
基于数据挖掘的电量异常数据智能识别方法研究
2023-12-14 12:16石云辉卢启芳
自动化仪表 2023年11期
杨 婧,石云辉,卢启芳
(贵州电网有限责任公司计量中心,贵州 贵阳 550000)
0 引言
电量异常数据会导致电网系统中的数据出现较大变化,对电网稳定运行产生直接影响,因此应避免电量异常数据产生。而电网异常数据识别是避免电量异常数据产生的主要技术[1-3]。
针对电量异常数据问题,有学者采用大数据技术建立电量异常数据识别模型[4]。该模型采用大数据挖掘Spark模块采集和处理电表数据;制定了表码和电量异常数据判定规则;采用大数据直线差值拟合表码,生成异常数据预警结果。有学者在电量异常数据风险识别过程中引入了概率预测模型[5]。该模型基于状态空间模型建立用电量结构化模型;采用变分贝叶斯推断模型进行用电量的概率分布预测,根据预测标准分数实现异常数据的在线识别。以上电量异常数据智能识别方法存在未对识别指标进行降维处理、异常识别指标不合理、使用的识别算法容易陷入局部最优的问题,导致识别准确率较低,难以满足电量数据安全管理的实际应用需求[6-8]。
数据挖掘算法可以从电量异常数据的历史数据中寻找电量异常数据的变化规律[9-11]。为了解决电量异常数据识别结果不准确的问题,本文设计了基于数据挖掘的电量异常数据智能识别方法。本文设计识别流程,构建异常识别指标体系;创新性地采用主成分分析算法对识别指标进行线性组合降维处理,构建合理性更高的异常识别综合指标;基于相关系数矩阵,采用数据挖掘算法确定指标权重;使用数据挖掘技术中的模糊C均值算法进行电量异常特征聚类,融合径向基神经网络构建异常识别模型,以提高算法识别的寻优效果、实现电量异常数据智能识别。本文通过仿真试验分析电量异常数据智能识别效果。试验结果表明,本文方法能得到较高的电量异常数据智能识别正确率,提高了电量异常数据的智能识别效率。
1 电量异常数据智能识别
1.1 识别方法的工作流程
基于数据挖掘的电量异常数据智能识别方法流程如图1所示。
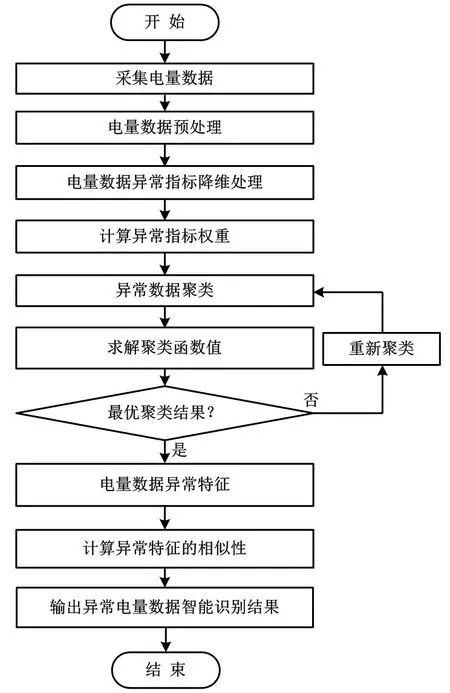
图1 电量异常数据智能识别方法流程图
图1流程首先构建电量异常数据识别指标体系,采集相关指标数据,并对数据实施数据清洗、缺失补全以及结构转换等预处理;然后采用主成分分析算法对电量异常数据指标进行降维处理;最后使用数据挖掘技术,根据降维处理后的数据建立电量异常数据识别模型。
1.2 建立智能识别指标
本文获取待识别电量数据,设定电量异常标准值,构建电量异常数据识别指标体系。电量异常数据智能识别指标如表1所示。

表1 电量异常数据智能识别指标
1.3 识别指标预处理
电量异常数据识别过程需要分析指标之间的关系。电量异常数据识别指标的主成分分析流程如图2所示。

图2 主成分分析流程图
本文采用主成分分析算法对初始电量异常数据识别指标实施线性组合,以构建新的电量异常数据识别综合指标。F1表示第一主成分,可令电量异常数据识别综合指标的方差足够大。由于方差同F1内所含信息之间成正比,在全部线性组合内选取F1方差最大的指标。如果F1无法描述初始指标包含的全部信息,选取第二个线性组合F2,将其定义为第二主成分。循环上述过程能够获取p个彼此间不具备关联性的主成分。这些主成分的方差依次递减。在实际电量异常数据识别过程中,一般选取前几个方差最大的主成分。这样就减少了电量异常数据识别模型的输入,提升了电量异常数据识别方法的工作效率。
1.4 识别指标权重确定
电量异常数据识别指标权重确定步骤如下。
①读取初始电量异常数据识别指标,对其实施标准化处理后,对指标数据进行统计量检验、球形检测。这2种检测均以相关系数矩阵为基础。统计量检验的取值范围为[0,1],其值越大,表示电量异常数据识别指标越优。球形检测需进行相关系数矩阵与单位矩阵间的相关性分析。若指标样本数据检验结果为0.001,代表异常指标间具有相关性。
②确定模型主成分特征值及其贡献率,选取特征值大于1%的若干个主成分构建评价指标。
③利用数据挖掘法实施因子旋转,获取因子载荷矩阵。根据因子载荷矩阵数据,构建电量异常数据智能识别主成分因子模型,计算不同主成分贡献率的乘积。
④评价一致性矩阵。根据计算权重,评价一致性矩阵为:
R=(txy)n×n
(1)
式中:txy为模型主成分特征值x和y的贡献率,%;n×n为因子载荷矩阵。
对评价一致性矩阵进行规范化处理,则:
(2)
式中:Rmax和Rmin为权值指标的最大值和最小值;u为因子旋转系数。
⑤数据挖掘方法根据计算权重设定关联规则,建立电量异常数据智能识别模型。
1.5 电量异常数据识别模型
本文使用数据挖掘技术中的模糊C均值算法实现电量异常特征聚类。本文采用X={x1,x2,…,xn}表示异常指标样本。其聚类中心及模糊分类矩阵分别用C=[c1、c2,…,cc′]T、A=[aij]c′×n描述。模糊C均值算法的表达式如式(3)所示。
(3)
式中:n为异常指标j的数量;c为聚类中心;c′为c的数量;aij为指标j的聚类隶属度。
聚类数量的最优结果可通过模糊聚类有效性指标函数获取,用Vx描述:
(4)
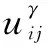
Vx的值越小,聚类结果越优。本文以最优聚类结果为基准,通过分类提取出与异常特征聚类中心最接近的电量数据,从而获得电量异常数据特征。
本文利用数据样本与异常特征的相似性,通过正态分布理论确定识别阈值,以识别电量异常数据。
待识别的电量数据集合用P描述。其隶属类的特征用Q描述。P中的某识别样本为p={1,2,…,k},相似性对比因数用y1描述:
y1(p)=P(p)-Q(p)
(5)
异常数据相似性特征符合式(6):
(6)
式中:δ1为y1的均方差;E1为δ1的均值;θ1为相似性识别阈值。
若电量数据符合式(6),则该数据为异常数据。
为了保证异常识别结果的准确性,本文使用径向基函数(radial basis functions,RBF)神经网络构建异常识别模型,对样本集进行训练,以增强模型的识别能力,从而获得相似性识别阈值内的最优识别结果。
RBF神经网络输出结果用式(7)描述:
(7)
式中:wik为连接权值向量;s为输出节点k的数量;Ri(k)为RBF。
为了获得最优值,需增加计算节点数量。各节点构建RBF神经网络,将训练样本均分给各节点实现并行处理,以训练各节点的RBF神经网络。为了提高训练准确率,需优化连接权值向量。优化后的连接权值向量为:
(8)
式中:αi′为节点i′对于全部节点所占比重;wi′为节点权重;m为节点数量。
2 仿真测试
本文采用某市电网18个电量数据采集节点作为研究对象,并将其分别命名为M01~M18。节点分布式环境采用Hadoop框架配置。仿真平台为多个节点组成Cluster,搭建Hadoop节点集群,集群通信基于多点接口(multi point interface,MPI)库实现。电量数据集选择该市电网公司这18个节点的开放数据集数据样本(共53 GB),写入Hadoop分布式文件系统(Hadoop distributed file system,HDFS)中。仿真环境配置如下:网络环境为DDR 20 GB Infiniband;单节点内存为6 GB;节点连接网络为天河-1A;MPI版本为MPICH-2;处理器为Intel Xeon 64 2.33 GHz;操作系统为Centors 7.0;Hadoop版本为Cloudera Hadoop 5.0。
测试过程为:按照设计的识别流程,构建指标体系;对原始数据进行预处理,采用主成分分析算法对识别指标进行线性组合降维处理;利用数据挖掘算法确定指标权重(贡献率)并进行指标排序;使用数据挖掘技术中的模糊C均值算法进行电量异常特征聚类,利用RBF神经网络构建异常识别模型;设定相似度识别阈值,通过模型训练获得最优识别结果。本文分别通过指标贡献率、识别准确性和识别效率测试本文方法的应用性能。
2.1 主成分分析结果
本文以M16为识别对象,对其进行电量异常数据识别。21个评价指标主成分特征值的贡献率如图3所示。

图3 评价指标主成分特征值的贡献率
由图3可知,主成分特征值的累计贡献率达到92.087%。这说明主成分分析能够体现识别指标的信息,有效实现降维。
2.2 电量异常数据识别结果
本文采用本文方法对18个对象进行电量异常数据智能识别,并进行排序。各研究对象电量异常数据识别结果如图4所示。

图4 各研究对象电量异常数据识别结果
本文将电量异常数据相似度识别阈值设定为-0.253~-0.185,取这2个数值的均值,即电量异常数据的识别阈值分界点设定为-0.219。分析图4可知,M17~M11不存在电量异常数据,而M13~M04具有一定的电量异常数据。这说明本文方法能够识别各种电量异常数据。
2.3 识别准确性分析
本文将本文方法和文献[4]方法识别出的电量异常数据与实际情况进行对比,以分析电量异常数据识别准确率。电量异常数据识别准确率结果如图5所示。
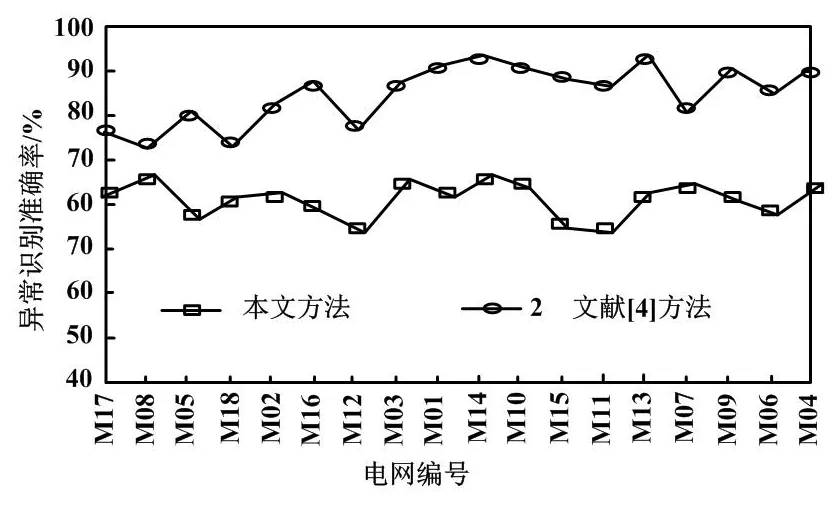
图5 识别准确率结果
由图5可知,本文方法识别准确率高于70%,而文献[4]方法的准确率低于70%。这说明采用本文方法对电量异常数据进行识别的准确性较高。
2.4 识别效率分析
本文进行异常识别效率测试。本文选择3个电量数据集作为测试对象。各数据集大小分别为1.56 GB、1.89 GB、2.01 GB。数据条数均为700条。本文对不同数据条数下数据识别效率进行测试。数据识别效率的测试结果如图6所示。

图6 数据识别效率的测试结果
由图6可知,本文方法对3个试验数据集的识别时间均较少。其中:数据量为1.56 GB的试验数据集的识别时间平均为402.32 ms;数据量为1.89 GB的试验数据集的识别时间平均为543.25 ms;数据量为2.01 GB的试验数据集的识别时间平均为596.32 ms。综上分析可知,本文方法的数据识别速度快,具有良好的识别效率。
3 结论
针对当前电量异常数据智能识别过程存在的问题,如识别时间长、错误率高等,本文设计了基于数据挖掘的电量异常数据智能识别方法。该方法采用主成分分析算法对识别指标进行降维处理,构建异常识别综合指标;利用数据挖掘算法确定指标权重;创新性地融合模糊C均值算法和RBF神经网络构建电量异常数据识别模型,实现电量异常数据智能识别。试验结果表明,本文方法能够准确识别不同电网数据异常现象,为电力数据安全管理提供支持。本文方法具有十分广阔的应用前景。
猜你喜欢
学苑创造·B版(2022年9期)2022-05-30
大众投资指南(2021年35期)2021-02-16
四川水力发电(2018年4期)2018-03-25
电子测试(2017年15期)2017-12-18
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
铁道通信信号(2016年8期)2016-06-01
信息通信技术(2015年6期)2015-12-26
电子设计工程(2015年6期)2015-02-27
电测与仪表(2014年16期)2014-04-22
