
基于逆向技术的深层网络爬虫与数据分析
2023-12-06 11:33邢羽琪
软件工程 2023年12期
邢羽琪, 杨 柽
(云南民族大学数学与计算机科学学院, 云南 昆明 650500)
0 引言(Introduction)
互联网经济时代,数据既是基础性资源也是战略性资源,更是重要的生产力,对各行各业的发展都有着重要影响[1]。在大数据架构中,网络爬虫技术作为数据获取的重要技术近年来得以快速发展。另一方面,Ajax(Asynchronous Javascript And XML,异步的JavaScript和XML)技术在Web站点中的使用却增加了数据采集的难度。Ajax可以实现浏览器与服务器的异步通信,提升Web站点的响应能力。XML是一种描述、存储、传输数据的标记语言。Ajax通过使用XMLHttpRequest对象从服务器异步请求数据,并将响应数据以XML格式返回。Ajax技术可以在不刷新整个页面的情况下更新局部内容,许多网站采用了动态生成页面内容的方式。这使得爬取网页变得更复杂,网页中的内容可能在用户与页面交互过程中动态加载或改变。爬虫需要解析JavaScript代码,并模拟用户与页面的交互过程,以获取最终的完整内容。
如今,大部分Web站点都采用Ajax动态请求、异步刷新方式生成数据,使得采取Python爬虫爬取静态网页的方法难以直接提取动态网页数据[2-3]。本文在前人研究方法的基础上,依据静态网址信息构造动态请求链接,以爬取某购物网站评论数据的过程为例,详细描述了构造动态网页URL的全过程,可为Ajax动态数据采集技术的研究提供参考。
1 JS逆向(JS reverse)
JavaScript(通常缩写为JS)是一种高级、解释型的编程语言,它的解释器被称为JavaScript引擎,是浏览器的一部分,广泛用于HTML网页,增强了网页的互动性。通过对JavaScript源代码进行混淆加密,既可以做到网页打开的速度和加密前相差不大,又可以做到加密结果不可逆,提高数据的安全性。但是,对于爬虫技术而言,JS加密的应用会成为影响数据分析人员采集数据的瓶颈。当前,JS逆向技术是应对以上瓶颈的有效措施[4]。JS逆向技术实质上是根据结果向前推导,分析构造URL所需的参数,找出后台参数生成原理(即参数加密过程),动态模拟浏览器JS生成结果,并最终获取目标数据的过程。实施JS逆向技术的难点是需要在被改写的源代码中破解加密算法、拆解相关参数。基于此,本文以某购物网站商品评论页面为例,采用JS逆向技术,使用Python程序还原参数加密过程,构造完整目标网页的URL信息,实现Python环境下的JS逆向技术爬取商品评论数据,同时进行简单的数据挖掘,使整个数据分析过程完整。
2 评论爬取过程分析(Analysis of comment crawling process)
爬虫可以分为搜索引擎网络爬虫、基于Agent的网络爬虫、迁移的网络爬虫、通用网络爬虫和聚焦爬虫等[5]。根据要爬取的Web页面的存在方式,又可将爬虫分为表层网络爬虫和深层网络爬虫。表层网络爬虫通常用于爬取以表层网页(即静态网页)为主的Web站点。本文的目标购物网站需要用户登录、提交关键词才能动态生成相应页面,是典型的由深层网页构成的网站,需要使用深层网络爬虫技术,动态构造URL请求信息,才能批量爬取指定数量的商品评论信息。基于Python的JS逆向技术爬虫算法流程图如图1所示。
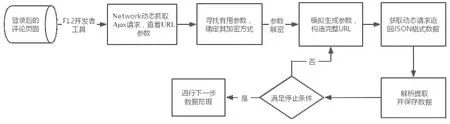
图1 基于Python的JS逆向技术爬虫算法流程图Fig.1 Flow chart of Python-based JS reverse technology crawler algorithm
2.1 构造URL
2.1.1 查看URL构成
静态网页是指不应用程序而直接或间接制作成HTML的网页,每一个页面都有一个固定的URL地址,可以使用Python代码直接获取网页的URL和相应的HTML信息。动态网页一般使用脚本语言(PHP、ASP等)将网站内容存储于数据库中,由于Python无法直接获取URL动态链接,因此爬取内容时需要动态构造URL链接。
在某购物网站商品评论页面,利用F12开发者工具,选择Network模块,再筛选XHR请求,刷新网页并不断下拉页,使开发者工具可以抓取到多个动态Ajax请求,选中其中一个重点查看URL的请求头(图2)。

图2 获取动态Ajax请求并查看URLFig.2 Obtaining dynamic Ajax requests and viewing URLs
2.1.2 确定请求头中的加密参数
在动态URL构造过程中,URL参数的变化信息一般可以在相关静态URL及源代码中寻找。通过多次请求分析,利用静态的URL地址的变化构造动态链接,从而实现数据采集程序自动对动态网页的爬取。
对比多个页面URL内容,最终确定“t”“sign”“data”三个动态变化且对采集有效的参数,观察多次请求的返回结果,发现参数“t”为13位时间戳,“sign”为加密参数,“data”为商品查询参数。由此,进入本研究的难点环节,即逆向破解参数的加密方式以及构造动态URL。多个页面URL参数对比内容如图3所示。
2.1.3 推导参数“sign”加密方式
推导参数“sign”的加密方式,具体步骤如下。
步骤1:在控制台中使用length()函数查看参数“sign”的长度,结果显示32位,由此初步推测该网站采用MD5加密算法。
步骤2:使用全局搜索查找“sign”,返回21条相关数据,发现返回的js文件中多次出现了“sign”,经逐一排查,排除若干干扰项,最终在mtop.js文件中追溯到参数“sign”。
步骤3:查看mtop.js文件的源代码,从中筛选出纯参数数据,在其位置打上断点并进行编译。断点查看参数“sign”加密方式如图4所示。
步骤4:查看运行过程得知,构成参数“sign”的信息包括参数“i”“d.token”“g”“c.data”和函数“h”,对其逐一分析发现。参数“i”为实时生成的13位时间戳信息;参数“g”由“||”语法得出,“c”是参数对象,因此“g”为请求头中的appKey,是一个定值;参数“c.data”与参数“g”同理,也是参数对象的“data”字段;参数“d.token”是放在cookie信息中的m_h5_tk值。对于函数“h”,前文已根据加密结果为32位信息推测该网站使用的是MD5加密算法,现将上述内容拼接的原始参数使用MD5在线加密器计算结果,同时使用断点测试程序查看加密后的结果,对比两者发现结果一致,验证了之前函数“h”为MD5加密函数的推测。对比函数“h”与MD5在线加密器结果如图5所示。

图5 对比函数“h”与MD5在线加密器结果Fig.5 Online encryptor results comparison of “h” function and MD5
步骤5:根据断点运行过程,逐步查看各参数构成方式,据此拼接完整的参数“sign”。
2.1.4 模拟生成URL
分析URL的构成,使用Python编写程序,具体为自定义时间戳和随机数,生成并拼接“t”“sign”“data”参数,构造完整的URL信息,对整个访问请求进行模拟并获得响应。将上述参数拼接成完整的URL,用requests的get/post方法发送请求并接收数据res=requests.get(url=url,headers=headers).content,返回得到JSON格式数据。
2.2 数据提取
JSON作为一种轻量级的数据交换格式,结构简单紧凑,是互联网上常用的数据传输与交换格式。JSON有两种结构形式,一是键值对形式,以“{”开始,以“}”结束,中间部分由0个或者多个“,”分隔的键值对构成,是一个无序的“‘名称/值’对”集合;二是数组形式,以“[”开始,以“]”结束,是一个值的有序集合。本次爬取返回的结果是以上两种情况的嵌套,需要通过分析找到所需数据所在层次,即res[′data′][′module′][′reviewVOList′]。之后,可利用Python爬虫解析库逐条分别提取评论用户、商品详情、评论时间及评论内容等信息。评论页面JSON代码的嵌套关系如图6所示。

图6 评论页面JSON代码的嵌套关系Fig.6 Nested relationship of JSON code for comment pages
2.3 数据保存
使用pip安装第三方库,以及对应的数据库软件,可以将结果保存至MySQL、MongoDB等数据库中。本文选择自定义saveCsv()函数,将爬取结果保存至csv文件中,实现该步骤的代码段如下。
def saveCsv(datas):
with open(′result.csv′,′a′,newline=″)as f:
csvwriter = csv.writer(f)
csvwriter.writerow([datas[′uid′],datas[′评论用户′],datas[′评论时间′],datas[′评论内容′]])
2.4 结果分析
按照上述流程,本文共获取该网站乐高商品数据356条,爬取数据样本示例如表1所示。

表1 爬取数据样本示例
2.5 特殊情况
2.5.1 应对反爬
(1)请求头。爬虫可以在程序中添加请求头信息达到伪装成浏览器的目的,从而实现反反爬机制,程序为res=requests.get(url=url,headers=headers),其中url为请求网页地址,headers为开发者工具中获取的“User-Agent”请求头信息[6]。
(2)Cookie。部分需要登录的网站,需要添加cookie信息。由于cookie具有生命周期,因此本研究在程序设计上采用分部爬取(20页信息为一个部分)方式,爬取间隔更换cookie信息,防止反爬。
(3)Token。Token实质是访问资源的凭证,一般是用户通过用户名和密码登录成功后,服务器将登录凭证作为数字签名,加密之后得到的字符串即token。查找源代码发现token就是放在cookie中的m_h5_tk值,并且token值也存在生命周期,需要定期更换。
2.5.2 遵守robot协议
在使用爬虫进行数据采集的过程中,应注意遵守对方网站robot协议的规定,本文在实验过程中充分考虑到这一点,在采集程序加入time.sleep(10)语句用于将爬虫访问的频率近似到类人水平[3]。
3 数据挖掘(Data mining)
3.1 数据预处理
由于商品的评论内容是日常口语评论,所以文本存在语言随性、表达多样、噪声大、语言不唯一等情况,进行数据清洗可以让评论文本更加简洁明了。因此,本文对“评论内容”属性列进行去除空格、网址、日期及时间等处理。
3.2 Jieba分词
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自然语言处理时,通常需要先进行分词。jieba分词支持三种分词模式,即精确模式、全模式、搜索引擎模式[7]。精确模式是将句子精确地切分,更适用于文本分析;全模式是把句子中所有可以成词的词语扫描出来,较为烦琐;搜索引擎模式是在精确模式的基础上,对长词再次切分,更适用于搜索引擎数据的分词。基于本研究中爬取的数据全部为文本数据,因此采用精确模式jieba.lcut( )对评论内容进行分词,为情感分析环节奠定基础。
3.3 SnowNLP情感分析
SnowNLP是一个功能强大的中文文本处理库,它具有中文分词、词性标注、情感分析、文本分类、关键字/摘要提取、TF/IDF、文本相似度等诸多功能[8]。SnowNLP利用机器学习和自然语言处理技术,对文本进行情感分析,将其归类为积极、消极或中性等情感类别,并给出相应的情感得分emotion。emotion是一个介于0到1的实数,其中0表示强烈的消极情感,1表示强烈的积极情感,中间的值表示中性或较弱的情感倾向。
3.3.1 情感得分
使用SnowNLP模块对评论进行情感打分,得分示例如表2 所示。由SnowNLP模块计算可知,emotion的平均值约为0.61,中位数约为0.81,单纯从评论情感分来看,得出好评多于差评的结果。

表2 SnowNLP情感得分示例
3.3.2 绘制情感分直方图
使用matplotlib.pyplot库绘制情感分直方图(图7)。

图7 情感分直方图Fig.7 Histogram of sentiment score
由图7可以看出,大部分用户的评论情感分较高,介于0.8~1.0,反映出用户对于乐高销售的整体反响较好,态度积极向上;但也存在部分得分相对较低评论,并且绝大部分得分介于0.0~0.2,这也对商家起到了警示作用,需要注重用户反馈的信息,及时采取措施纠正或完善。总体来说,评论数据情感分布两级分化较为严重,提醒商家需要调整销售策略,做到扬长避短。
3.3.3 划分积极评论
根据情感评分模型的特点,观察得到当评论为“不错”时,输出得分为0.861 213;评论为“好”时,输出得分为0.655 863;评论为“一般”时,输出得分为0.526 233。根据多条输出结果,判定情感倾向的标准是得分大于等于0.6时,可认定为积极态度评论,统计得到积极评论数量为235条且占比约为66%,绘制其积极评论占比图如图8所示。
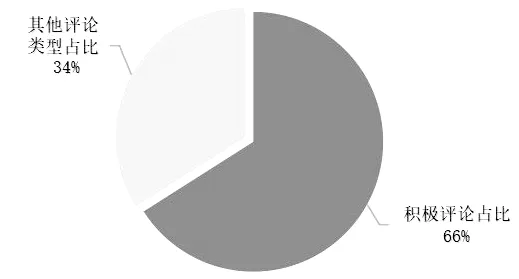
图8 积极评论占比图Fig.8 Proportion of positive comments
根据图8得知大部分用户对乐高商品较为满意,可进一步挖掘积极态度的评论,探究用户评论高频词,帮助商家调整销售策略,做到优势最大化。
3.3.4 提取评论高频词
对上述划分为积极态度的评论内容进行分词并按词频统计,提取评论中出现的高频词,并绘制评论高频词云图(图9)。

图9 评论高频词云图Fig.9 Word cloud diagram of high frequency comments
根据词频展示结果,可以清楚地看到“喜欢”“不错”等字眼占据评论数据的主要地位,“快递”“盒子”“包装”等词汇显示出乐高玩具的用户比较注重快递包装外观,乐高销售商可在这个方面进一步做提升,获得更高的用户满意度。
4 结论(Conclusion)
目前,JS逆向技术俨然成为爬虫领域的重要探索工具:首先通过对网页的结构进行分析,找出请求信息中的加密参数;其次通过断点技术,寻找有用参数的加密流程;最后模拟浏览器动态构造请求信息获得数据。与传统的爬虫技术相比,整个爬取过程的复杂度和难度都增加了。本文在前人研究的基础上,以某购物网站乐高商品评论数据的爬取过程为例,基于Python语言采用JS逆向技术,详细描述JS逆向技术流程,批量爬取了多个商品的评论数据,并对其结果进行SnowNLP情感分析、提取评论高频词,挖掘乐高商品销售可能存在的优势与不足。所使用的爬虫算法及具体实践对使用了Ajax和JS加密的数据获取有一定的参考作用。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
音乐天地(音乐创作版)(2022年1期)2022-04-26
现代信息科技(2021年21期)2021-05-07
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
电子测试(2015年18期)2016-01-14
计算机与网络(2014年7期)2014-03-25
应用技术学报(2014年3期)2014-02-28
