
互联网社交平台舆论趋势预测算法研究
2023-12-12 11:30王海兮吴喆熹马军
应用科技 2023年6期
王海兮,吴喆熹,马军
中国电子科技集团公司第三十研究所,四川 成都 610041
2022 年7 月Facebook 的月活跃用户数为29.34 亿,是全球最活跃的社交媒体平台,Twitter平台紧随其后。 本文以全球主要舆论平台为研究对象[1],通过分析其特定话题下的舆论趋势,识别舆情传播关键节点、预测舆论未来走向,能够为把握国际舆情走势、认清国际舆论环境提供重要支撑。
舆论趋势预测通常从舆情分析入手,预测未来网民观点立场变化。然而由于社交媒体活跃用户量大、涉及内容数据多以及社交网络本身异构性、舆情发酵多变性等因素众多,预测结果往往精度不高。在舆情分析中,主要通过话题检测分析、基于内容的情感分类分析等技术实现网络舆情的监测。张君第[2]通过获取言论信息,利用基于词向量的神经网络模型对 Twitter 帖子情感进行分类,实现对舆情的监测;刘纯嘉[3]在面向高校舆情的中文文本情感倾向性分析时,提出融合汉字形态学特征和HowNet 的文本情感分类方法和一种基于注意力胶囊网络的文本情感分析方法;岳亚南[4]在研究面向舆情文本的情感倾向性分类时,针对现有深度学习方法词性信息利用不充分问题,提出了一种融合词性和自注意力机制的情感倾向性分类模型。在舆情趋势预测分析中,刘定一等[5]提出了融合微博热点分析和长短期记忆神经网络的舆情预测方法,采用网络热点分析技术计算微博热度分值并预测未来热度值。彭思琪等[6]将评论文本的情感值作为演变预测的对象,利用情感词和舆情事件中评论文本的语义相似度,对情感时间序列进行预测,能较好地实现舆情事件中评论文本的情感演变预测。
基于以上调研和分析发现,舆情分析和趋势预测的分析和判断大多是分析帖子情感倾向[7],并对情感倾向性进行预测[8]。本文拟通过构建基于话题发帖内容、评论账号属性和评论内容等信息的舆论趋势走向预测神经网络模型,从用户社交账号针对特定话题的观点立场分析入手,设计一种基于量化计算的舆论场趋势预测分析方法,预测用户社交账号立场观点趋势变化值,得到舆论趋势走向拐点,实现对舆论趋势的精确预测。
1 舆论趋势预测算法总体思路
传统舆论趋势分析的方法[9-12]通常是基于用户社交影响力构建传播评估模型,以用户间影响力判断信息能否传播,从而分析舆论趋势变化,通过用户间历史交互行为关系、信息传播关系挖掘关系扩散特征,构建传播评估模型,分析舆论趋势。该方法并未综合考虑信息内容、主题匹配度等因素对舆论趋势变化的影响,因此对舆论趋势预测考虑不够全面。
为了解决如何对特定主题实现有效舆论走向判断的问题,本文构建了舆论趋势预测算法。其技术构思是通过分析特定话题的所有评论用户立场以及立场趋势变化,综合利用社交账户人物画像、个体言论内容、主题内容等特征,量化分析以上因素对舆论走向的影响度,构建舆论趋势走向预测模型,最终实现特定话题下舆论走向的有效预测。本技术方案的总体流程如图1 所示。
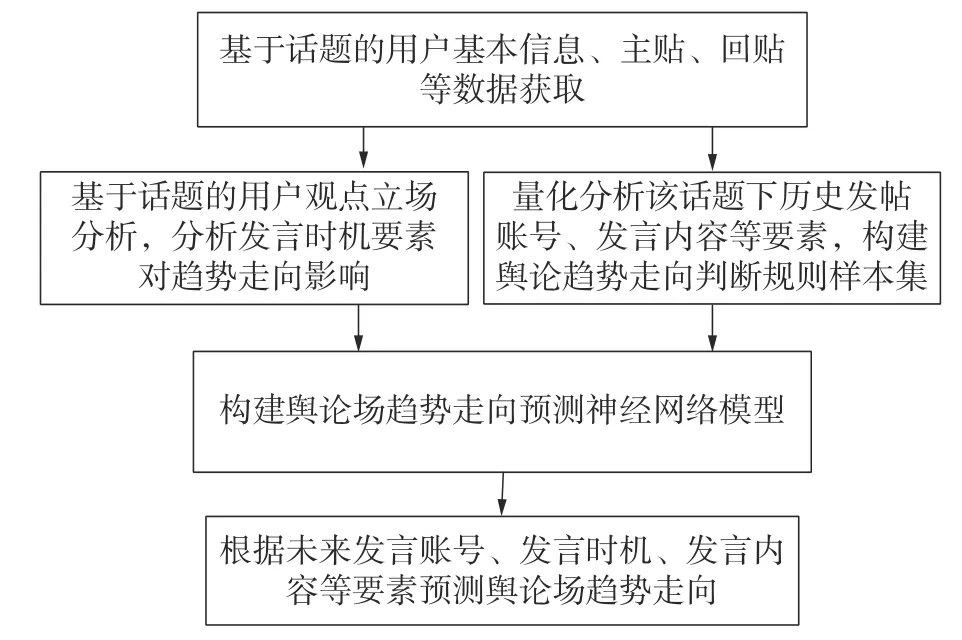
图1 舆论趋势预测总体技术方案
2 基于话题的用户数据获取
数据是一切分析的基础,本文研究的舆论趋势预测算法需要根据特定话题,获取社交平台下该话题的主贴内容、评论内容以及评论账号基本信息等。话题是指用户发帖时讨论的共同主题,以Facebook 平台为例,可以通过话题标签搜索出所有讨论该话题的帖子。Facebook 话题标签是随话题或短语输入 #(数字符号),并将其添加至帖子中的短语,Facebook 话题标签示意见图2。
确定特定话题后,在Facebook 社交网络平台根据话题关键词搜索帖子,基于Scrapy 爬虫框架构建网络爬虫。通过已有账号资源,利用RabbitMQ 实现多节点分布式数据采集,采集与话题相关的主贴以及评论内容,包括发表言论的社交账户基本信息、行为信息、内容信息等,作为进行用户观点立场分析的基础数据。
3 基于话题的用户观点立场分析
基于获取的基础数据进行用户立场检测,并开展立场趋势变化分析。本文的用户立场检测主要是针对当前话题,检测帖子评论者的用户立场,立场分为对该话题支持、反对、中立3 种态度。
传统的立场检测技术通常将发文内容与主题内容的一致性作为重点考量对象,通过判别一致性分析发文者所持立场。然而该技术在复杂多变的实际场景中分析效果欠佳。
词向量技术已广泛应用于文本语义提取[13],本文经过对互联网社交平台评论内容和评论用户属性分析发现,评论用户本身所属阵营对其立场影响作用不可忽视,可作为用户观点立场分析的一个因素。因此本文提出在构建立场分析模型时,分析获取评论用户属性信息,分析其所属阵营,形成外部知识,再结合评论内容、话题内容提取语义进行综合分析,最终实现评论内容立场检测。其实现的运行逻辑分为以下3 个步骤:
1)观点挖掘模块从文件系统提取“文本数据”,而后根据预先设定的字典将文本中的文字和文字在字典中对应的数字进行映射,即Token 化,然后逐条输入至Pre-trained StBERT 模型,通过多个Transformer 层学习到文本信息的抽象表示。
2)将数字序列输入已预训练好的StBERT 模型,即Pre-trained StBERT,得到数字序列的特征表示,而后取这一特征表示以及特征化后的用户所属阵营信息,共同输入至Softmax 分类器进行立场识别,立场分为赞同、中立、反对3 种,分别对应分值1,0,-1。
3)通过Softmax 分类器形成1 个三元组数值,分别表示赞同、中立、反对对应的概率,概率最高的即为该文本针对某一主题的实际观点,最后将立场分值附加到最初的文本数据后面,形成“文本+立场”的新的数据结构。
用户观点立场检测通过自然语言处理技术,构建多因素的分类模型,立场检测原理如图3 所示。通过分类模型分析出当前评论文本内容对话题的立场倾向是“支持”、“反对”还是“中立”,分析原始数据样例如图4 所示,最后一列label 是给当前评论定义的立场。

图3 用户立场检测原理
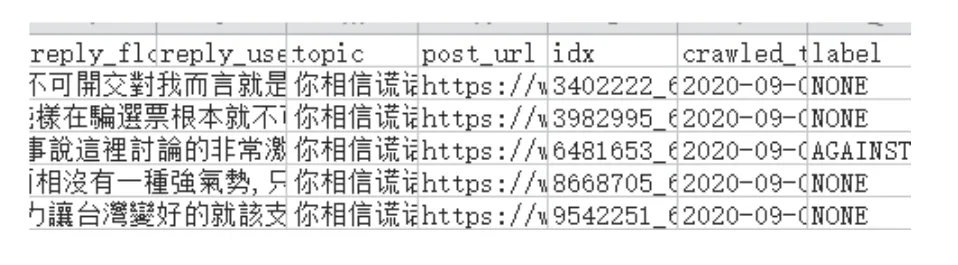
图4 原始数据样例
分析单个评论的立场后,需要对立场人数总体占比进行统计,而后构建立场趋势预测模型,实现对立场占比趋势变化进行预测。立场占比是对该主题下所有评论的立场趋势分析,为某时间段归属于某立场的帖子数与某时间段的总帖子数的比值,立场占比趋势如图5 所示。其趋势变化实现逻辑为各立场支持的评论帖子分析立场后,加入各立场集合。当有新用户评论时,根据其所持观点加入对应集合;当已发言用户再次发言,如所持观点不变,则集合不变,如所持观点改变,则在原集合中删除该人员,添加到其所持新立场的人员集合。

图5 各立场人数占比随总发帖量的趋势变化
4 构建舆论趋势走向判断规则样本集
由于影响立场趋势变化的因素非常多,且大多是定性的分析,因此构建趋势预测模型最大的挑战是如何定量分析影响趋势变化的因素。本文构建了影响趋势变化的样本特征,并根据特征重要程度构建了样本打分机制,实现了影响因素的定量分析;而后可以根据构建的样本作为语料,用于舆论趋势预测模型的训练。
根据前期分析,影响趋势变化的因素包括话题发帖内容、评论账号属性和评论内容3 个。评论内容特征是根据bert_sentence 模型输出,该模型由bert 模型经过下游语言任务(情感分类等)大量语料样本训练而成。这里将评论中的发文内容输入bert_sentence 模型,输出是768 维的语义向量,表征评论内容的语义。同时也将话题发帖内容输入模型,得到768 维语义向量,表征话题以及立场。评论账号特征包括账号基本属性、行为属性等12 维,最后的样本特征是由评论账号特征特征(12 维)、发文内容语义特征(768 维)、话题语义特征(768 维)组成,我们通过样本特征计算出样本分数作为训练样本,构建舆论趋势走向预测模型,具体步骤如下。
1)趋势平滑。对各立场人数占比随总发帖量的变化的趋势曲线进行Savitzky-Golay filter 平滑[14],使用最小二乘法将数据的一个小窗口回归到多项式上,然后使用多项式来估计窗口中心的点,最后窗口向前移动一个数据点,重复这个过程。这样继续下去,直到每个点相对于邻居都进行了最佳调整,如图6 所示。
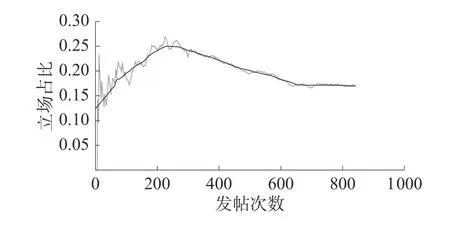
图6 趋势图曲线平滑示意
2)趋势图曲线拐点检测[15]。采用基于滑动窗口算法,该方法依赖于单个变化点检测程序并将其扩展以找到多个变化点。算法实施时,2 个相邻的窗口沿着信号滑动,计算第一窗口和第二窗口之间的差异。当这2 个窗口包含不相似的片段时,计算得到的差异值将会很大,检测得到一个拐点。在离线设置中,计算完整的差异曲线并执行峰值搜索过程以找到拐点索引。对平滑后的趋势曲线进行拐点检测标注,如图7 所示。
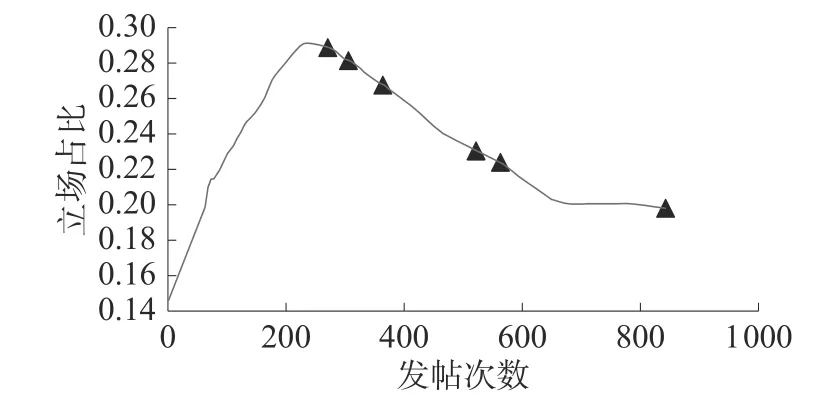
图7 平滑曲线拐点检测示意
3)趋势段选取[16]。基于图7 的趋势曲线标注的拐点,计算曲线中上升幅度最大的一段作为样本提取出来,与该趋势曲线同立场的评论标注为正样本,其他立场的评论标注为负样本,遵循此规则给各评论打标签。此标签作为趋势影响力得分的考量,如图8 所示。
图8 趋势段选取示意
样本趋势走向判断规则由某个评论社交账户基本信息得分和本次评论社交账户对立场趋势影响力得分2 部分构成。人物画像得分Suser计算方法为
式中:Sproperty为人物账户属性得分,包含粉丝量、发帖量等;wproperty为基本属性权重比例;Sbehavior为行为属性得分;wbehavior为行为属性权重比例。
样本得分Sfinal计算方法为
式中:Slabel为本次评论社交账户对立场趋势的影响力得分,Wlabel为趋势影响力得分权重比例,Wuser为人物账户属性权重比例。其中Slabel得分规则如下:本次评论成功影响了一位其他立场人员的评论,该评论得4 分;本次评论成功增加了本立场人数,该发言得3 分;本次评论未能增加本立场人数,该评论得2 分;本次评论使本立场人数降低,该评论得1 分。
5 构建舆论趋势走向预测神经网络模型
舆论趋势的变化是非常前沿且发散的问题,其包含的影响因素多且广。神经网络模型具有高复杂性,能够拟合高维复杂函数,所以在此选择神经网络模型作为舆论趋势预测模型。
模型输入特征有3 部分内容:人物账户属性特征、评论内容语义特征和主题立场语义特征。针对任务账号属性特征分析,由于人物账户属性特征多由人工挖掘定义,在分析时为了覆盖面广、不遗漏,会尽量考虑多维度构建特征,但在特征建模时可能会产生一些冗余特征,这部分冗余特征对结果贡献度不高,但增加了维度,加大了计算量,所以需要进行特征筛选,根据各特征重要程度剔除冗余特征。人物账户属性特征的筛选通过进行机器学习xgboost 的模型训练,根据各特征重要程度选择。随机划分样本,将80%样本作为训练集,20%样本作为测试集,训练机器学习xgboost 模型,输出特征重要程度,如图9 所示,以此作为依据进行人物账户属性特征选择。
评论内容语义特征是根据bert_sentence 模型输出,该模型由bert 模型经过下游语言任务(情感分类等)大量语料样本训练而成。这里将评论内容输入bert_sentence 模型,输出是768 维的语义向量,表征评论内容的语义。同时也将主题立场内容输入模型,得到768 维语义向量,表征主题以及立场。人物账户属性特征包括行为热度、关系热度、好友数、潜水值、性别等数值特征。最后的样本特征是由人物画像特征(12 维)、发文内容语义特征(768 维)和topic/label 语义特征(768 维)这3 部分构成。这3 部分特征维度不尽相同,目前能够处理多领域信息的有推荐系统中的DSSM 双塔模型,通过参考该模型架构,根据3 部分输入的内容维度进行神经网络模型结构构造,提出了一种舆论趋势走向预测神经网络模型(trend forcast neural network,TFNN),经过2 层全连接层加上1 层激活层后,将3 部分进行concat 操作,再经过全连接层加激活层,其原理结构如图10 所示。
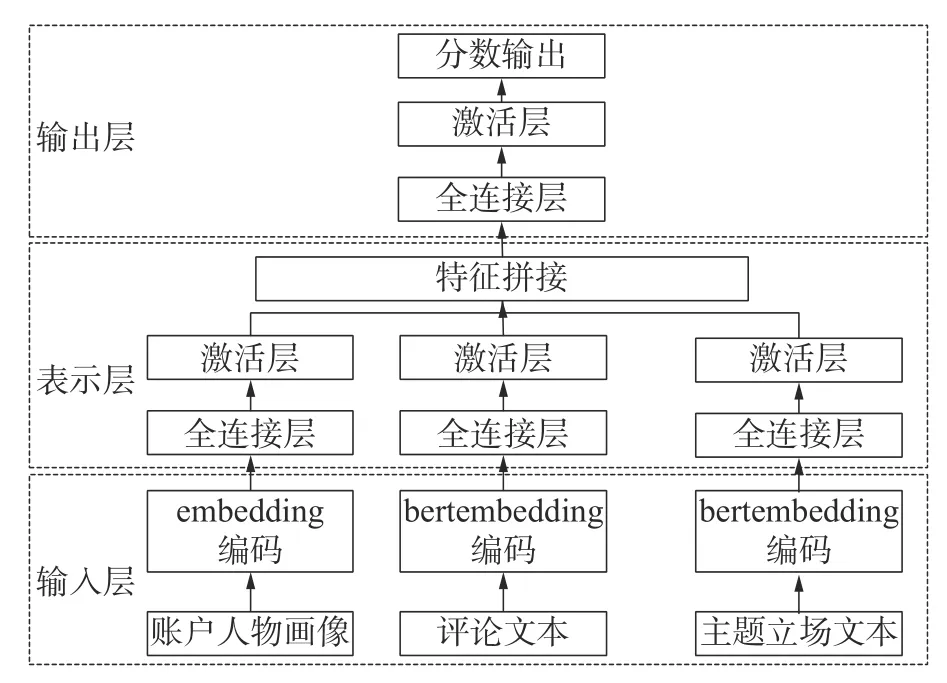
图10 TFNN 模型结构示意
TFNN 模型经过训练后,均方误差(mean squared error,MSE)为 0.144,均方对数误差(mean squared log error,MSLE)为 0.018,均方根对数误差(root mean squared logarithmic error,RMSLE)为0.136,均方根误差(root mean squared error,RMSE)为 0.380,平均绝对误差(mean absolute error,MAE)为 0.216,平均绝对百分比误差(mean absolute percentage error,MAPE)为 0.165,绝对误差中位数(median absolute error,MedianAE)为 0.152,绝对百分比误差中位数(median absolute percentage error,MedianAPE )为0.125。训练中各指标随训练代次(iteration)变化过程如图11 所示。
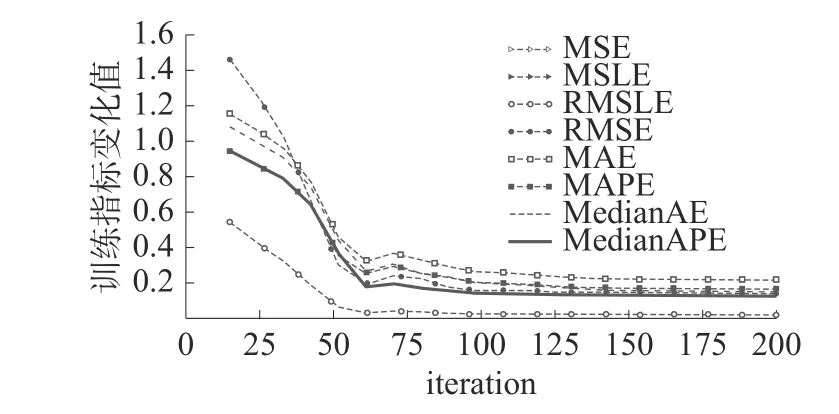
图11 TFNN 模型训练过程指标变化
6 结束语
本文研究的舆论趋势预测算法,通过综合考虑评论内容、主题、评论账户属性等多种因素,制定了样本舆论趋势判断规则,同时提出了一种新的引导舆论趋势走向预测神经网络模型,实现了舆论趋势走向预测,能够对新时期网络社会的科学治理和媒体平台舆论趋势走向判断提供科学、有效的决策建议。
猜你喜欢
青年文摘(彩版)(2023年15期)2023-11-20
第一财经(2021年6期)2021-06-10
河北画报(2020年10期)2020-11-26
武术研究(2020年3期)2020-04-21
环球时报(2019-04-12)2019-04-12
Coco薇(2017年9期)2017-09-07
领导科学论坛(2016年10期)2016-06-05
纺织服装流行趋势展望(2016年2期)2016-05-04
汽车科技(2015年1期)2015-02-28
中国记者(2014年6期)2014-03-01
