
基于服装结构特征识别的相似样板匹配技术
2023-12-05 13:57:04刘蓉,谢红
纺织学报 2023年10期
刘 蓉, 谢 红
(上海工程技术大学 纺织服装学院, 上海 201620)
服装制版是服装设计和生产过程中的重要一环。在服装制版过程中,设计师通过服装款式图将服装的结构信息传递给制版师,制版师通过信息解读,构建款式图与样板结构之间的相关关系,实现从款式图到样板的转换。该过程中款式图信息的传递和转换主要依赖制版师个人,易出现信息转换差异大和效率不高等问题。
针对上述问题,实现从服装款式图到样板的自动转换是减小信息转换差异和提高转换效率的有效途径。有学者[1-2]从款式图的特征参数出发,通过建立相关模型,将款式特征转换为样板结构参数,解决了款式图信息转换的差异性问题,但该方法实施过程中首先需要对款式图进行大量的修正和标准化处理,信息的转换效率依旧不高。另有学者基于款式图识别的样板转化方法归纳出匹配转换技术,即利用图像匹配技术完成款式图与样板的转换[3]。匹配转换可构建模型将款式图像与样板进行关联,通过款式图像识别得到与之相对应的样板分类号,实现从款式信息到样板信息的自动转换。此外,相似样板确定了款式图的大体结构,在此基础上进行新样板开发可减少大量重复劳动,提高样板生成效率。
早期的服装款式图识别中,图像的特征提取和模型分类大都分离,分类效率较低,且分类类别之间的差异较大,识别难度相对较小。徐增波等[4]采用复杂网络对衣领轮廓进行特征提取和描述,结合支持向量机(SVM)分类模型,实现了对服装领型的识别。随着大数据时代的到来,深度学习应用广泛,其中卷积神经网络(convolutional neuralnetworks,CNN)[5]在图像的识别和分类上有很好的应用。相较于传统的图像识别,卷积神经网络将图像的特征提取和模型分类合二为一,分类效率进一步提高。江慧等[6]通过构建残差网络模型(ResNet50),并结合迁移学习,得到了服装款式风格的相似度计算模型。相较于颜色、纹理等特征而言,实现从服装款式图到相似样板的转换所需的细粒度特征更精细。在建立服装结构特征与样板之间的相关关系时既需要考虑全局特征[6]如裤子的轮廓造型,又需要考虑局部特征如褶裥、省道等。
AlexNet模型作为最早的深度卷积神经网络,其模型的构建与参数调整相对而言更易把握,也较适合平面款式图片的识别研究,因此,本文将通过对AlexNet神经网络的应用和改进完成对女裤的廓形、褶裥、腰头类型等18个细粒度特征的识别,并基于对这18个细粒度特征的识别实现相似样板的匹配。
1 实验设计
1.1 服装结构特征的定义及分类
本文将服装款式图中能表征结构制图规则的图像信息定义为服装结构特征。在款式图所能反映的结构特征中,中廓形、长短、褶裥、省道等相对直观,易辨别;松量等则需要借助其它图像信息进行判定,如根据臀部褶皱量来判定臀围松量。实现对服装结构特征的准确判定是进行平面款式图分类,构建实验数据集的基础。
实验中以平面款式图为输入,相较于其它类型的款式图而言,平面款式图不包含人体、背景等图像信息,对服装结构特征的反映更加清楚、直观,有利于神经网络的特征提取。实验设计中服装款式图、结构特征以及服装样板三者之间的转化关系如图1所示。当款式图X与样板Y中的结构特征元素相同时,即xi={ai,bj,…,wk}=yi时,款式图与样板可进行匹配。

图1 款式图与结构特征以及样板之间的关系图示Fig.1 Diagrammatic representation of relationship between style drawings,structural features and samples
根据服装制版知识,从平面款式图中选择部分服装结构特征作为样板相似性表征。然后将选定的这部分服装结构特征设置为实验中的多标签分类[7]类别,其中以廓形作为第1类标签,标签中的元素包括紧身裤、喇叭裤、直筒裤、锥形裤、阔腿裤和萝卜裤。参考GB/T 15557—2008《服装术语标准》中对裤子的定义,将女裤的主要结构分为裤长、腰部结构、臀部结构、裆部结构、膝围、裤口6个部分。由于实验中将研究对象统一为长裤,因此未将裤长作为结构特征标签;腰部结构可设定腰位、腰部工艺和腰下造型3类标签,每类标签又包含了不同的类别,其中腰位可进一步分为高腰、中腰、低腰,腰部工艺分为拉链和松紧,腰下造型分为有省道、有褶裥、较多褶裥和无;臀部结构以臀围为标签,根据臀围松量大小可将标签的具体类别定义为合体臀、较宽松臀和宽松臀;裆部结构受到腰部结构、臀围结构和廓形这3类结构的共同影响,对该结构的分类可转化为对这3类结构的分类;膝围和裤口主要受廓形的影响[8],可等同于廓形分类。具体分类流程和标签所包含的类如图2所示。

图2 女裤结构特征分类流程图Fig.2 Flowchart for categorizing stuctural characteristic of women′s pants
综上所述,根据女裤的制版相关知识,本文共设置了5类服装结构特征分类标签,根据结构差异为每类标签定义了不同的标签类别,如表1所示。女裤结构特征的多标签集合表示形式为D={Kn,Wm,Mp,Dq,Hk},变量n、m、p、q、k分别表示每类标签包含的类别数。其中Kn={紧身裤,直筒裤,喇叭裤,锥形裤,萝卜裤,阔腿裤},Wm={高腰,中腰,低腰},Mp={拉链,松紧},Dq={有省道,有褶裥,较多褶裥,无},Hk={合体臀,较宽松臀,宽松臀}。

表1 女裤结构特征分类Tab.1 Classification of structural characteristics of women′s pants
1.2 标签设计
分类标签决定了实验数据集的构建。在实验的设计中款式图输入与样板类别输出之间一一对应。根据表1中女裤结构特征的多标签类别,本文采用问题转化法[9]将多标签转化为单标签,通过单标签分类器进行模型训练。具体操作相当于将多标签中的类别进行排列组合,将组合后的结果看作一个单标签,如单标签类别 “紧身裤 高腰 拉链 有省道 合体臀”是由“紧身裤”“高腰”“拉链”“有省道”“合体臀”多标签中的5个标签类别组合而成。
由于大多数多标签数据集都存在严重的类不平衡问题[10],为减少类不平衡对分类性能造成的影响,实验中对通过多标签组合产生的单标签类别进行分析,研究类别中数据的分布情况。实验中随机抽取600个样本,样本以廓形标签为中心均匀分布,图3示出廓形标签中抽样数据分布。图中X轴为廓形标签,Y轴为其它结构标签。通过数据可视化的方式对单标签类别中的数据分布情况进行研究。图中方块颜色越深,说明标签中数据分布越多,浅色色块表示无数据分布或数据分布极少的类别。在标签集上选择相关度高且不包含冗余特征的特征子集可减少类别数据不平衡[11],因此结合抽样统计结果和结构制图知识对部分单标签类别进行选择,以提高数据利用率和模型的分类性能。

图3 其它结构标签在廓形标签中的分布Fig.3 Distribution of other structural labels in silhouette labels
实验中又进一步对单标签类别间的相关关系进行了探究。根据上述抽样样本数据分布,采用欧氏距离对廓形标签的结构相似性进行计算。K1(紧身裤)、K2(直筒裤)、K3(喇叭裤)、K4(锥形裤)、K5(萝卜裤)、K6(阔腿裤)间的欧氏距离计算结果如表2所示,其中K1与K3、K2与K4之间的欧氏距离计算值较小,分别为20.4和36.2,即相较于其它廓形而言,紧身裤与喇叭裤,直筒裤与锥形裤之间的结构相似性最大。不同廓形间的结构相似性计算结果可作为单标签选择的依据,减少相似性较大的标签,用较少的单标签类别覆盖尽可能多的多标签子集,提高数据利用率和模型的分类性能。

表2 不同廓形特征的结构相似性计算Tab.2 Structural similarity calculation for different profile features
综上,实验中通过数据可视化分析对单标签类别进行了选择,改善了多标签数据集中存在的类不平衡问题;通过对标签间相关关系的研究,减少了标签分类类别,缓解了数据集压力。最终实验将进行女裤识别的分类类别设定为18个,如图4所示。其中标签类别和结构特征可作为实验的识别结果输出,图中所列举的平面款式图为符合每个类别分类标准的款式图实例,标签类别所对应的结构样板为匹配的相似样板。这些单标签类别将作为服装结构特征识别实验中分类和数据集构建的依据。

图4 实验标签设计结果Fig.4 Results of experimental label design
1.3 模型设计
模型的结构设计基于经典AlexNet卷积神经网络模型。AlexNet网络作为最早的深度卷积神经网络,相对于早期的LeNet[5]系列网络、后来出现的VGGNet (visual geometry group network)[12]网络和ResNet(residual network)[13]等网络而言更适合图像并不复杂的黑白平面款式图的深度学习,网络参数在训练过程中也更易把握。
本文模型以512像素×512像素的女裤平面款式图为输入;根据数据集的特点,实验模型在原有模型的结构设计上做减法,将卷积层由原来的5层减少到4层,以防止过拟合;在第3层和第4层卷积中增加了最大池化层,以控制参数量;在每层卷积层后增加批归一化[14]操作(batch normalization,BN)来加快模型的收敛速度,提升对浅层网络的泛化性能[15]。该操作的主要计算公式为
(1)
式中:yi和xi分别为批归一化操作的第i个输出和输入值;γ、β为神经网络待训练参数;ε为一小正数。
本文模型仍以ReLu作为激活函数,相较于Sigmoid、tanh等激活函数,ReLu函数的优势在于能有效地避免梯度消失和梯度爆炸,加快模型的收敛速度,其函数的表达式如式(2)所示,该函数为函数值为非负的分段函数。
f(x)=max(0,x)
(2)
本文模型在第1层全连接层后仍采用Dropout操作,该操作可有效防止过拟合现象发生,提高模型的泛化性能,模型中输出概率Dropout rate参数值为0.5。改进模型的相关参数如表3所示,其结构设计如图5所示。

表3 改进后的模型参数Tab.3 Parameters of improved model

图5 改进后的网络模型Fig.5 Improved network model
模型中各层网络的图片输出尺寸Y与卷积核大小(F)、步长(S)、边界填充(P)之间的关系如式(3) 所示。
Y=(X-F+2P)/S+1
(3)
1.4 实验流程设计
女裤结构特征识别流程主要包括实验数据集构建、实验模型构建、模型训练及验证、对比实验、模型应用,其具体流程图如图6所示。
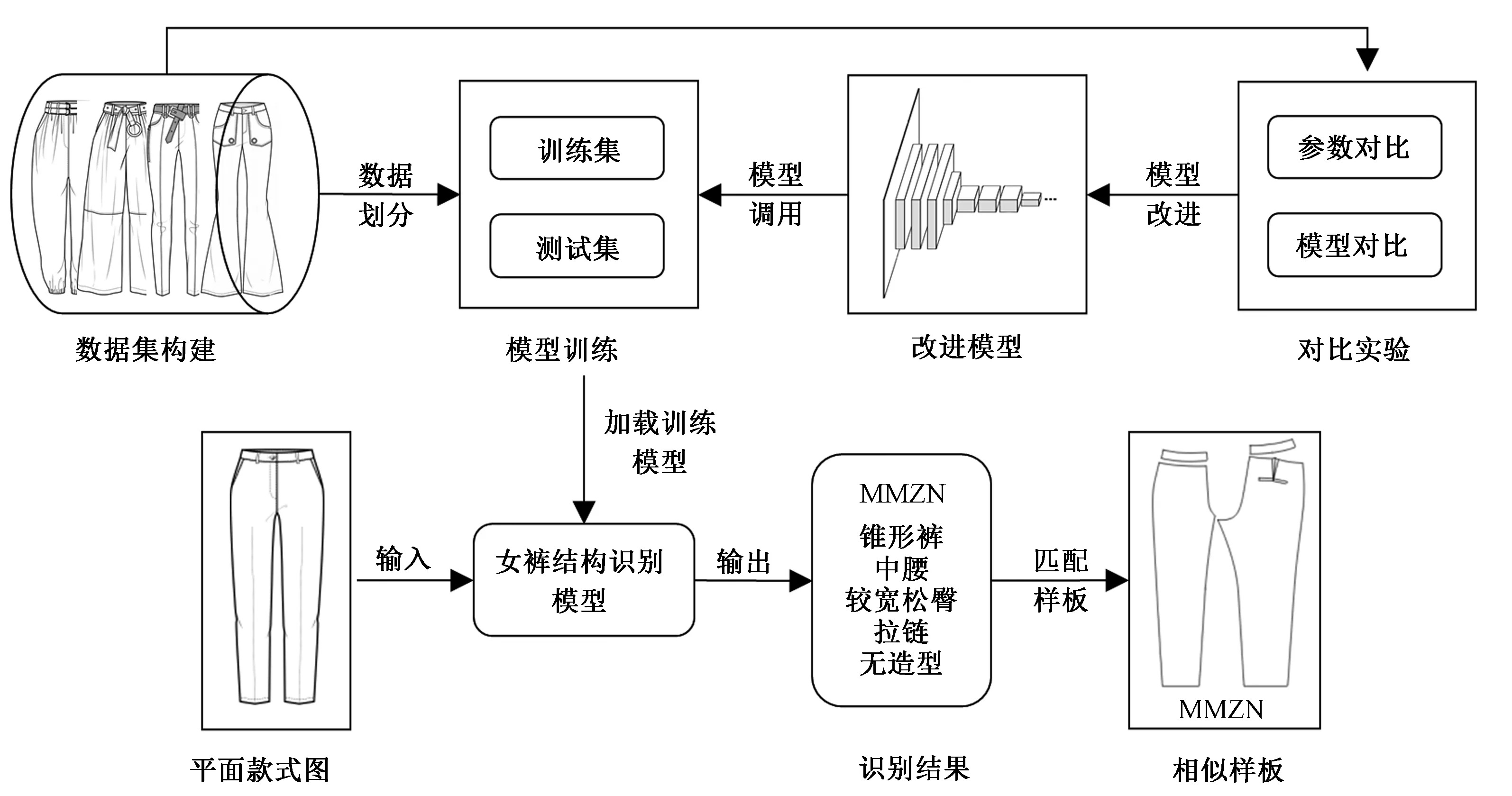
图6 女裤结构特征识别流程图Fig.6 Flowchart for structural feature identification of women′s trousers
1)数据集构建:主要分为数据收集、数据增强、数据的标准化、归一化处理以及数据集的划分。
2)实验模型构建:以经典AlexNet模型为基础,通过对原网络模型进行改进来构建实验模型。
3)模型训练及验证:采用训练集和测试集来进行模型的训练,采用验证集对训练后的模型进行测试,根据测试结果对模型进行评价。
4)对比实验:对比实验包括参数对比实验和模型对比实验。参数对比实验主要设置了针对BN操作的对比实验。模型对比实验设置了AlexNet网络、VGG11网络以及ResNet18网络的对比实验,根据2种对比实验对模型的改进效果进行评估。
5)模型应用:以任意女裤平面款式图为输入,通过模型识别输出类别号以及其对应的结构特征,根据结构特征匹配得到相似样板。
2 实验验证
2.1 实验数据集构建
数据集以女裤平面款式图为数据,通过服装企业和相关网站进行实验数据收集。实验首先通过数据增强的方式对收集的数据进行处理,如图7所示,其中包括图像水平翻转、图像对比度增强、图像变暗、图像亮度增强和图像椒盐噪声。增强后的样本总量为20 414,然后统一图片大小为256像素×512像素,并按本文设计的标签类别对数据进行分类,类别最少数据量为1 057,最大为1 317,其余类别样本数据量分布居中。采用Pytorch库建立数据集,数据集的标准差(standard deviation)计算值为[0.170,0.171,0.171], 平均值(mean)计算值为 [0.901,0.901,0.899], 通过标准差和平均值进行图片的标准化和归一化处理。

图7 数据增强Fig.7 Data augmentation.(a) Original image; (b) Horizontal flip;(c) Contrast enhancement;(d) Darker;(e) Brighter enhancement; (f) Salt and pepper noise
2.2 模型验证
本文的实验环境为Window10系统,i7-9750H处理器,16.0 GB内存,NVIDIA GeForce RTX 2070显卡,Python语言编程,Pytorch框架,cuda训练环境。
实验首先对数据集样本进行划分,其中训练集样本量为12 874,测试集样本量为4 300,验证集样本量为3 240。训练集主要用于模型训练,测试集用于训练过程中准确率的计算,验证集主要用于模型的准确率、召回率、F1值的计算,并作为对模型性能的评价指标。
模型训练过程中的参数设置包括:学习率(Learning rate)参数0.000 1;优化器采用Adam(adaptive moment estimation)自适应学习率算法;批处理(Batch_size)参数设置为64;损失函数采用交叉熵损失函数,如式(4)所示。
(4)
式中:p(xi)表示模型真实概率分布;q(xi)表示预测概率分布。
模型训练遍历次数(epoch)为100时打印损失函数图、训练精度图。图8为改进模型在实验数据集上的训练验证精度曲线图,模型最终训练准确率在99%附近趋于稳定,模型训练过程中未发生过拟合和欠拟合现象。

图8 改进模型训练验证精度曲线图Fig.8 Training validation accuracy graph of improved model
调用训练模型对验证集进行测试,采用准确率、召回率和F1值对模型进行评估,各指标数值越接近1说明模型的效果越好。模型测试结果为:准确率83.4%,召回率为83.4%,F1值0.835。不同类别的准确率如图9所示,其中最高准确率为100%,最低为66%。

图9 不同类别准确率Fig.9 Accuracy of different categories
2.3 对比实验
对比实验主要包括参数对比实验和模型对比实验。参数对比主要探究了BN操作对模型性能的影响。图5中,由于改进模型在4层卷积层后分别增加了批归一化操作,因此设置对比实验,分别在模型中增加0层BN,1层BN,2层BN和3层BN,保持其它参数不变。遍历次数为30后各模型的损失函数图如图10所示。其中采用BN操作的4组损失函数下降的速度均快于0层BN组。表4示出不同BN操作后模型的准确率,其中采用BN操作的4组实验的准确率均高于0层BN组。根据上述结果可知,模型中增加BN操作可加快模型的收敛速度,提高准确率。

表4 不同BN操作后模型的准确率Tab.4 Accuracy of model after different BN operations

图10 不同层数批归一化的损失函数图Fig.10 Loss function diagram for different layers of BN
模型对比实验主要与原AlexNet网络模型、ResNet18以及VGG11模型进行对比。不同模型在不同类别上的准确率结果如图11所示。
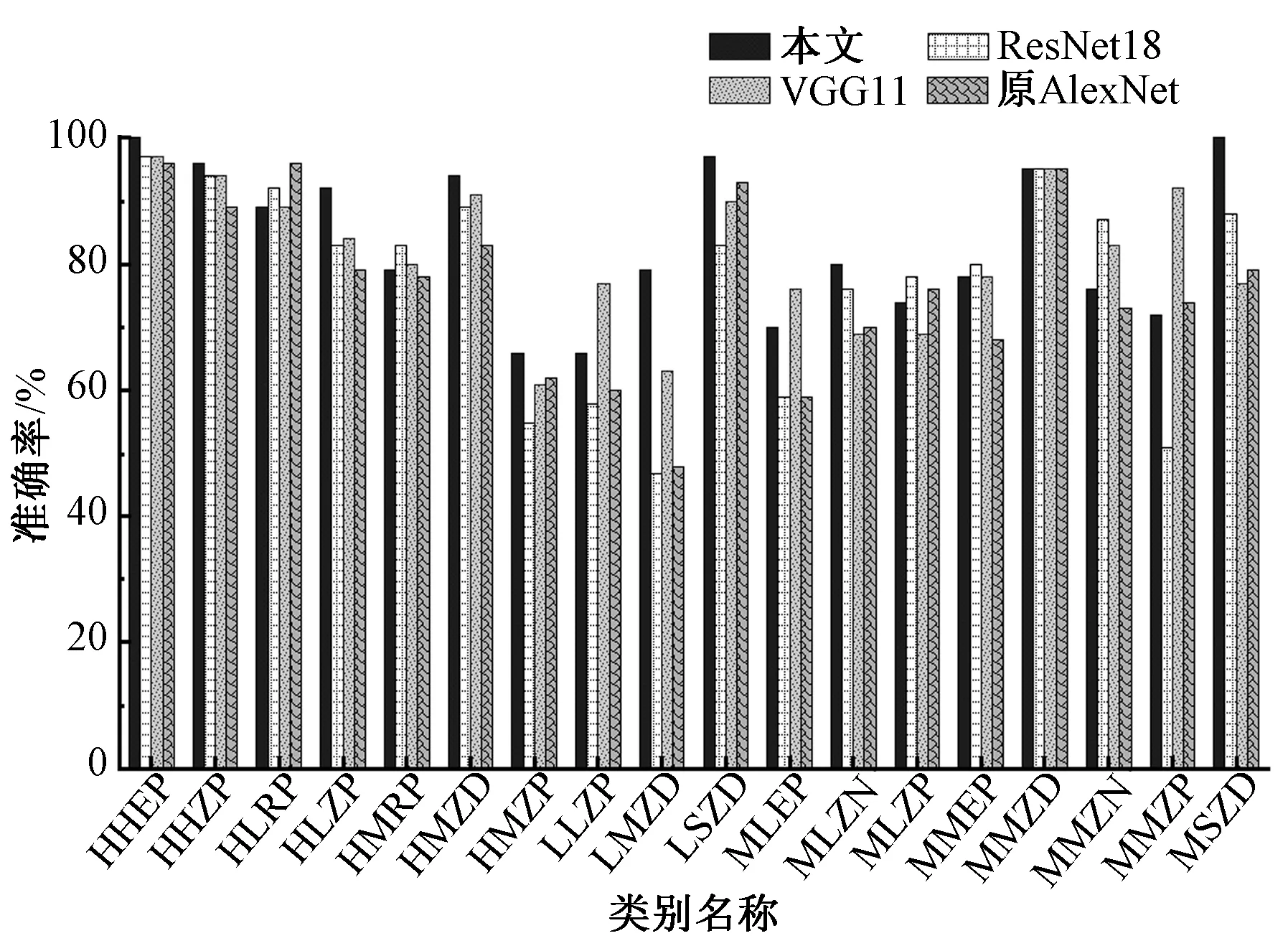
图11 不同模型不同类别准确率Fig.11 Accuracy of different models in different categories
表5示出不同模型的准确率测试结果。其中本文模型准确率为83.4%,相较于原AlexNet模型提高了6.7%,相较于网络层数更高、模型深度更深的ResNet18和VGG11网络模型也分别提高了6%和3.6%。在参数量大小的比较中,本文模型大于ResNet18,小于原AlexNet和VGG11。总体而言,改进模型的综合性能相对较好。

表5 不同模型的准确率Tab.5 Accuracy of different models
2.4 实验分析
实验基于改进的AlexNet模型,通过数据集的训练和验证,改进模型在验证集上的准确率为83.4%,高于改进前的AlexNet模型以及当前应用较为广泛的ResNet系列模型和VGG系列模型;通过参数对比实验结果可知,本文通过在网络层数增加批归一化操作,加快了模型的收敛速度。对比实验证明了本文对模型的改进提高了识别准确率,且具有较好的应用性。
当然,本文实验也具有一定的局限性,部分类别的准确率不够高。对模型中普遍准确率较低的类别进行分析,探究影响这些类别识别准确率低的原因。例如:类别“HMZP 锥型裤 高腰 较宽松臀 拉链 有褶裥”在各模型中最高准确率仅有66%。根据结果显示,在该标签被错分的所有类别中被分为“MMZP 锥型裤 中腰 较宽松臀 拉链 有褶裥”的概率最高,占比为45%。从结构特征上看,2个类别最大的区别在于腰部位置,即高腰和中腰的区别,如图12所示。
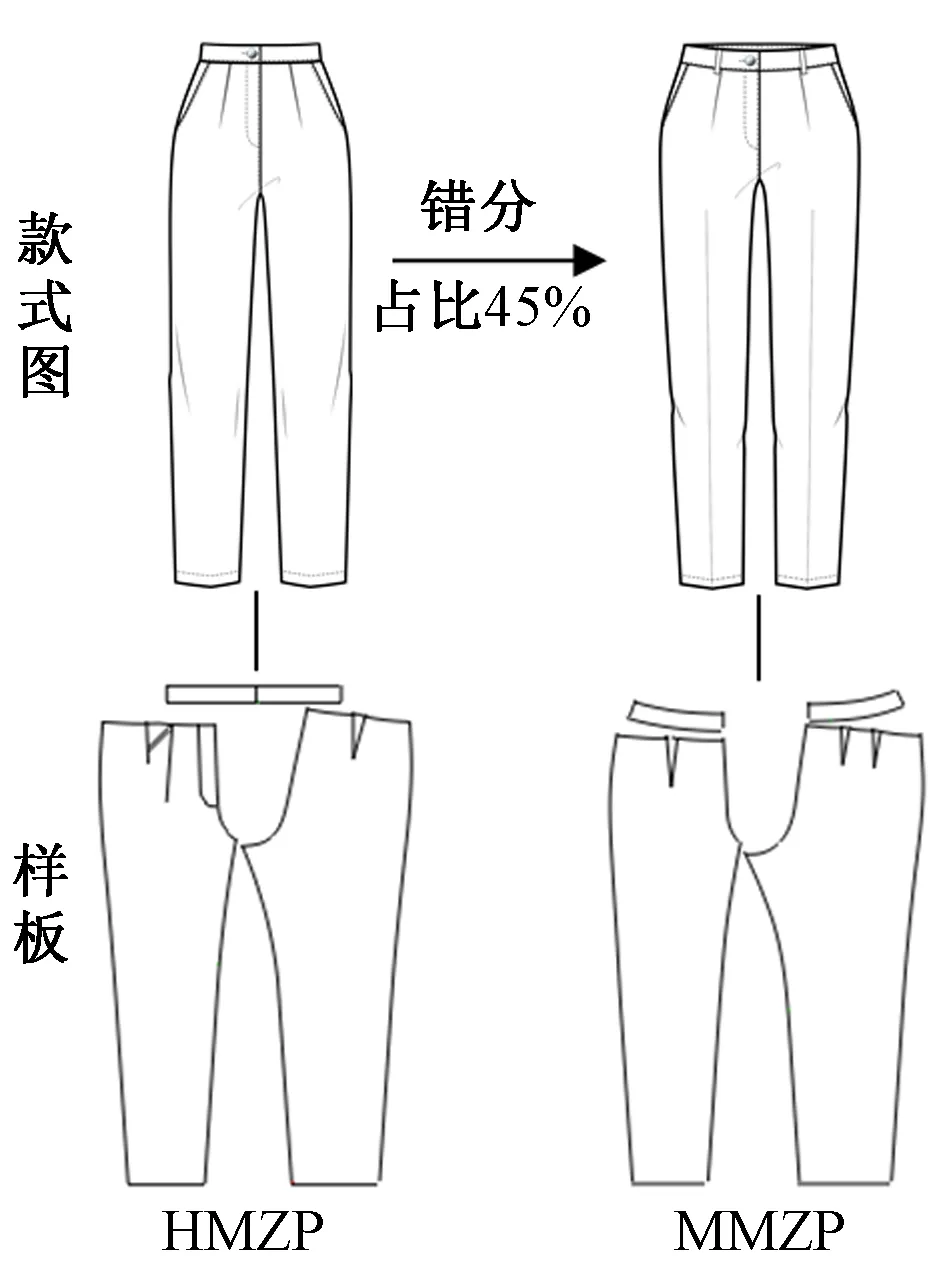
图12 易错类别分析Fig.12 Analysis of error-prone categories
3 结 论
本文以女裤为例,基于深度学习实现了从平面款式图到样板的转化,从实验的验证过程中得出如下结论。
1)通过定义结构特征,设计分类标签,可将对样板的识别转化为对平面款式图的识别;通过数据可视化分析对单标签类别进行选择,改善了多标签数据集中存在的类不平衡问题;通过对标签间相关关系的研究,减少了标签分类类别,缓解了数据集压力,提高了数据的利用率和模型的分类性能。
2)以平面款式图为数据构建数据集,作为模型的训练输入,有利于模型进行特征提取;通过在网络模型的卷积层中引入批归一化操作,可加快模型的收敛速度,提高对新样本的泛化能力。
3)在解决多标签分类问题时将多标签转化为单标签,该方法对数据量的要求较高,也可考虑从模型结构设计上进行相关问题的研究;本文通过廓形、腰位、腰部造型、腰部工艺、臀围中的18个结构特征对样板的相似性进行表征,后续研究可考虑增加口袋、分割线等表征,以进一步提高匹配样板的相似度。根据本文实验思路,数据量越大,标签设置越全面,可匹配到的样板相似性越高。
猜你喜欢
今日农业(2020年13期)2020-08-24 07:35:08
人大建设(2018年11期)2019-01-31 02:40:56
能源(2018年5期)2018-06-15 08:56:00
小资CHIC!ELEGANCE(2018年17期)2018-06-15 01:29:02
兽医导刊(2016年12期)2016-05-17 03:51:54
Coco薇(2015年5期)2016-03-29 22:40:10
应用海洋学学报(2015年3期)2015-11-22 07:39:10
小说月刊(2014年11期)2014-04-18 14:12:27
oggi今日风采(2013年6期)2013-10-09 03:09:36
上海理工大学学报(2012年1期)2012-03-20 13:54:12
