
翻译实验性研究:历史、现状与未来趋势
2023-12-06 03:08倪铁丹
名家名作 2023年22期
倪铁丹
一、翻译实验法的基本特征
翻译研究中的实验法是一种实证研究方法,因此它必然具备实证研究的核心特征,包括对现象的描述、数据的量化分析以及透明的研究方法。通常,实证研究的基本流程包括研究者通过观察等方式获取自然情境中的研究数据,然后通过归纳、统计和总结提出理论假设。还有一种方式是首先提出理论假设,然后通过实验等方法获得经验数据,最后对假设进行验证或推翻。实验法明显属于实证研究过程的第二类,其核心逻辑是通过实验来验证假设命题。
具体而言,实验研究方法包括以下三个基本要素:(1)自变量和因变量;(2)前测和后测;(3)实验组和控制组。实验研究方法通常可分为实验室实验、实地实验、前实验和准实验等常见类型。实验设计包括多个关键步骤,如确定研究假设、设计研究方案、进行实验操作,最终得出研究结论。需要注意的是,翻译研究中的实验过程可能存在一些独特之处,与传统实验研究方法有所不同。
翻译实验研究是一种有计划、有目的的方法,用于控制和操纵理论假设中的变量和某些实验条件。它通过观察一个变量的变化来研究两种变量之间的因果关系,总结经验变量和翻译规范,阐释它们之间的内在关系规律。实验研究旨在建立关于翻译现象和翻译行为的解释性和预测性的原理和规则。
因此,实验法具有两个主要特点:人工干预和操纵,以及能够反复测试研究结果。一旦我们明确了实验研究方法的基本要素、实验逻辑和实验设计等概念,就能够为实验性论文的检索筛选提供指导。
二、数据分析与统计结果
尽管实验方法的应用不仅局限于翻译领域,但如果直接使用关键词“翻译、实验”进行检索,会导致80%的检索结果涉及非翻译学领域,如生物学、医学等,这些非相关领域的论文并不在本研究的范畴内。因此,为避免收集到不必要的数据信息,首先需要用“翻译”作为主题进行搜索,将研究领域锁定在翻译研究领域,检索式A: 主题 = 翻译实验 or 题名 = 翻译实验 (模糊匹配)。再选择“在结果中检索” ,用“翻译、实验”的关键词在知网上进行搜索,一共得到71条论文结果。其中2010—2022年一共发表有62篇论文。进一步筛选结果,排除与研究主题无关的论文,如“肝癌中RACK1对JNK通路的调控作用及机制探讨”“基于GAN的农作物病害图像数据增强方法研究”以及未采用实验方法的论文,例如“复合型翻译人才培养实践教学模式研究”“翻译硕士专业学位论文参考模板探讨”等共计11篇,从而最终得到51篇有效论文。
本文的重点是对收集到的数据进行分析。通过提炼关键信息,找出研究对象翻译研究实验法的内在规律。数据分析中,采用了知网可视化技术,注重多角度、客观性和对比性,从以下四个角度进行统计分析。
(一)从量的角度对发文趋势进行分析
通过分析总趋势发现,起伏较大,2010年到2015年一直呈增长趋势,但2016年仅两篇论文出现,而在2018年发文数量达到顶峰,2019年到2020年发文数量稍有下降(见图1)。从后五年的发文数量几乎是前五年的两倍可推断实验性论文的发文趋势仍呈上升状态。
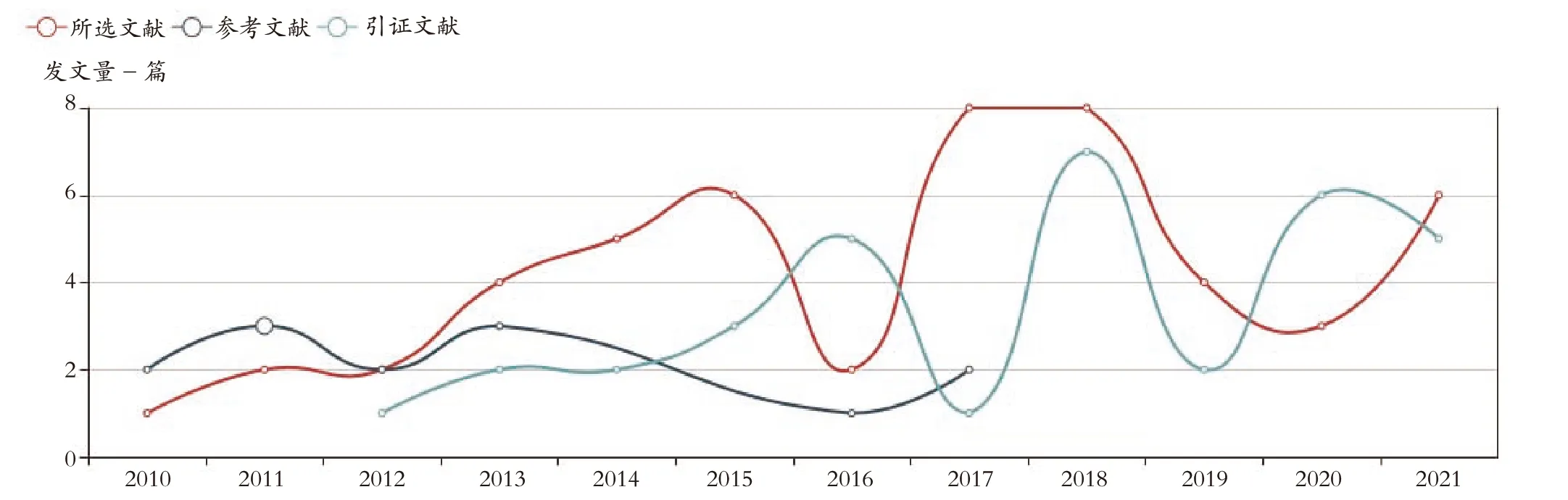
图1 2010—2021年发文趋势图
(二)从质的角度对研究层次进行统计
从资源类型分布来看,采用实验法进行实证研究的大多是硕士论文,其次是期刊和博士论文。而在近两年也就是2019年和2020年出现了采用实验法来进行翻译研究的中科院的博士论文,可见这一领域的研究层次逐渐上升(见表1)。

表1 资源类型分布表
(三)从研究广度对学科分布进行可视化统计
对数据进行学科分布统计可知,翻译的实验性论文不同于大多数描述性论文,它不仅涉及人文学科,还囊括信息科技、社会科学等学科,研究领域广泛且交叉(见表2)。

表2 学科分布表
(四)对关键词共现网络进行分析
对关键词共现网络的可视化成果进行分析,观察图2可发现聚集较多、圆点较大的关键词分别是词组3、词组4、词组5,由于词组6“口译教学”和词组3“口译研究”关联性高可归为一大类,因此实验性研究主要集中于口译研究(教学)、机器翻译等实验报告。
三、翻译实验方法研究的未来趋势
实验法论文宏观层面的数据能够有效识别其特征、说明其特点,但发展趋势的判断还需要结合具体的论文内容进行考察。通过阅读具体的实验法论文,从研究工具、研究方法、作者合作情况、数据阐释等四个方面分析,预测未来实验法论文在翻译研究领域的发展趋势。
(一)技术的发展为翻译研究带来新的研究视角和研究机会
在实验法研究中,科技发展让研究更加科学,而在具体的计算机软件的使用中,国外研究者和国内研究者也有不同的选择。国外研究者基于有声思维法,采用Tanslog软件研究翻译过程。这种软件能够记录译者使用文字处理器时手指敲击键盘的情况,以此探寻译者的思维痕迹,不过这一软件不能录入中文,因此在英汉语对互译时没有什么实用性。而国内研究者采用了替代软件Camtasia 等来研究翻译的过程。如王树槐、徐敏(2012)在有关翻译过程策略的实证研究中,就采用了该软件和译文分析、问卷调查、电话访问四位一体的数据采集方法来考察32名译者在翻译过程中的翻译策略差异。
但相同的是中外研究者都采用了计算机技术辅助研究数据的收集,可见技术的迭代为翻译实验研究提供了新路径。
(二)翻译研究方法的多样化,必然催生出跨学科的新研究领域
观察统计的研究摘要,可以看出已经有学者采用神经网络降维方法、有声思维实验法突破传统翻译对文本的分析,开始探索译者译后编辑模型等新的研究领域。在翻译研究领域,两篇重要的实验性论文备受瞩目。首先,《基于神经网络学习的统计机器翻译研究》引入了神经网络降维方法,用以学习低维向量表示的未标注数据中的调序特征。实验结果表明,在中文到英文以及日文到英文的机器翻译中,相较于基准系统,这个基于神经网络的预调序模型显著提高了机器翻译系统性能(杨南,2014)。其次,《基于PACTE的译者译后编辑能力模型研究》聚焦于翻译后编辑领域。该研究邀请了翻译初学者和资深译者对Jim Al-Khalili所著的Quantum Mechanics的选段进行译后编辑,旨在比较两组参与者的译后编辑能力。通过深入分析参与者的翻译过程和译文,结合西班牙巴塞罗那的研究组织PACTE针对翻译能力的研究成果,将初学者和资深译者的译后编辑能力模型进行了对比。研究考察了两组参与者在翻译认知过程、翻译水平、翻译策略和问题解决能力等方面的差异,以及这些差异对译文质量和水平的影响(杨珍,2020)。最终,研究不仅提供了有益的见解,还为翻译人才培养计划的调整提供了一些有效的建议。
这些论文代表了翻译研究领域的新趋势,包括技术创新、跨学科合作和实证研究方法的广泛应用。这些研究为未来的翻译研究提供了有价值的方向和启示,强调了实验性方法在深入理解翻译过程和提高翻译质量方面的重要性。
(三)翻译研究不断提高的跨学科性正在催生跨学科团队的协作
在一些跨学科的翻译研究中,研究者已经迈出了跨学科团队协作这一步。如中国科学院软件研究所的熊维、吴健、刘汇丹、张立强进行了《基于短语串实例的汉藏辅助翻译》的合作研究,新疆师范大学的徐春、杨勇、董兴华合作发表了《汉维/维汉统计机器翻译中若干问题研究》,等等。
(四)多元化软件利用中的数据阐释比数据统计更关键
从软件数据结果分析上看,实验性研究不仅注重量化统计与分析,还注重对实验结果数据的解释,实验实证研究数据有一手数据和二手数据之分,初涉研究的研究者大多收集的是一手数据。数据分析有两种方式:定性分析和定量分析,每种方式有一定的规范。目前许多研究采用的是定性和定量研究相结合,定量研究能得到一个趋势性结论,定性研究针对个案深入一步。而利用三角分析模式进行数据阐释是各种研究方法的结合,旨在最大限度地避免研究可能出现的误差,这一点也符合实证学科的发展特点。
四、结论
归纳总结以上数据分析结果,2010—2022年的翻译实验性研究主要呈现出以下几个特点:第一,量的方面,研究成果渐增。第二,质的方面,研究层次渐次提升。第三,广度方面,研究领域纵横拓展;第四,研究焦点,集中于口译研究(教学)、机器翻译等实验报告。
实验性研究还呈现以下趋势:
第一,技术的发展为翻译研究带来新的研究视角和研究机会。科学技术的迭代和发展为翻译研究提供了新的研究路径。
第二, 研究方法的多样化,催生了跨学科的新研究领域。有声思维法的出现,使翻译研究和人脑科学开始产生联系,产生了新的研究视角。
第三,不断提高的跨学科性催生了跨学科团队的协作。实证翻译研究无论是对翻译过程、产品还是功能的考察,均涉及数种专业方法的综合运用。这种多维应用预示了建立跨学科研究团队势在必行的发展可能性。
第四,多元化软件利用中的数据阐释是关键。实验性研究不仅注重量化统计与分析,更注重对实验结果数据的解释,采用的三角分析模式是各种研究方法的结合,旨在最大限度地避免误差。
猜你喜欢
艺术启蒙(2022年11期)2022-12-06
法律方法(2022年1期)2022-07-21
科学大众·教师版(2022年6期)2022-05-23
历史教学问题(2022年6期)2022-02-28
大学(2021年2期)2021-06-11
建材发展导向(2019年11期)2019-08-24
知识产权(2016年4期)2016-12-01
安徽医药(2014年9期)2014-03-20
实验动物与比较医学(2014年3期)2014-02-28
技术经济(2014年12期)2014-02-28
