架接口,底层针对不同的众核处理器片上存储层次特点,开展具体的优化实现,从而提升应用面向不同片上存储结构的性能可移植性;在运行时支撑库的角度,应该针对目标平台的存储层次特点开展领域典型算子库的设计与实现,为应用程序开发提供平台相关的高效API 接口支撑。
3)算法与程序设计层面。就HPC 用户层面而言,需要针对具体的目标平台上的存储层次特点,结合应用核心运算特征,开展高效的众核并行算法模型设计。并行算法模型需要根据应用的核心任务数据量和访问特征研究线程间无关并行、线程间流水并行、基于共享内存或片上通信的多线程协同并行、主从异步并行等方式,再基于具体的并行模式开展数据布局与传输方案设计。而应用程序级的优化则需要结合目标平台众核片上存储层次的具体特点,比如SPM 的容量大小、共享范围、访问带宽和延时,再进一步结合程序核心循环的数据访问方式、数据量等开展数据布局优化、SPM 数据重用优化、批量数据传输优化、基于SPM 缓冲的数据传输与计算重叠优化等,从而使应用程序能够更好地发挥出存储层次的优势,提升应用效率。
5 结束语
本文阐述了3 类常见的片上存储结构及特点,分析了国际主流GPU、同构众核及国产众核等面向主流E 级超算系统的众核处理器片上存储层次设计现状与发展趋势,并总结了国际上的存储层次设计与优化相关软硬件技术的研究现状。后续将针对具体的应用领域,对应用获得的性能与片上存储结构类型及各种结构参数的定量关系方面开展研究,从而为众核片上存储层次的软硬件设计给出更具体的参考依据。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
汽车工程(2021年12期)2021-03-08
电信科学(2017年6期)2017-07-01
燕山大学学报(2015年4期)2015-12-25
电测与仪表(2015年22期)2015-04-09
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
