
基于可变形注意力Transformer 的场景文本检测*
2023-12-09 08:50:44陈姚节许晓峰
计算机与数字工程 2023年9期
刘 恒 陈姚节,2 许晓峰
(1.武汉科技大学计算机科学与技术学院 武汉 430065)
(2.智能信息处理与实时工业系统湖北省重点实验室 武汉 430065)
1 引言
当下,文本的检测与识别在导航定位、证件识别、安防监控等领域有重要的使用价值,而文本检测作为文本识别的先觉条件自然成为了计算机视觉领域的一个研究热点。主流的场景文本检测算法分为两类,基于候选框的回归算法和基于图像分割的算法,虽然这两类算法相较于依赖手工设计特征去进行特征提取和分析的传统算法存在着巨大的优势,但它们也存在着一些问题。基于候选框的回归算法在得到最后的预测框之前存在着设置预选框和去重的操作,而基于分割的算法最终得到的预测框太依赖于分割的精度。针对上述两类方法存在的问题,本文将最近在自然语言处理领域大放异彩的Transformer[1]应用在文本检测领域中,因此基于Transformer的场景文本检测网络应运而生。
2 相关工作
深度学习近些年在众多研究领域的尝试以及成功,展现了它的优势以及独特的魅力,这份优势也同样影响了文本检测领域。其中回归和分割方法是文本检测的强力手段。
文字的出现往往成段落式,一块文字恰好可以用包络框围住,许多学者基于边界框回归的思想进行文本检测。CTPN[2]算法在网络中设定了一个固定宽度大小的anchor 使用双向长短记忆神经网络进行文本行检测,该方法有效地解决了场景图像中文本行具有复杂长宽比的问题。Jiang 等提出的R2CNN[3]为了解决图像中具有极端长宽比和多方向的文本难以检测的问题,首先使用了不同尺度的感兴趣区域池化操作,增加了特征尺寸,然后在Fast R-CNN 中额外增加了一个分支预测倾斜框,最后并在该支路后采用了非极大值抑制后处理算法得到检测结果。TextBoxes[4]算法在SSD 算法的基础上修改其anchor 来检测不同比例的文本。TextBoxes++[5]方法通过四边形或者倾斜的矩形来表示图像中的文本区域,在SSD的多个输出层后面通过预测回归从而检测任意方向的文本区域。Liao等着力于解决文本与轴向角度过大的情况,提出RRD[6]方法关注其旋转不变的特征,并实验验证了文本与轴向角度过大时此方法的有效性。He 等提出SSTD[7]方法学习生成注意力图来突出文本区域,然后将生成的注意力图与原始图像进行元素级别的相乘操作,使得文本区域的特征得到增强。Ma 等提出的RRPN[8]方法提出了旋转区域建议网络,该方法通过对角度信息进行调整,然后进行边框回归以达到检测任意方向的文本。
基于分割的文本检测方法主要是对全卷积网络(FCN)[9]的改进。Long S 等基于FCN 提出TextSnake[10]算法,该方法利用全卷积网络,借助多候选框能够检测出水平、多方向和弯曲的文本。PixelLink[11]算法在对特征图中的像素进行预测时,首先,通过对像素进行二分类,即像素归为文本或非文本;然后,基于连通域操作将该像素周围8 个方向存在预测为文本类的像素归为一个区域;其次进行噪声过滤去除操作;最后通过并查集得到最终的文本边界框。Zhou等提出的EAST[12]算法采用一个全卷积神经网络来实现文本区域的检测,其特征提取网络通过特定的分支网络来进行文本和非文本的二分类,并且还对文本区域进行了曼哈顿方向的回归,以获取文本的旋转角度和形状。Liao 等提出的Mask TextSpotter[13]算法共享网络和多任务损失函数进行端到端的训练,通过分割掩码机制对区域进行细分,能应对不同形状、大小和方向的文本。Xie 等提出的SPCNet[14]算法利用空间优先的上下文信息来提高文本检测的性能,通过多个分支的卷积神经网络进行文本区域的分类和定位,能够适应不同形状和复杂背景的文本检测任务。Wang等提出了一种基于分割的算法PSENet[15],它先对文本行不同核大小做预测,然后采用渐进式算法将小文本核扩展到最终的文本行大小,因此它可以很好地区分相邻行。CRAFT[16]算法通过两个并行分支网络来对每个像素进行文本/非文本和字符级别的分类,引入两个表示文本方向的热图,CRAFT 算法能够利用角度信息来辅助文本检测。Liao 等提出DB[17]算法,将ResNet网络所提取的特征送入特征金字塔中,并提出可微分近似二值化替换固定阈值的一般二值化,使该过程可与分割网络一起训练,该方法可以很好地区分前背景对象和距离相近的文本实例。
基于对边界框执行回归操作的文本检测方法不够直观,主要有两个问题:存在着对网络生成的预选框、先验框进行回归和分类,而非端到端的一步到位的直接预测目标框的问题;模型的效果会受到后处理消除大量重叠框、anchors 的设计、怎么把目标框与anchor 关联起来等问题的影响。基于分割的方法可以对多方向和不同形状的文本进行检测,但往往依赖于边界框或像素级掩模来表示文本区域。针对不同形状的文本和复杂的文本尺度影响文本检测精度的情形,本文提出了一种将文本检测转化为一个序列预测的任务方法,即在CNN 后增加Transformer模块[18],由输入图像直接得到预测结果,在Transformer模块中将自注意力机制改为可变形注意力机制解决小目标文本的问题,提高文本检测性能。
3 基于可变形注意力Transformer的文本检测方法
3.1 网络结构
通过将文本检测看作集合预测问题,本文简化了训练网络。如图1 所示,首先将图片传入骨干网络为ResNet50 的标准CNN 网络中得到多尺度特征图,然后将得到的特征图采用注意力机制传到图中黑框部分名为Transformer的编解码器结构。Transformer 是一种利用注意力机制实现了并行预测序列的结构,并且它的自注意机制可以将序列中全部的元素进行两两交互,因此此架构特别适合于特定的集合约束。
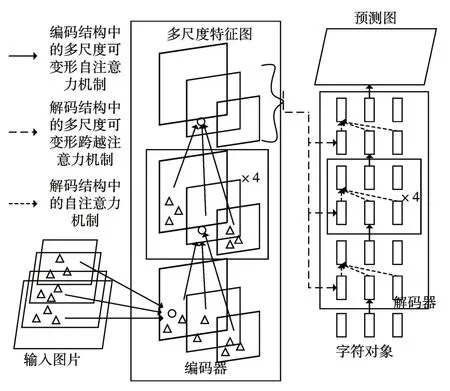
图1 基于可变形注意力Transformer的检测模型结构
本文的检测模型在最后输出预测结果时一次性预测所有文本对象,并通过损失函数在预测文本和真实文本之间进行二分图最大匹配。检测模型首先通过舍弃设置预选框、去重等操作,从而简化了检测网络。然后,与大多数文本检测方法不同,该网络不需要任何人为设计的网络去筛选预测框,因此可以在任何包含标准CNN 和Transformer 类的框架中轻松复制。
与以往直接预测文本对象的方法相比,该方法的主要特点是将二部匹配损失和Transformer 与并行译码结合起来。本文的匹配损失函数唯一地将一个预测赋给一个真实文本对象,并且对预测文本对象的排列不变,因此我们可以并行地输出它们。
本文在Transformer 中将它原本的自注意力机制改为了可变形注意力机制,它结合了可变形卷积稀疏空间采样的优点和Transformer 的关系建模能力,解决了算法收敛速度慢、复杂度高的问题。可变形注意力模块只会关注参考点附近少量的关键采样点,作为突出的关键元素代表特征图上所有的像素,即在高分辨率特征图上计算复杂度也不会太大。
3.2 Transformer模型
3.2.1 编码器
编码器的结构如图2 左黑框所示,首先,此部分结构由N个完全相同的大模块堆叠而成;然后,对于这每一个大的模块又可以分为两个模块,分别是多头注意力层和前馈神经网络层;其次,继续挖掘模块的组成,多头注意力模块可以分为放缩点积注意力层和正则化层,而前馈神经网络层可以分为线性层和正则化层。

图2 Transformer结构图
1)放缩点积注意力机制
与人的视觉注意力类似,注意力机制的本质是通过快速浏览全局图像,获得需要特殊关注的局部区域,然后对这部分区域进行重点关注,得到其更多的细节信息。
不同于传统Attention 的形式,Transformer 采用的是参数矩阵之间进行点积运算来计算相似度的Attention,计算输出矩阵的方法如下所示:
如式(1)所示,在计算Attention 的时候先用矩阵Q点乘矩阵K的转置在除以dk的平方根,将计算得到的结果经过softmax 后点乘V 矩阵得到最终结果。在上述的计算过程中矩阵之间的运算采用的都是点乘而非加法,从大部分人的数学认知上来看,这显然会增加计算量,但是换个角度想,矩阵加法在作为一个整体的去计算Attention 的时候相当于一个隐层,整体的计算量和点乘是类似的。
注意到标题的放缩字样,公式中的dk就很好的反映了这一点。如图3 所示,随着输入向量x的增大,刚开始向量点积结果增大的速度极快,而快到临界值时,此时softmax 的梯度趋近于0,显然这对于模型的训练不友好,所以加入dk这一放缩因子缓解此现象。

图3 向量点积结果图
2)多头注意力机制
类似于卷积神经网络中一个卷积层使用多个卷积核的模式,Transformer也使用了多个放缩点积注意力层组成了多头注意力模块。如图4所示。在多头注意力模块中,每一个注意力模块都接受了三个参数矩阵KQV 作为输入,它们分别通过层归一化后进入放缩点积注意力模块计算Attention,最后通过合并和归一化后得到输出。不难看出多个注意力模块的作用是允许模型在不同的表示子空间里学到相关的信息。如下公式表示:

图4 多头注意力模块
式(2)、(3)中的是第i头的输出,h为模块头的总数,,,,为参数矩阵,,,分别对Q、K、V进行线性映射,对多个头的输出进行线性映射,并且∈,∈,∈,∈。
3.2.2 解码器
解码器的模块组成如图2 右边黑框所示,解码器同样由N个相同的层组成,每一层包含遮掩多头注意力模块和多头注意力模块。其中遮掩多头注意力模块的部分用于将未来的信息遮掩掉,因为在生成的时候是无法知道未来的信息的;多头注意力模块除了接收来自每个编码器层输出的两个矩阵K和V之外,解码器还加入了第三个矩阵Q,与矩阵K、V一起作为输入,然后执行多头注意力操作得到最后的输出信息。参照编码器的结构,解码器同样在每个模块的最后加入了残差连接,然后正则化。
3.2.3 位置编码
Transformer 中的Attention 机制并没有包含位置信息,即序列中的词在不同位置时在Transformer中体现不出区别,这显然不符合常理。因此非常有必要在Transformer 中加入位置信息。位置编码公式如下:
在式(4)、(5)中,PE为二维矩阵,i为词语关联的向量位置,pos为词语输入位置,dm代表i的维度,采用正弦操作和余弦操作的原因是可以得到词与词之间的相对位置以此填满PE矩阵,因为
即由sin(pos+k)可以得到,通过线性变换获取后续词语相对当词语的位置关系。
3.3 多尺度可变形注意力模块
在图像特征图上应用Transformer 注意力的关键问题是,在初始化时注意模块会对特征图中的所有像素施加几乎一致的注意权重,即它会关注所有可能的空间位置,这样会导致处理高分辨率特征图的计算和内存复杂度非常高,从而导致从高分辨率图像中检测出小物体非常的困难。为了解决这个问题,本文采用了可变形注意力模块,仅关注少量采样点,为每次词语分配少量key。给定输入特征图X∈RC×H×W,用q作为一个query 元素的索引,其特征表示是zq,二维参考点pq,可变形注意力特征的计算如下:
其中m是注意力head 的索引,k是采样keys 的索引,K是所有采样key 的个数(K<<HW)。 Δpmqk和Amqk分别表示第m个注意力head 中第k个采样点的采样偏移量和注意力权重。标量注意力权重Amqk位于[0,1]之间,用做归一化。Δpmqk∈R2是二维实数,取值范围没有限制。因为pq+Δpmqk是小数,故采用了双线性插值。Δpmqk和Amqk是对query 特征zq做线性映射得到的。在实现时,query 特征zq输入进一个有3MK 个通道的线性映射操作符,前2MK 个通道编码采样偏移量Δpmqk,剩下的MK 个通道则输入进一个softmax 操作符,得到注意力权重Amqk。
由于图像中物体的形状各异且大小不一,甚至存在着一些极小、极大等极端状况,因此为了更精确的检测目标物体,多尺度特征图就显得尤为重要。那么为了更好地对复杂形状的文本进行检测,本文的可变形注意力模块可以扩展到多尺度特征图上。
式(9)中m是注意力head的索引,l是特征图层级的索引,k是采样点的索引。Δpmlqk和Amlqk分别表示第m个注意力head 在第l个特征层级上第k个采样点的采样偏移量和注意力权重。标量注意力权重Amlqk用做了归一化。这里,使用归一化坐标p̂q∈[0,1]2为了尺度表述更清晰,归一化的坐标(0,0)和(1,1)分别表示图像的左上角点和右下角点。函数ϕl(p̂q)对归一化的坐标重新做了缩放,符合第l 个特征图层级。多尺度可变形注意力和之前的单尺度版本很像,除了它会从多尺度特征图上采样LK个点,而不是单尺度特征图的K个点。
4 实验结果及分析
4.1 数据集与实验参数
本文的数据集(场景文本数据集)收集并制作了10000 张包括明亮、灰暗等各式背景图片,其中8000 张图片用于训练,2000 张图片用于测试,每一份标签数据都是在图片调整分辨率为512*512 后生成文字然后标注而成。标签文件中的标注由文本区域的左上角顶点坐标和右下角的坐标共4 个数字组成。
ICDAR-2013(IC13)是一种常用的多方向英文场景文本检测数据集。数据集中的图像涵盖了各种不同的条件和场景,例如低分辨率、不同的字体和语言、噪声、倾斜等。
为了提升数据集的多样性,对训练中的数据集进行了数据增强,包括:裁剪、水平翻转、腐蚀。在进行数据增强后的数据集样例效果图如图5所示。

图5 数据增强样例
本文的检测器使用ImageNet 预训练的ResNet-50 作为骨干网络,将初始的学习率设置为2e-4,学习率的衰减大小为1e-5,并且所有网络都采用AdamW 进行优化。本文的实验在RTX 2070super 上进行,在IC13 和本文的数据集分别训练100个epoch后进行测试。
4.2 评估指标
本文在IC13 数据集上采用精确率Precision 和召回率Recall 以及F1 值对模型进行评价。精确率反映模型对文本行的查准率,召回率反映模型对文本行的查全率。F1 则反映了模型性能的好坏。公式如下:
其中,TP 代表判定是正样本,真实标签也是正样本;FP 代表判定是正样本,但其实是负样本;FN 为判定是负样本,但实际上是正样本。F1 值越高则检测器对文本的检测越有效。
本文在场景文本数据集上采用平均精确度AP对模型进行评价。如下公式:
在这一积分中,p代表精确度,r代表召回率,p是一个以r为参数的函数,积分的结果为对0~1 之间的多种阈值下的精确度与召回率相乘累加而得。
4.3 实验结果
表1为各方法在ICDAR2013上的测试结果,从表上的数据不难看出本文方法明显优于CTPN 等传统方法,在F1score 指标上,本文方法比R2CNN高了3.66%。
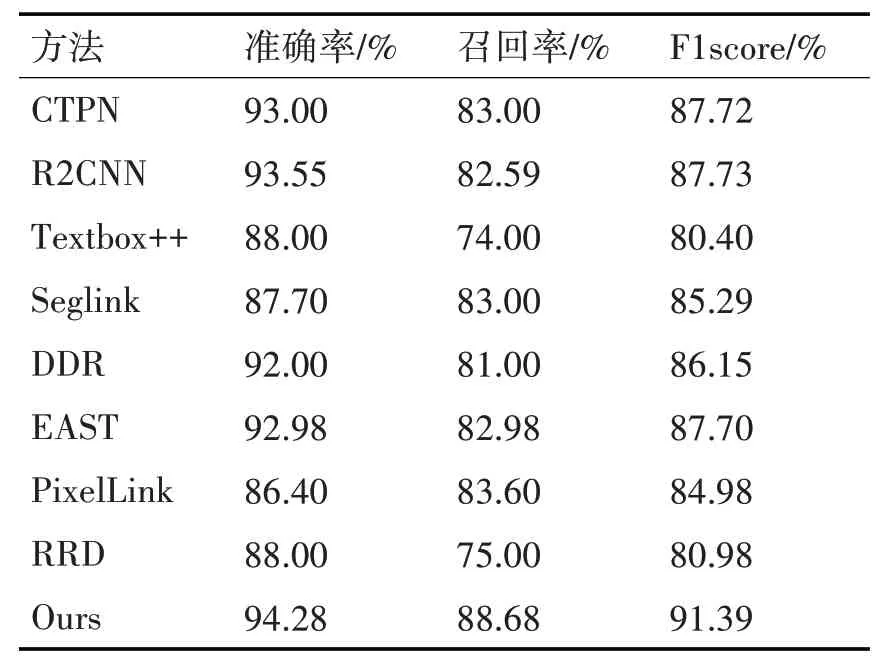
表1 本文检测模型与其他检测模型在IC13上的指标
表2为各方法在ICDAR2015上的测试结果,从表上的数据可以看出本文方法要优于基于分割的PSENet 算法,在F1score 指标上,本文方法比PSENet高了4.18%。

表2 本文检测模型与其他检测模型在IC15上的指标
表3 为各方法在MSRA-TD 500 上的测试结果,从表上的数据可以得到本文方法比DB 算法高了2.67%。

表3 本文检测模型与其他检测模型在MSRA-TD 500上的指标
表4 为本文方法与Faster RCNN 和不含可变形注意力的Transformer检测模型的对比,从表上的数据来看出,基于Transformer 的检测模型与Faster RCNN 在性能上只有微弱的差别,而在Transforner上增加了可变形注意力机制后,检测效果得到了明显的提高,体现在Ap(0.50∶0.95)上升了4.03%。

表4 本文检测模型与其他检测模型在场景文本数据集指标
如图6 所示,本文的检测模型在具有不同背景和不同尺寸大小情况下的检测样例。

图6 检测结果样例
为了更直观地感受模型检测文本的效果,本文将编码器和解码器中最后一层的采样点与权值可视化。如图7 所示,每个取样点被标记为一个填充的圆点,预测的边界框显示为一个矩形。由图上圆点的分布不难看出,模型会更注意文本所在的区域,即圆点会密集的会聚在文本区域,而在非文本区域圆点则呈现分散的状态。

图7 采样点可视化样例
如图8 所示,与不采用多尺度可变形注意力机制相比,应用了多尺度可变形注意力机制,模型从计算整个特征图的复杂度,下降到只用计算采样点及其周围几个像素点的复杂度,致使训练loss 下降的速度增快了几倍,模型的收敛需要的epoch 自然而然的减少。
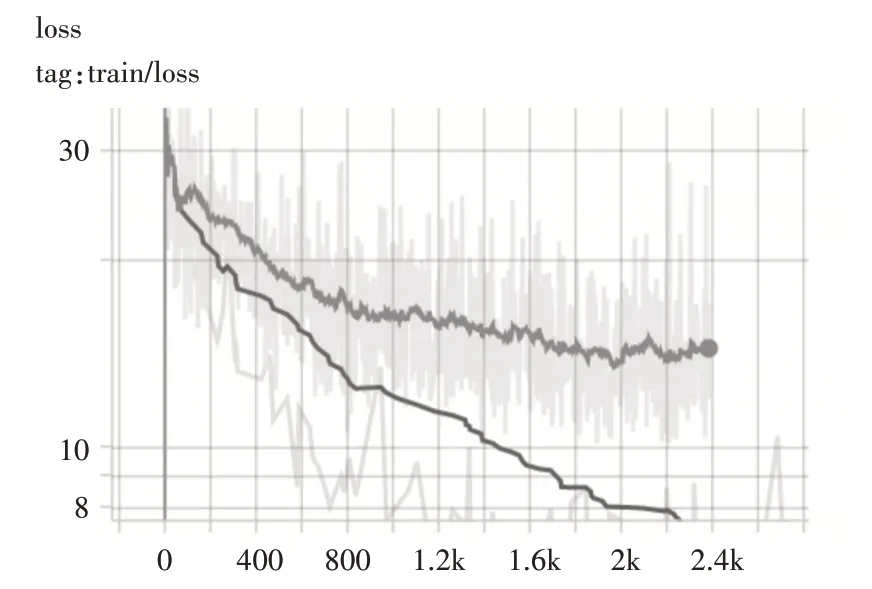
图8 是否采用多尺度可注意力机制loss下降对比
5 结语
本文提出了一种基于可变形注意力机制改进的Transformer的场景文字检测模型,模型利用了基于ResNet 作为骨干网络,结合Transformer 编解码模块,实现端到端的图像文字检测。模型的有以下优点:没有传统边界回归方法的一些后处理操作,如消除大量重叠框、anchors 的设计等;采用了可变形注意力模块,让模型只关注参考点附近少量的关键采样点,减少高分辨率特征图的计算复杂度,这样能在高分辨率特征图上检测到小目标。
从实验分析得到的结果来看,本文方法在场景文本检测领域拥有着能与Faster RCNN 媲美的性能,因此本方法能使用在类似证件照识别,安防监控等存在文字检测需求的领域中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中华诗词(2020年1期)2020-09-21 09:24:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
小学生作文(中高年级适用)(2018年5期)2018-06-11 01:22:56
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
传媒评论(2017年3期)2017-06-13 09:18:10
中学生数理化·七年级数学人教版(2017年11期)2017-04-23 07:18:00
数学大王·中高年级(2016年12期)2016-12-26 21:37:36
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
