
基于深度Q网络的5G网络优化方法
2023-12-14 11:10于星辉
通信电源技术 2023年19期
于星辉
(郑州工业应用技术学院,河南 郑州 451100)
0 引 言
随着信息通信技术的飞速发展,5G技术作为当今通信领域的前沿技术,具有极高的数据传输速率和超低的传输时延,支持大规模设备连接,为各类应用场景提供支持与保障[1-2]。与5G技术的广泛应用相伴而生的是网络资源的快速消耗和复杂的环境变化,给5G网络的优化与管理带来了前所未有的挑战[3-4]。
通过引入人工智能技术,能够提升5G网络性能并改善其自愈能力。首先,研究了5G网络的基本架构,并分析了其关键组成部分和各类网络节点之间的通信机制,以便全面了解5G网络的运行机制与特性。其次,深入分析深度Q网络(Deep Q-Network,DQN)的结构与原理。DQN作为一种强化学习方法,为优化5G网络性能提供了潜在的解决方案[5]。再次,提出基于DQN的5G网络自愈能力的实现方案。通过引入强化学习算法,结合5G网络中的状态空间、动作空间、奖励机制,使5G网络具备网络自动调整与优化的能力。旨在通过智能化决策,提升5G网络对环境变化和异常情况的适应性,从而提升网络的可靠性与稳定性。最后,进行了一系列的实验与测试,以验证所提方法的有效性与性能。通过在5G网络环境下的模拟实验,评估方案在不同场景下的性能,为5G网络的优化提供实证支持。
1 5G网络基本架构
5G网络的基本架构是一个高度复杂的生态系统,由多个关键组成部分构成,包括基站、承载网、电信机房、骨干网络、接入网以及核心网等。5G网络基本架构如图1所示。
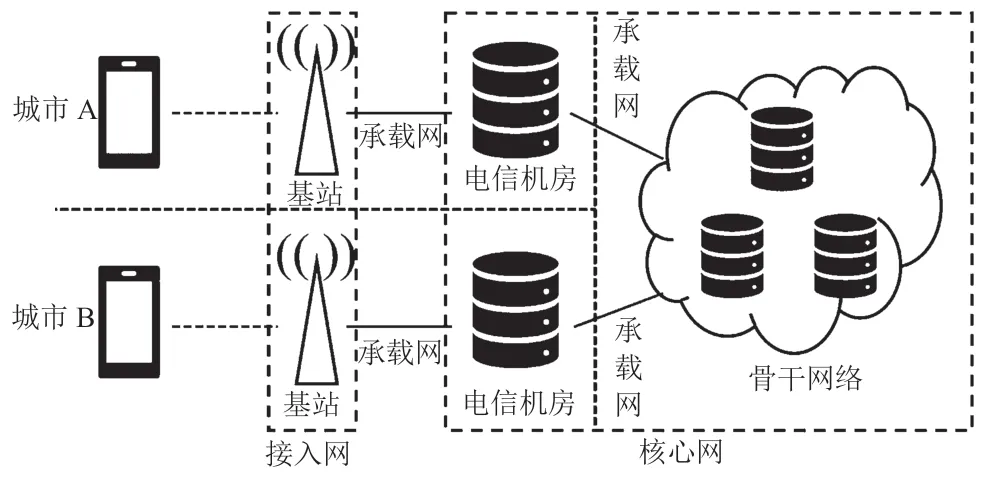
图1 5G网络基本架构
5G网络基本架构的核心组件之一是基站,负责传输和接收无线信号,将用户设备(如智能手机)连接到5G网络。5G网络引入了多种类型的基站,包括宏站、微站、室内小站以及边缘计算站,以满足不同的覆盖范围和容量需求。接入网是连接用户设备和基站的部分,通常由多个基站连接到接入点,负责将用户设备的数据流引到核心网络,起到数据的集散功能。承载网是负责承载数据传输的网络层,通常由光纤和高速传输线路构成。承载网负责高效、可靠地传输数据流,以确保数据在网络中的高速传输。电信机房是5G网络的关键组成设施,用于托管网络设备、服务器和数据中心,连接核心网络和接入网络。骨干网络是5G网络的主要传输网络,负责将数据从基站传送到核心网络。通常由高速光纤、光缆、路由器组成,以实现快速、高容量的数据传输。核心网是5G网络的智能中枢,具备处理网络管理、鉴权、安全性以及服务控制等功能。同时承担着数据的路由和传输,以确保数据流从源到目标的快速传输,能够实现复杂的通信服务,如视频流、基于IP的语音传输(Voice over Internet Protocol,VoIP)通话等。
2 基于DQN的自愈能力研究
2.1 DQN架构
DQN是一种强化学习算法,用于训练智能体,使智能体能够在与环境的交互中选出最优策略。智能体是DQN的主体,代表需要学习和做出决策的实体,通常指一个神经网络模型。环境是智能体的操作背景,包含智能体所处的情境、可供智能体进行操作的状态和动作。智能体通过观察环境的状态来获取信息,这些状态是环境的描述,通常以向量或张量的形式呈现。状态是环境的内部表示。智能体不能直接观察到状态,但会对其行为和决策产生影响。智能体根据观察到的状态选择一个动作,这个动作会对环境产生影响。每次智能体执行一个动作后,环境会返回一个奖励信号,用于评估动作的好坏,正奖励表示积极的动作,负奖励表示消极的动作。DQN基本结构如图2所示。
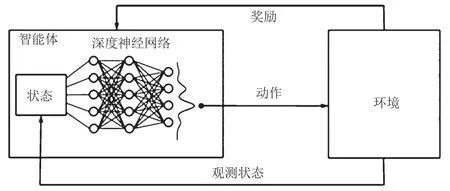
图2 DQN基本结构
该网络的目标是让智能体学到一个最优的策略,使其能够长期累积奖励。通过不断的学习和改进,可以逐渐提高网络性能,以适应不同环境和任务。这种基于奖励的强化学习方法得到了广泛的应用,包括游戏、自动驾驶和机器人控制等领域。第一,智能体通过观察当前的状态,使用一个深度神经网络(Dynamic Neural Network,DNN)来估计动作价值。DNN被称为Q网络,即将状态作为输入,输出每个动作的预期累积奖励(即Q值)。第二,智能体根据一定的策略选择一个动作,通常会使用ε-贪心策略。即以ε的概率随机选择动作,以1-ε的概率选择具有最高Q值的动作。第三,智能体执行所选动作,并观察下一个状态和环境返回的奖励。第四,通过深度学习中的优化算法,使用观察到的奖励来更新Q网络,以减小实际奖励和预测奖励之间的差距。第五,重复上述步骤,不断与环境互动、学习和优化策略,以最大化累积奖励。
2.2 基于DQN的优化方案设计
基于DQN的5G网络自愈能力的实现,需要采用马尔可夫决策过程(Markov Decision Process,MDP)。MDP是一种数学模型,由5个元素组成,即5元组(S,A,P,R,γ),MDP组成元素及其含义如表1所示。

表1 MDP组成元素及其含义
DQN通过建立一个Q函数,用于估计每个状态-动作对的累积奖励。Q函数的更新过程基于Bellman方程,即
式中:Q(s,a)表示在状态s下采取动作a的Q值,即预期累积奖励;R(s,a)表示在状态s下采取动作a后所获得的即时奖励;γ表示折扣因子用于衡量未来奖励的重要性;s'表示由状态s采取动作a后得到的下一个状态;a'表示在s'下选择的最佳动作。
DQN的目标是通过训练神经网络来逼近Q函数,使其预测的Q值尽可能接近Bellman方程右侧的最大值。使用均方误差(Mean Squared Error,MSE)损失函数Loss来衡量Q值的预测误差,公式为
式中:E表示数学期望。
通过利用最小化损失函数,DQN的神经网络逐渐学习并优化Q值,以达到在不同状态下选择最佳动作,实现最大化累积奖励的目标。
3 实验与分析
3.1 实验设计
采用模拟数据对DQN模型进行训练和测试。第一,数据收集。使用网络仿真工具,如Ns-3或OMNeT++,创建一个虚拟的5G网络环境,并收集仿真数据。Ns-3和OMNeT++是用于网络仿真和模拟的开源工具,用于研究和开发网络协议、通信系统和分布式系统。第二,数据预处理。对采集的原始数据进行预处理,包括数据清洗、特征工程、归一化等。其中,数据清洗用于去除可能存在的异常值或噪声;特征工程用来选择和构建适当的特征,方便后续进行建模和分析;数据归一化能确保数据在相同的尺度范围内。第三,构建环境。模拟5G网络的环境,包括状态空间、动作空间、状态转移概率函数以及奖励函数等。其中,状态空间涵盖各种可能的网络状态;动作空间定义了可供智能体选择的操作;状态转移概率函数描述了在给定状态下采取动作后的下一个状态的概率分布;而奖励函数则用于评估每个动作的优劣。第四,建立DQN模型。包括神经网络的结构、层数、激活函数等。本次采用深度学习框架TensorFlow来搭建模型。第五,训练DQN模型。使用数据集中的样本来训练DQN模型。在训练周期中,智能体与模拟环境进行交互,并根据当前状态选择动作,接收奖励信号;同时使用损失函数来更新模型参数,使Q值逼近Bellman方程右侧的最大值。第六,模型评估。在训练过程中,需要定期对模型进行评估以了解其性能。即评估模型在测试数据集上的性能,观察其在不同状态下采取动作的效果和累积奖励的变化情况。
3.2 结果与分析
为了验证文章所提方法的有效性,做了4个不同的实验,以测试基于DQN的5G网络自愈能力模型的性能,测试结果如表2所示。
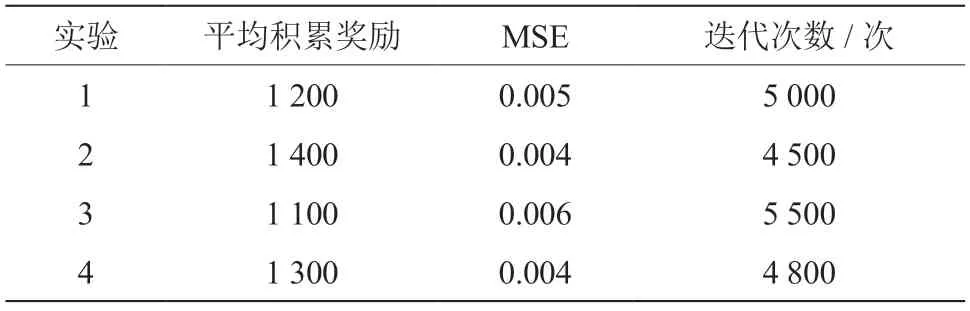
表2 实验结果统计
由表2可知,实验2获得的平均累积奖励最高,表明该模型在各种状态下选择动作以最大化奖励表现出较好的性能;MSE表示实验模型的最终性能,用于衡量Q值的预测精度,实验2与实验4的最终性能最低,表明其在估计Q值方面具有较高的准确性;迭代次数表示模型达到稳定性能所需的训练次数,相比之下实验2的收敛周期最短,表明该模型能更快地学习并提高性能。因此,实验2对应的模型是一种较为有效的5G网络自愈能力模型,可以用于优化5G网络性能。同时,需要进行进一步的研究和测试,以验证模型的可靠性和健壮性。
4 结 论
文章提出了一种基于DQN的5G网络优化方法,通过深入研究5G网络的基本架构和应用强化学习的原理,成功地建立了一个具有潜在应用前景的DQN模型,用于提升5G网络的性能和自愈能力。实验结果表明,该模型在累积奖励和Q值的准确性等方面,表现出优良性能。同时,需要相关研究人员作进一步的研究和实验,以验证该模型的可靠性和健壮性。
猜你喜欢
家庭影院技术(2019年8期)2019-08-27
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
少年博览·小学低年级(2017年4期)2017-06-09
家庭百事通(2016年3期)2016-03-14
山东青年(2016年3期)2016-02-28
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
少儿科学周刊·少年版(2015年4期)2015-07-07
