
基于神经网络的电力系统节点碳排放因子预测方法
2023-12-07 08:28杨雨瑶潘峰钟立华张军招景明
广东电力 2023年10期
杨雨瑶,潘峰,钟立华,张军,招景明
(广东电网有限责任公司计量中心,广东 广州 510080)
当前,能源领域是我国碳排放的最大源头,在能源领域中,电力碳排放占比最高。以2020年全国碳流图为例,能源领域碳排放约为113亿t,其中电力碳排放约为39.31亿t,占比37.8%,远高于其他行业[1]。而且,随着各行业电气化程度增高,未来电力碳排放占比将持续增大[1-2]。按照国家能源局预测数据,2030年各行业电气化率约为34%,将比2020年增加6个百分点,2060年更是将超过77%。由此可见,电力在社会发展过程中应用越来越广泛,电力减碳是实现国家“双碳”目标的关键环节[2]。
一般而言,碳排放主要是发电侧的化石燃料在转化为电能过程中产生的,电能从发电端输送到用户端,最终被用户消耗[3]。因此,碳排放责任是从化石燃料机组转移到了用户。为了更好地推进碳减排,有必要掌握发电、电网和用户的真实碳排放情况。
碳流分析法是一种基于电力潮流的虚拟网络碳排放流追踪方法[4],其基本思想是在潮流结果的基础上,利用顺流或逆流跟踪算法确定电网中的功率分布,然后结合机组的碳排放,将发电侧碳排放公平分摊到各节点负荷、各支路功率以及网络损耗,从而实现碳排放具体流向的准确追踪与溯源。碳流分析法清晰地揭示了碳流在电力网络中的分布特性和传输消费机理,不仅可以获得不同能源主体的碳排放总量,还可以将碳排放总量分解到不同的时段与电网节点,并赋予对应的精细化碳排放,从而极大地推动电力系统碳排放分析与统计工作的开展[5-6]。
碳流分析法需要收集潮流数据[7-9],存在通信延迟[10],会给碳排放计算带来一定误差,并且需要考虑碳排放因子的方程求解,计算比较繁琐。文献[11]根据日前发电调度计划与实际运行数据的对比,消除了新能源发电不可控给化石能源机组和电力用户带来的潜在碳排责任,更合理地分配了碳排责任。文献[12]根据发电厂与电网、用户之间的关系,利用关联矩阵来分析碳排放流在源、网、荷之间的流动关系。文献[13]给出适用于通过循环递推的方式,依次推导更新每个节点的碳排放因子,但是这个方法只适用高压输电网络的碳排放流计算,不适用于配电网。相比于传统碳排放计算模型,基于数据驱动的手段无需计算或采集潮流数据,只需通过历史数据学习,就能有效获取碳排放与电气量之间的特征关系。对于长期碳排放预测,文献[14]采用反向传播神经网络(back propagation neural network,BP)来评估中国未来数月的碳排放。文献[15]建立针对高耗能企业的碳排放检测模型,并采用传统回归方法和机器学习方法进行比较,实验验证了神经网络预测性能表现较优。
为了兼顾碳排放计算的准确度和实时性,本文提出基于Dropout反向传播神经网络(Dropout based back propagation neural network,DBP)[16-17]的碳排放因子预测模型[18]。该预测模型根据实时负荷数据[19]预测电力系统各个节点的碳排放因子,并根据训练过程对神经网络节点进行随机失活,提升网络的泛化能力,可以有效避免模型过拟合。最后采用IEEE 39节点系统、118节点系统和9节点系统验证模型的有效性。
1 基于潮流分析的电力系统节点碳排放因子计算方法
基于潮流分析方法,电力系统每个节点的碳排放因子定义为流出该节点的碳排放因子,即流出该节点的分支功率以及接入该节点负荷的碳排放因子。对于一个包含m个节点的电力系统,流出节点i的碳排放因子可以根据流入该节点电能的总转移碳排放计算,公式如下:
(1)
式中:Gi,k、ci、δg,k分别为与第i个节点相连接的第k个发电厂的发电量、与第i个节点相连接的总的发电厂个数及第k个发电厂对应的碳排放因子;Di为第i个节点连接的负荷总用电量;Pi,j和ni分别为第j个节点向第i个节点的功率潮流注入和第i个节点连接的节点数总和;δp,i为第i个节点的碳排放因子。
对式(1)进行处理,得到第i个节点的碳排放因子方程表达式,如下:
(2)

2 基于神经网络的电力系统节点碳排放因子预测方法
上述基于潮流分析的碳排放因子计算需要考虑电力系统的拓扑和实时潮流数据,并且需要求解碳流方程。而基于数据驱动的方法,则不需要考虑电力系统拓扑,其利用历史数据进行神经网络学习,并且在实时预测中不需要考虑潮流量数据。基于神经网络的碳排放因子预测方法包含3个模块:数据采集、网络训练和在线预测。
2.1 数据采集
基于碳排放因子计算模型,分析各节点的碳排放。由于各节点功率潮流变化难以控制,本文选取各节点的负荷Di(i∈DPQ,DPQ为有功-无功节点和平衡节点的集合,包含d个元素)作为输入变量,将各节点的碳排放因子计算结果δp,i(i=1,2,…,m)作为输出,建立包含为1个d维负荷输入和m维碳排放因子输出模型。
将系统的最大发电量设置为总负荷最大范围,为确保输入的负荷数据为随机数据,设置d+1个0~1的随机数,其中d个随机参数为负荷占总负荷的比例ai(i=1,2,…,d),剩余1个随机参数为发电量转移到负荷区域的比例参数b。故随机负荷Li可以设置如下:
(3)
(4)
式中:Gmax、gmax和Gi,j分别为电力系统总的发电量、发电机总数和第j个发电机组对第i个节点的功率注入。
在历史数据收集阶段,本文根据随机输入负荷序列L,通过潮流计算得到各节点的功率潮流,再通过碳排放因子计算模型〔式(1)、(2)〕得到系统各节点的碳排放因子。
2.2 神经网络训练
2.2.1 网络设计
理论上,神经网络和全连接层都可以视为一个函数逼近器,只要训练得当就能逼近任何函数。本文考虑全连接网络的回归性能和快速计算优点,采用一个全连接网络来预测碳排放因子。网络训练效果主要与数据样本大小和网络结构设计相关。同时,为避免神经网络的训练出现过拟合现象,本文采用3个全连接层网络,每个全连接层都包含1个Relu层和Dropout层[20],网络结构如图1所示。
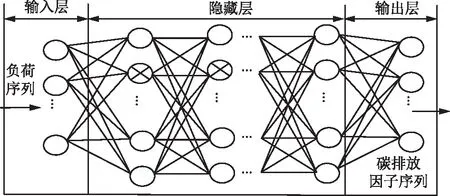
图1 网络设计Fig.1 Network design
2.2.2 离线训练
预测模型训练采用梯度下降法,目标是训练样本的输出逼近实际样本数据。为方便训练,本文将样本的训练批次型号设置为64,批量设置可以使网络先计算一个批量样本损失,同时更新对应的权重和偏置矩阵。将训练集划分为4∶1的训练集合验证集,通过五折交叉验证[21],选取最优网络。网络损失函数设置为均方误差函数[22],计算如下:
(5)

2.3 在线预测
本文提出的预测模型包含全连接层和Relu层,其输出可表示为
Hl=Rl(WlHl-1+Bl) ,l=1,2,….
(6)
式中Hl、Rl、Wl和Bl分别为第l层的输入特征、Relu函数、权重矩阵和偏置向量。
2.4 预测流程
预测流程分为4个步骤,如图2所示。步骤1,根据随机参数产生随机的负荷序列,以满足下一步的潮流计算;步骤2,根据随机负荷序列、电力系统给定的拓扑连接及发电数据进行潮流计算分析,再根据潮流数据计算各节点分摊的碳排放责任和对应的节点碳排放因子;步骤3,收集负荷数据和计算的碳排放因子数据,进行网络训练,经过不断迭代,使网络输出逐步逼近碳排放因子数据;步骤4,根据离线训练的网络进行在线预测,实现对各节点碳排放因子的快速预测。需要注意的是,在实际网络在线预测中,只需要系统节点负荷数据就可以预测碳排放因子,而不需要实时的潮流数据。

图2 预测流程Fig.2 Prediction flowchart
3 仿真验证
3.1 参数设置
本文采用IEEE 39节点、IEEE 118节点和IEEE 9节点的电力系统对碳排放因子预测模型的有效性进行仿真验证,参数设置分别见表1、表2,采用表3的参数对碳排放因子预测模型进行训练,表3中网络结构为神经网络的隐含层结构。

表1 IEEE 39节点机组碳排放因子Tab.1 Carbon emission index of generator for IEEE 39 node system
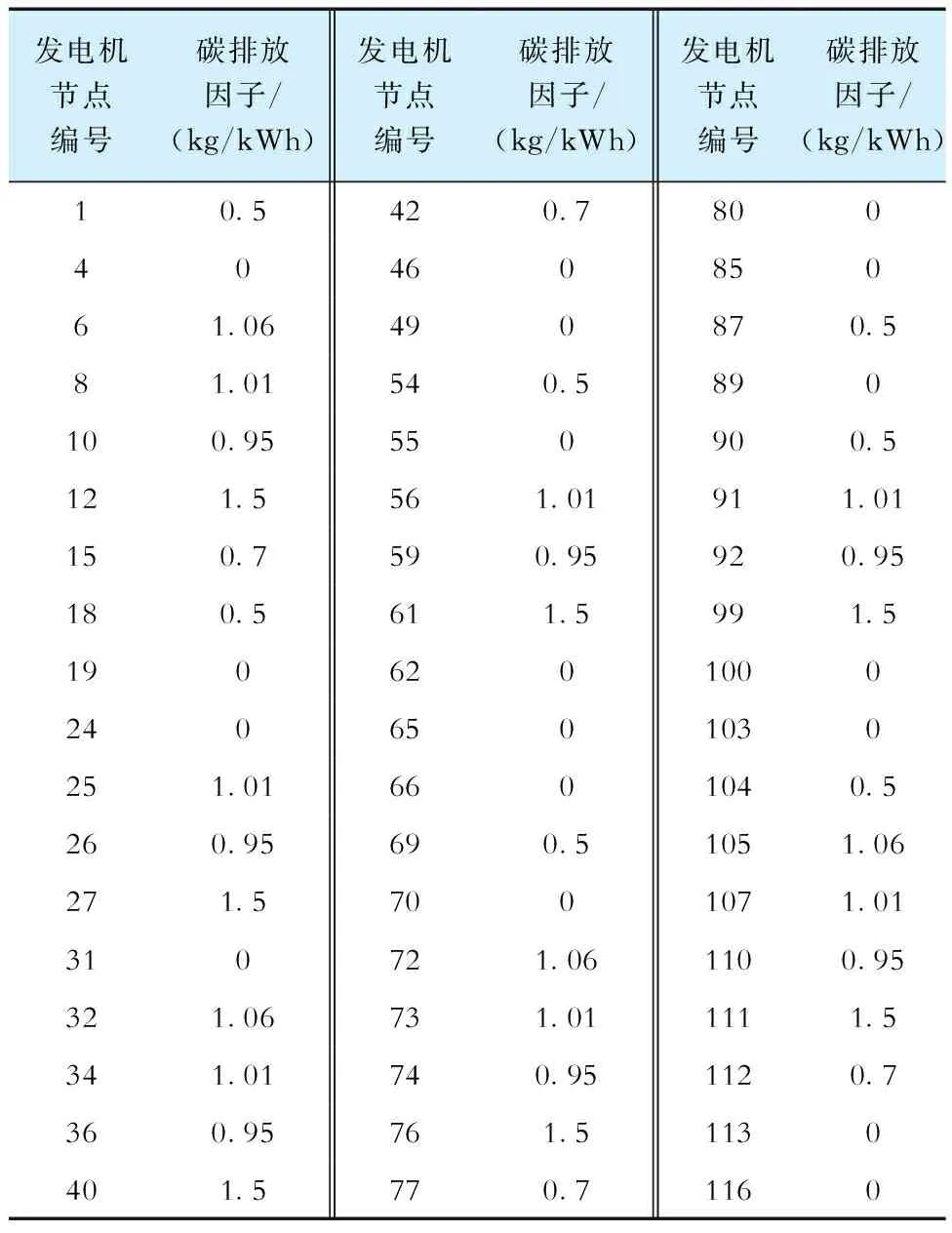
表2 IEEE 118节点机组碳排放因子Tab.2 Carbon emission index of generator for IEEE 118 node system

表3 模型参数设置Tab.3 Model parameters setting
3.2 IEEE 39节点案例分析
采用IEEE 39节点电力系统对碳排放因子预测模型进行仿真。预测模型的损失函数训练迭代图如图3所示。由图3可知,经过300次迭代后预测模型已经收敛。
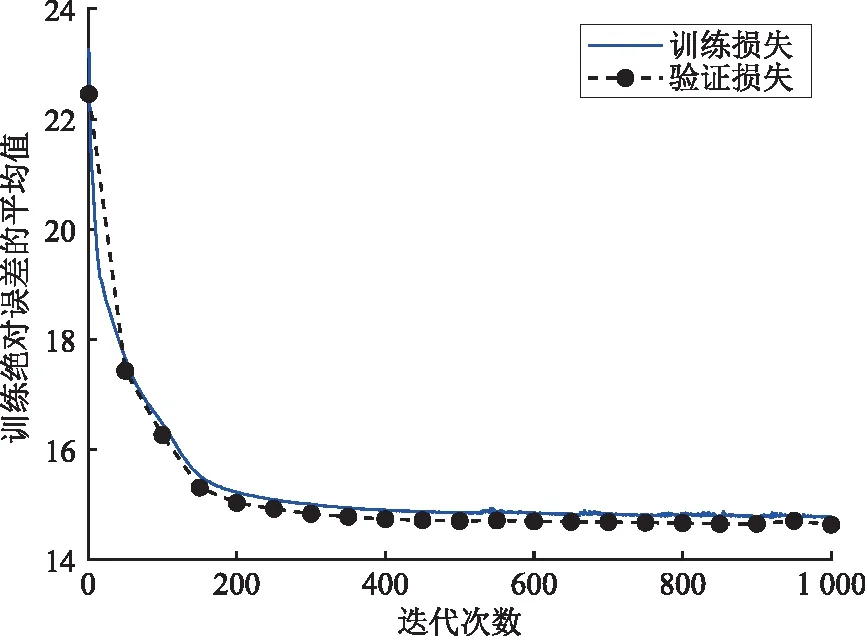
图3 训练损失函数Fig.3 Loss function during training process
图4所示为碳排放因子预测对比结果雷达图,其中碳排放因子单位为kg/kWh。由仿真结果可知,由碳排放因子预测模型得到的碳排放因子预测值,与采用潮流分析方法计算得到的碳排放因子值相比较,两者相对误差为5.05%。
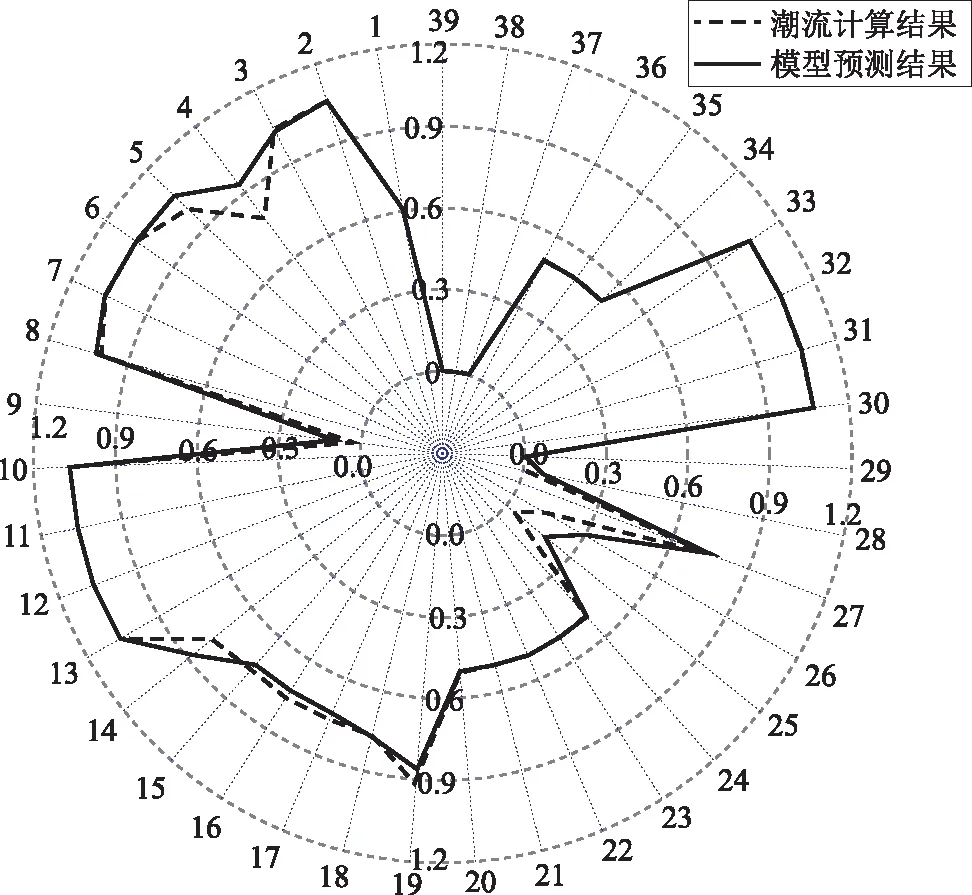
图4 IEEE 39节点系统节点碳排放因子预测对比结果Fig.4 Comparison results for carbon emission factors of IEEE 39 node system
3.3 IEEE 118节点案例分析
采用IEEE 118节点的电力系统对碳排放因子预测模型进行仿真。预测模型的损失函数训练迭代如图5所示,经过1 000次迭代后,预测模型基本收敛。图6所示为碳排放因子预测对比结果雷达图。由仿真结果可知,由碳排放因子预测模型得到的碳排放因子预测值,与采用潮流分析方法计算得到的碳排放因子值相比较,两者相对误差为7.49%。
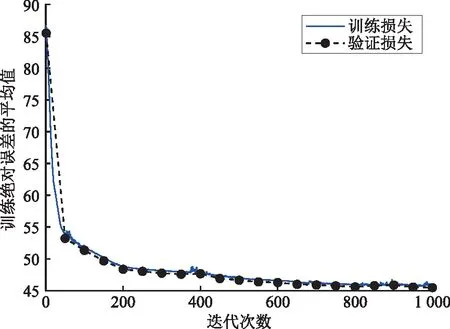
图5 训练损失函数Fig.5 Loss function during training process
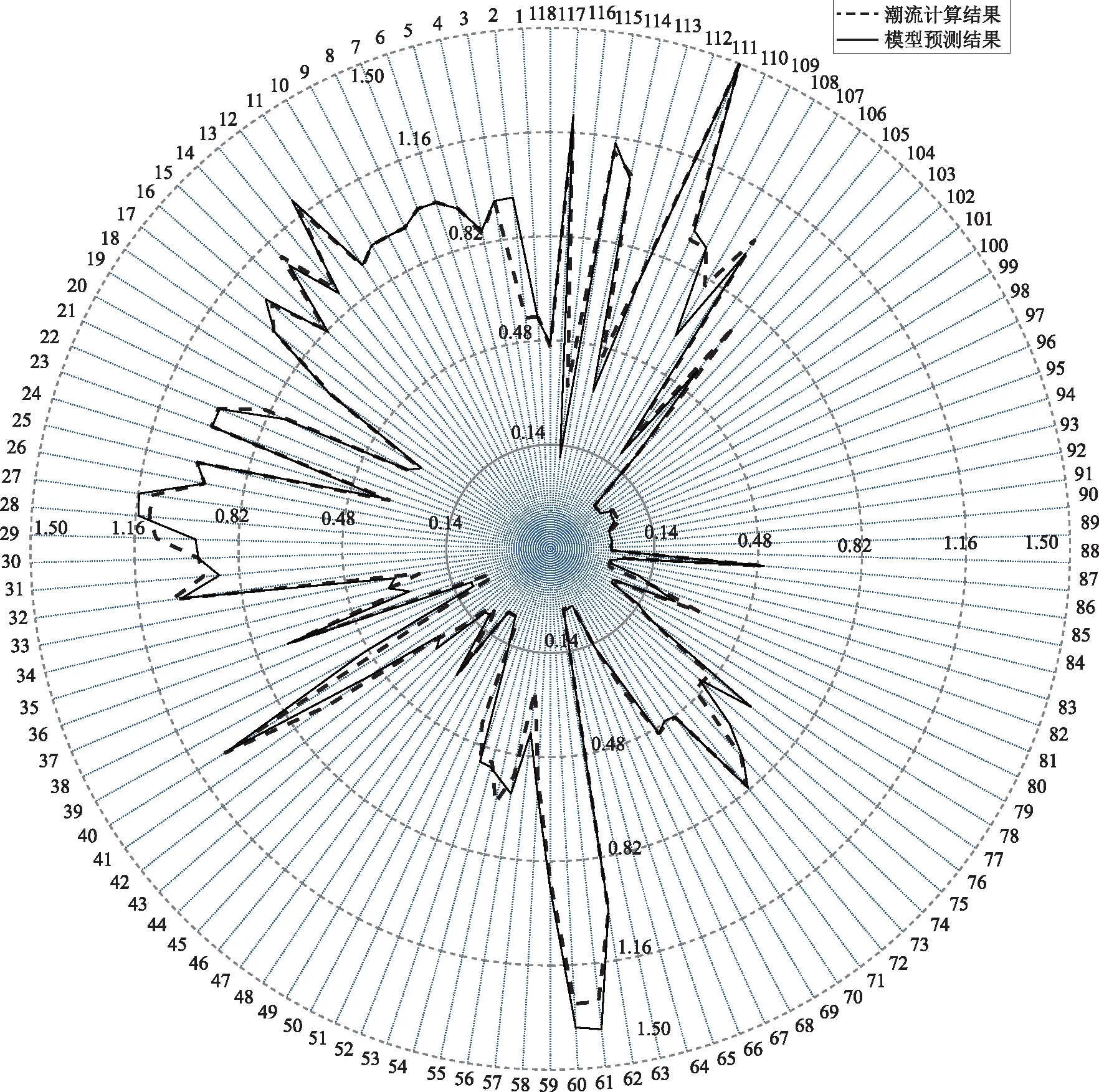
图6 IEEE 118节点系统节点碳排放因子预测对比结果Fig.6 Comparison results for carbon emission factors of IEEE 118 node system
3.4 IEEE 9节点案例动态分析
采用IEEE 9节点的电力系统对碳排放预测模型进行仿真,该系统的构成如图7所示,其包含3个发电机组、3个负荷和9个节点。实验采用基于潮流分析的碳排放因子计算(power flow analysis based carbon emission calculation,PCE)、BP与DBP进行预测性能的对比。图8——图10分别给出不同负荷情况下系统第5、第7和第9节点的碳排放因子变化情况。由图8、图9和图10可知:随着负荷变化,由预测模型计算的碳排放因子,与潮流分析法计算的碳排放因子,两者变化趋势一致。此外,对于图8,当负荷处于部分边界值时,DBP算法预测效果优于BP算法,例如当负荷2为300 MW、负荷1为200~300 MW时。对于图9,当负荷1为0、负荷2为0~200 MW时,BP算法预测能力相比DBP算法较差。
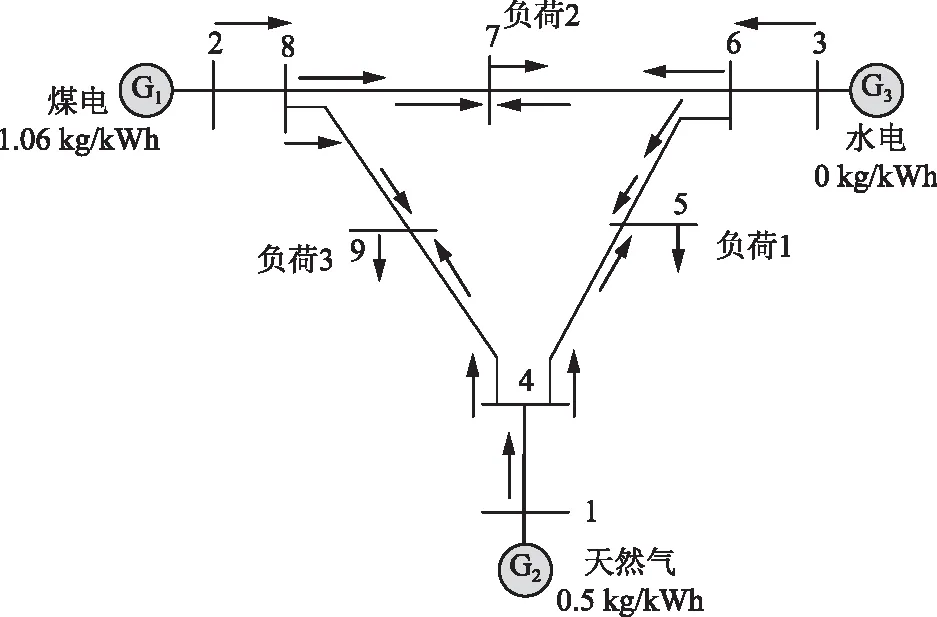
图7 IEEE 9节点系统拓扑Fig.7 Topology of IEEE 9 node system
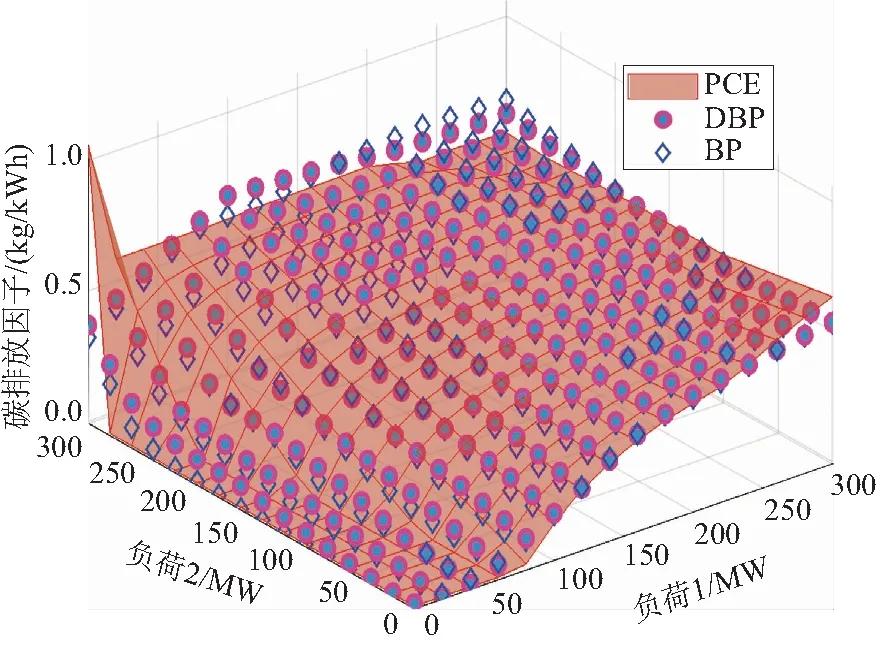
图8 IEEE 9节点系统负荷1用电碳排放因子预测Fig.8 Forecast of carbon emission factor for load 1 electricity consumption in IEEE-9 node system

图9 IEEE 9节点系统负荷2用电碳排放因子预测Fig.9 Forecast of carbon emission factor for load 2 electricity consumption in IEEE-9 node system

图10 IEEE 9节点系统负荷3用电碳排放因子预测Fig.10 forecast of carbon emission factor for load 3 electricity consumption in IEEE-9 node system
2种方法的预测误差列于表4:节点3和6接入新能源机组,碳排放为0;而对于节点1、2、8,由于直接用电来源为机组发电,碳排放因子数据在大多数时刻为固定数值,预测偏差较小;对于节点5、7、9,碳排放因子随着负荷波动。除节点5之外,DBP算法的预测效果均优于BP算法,这也说明了Dropout机制的引入有助于提升网络的预测效果和泛化性能。
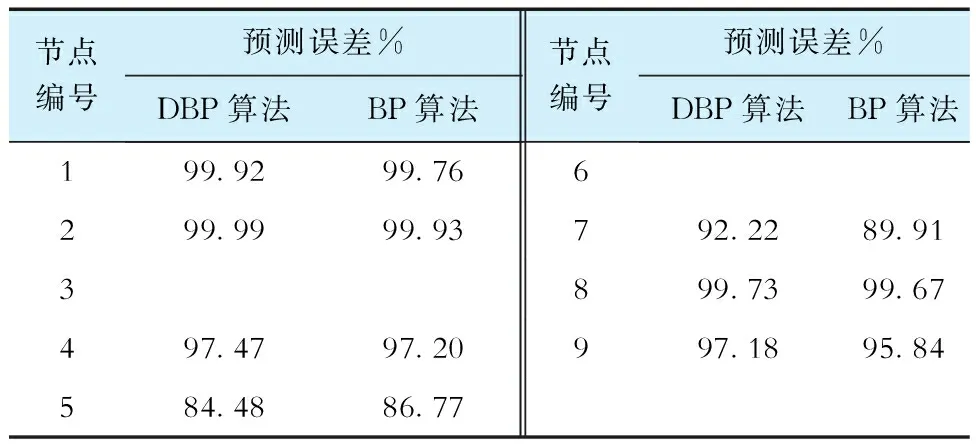
表4 IEEE 9节点节点碳排放因子预测误差Tab.4 Prediction error of node carbon emission index of for IEEE 9 node system
4 结束语
本文提出一种基于神经网络的电力系统节点碳排放因子预测方法,该方法不仅可以快速实时预测电力系统节点的碳排放因子,还可以分析节点负荷对系统碳排放因子的影响,采用IEEE 39节点、118节点和9节点系统验证了节点碳排放因子预测方法的有效性。与潮流分析方法相比较,本文所提预测方法在保证计算准确度的基础上,大幅缩短了计算时间。
该方法可用于电力系统低碳调度的辅助决策,还可引导电力用户低碳生产和生活。
猜你喜欢
电子制作(2019年19期)2019-11-23
足球周刊(2016年14期)2016-11-02
足球周刊(2016年15期)2016-11-02
足球周刊(2016年10期)2016-10-08
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
核科学与工程(2015年2期)2015-09-26
Coco薇(2015年1期)2015-08-13
