
基于YOLOv7的道路监控车辆检测方法
2023-12-06 06:37蔡刘畅杨培峰张秋仪
陕西科技大学学报 2023年6期
蔡刘畅, 杨培峰, 张秋仪
(1.福建理工大学 计算机科学与数学学院, 福建 福州 350118; 2.福建理工大学 建筑与城乡规划学院, 福建 福州 350118)
0 引言
目标检测广泛应用于交通场景中,比如视频监控、自动驾驶、车牌识别、车流检测等.交通监控的普及产生了海量交通图片视频,使智能交通系统日益备受关注,智能交通系统可以通过交通监控分析车流状态,以实现交通智能化管理以及道路规划.车辆目标检测是智能交通系统重要的一环,如识别车辆、分类车型、检测超速和逆行等.
为了实现高效的车辆目标检测,已经有学者研究智能化检测方法,研究包括机器学习以及与深度学习有关的识别方法.
基于机器学习的车辆检测步骤分为特征提取和分类器训练.特征提取方法有Haar/Haar-like[1,2]、方向梯度直方图[3,4](Histogram of Oriented Gridients,HOG)和变型部件模型[5](Deformable Parts Model,DPM),它们在车辆的类型状态发生改变时仍稳定提取特征,在车辆检测中有良好效果.尺度不变特征变换[6,7](Scale-invariant Feature Transform,SIFT)、加速稳健特征[8](Speeded-Up Robust Features,SURF)、局部二值模式[9,10](Local Binary Pattern,LBP)特征提取方法可以产生更丰富的车辆检测特征.提取的特征用于训练分类器,从而使用分类器识别车辆目标.而分类器需要平衡泛化能力和拟合精度,常用的分类器有K-近邻算法[11](K-Nearest Neighbor,KNN)、支持向量机[12](Support Vector Machine,SVM)、决策树[13]和自适应提升算法[14](Adaptive boosting,AdaBoost).但是传统方法检测过程被分解为多个步骤,缺乏实时性.其检测精度不高、泛化能力不强.
深度学习方法根据车辆检测过程分为两步检测和单步检测两种方法.前者分为预测车辆区域和从预测区域中检测车辆目标两个阶段,典型的方法有基于区域的卷积神经网络[15](Region-based Convolutional Neural Networks,R-CNN)、空间金字塔池化网络[16,17](Spatial Pyramid Pooling Networks,SPP-Net)、基于区域的快速卷积网络方法[18,19](Fast Region-based Convolutional Network,Faster R-CNN).后者把车辆识别和检测整合到同一个网络中,不先预测车辆区域.典型的方法有单发多框检测器[20](Single Shot Multibox Detector,SDD)、YOLO[21-23]( You Only Look Once)、多级特征金字塔目标检测[24](Multi-Level Multi-Scale Detector, M2Det);两步检测方法的准确性普遍高于一级检测方法,但单步检测方法更具有实时性[25].随着单步检测方法的不断改进,其检测准确度得到改善,逐渐适用于要求高检测精度的车辆目标识别场景.深度学习方法的端到端结构,将特征提取和anchor box集成到一个网络中,提高了车辆目标检测速度,增强了目标检测在实际应用中的实时性.
目前,目标检测算法已经达到了较高的准确率.但针对道路监控下的车辆目标检测存在两方面的不足,一方面,检测算法需要较强算力的设备.车辆检测算法可以部署到嵌入式设备中,从而减少推理延迟.但嵌入设备计算能力不强,存储空间有限,因此将车辆检测算法进行轻量化处理,使其可以部署在计算能力不强、储存空间有限的嵌入式设备.另一方面,小目标检测精度不高.由于道路上的监控摄像头往往是俯视视角,导致部分车辆目标较小含有的图像信息少,如远处的轿车或摩托车.因此检测小目标车辆存在精度不高的问题.
YOLO模型更适合应用于实际交通场景的目标检测[25].在实际应用中目标检测的实时性发挥着越来越重要的作用,单步检测模型如SDD、YOLO,采用回归方法检测对象,操作速度更高.但SDD没有考虑到不同尺度之间的关系,在检测小目标方面有一定的局限性.而YOLO更容易学习一般特征,运算速度更高.目前,在FPS为5~160范围内,YOLO v7模型的速度和精度都超过了所有已知的目标检测模型[26].
因此,本文选择YOLOv7作为基础车辆检测方法,以提升精确度、降低模型体量为方向,优化YOLOv7车辆检测方法.将YOLOv7主干网络替换为高效的网络GhostNet.为了在轻量化的同时保证检测精确度,通过对有效特征层添加通道注意力机制,模型的特征提取能力得到增强.最后将改进的模型在自主构建的数据集上进行试验,并与其他常用模型进行检测性能对比,以期为监控视角下的车辆识别分类提供一种轻量化的检测方法.
1 相关理论基础
1.1 YOLOv7概述
YOLOv7[27]是一个单阶段的目标检测算法, 分为3部分.首先通过主干网络,将输入图像的尺寸调整为640×640大小,采用多分支堆叠结构,利用最大池化和2×2的卷积核提取特征,最终形成三个有效特征层.
为了捕捉更准确的车辆特征,对不同尺度的特征层进行结合,得到三个加强的有效特征层,其结构如图1加强特征提取网络部分所示,特征层包含特征点,特征点上有三个先验框.利用三个增强的特征层,从多个特征中抽取出最优的,实现多维的特征融合.YOLOv7为了提高效率,训练过程中,将每个真实框分配给多个先验框,更有针对性地进行预测,预测框与先验框对比调整后,更有效地确定符合真实框的先验框.
为了提高特征提取网络的性能,YOLOv7用空间金字塔池化(Spatial Pyramid Pooling,SPP)结构来扩大感受野,并且在其中添加一个大的残差边,以便将最大池化操作后输出的特征层堆叠起来优化和提取特征.其结构如图1中包含上下文信息的空间金字塔池化卷积 (Spatial Pyramid Pooling with Contextualized Spatial Pyramid Convolution,SPPCSPC)部分所示.基于感受野块的卷积神经网络[28](Receptive Field Block-based Convolutional Neural Network,RepConv)模块用一种重参数化的方法,降低网络的复杂性,改善模型的性能.训练时,给3× 3的卷积添加1×1的分支,部署时,将分支的参数通过重参数化整合为一个分支,在3×3 主分支卷积输出,从而降低训练的复杂性.Yolo Head部分是YOLOv7的分类器,用于分类特征点对应的先验框.
1.2 GhostNet概述
GhostNet[29]网络由华为诺亚方舟实验室在2020年发布,优势在于轻量化.通过计算量较小的线性处理,生成冗余的特征,从而实现准确检测,同时还可以降低网络的复杂度.
网络利用Ghost Bottleneck的堆积来实现,Ghost Module是Ghost Bottleneck的组成部分,Ghost Module 用1×1卷积来调整输入特征层的维度,之后用深度可分离卷积得到相似特征图.Ghost Bottlenecks由Ghost Mudule、残差边以及2×2的深度可分离卷积构成,其中,2×2卷积对图像的宽、高进行压缩.
Ghost Bottlenect根据卷积核步长s的不同,分为两类,s=2表示输入进来的特征层需要被压缩时,此时在GhostModule中加入分组卷积层,步长为2.在残差边中加入s=2的分组卷积,1×1的普通卷积.Ghost Bottlenect结构如图2所示.
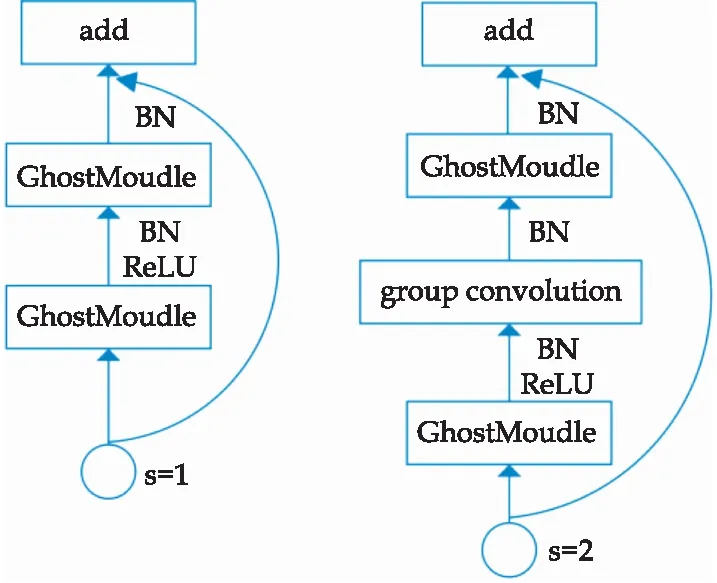
图2 Ghost Bottlenect网络结构
2 改进的YOLOv7算法
2.1 网络架构
本文通过使用 GhostNet来代替主干部分,以达到在确保检测准确性良好的前提下,尽可能缩减模型参数.改进后YOLOv7网络如前述图1的主干特征提取网络部分所示.
GhostNet 模块可以有效地替代传统的卷积操作,将传统卷积生成的特征分为两部分输出,首先通过卷积核计算得出一部分特征,再通过线性操作的方式使已生成的特征输出另一部分特征.而传统卷积操作生成的特征都是通过卷积核计算得到.通过线性操作的方法,GhostNet 模块可以有效地减少参数量,同时保持输出特征的大小不变,从而使得计算复杂度低于传统的卷积神经网络.
GhostMoudle和传统卷积输出特征的参数量分别如式(1)和式(2)所示,计算量分别如式(3)和式(4)所示.

(1)
paramenters=ksize×ksize×cin×cout
(2)
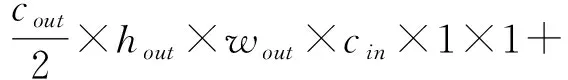
(3)
FLOPs=cout×hout×wout×cin×ksize×ksize
(4)
式(1)~(4)中:k表示卷积核的大小;c表示通道数,h和w表示图片的高和宽,out和in表示输出和输入图.
通过比较式 (1)~(4),GhostMoudle网络的计算量和参数量与普通卷积操作比值小于1,如式(5)所示.由此可知,采用GhostNet作为YOLOv7的特征提取,能够显著减少模型的参数.
(5)
2.2 融合高效的注意力机制模块
通过GhostNet结合YOLOv7,可以降低模型的复杂性.但是,由于计算量及相关参数的减少,导致了检测的准确性受到影响,因此,将YOLOv7的特征层添加注意力机制,以此来改善其特征提取的性能.
高效通道注意力[30](Efficient Channel Attention,ECA)是一种通道注意力机制.ECA用一维卷积代替SENet(Squeeze-and-Excitation Networks)的全连接层(Full Connection,FC),减少了参数,并且可以有效地交换多个通道之间的信息,从而更好地识别出各个通道之间的权重及其对应的关联,其结构如图3所示.假设W、H、C为特征图的宽、高和通道数.对每个特征图全局平均池化操作,以获取图3中1×1×C的特征图.然后,设卷积核大小k=5,将特征图卷积后经过 Sigmoid 激活函数,再与原输入的特征图相乘,从而获取最终的输出特征图.本文选用了ECA模块来提取特征,是因为相比于其他主流的注意力机制如SENet、通道注意力(Channel Attention,CA)和卷积块注意力模块(Convolutional Block Attention Module,CBAM) 模块,ECA 模块更有效提取图片关键特征点.
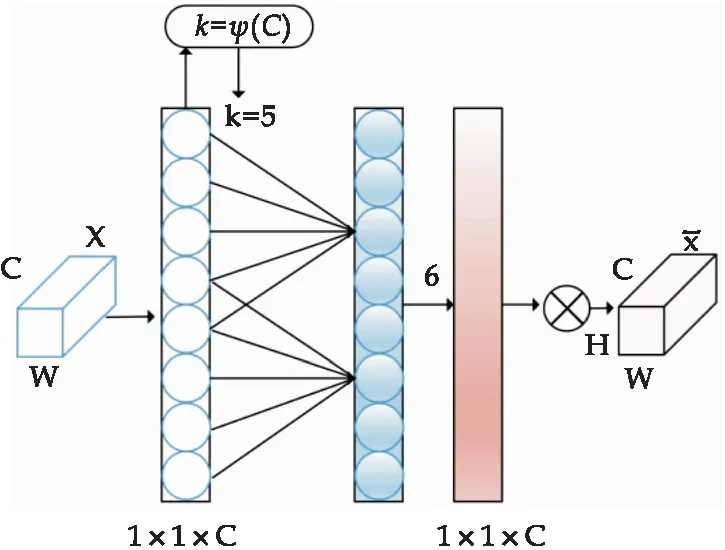
图3 ECA模型结构
基于YOLOv7结合GhostNet的网络结构,添加不同注意力机制进行对比实验,具体参数设置如3.3实验参数所示.在文中数据集上,实验结果为使用ECA模块改进的YOLOv7的mAP为90.37%,替换为SENet后mAP为89.32%,替换为CBAM模块后mAP为88.45%,替换为CA后mAP为88.47%.通过实验对比得出,选用ECA为改进YOLOv7的较好选择.
结合GhostNet和YOLOv7,用GhostNet替换YOLOv7的主干网络,针对经过堆叠的Ghostbottlenect输出的三个有效特征层,增加通道注意力机制ECA后,最终生成的基于YOLOv7的车辆检测方法网络模型结构如图1所示.
3 实验结果分析
3.1 车辆数据集
车辆检测数据集源于福州交警发布的实时路况.为模拟真实的道路监控拍摄情况,录制了福州市福飞路往森林公园路段和贵新隧道的实时监控视频,对监控视频进行分帧,设置图像大小为1 920*1 080.
3.2 数据标注
通过使用LabelImg工具,标注目标为三类:large vehicle(包括公交车和货车)、medium(包括轿车和面包车)和compact car(包括摩托车).共标注6 121张图片,各类别目标数量分别有3 515、14 723和1 151个,如表1所示.
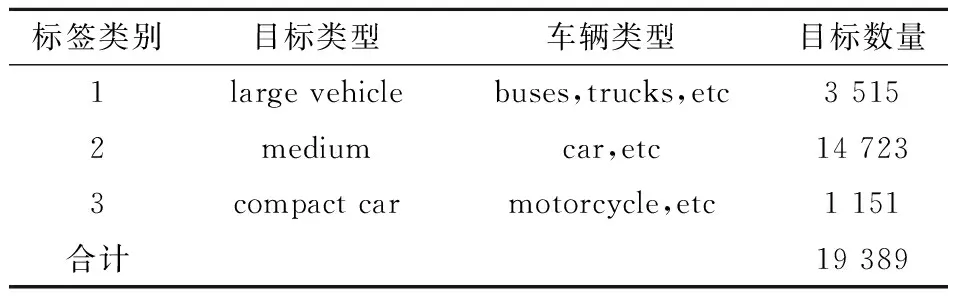
表1 三种目标及标签
3.3 参数设置
模型总共训练epoch=180,batch_size=4,最大学习率Init_lr=le-2,最小学习率=Init_lr×0.01,优化器SDG中动量参数momentum=0.937,权值衰减weight_decay=5e-4,学习率下降方式lr_decay_type=“cos”.
3.4 实验环境
实验配置为 Intel®Core i9-10900K CPU @3.70 GHz,内存是64 GB,GPU是NVIDIA GeForce RTX3070,pytorch版本1.7.0;Cuda版本11.6;python版本3.8.10.
3.5 性能指标评价
评估改进的YOLOv7指标为mAP值(mean AveragePrecision),平均精度 (Average Precision, AP)、召回率(Recall,R)、精确率 (Precision,P)和F1(F1-Score) ,计算如式(6)~(9)所示:
(6)
(7)
(8)
(9)
式(6)~(9)中:TP表示正确检测个数,FP表示错误检测个数,FN表示检测个数,∑AP指所有缺陷类别的总AP值,N(class)指缺陷类别总数.
3.6 改进方法有效性评价
通过消融实验,观察YOLOv7网络性能受不同改进方法的影响,从而证明改进方法的有效性和必要性.对比结果如表2所示.

表2 消融实验结果对比
在表2中,“√”代表引入了对应方法,而“×”则代表未引用对应方法.首先对比GhostNet主干网络的效果,然后对比注意力机制ECA.实验中除了改进方法不同,其他参数均相同.由表2可知,本文把GhostNet引入YOLOv7主干部分,使得参数量由38.21 M降低至32.54 M,浮点计算量由106.48 G降低至48.206 G,权值文件缩小了15%.针对模型轻量化后检测精度降低的问题,对GhostNet输出的特征层添加了通道注意力机制,网络准确率较原始YOLOv7提高了1.73百分点.因此改进的YOLOv7相比原始YOLOv7方法,可以提高准确性,同时减少计算量和参数.
3.7 不同网络对比试验
本文将改进的YOLOv7与Faster-RCNN、YOLOv4、Tiny-YOLOv4和原始YOLOv7在自制数据集上进行车辆检测对比实验.对比结果如表3所示.
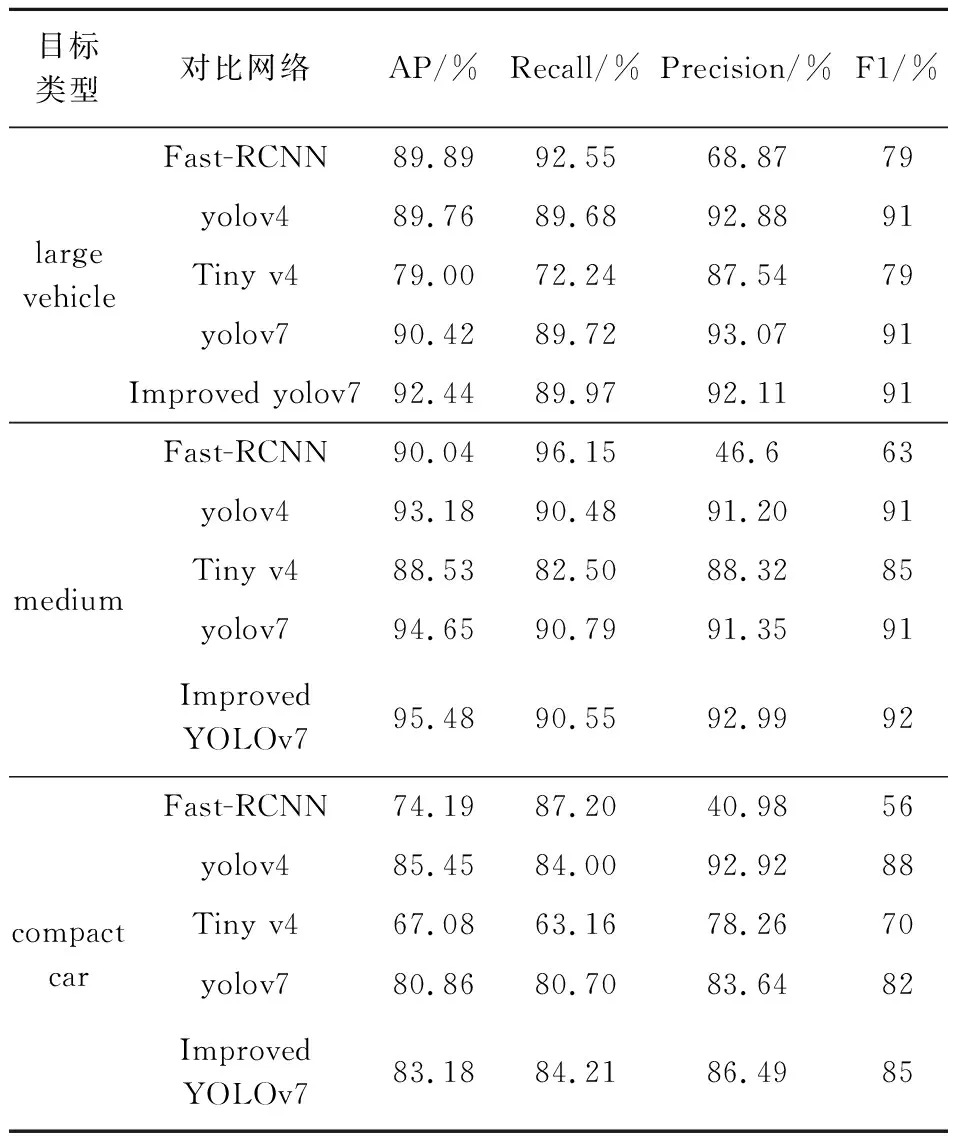
表3 不同网络性能对比
由表3可知,在大型、中型车辆检测中,改进的YOLOv7的准确率高于其他三类对比模型,在小型车辆检测中,改进的YOLOv7的检测精度低于YOLOv4,相比表3中其余检测方法总体较好.改进YOLOv7检测结果平均获得90.36%的精确度,88.24%的召回率,89.33%的F1值.比YOLOv7的指标分别提高了1.72个百分点、1.17个百分点、1.33个百分点.
为了评估改进的YOLOv7模型大小和检测速度,引入评价模型指标浮点运算量、参数量和每秒识别帧率 (Frames Per Second,FPS).用Fast-RCNN、原始YOLOv7、YOLOv4和TinyYOLOv4与改进YOLOv7对比.结果如表4所示.
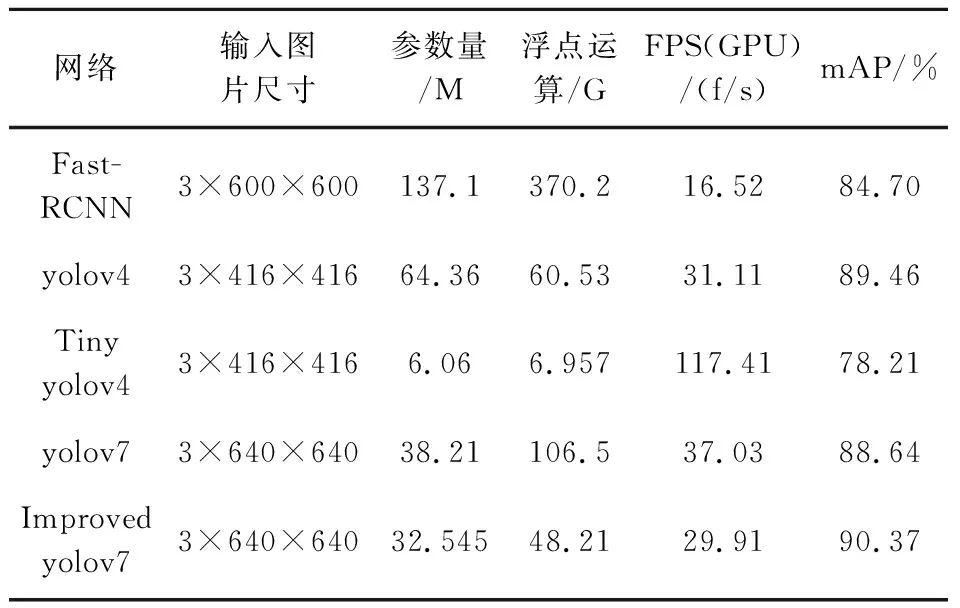
表4 网络模型复杂度对比
由表4可知,Tiny-YOLOv4模型的复杂度和运算速度最快,但是其检测准确率太低,特别是对于小目标检测的准确率仅67%.而改进的YOLOv7模型参数量和计算量在其余四种模型中最低,并且其精确度最高.因此,改进的YOLOv7在提高精确度的同时轻量化了原始模型,该方法可以为较低算力的设备应用车辆检测方法提供参考.
3.8 注意力机制对比试验
为了使提取到的特征具有更强的表观信息和语义信息,针对YOLOv7网络生成的三个有效特征层增加注意力机制.通过对比实验评估不同注意力机制对检测算法的影响,观察车辆检测算法的性能变化.对比效果如表5所示.
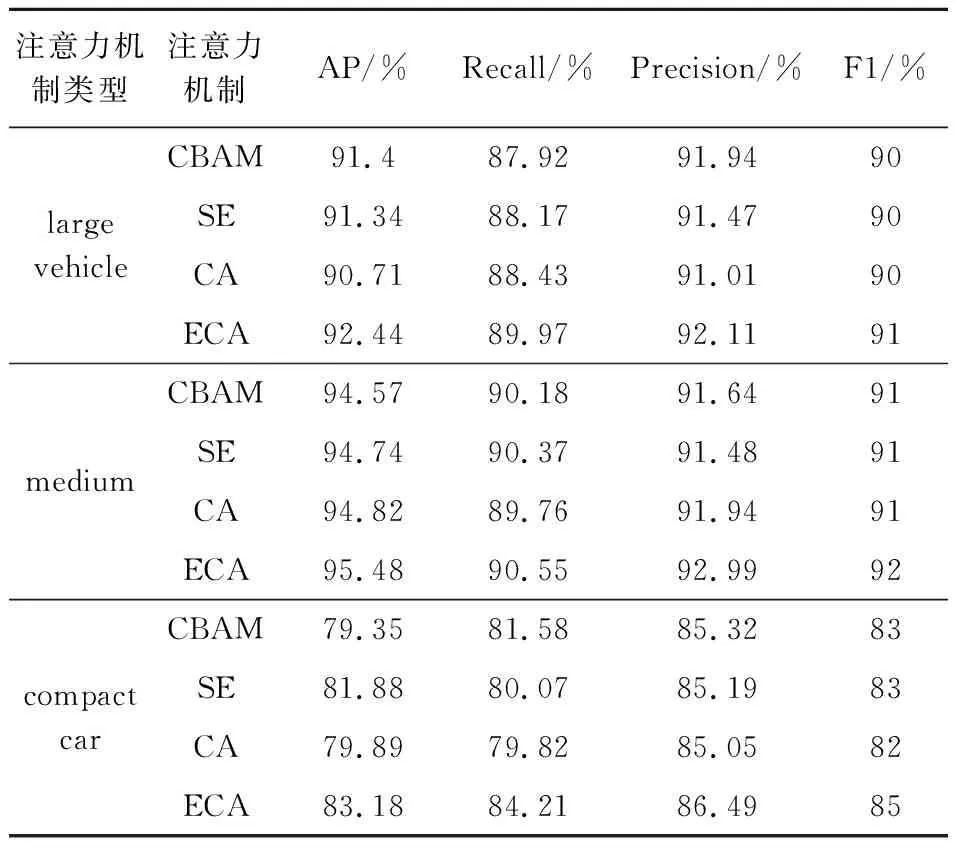
表5 不同注意力机制影响模型性能对比
添加ECA后,网络AP 为90.37%.添加CBAM后,网络mAP为88.45%.添加注意力机制SE后,网络mAP为89.32%.添加注意力机制CA后,网络mAP为88.47%.实验对比得出,在结合GhostNet的基础上,ECA对原始的YOLOv7的性能提升最明显,相比原始的YOLOv7的mAP提高了1.73百分点.
3.9 检测结果对比
为直观地表现本文算法更有效检测监控视角下车辆,图4~6展示了YOLOv7和改进YOLOv7的检测效果.在光线明亮的公路上,车辆无重叠或距离较远的情况,两类检测器对车辆的检测效果均良好;但是,当车辆较多以至遮挡、有小型车或较远的中大型车时,YOLOv7模型出现漏检,其检测效果比改进的YOLOv7 较差.

图4 摩托车检测对比
在光线明亮的场景中,当道路中出现小型车辆摩托车的情况下,如图4所示,原始的YOLOv7 存在摩托车小目标的漏检现象,改进的YOLOv7能检测出道路中的摩托车.
当多个车辆重叠遮挡的情况下,如图5所示,原始YOLOv7 检测算法可以检测出 8个目标,改进的 YOLOv7 检测算法共测出 11个车辆目标,包含被遮挡3个的车辆.
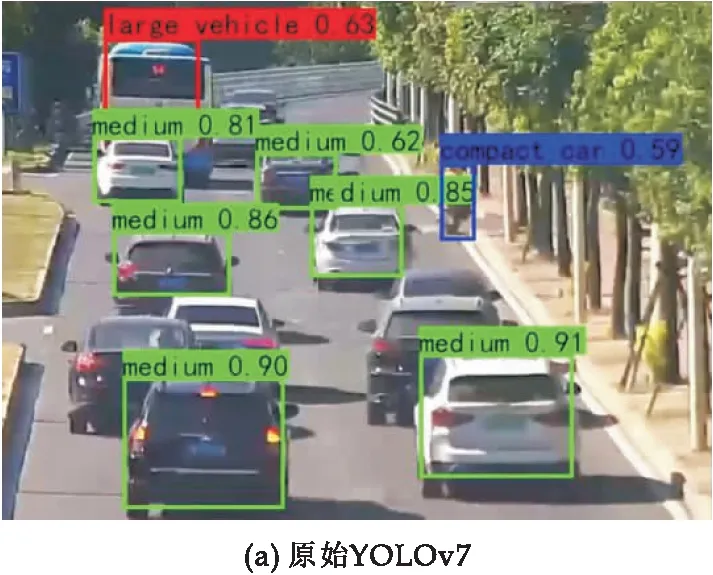
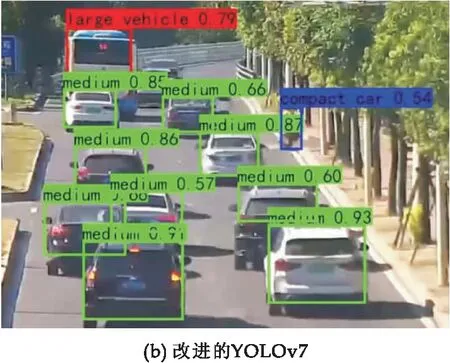
图5 遮挡车辆检测对比
在光线昏暗的隧道中,如图6所示,原始的YOLOv7检测出3个目标.改进的YOLOv7检测出4个目标,包含远处的1个型车辆目标.

图6 隧道小目标检测对比
通过分析可知,YOLOv7和改进的YOLOv7可以准确识别近处且未被遮挡的车辆,但是原始的 YOLOv7 漏检了部分被遮挡车辆、远处车辆和小型摩托车.相比原始的YOLOv7,改进的YOLOv7可以检测出更多遮挡车辆和远处的车辆.
4 结论
本文提出了一种改进的YOLOv7网络和道路监控相结合检测车辆的方法.基于自制的道路监控车辆数据集,使用GhostNet网络替换YOLOv7主干网络,减少模型参数和计算量.并在原始YOLOv7网络增加通道注意力机制模块聚焦车辆特征,提高检测精度.实验表明,针对道路监控下的小目标和不完整目标,本模型可以为道路监控的车辆提供辅助检测.通过对YOLOv7的优化,不仅实现了较精确的车辆识别,还减少了模型的计算复杂度,减少参数和权值文件大小,使车辆检测方法更适合于计算性能较弱、内存小的嵌入式设备.但优化过的算法仍有改进空间,如何保证准确率的前提下,提高检测的速度是下一步研究待解决的问题.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
阅读与作文(小学低年级版)(2016年12期)2016-12-22
第二课堂(课外活动版)(2016年2期)2016-10-21
汽车文摘(2015年11期)2015-12-02
电视技术(2014年19期)2014-03-11
