
基于对齐卷积和椭圆损失函数的遥感图像目标检测算法
2023-12-07 02:29:20郑凌云李佐勇蔡远征唐郑熠
软件工程 2023年12期
郑凌云, 李佐勇, 蔡远征,4, 唐郑熠
(1.福建工程学院计算机科学与数学学院, 福建 福州 350118;2.闽江学院计算机控制与工程学院, 福建 福州 350121;3.福建省信息处理与智能控制重点实验室, 福建 福州 350121;4.四创科技有限公司, 福建 福州 350100)
0 引言(Introduction)
近年来,卷积神经网络(Convolutional Neural Network)已成功应用于计算机视觉领域的各种任务中[1-7]。得益于神经网络的蓬勃发展,当前遥感图像识别网络主要围绕经典的检测器构建,从2017年的旋转视网膜网络(Rotated Retinanet)开始,遥感目标检测的研究逐渐受到关注[8-9]。遥感目标检测使用主干网络的相同特征进行学习,但是分类分数和定位精度一般不会匹配,对高分类分数的目标不利。目前的损失函数侧重于沿用水平框的面积计算得出交并比(Intersection over Union,IoU),导致在大长宽比的旋转框下,细微角度的偏差会导致IoU偏差巨大,容易让网络过拟合。为了克服上述问题,本文提出一种基于对齐卷积和椭圆损失函数的遥感图像目标检测算法,该网络引入对齐卷积,可以根据尺度、形状和方向生成对齐特征,达到提升精度的目的;使用椭圆框,减少学习过程中IoU损失函数振荡;使用均方误差损失进一步优化回归损失。
1 相关工作(Related work)
随着深度学习的发展,目前的检测器分为两种类别,即单级检测器和两级检测器。单级检测器只需提取一次特征即可实现目标检测,其速度比两级检测器快,但总体精度略低。目前的单级检测器例如YOLO(You Only Look Once)[10],能直接完成从特征到分类和回归的预测,使用相同的完全连接层实现分类和回归。SSD(Single Shot MultiBox Detector)[11]网络是一个完全卷积网络,即通过VGG16进行特征提取后,提取38×38、19×19、10×10、5×5、3×3和1×1六层不同尺度的特征,用于SSD分类和回归。两级检测器需要提取多种特征,学习速度慢,但是精度高于单级检测器。常见的两级检测器包括R-CNN[12]、Fast R-CNN[13]、Faster R-CNN[14]、Mask R-CNN[15]和Feature Pyramid Network(FPN)[16]。FPN网络构建了一个特征金字塔,可以学习不同尺度的特征和处理大规模的对象变化。综上所述,上述检测模型主要依赖两阶段网络分别进行特征提取和识别。
目前研究人员在遥感图像识别领域取得了如下的研究成果。ReDet[17]用于提取旋转等变特征,可以准确预测方向并大幅度减小模型尺寸。滑动顶点(Gliding Vertex)[7]方法没有回归通常矩形的4个顶点,而是在每个矩形框上移动顶点形成旋转框。旋转不变CNN在现有CNN体系结构的基础上,引入和学习一个新的旋转不变层[18]。LIU等[19]构建了一个近似封闭的船舶旋转框空间,WANG等[20]提出了一个中心地图OBB(Oriented Bounding Boxes),通过减少OBB中背景因素进而更好地表示OBB。通过在经典的水平边界框表示法中添加四个滑动偏移变量,可以获得图像的新表示法,检测器也可以学习新的特征。YANG等[8]提出的RepPoints是一种新的对象检测表示,它由一组表示对象空间范围和语义重要局部区域的点组成。这种表示是通过弱定位监督和矩形锚点隐式识别反馈实现学习的。ZHANG等[21]开发的CAD-net(Context-Aware Detection Network)由全局上下文网络组成,该网络利用注意力调制特征以及联系全局特征与局部特征检测图像。
2 方法(Method)
2.1 网络架构
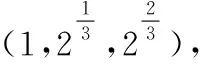

图1 单阶段对齐检测网络框架Fig.1 Single-stage alignment detection network framework
2.2 对齐卷积模块
标准的卷积可以用公式(1)表示:
(1)
其中:W表示卷积核的参数,r为卷积像素相对于当前位置的偏移,p表示当前卷积的空间位置,R为常规的采样位置。
本文研究的网络中,在改进视网膜网络模块中增加了对齐卷积模块(Alignment Convolution Module),与标准卷积不同的是,对齐卷积增加了一个偏移量o:
(2)
其中:o为采样到的锚框坐标和真实值之间的偏差值,p中含有如下参数(x,y,h,θ)表示p位置的锚框,对于每个规则位置的r,基于锚框的采样位置为
(3)
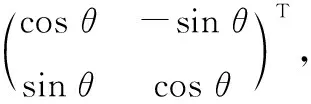
(4)
图2为对齐卷积网络模块的图例,通过在网络中加入对齐卷积将W*H*KA锚框中预测的位置解码成旋转矩形(x,w,h,θ),K为分类的类别,在DOTA1.0数据集中的K为15,本次实验采用9个不同的锚框,所以A为9。与输入特征一起计算对齐卷积,提取对齐卷积的特征。对齐卷积网络模块由输入通道和输出通道都为256的5层可变形卷积组成,经每个卷积层后使用ReLU作为激活函数。
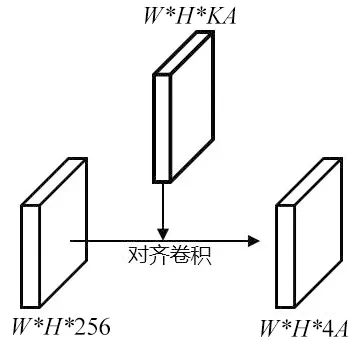
图2 对齐卷积网络模块Fig.2 Aligned convolutional network module
2.3 椭圆损失函数(Elliptic loss function)
计算椭圆IoU的流程如图3所示,首先将边界框转换为高斯分布,将边界框的中心点重合,其次使用卡尔曼滤波获得重叠区域的分布函数,最后将得到的分布函数值和旋转框计算IoU。
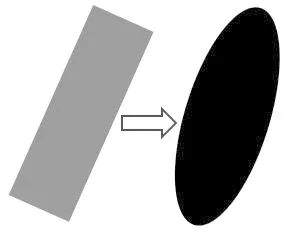
(a)将矩形框转变为椭圆框
2D旋转框可转换为高斯分布G(μ,Σ)形式表示:
Σ=RΛRT
(5)
μ=(x,y)T
(6)
其中,R表示旋转矩阵,Λ表示特征值的对角矩阵。
对于2D目标B2(x,y,h,w,θ):
(7)
(8)
此处,可基于方差公式计算出高斯分布旋转框的面积VB,由于遥感图像识别检测的是二维平面,因此此处带入n=2,并使用协方差累乘,可得面积VB公式如下:
(9)
进一步引入高斯分布计算预测框与真实值之间的重叠部分的面积Gs,该过程可以通过由两个高斯分布G1和G2的乘积得到:
αGs(μ,Σ)=G1(μ1,Σ1)G2(μ2,Σ2)
(10)
其中:α可以表示为
α=Gα(μ2,Σ1+Σ2)
(11)
μ、Σ可表示为
(12)
公式(12)中,K=Σ1(Σ1+Σ2)-1。需要注意的是,公式(12)计算后得到的高斯分布的协方差Σ,与协方差Σ1与Σ2有关,该公式没有体现出位置对于协方差的影响,其原因在于该计算过程中采用的高斯分布αGs(μ,Σ)并不是标准高斯分布,不能在不考虑中心点系数α的情况下,直接计算出重叠面积。在计算面积时,要同时把α考虑进去。所以,引入中心点损失使得两个分布同中心,这样就不需要考虑中心点系数。椭圆损失函数如下:
(13)
接下来,我们就可以将轴对齐的框的特征转换成任意方向上的特征。
2.4 损失函数
在单阶段图像识别中,正样本仅占很少的一部分,更多的负样本对训练没有帮助。本次实验不使用传统的交叉熵损失函数,改为使用能解决正负样本不平衡问题的Focal Loss损失函数。
Focal Loss损失函数定义如下:
LossF=-(1-pt)γlog(pt)
(14)
其中:γ是范围在[0,5]的参数,pt定义为
(15)
其中:p为模型属于前景的概率,y的取值为1和-1,分别代表前景和背景。(1-pt)γ作为一个调制因子,当背景容易分辨时,(1-pt)γ较低,说明对损失的贡献较小,即降低了易区分样本的损失比例。
由于SmoothL1损失函数对长宽比完全不敏感,所以本次实验在回归网络中使用均方误差损失,公式如下[24]:
(16)
其中:y为真实值,y0为预测值。
均方误差损失的优点在于函数曲线连续、光滑、处处可导,适用于梯度下降算法,并且误差减小时,损失也会减小,有利于收敛。即使使用固定的学习速率,也能很好地收敛到最小值。
在本文的SAN网络中,不同的网络模块损失函数的计算方式不同,视网膜模块损失函数的计算方法为
Losstotal=LossF+LossE
(17)
旋转检测模块损失函数的计算方法为
(18)
3 实验(Experiment)
3.1 数据集
DOTA[25]是一个用于定向目标检测的大型航空图像数据集,目前一共有DOTA1.0、DOTA1.5、DOTA2.0三个版本。DOTA1.0包含2 806张800×800~4 000×4 000的图像和188 282个实例,包含15个常见目标类别:飞机(PL)、棒球场(BD)、桥梁(BR)、田径场(GTF)、小型车辆(SV)、大型车辆(LV)、船舶(SH)、网球场(TC)、篮球场(BC)、储罐(ST)、足球场(SBF)、环岛(RA)、港口(HA)、游泳池(SP)和直升机(HC)。其中,数据集的1.5版本使用了和1.0版本相同的图片,但是额外标注了非常小的目标(小于10个像素),并且多了一个类别(集装箱起重机,CC),而DOTA2.0包含了18个类别,并且有11 268张图像和1 793 658个实例。与DOTA v1.5相比,DOTA2.0进一步增加了新的图像类别。
DOTA数据集提供了训练集、验证集和测试集,其中测试集的数据不公开。将训练集和验证集的数据都用于训练。在DOTA之后,从原始图像中裁剪了一系列1 024×1 024的补丁,步幅为824。为了避免过拟合,没有使用其他技巧。
HRSC2016是一个带有旋转框的船舶检测数据集,包含1 061张船舶的遥感图像,大小范围为300×300~1 500×900。训练集、验证集和测试集分别包含436、181和444张图像。使用训练集、验证集进行训练,测试集用于测试。根据原网络的设置不同,把所有图像的大小改为800×512或者512×800,但不改变图像的长宽比。训练过程采用随机翻转方式,随机翻转的方向包含水平和竖直方向。
3.2 实验设置
本次实验在两张NVIDIA RTX A4000的环境下运行,实验都使用ResNet50初始化。所有网络使用同样的参数设置,学习率为0.002 5,动量和动量衰减分别为0.9和0.000 1,在DOTA数据集下,epoch为12,在HRSC2016数据集中,epoch为36。使用SGD梯度衰减。
在DOTA数据集中,本次实验采用平均精度均值(mAP)作为评价指标,此评价指标被PASCAL VOC、COCO、ImageNET、Google Open Image Challenge等图像检测比赛所使用。在mAP的计算中,涉及以下概念。
TP:实际为正样本,同时被分类器划分为正样本的样本数。
FP:实际为正样本,但是被分类器划分为负样本的样本数。
FN:实际为负样本,但是被分类器划分为正样本的样本数。
TN:实际为负样本,同时被分类器划分为负样本的样本数。
召回率Recall的计算方式为
(19)
准确率Precision的计算方式为
(20)
P-R曲线是所有Precision-Recall点连成的曲线,用于计算AP值。通常,P在纵轴,R在横轴,P值越高,R值越低。AP值就是P-R曲线围成的面积,由于检测精度需要IoU作为度量的边界,使用不同IoU度量的P-R曲线的AP值也不同,mAP是使用不同IoU得出的AP值的均值。AP50是IoU阈值取0.5时得出的AP值,研究人员在HRSC2016数据集中使用此评判方法。
将典型的Rotate Retina Net(RR)作为基线,视网膜网络作为单级检测器检测速度快,但也会因为添加了模块而增加了计算量。视网膜网络的焦点损失表现较好,在当时精度超过了二级检测器,计算速度超过了单级检测器,是一个很好的挑战目标。
3.3 实验结果
表1是本文方法与当前的主流网络的精度对比结果,表1中有些网络的名称使用缩写,黑体数字下划线表示类别中最高的精度,黑体数字表示次高的精度,可以看到,本文方法的mAP比基线方法提高了13.2%,比当前主流网络有了较大的提升,并且对难以识别的一些目标(直升机、田径场、大型汽车)也表现出最优的检测效果。在大长宽比的物体识别中,对比其他的网络的mAP也有较大的提升,说明网络改进的方向是正确的。

表1 本文方法与各个主流网络的精度比较
对网络进行消融实验,分别对网络是否添加了椭圆损失函数、对齐卷积和均方误差损失做了对比,如表2所示,对齐卷积网络模块能让网络学习到角度信息、椭圆损失函数能够更加精确地计算交并比、均方误差损失函数能优化梯度计算。从表2中可以看到,当使用了更多的对齐卷积或者卷积函数时,精度会比没使用或者使用更少的方法高,证明每个模块的引用是有意义的。
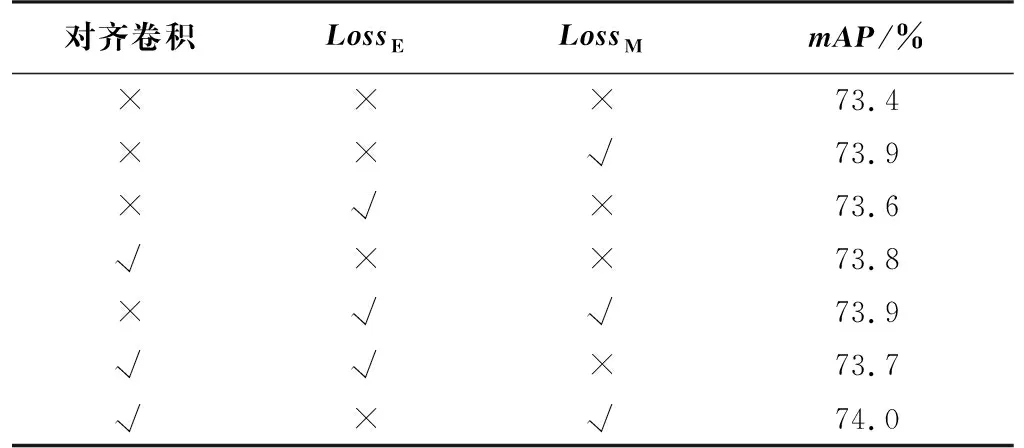
表2 使用不同算法的结果
替换旋转检测网络模块中的回归损失函数,比较结果如表3所示,从表3中可以看到,在相同的网络下,均方误差损失在本文方法里发挥的最好,均方误差损失便于梯度下降和利于收敛的性质更契合本文网络,并且模块的增多也会相应地提升精确率。

表3 本文方法与其他损失函数的比较
表4是本文方法与其他主流方法在HRSC2016数据集上的结果。我们用AP50作为评判标准。在HRSC2016数据集上,本文所提网络的精确率比基线提高了15.5%,并且优于当前的主流方法。HRSC2016数据集包含的船舶目标都是任意方向和大长宽比的,表明本文所提网络在遥感图像识别领域的表现出色。
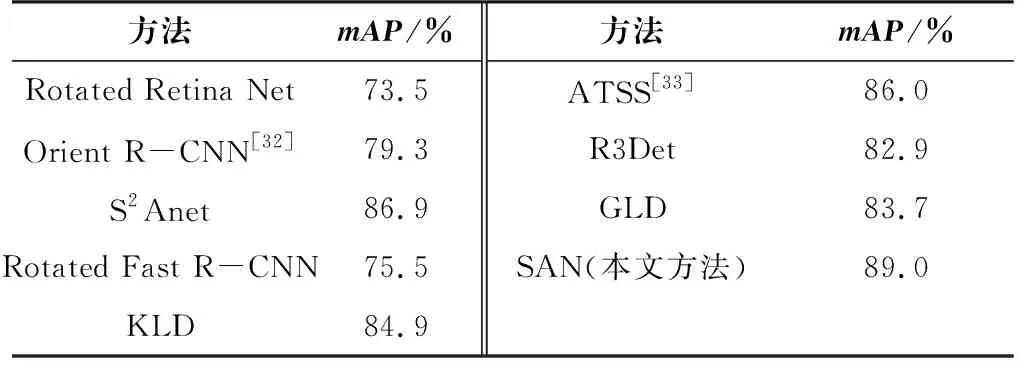
表4 各方法在HRSC2016数据集上的结果
图4是DOTA实例的识别结果。对于相同的图像,图4(b)和图4(d)是本文网络的实验结果,图4(a)和图4(c)是基线的实验结果。基线网络对于角度的回归不是很稳定,会出现检测框大小正确,但方向有误的情况。图4(a)和图4(b)展示了常见的遥感图像,从中可以看出遥感图像的目标更加密集,本文方法对于每个目标的置信度相对于基线方法更高,并且旋转框的定位更加准确,在图像尺寸明显增大的情况下,基线方法有较大的缺点:旋转框的定位不精确,会出现明显的角度偏差,并且由于图像尺寸过大,导致某些目标难以检测。本网络显著提升了定位精度和置信度,也能检测出基线网络检测不出来的实例。

(a)基线方法
4 结论(Conclusion)
本文研究了遥感目标检测技术的发展现状以及目前存在的问题,提出了一种使用椭圆旋转框和对齐卷积的单阶段检测网络。使用高斯分布将矩形锚框转变为椭圆锚框,有效弥补了水平锚框因为角度偏差出现的IoU与实际精度不匹配的缺陷。同时,引入对齐卷积网络模块与协变性特征,解决定位精度和分类分数不高的问题。本文方法和其他主流网络比较,具有明显的优势,在现阶段流行的数据集中取得了优于主流算法的精度。在将来的工作中,要进一步考虑当前算法对于小目标实例召回率不高的问题,通过添加对小目标友好的网络模型子网络分支与显著性模块增强等方式,逐步提升小目标的召回率。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
数字通信世界(2021年3期)2021-04-09 02:05:00
湖北理工学院学报(2020年4期)2020-08-22 06:43:26
今日农业(2019年15期)2019-01-03 12:11:33
中国交通信息化(2017年9期)2017-06-06 07:14:57
计算机应用与软件(2017年4期)2017-04-24 10:39:07
工业设计(2016年11期)2016-04-16 02:49:43
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
河南科技(2014年22期)2014-02-27 14:18:12
