
基于集成学习的砂姜黑土含水量高光谱反演研究
2023-12-05 03:14王志刚黄子琪贺成龙蔡太义冯玉庆陆宁静窦焕衡
农业资源与环境学报 2023年6期
王志刚,黄子琪,贺成龙,蔡太义,冯玉庆,陆宁静,窦焕衡
(1.河南理工大学测绘与国土信息工程学院,河南 焦作 454000;2.哈尔滨师范大学地理科学学院,哈尔滨 150025)
土壤含水量(SMC)是农业、水文和生态等领域中的关键指标[1],实时、快速测定土壤水分对作物增产和粮食安全具有重要意义[2]。传统土壤水分测定方法检测周期长、范围小,且具有破坏性,这严重限制了对农田水分的精准管理[3]。
高光谱遥感因具有分辨率高、预测精准,且能快速、实时和大面积监测等优势[4],受到了国内外学者的广泛关注。Liu 等[5]的研究探明,土壤含水率低于0.4 g·cm-3时与高光谱反射率呈负相关,高于0.4 g·cm-3时则呈正相关。吴代晖等[6]综合评价了土壤含水率和反射率的两种机理模型(物理模型和统计模型),认为后者精度更高。刘伟东等[7]比较了5种光谱变换方法反演土壤表面湿度的能力,认为一阶微分与差分方法对土壤水分的预测能力最强。姚艳敏等[8]的研究表明,黑土反射率对数一阶微分建立的含水率预测方程的模拟效果最好,决定系数(R2)可达0.931。贾学勤等[9]的研究表明,褐土基于连续投影算法的多元线性回归模型R2可达0.957;张磊[10]建立了喀斯特地区耕地土壤多元散射校正-主成分分析的神经网络(MSC-PCA-BPNN)模型,显著提高了模型预测能力。张通等[11]对大豆的相关研究表明,与传统反演算法支持向量机回归(Support Vector Regression,SVR)相比,集成学习(Ensemble Learning)的自适应提升算法(Adaptive Boost,AdaBoost)能提高模型的准确性,可将决定系数R2提高至0.982。Fu等[12]基于决策树的集成机器学习算法(XGBoost)对模型进行校正后可使R2由0.59 显著提升至0.86。Tao 等[13]研究发现,与单个机器学习算法相比,堆叠(Stacking)集成模型可以更准确和稳定地检测葡萄地土壤含水率。综上,集成学习能够整合多个学习方法的结果进而增强原方法的泛化能力,较单一模型估测精度更高。
砂姜黑土是黄淮海地区典型的中低产土壤(面积约400 万hm2),恶劣的物理结构是其低产诱因[14],而监测和调控其土壤含水率则是砂姜黑土结构改良的关键。然而,利用集成学习预测砂姜黑土土壤含水量的研究明显不足。本研究以黄淮海地区砂姜黑土为研究对象进行室内高光谱测量,利用集成学习优化和改进砂姜黑土土壤含水率反演算法,进而提高砂姜黑土土壤水分估算精度,为砂姜黑土区结构精准改良提供理论参考。
1 材料与方法
1.1 土壤样品采集与处理
河南驻马店西平县(图1)整体地势西高东低,西部为山区,中部为丘岗区,东部为平原区。在对西平县土壤类型分布、地形地貌、空间特征分析后,本研究选择东部平原砂姜黑土区作为研究对象,采样时间为2022 年6 月,采土样时地表主要作物处于收获期,土样采集数量20个,采集深度0~30 cm。

图1 研究区位置示意图Figure 1 Location diagram of the study area
将不同采集点土壤样品风干后,剔出土壤中植物残体、石砾等侵入体。为探究研究区内砂姜黑土含水率反演模型,消除不同采集点砂姜黑土组成成分之间的差异,将各采样点土壤样品等比例充分混合,将混合后的样品研磨均匀,过2 mm孔径筛,均匀混合后分别装入密封袋备用。设置8 个含水率梯度组,每组内有4个重复样,共32份样品,每份样品为30 g,分别放置在半径5 cm、深4.5 cm的铝盒内,标明组别序号,向1~8 组分别喷水1.6、3.2、4.8、6.4、8.0、9.6、11.2 mL 和12.8 mL。在放置24 h 土壤充分浸润、吸收表面自由水后,对土壤样本进行光谱测量,得到不同含水率条件下的光谱曲线。测量完成后,立刻采用烘干法测定样本的土壤含水率。
1.2 土壤反射光谱测量及光谱预处理
采用美国ASD Filed Spec 4 Wide-Res 便携式光谱仪(光谱范围为350~2 500 nm)进行室内土壤反射光谱测量。将土壤样品表面刮平,采用Hi-Brite 探头补充光源及光谱测量,探头放置于样品上方5 cm 处。利用白板进行标准化校正,将土壤样品90°转动3 次,在4 个方向重复采集5 次,共得到20 条光谱曲线,取平均值作为原始光谱反射率,以降低土壤样品光谱受各向异性因素的影响。所得土壤光谱反射率在波段350 nm 和2 500 nm处受噪音影响波动明显异常,因此在经过光谱仪配套数据处理软件ViewSpec Pro预处理后,选取400~2 400 nm范围内的光谱用于分析[15]。
1.3 光谱变换与特征波段选择
光谱变换通过对原始光谱进行数学变换来削弱噪声和无用高光谱信息并增强特征信息。本研究中除了研究平滑后的反射率光谱(Smoothed reflectance,SR)外,还采用了4种光谱数学变化方法:反射率倒数的对数变换[LOG(1/R)][16]、反射率的一阶微分变换(First-order differentiation,FD)[10]、多元散射校正变换(Multivariate scatter correction,MSC)[17]和去包络线变换(Continuum removal,CR)[18]。
在特征波段选择过程中,土壤样品反射率曲线首先经过不同形式数学变换获得5 种光谱曲线,再对5种光谱曲线每个波长的反射率与土壤含水率进行皮尔逊相关性分析以及显著性检验,通过P<0.01 水平显著相关的波长为初步筛选的特征波段。通过连续投影算法(Successive projections algorithm,SPA)[19]将初步筛选的特征波段进一步筛选为最佳特征波段。以上计算在Matlab软件中进行。
1.4 模型构建与精度检验
首先构建偏最小二乘法回归(Partial least squares regression,PLSR)[20]模型和支持向量机回归(Support vector machine regression,SVR)[21]模型,并以PLSR 和SVR 作为基模型建立了堆叠集成(Stacking ensemble)学习模型[22],通过交叉验证[23]计算出上述构建模型的均方根误差(RMSE)、决定系数(R2)和相对分析误差(RPD)[24](表1),对模型精度以及泛化能力进行评估。RMSE越小,模型泛化能力越好;R2越接近1,模型越稳定。RPD小于1.4 时模型不具有预测能力,介于1.4~2.0 时具有一定的预测能力,而大于2.0时模型具有极好的预测能力。

表1 精度校验方法公式Table 1 Precision calibration method formula
具体操作如下:选取32份土壤样品并随机分为4组,每次以其中3 组作为训练集构建基于交叉验证的PLSR模型和基于交叉验证的SVR模型;并以PLSR和SVR作为基模型,以线性回归模型为元模型将基模型预测结果作为新特征值,训练Stacking 集成模型。然后以剩余的一组数据对模型进行验证并评价。通过测试发现,本实验样本建模过程中增加到40 次交叉验证时的评价结果趋于稳定,因此本实验中以50 次交叉验证得出的RMSE、R2、RPD均值作为模型最终精度。以上计算在Matlab软件中进行,设置交叉验证折数为4,PLSR 函数主成分数设置为5,SVR 模型使用线性核函数,设定核尺度为“auto”。
2 结果与分析
2.1 土壤含水率与光谱曲线
由表2 可知,砂姜黑土样品含水率介于11.14%~44.31%之间,取同一梯度组的重复样含水率平均值作为该组含水率,并绘制不同含水率下砂姜黑土光谱反射率曲线(图2)。
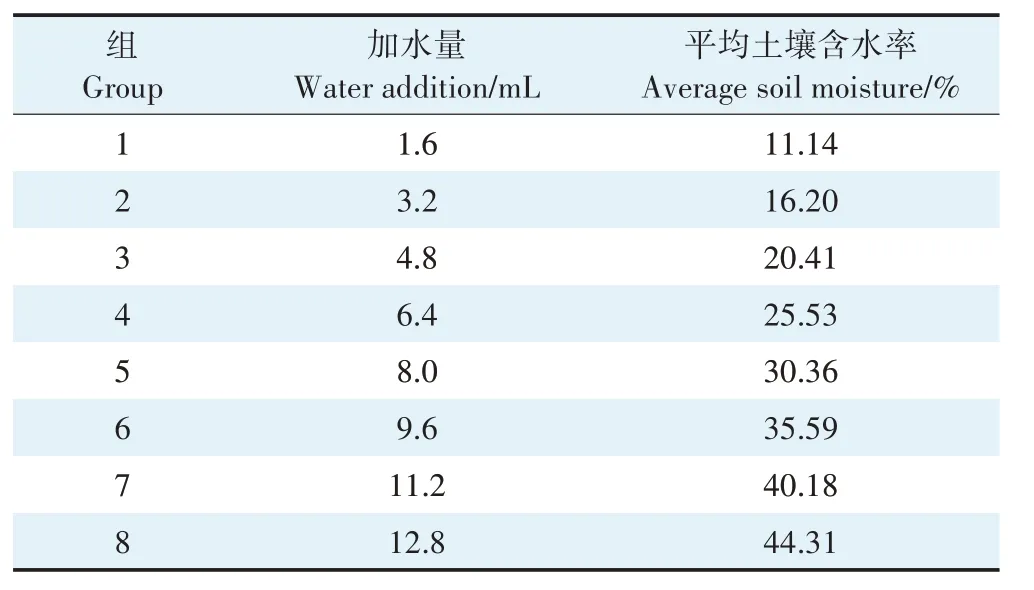
表2 不同梯度组土壤样本平均含水率Table 2 Average moisture content of soil samples group
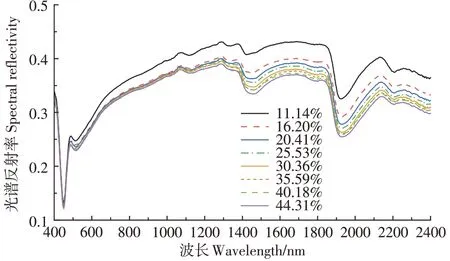
图2 不同含水率条件下的光谱曲线(SR)Figure 2 Smoothed spectral curves under different moisture content(SR)
由图2 可知,不同梯度样品光谱曲线具有相近的形态特征,差异在于主要吸收峰的位置偏移和深度改变,整体上表现为随含水率增加反射率下降,11.14%与16.20%含水率之间反射率曲线间隔较大。在400~500 nm 范围内各梯度反射率几乎重叠而无法分辨,500~1 000 nm 范围内各梯度间反射率曲线十分接近而难以辨认。这是由于该部分土壤光谱反射率主要受土壤样品质地与组成等因素影响,而在土壤充分混合后样品之间土壤组成差异被排除,不同样品间光谱曲线趋同,说明含水率变化对该范围内光谱反射率变化贡献不明显。在1 000~2 400 nm 近、中红外光波段内,可以明显观察到光谱反射率都随土壤含水率的增加而降低。
2.2 光谱变换
LOG(1/R)光谱曲线拥有与原光谱曲线几乎相反的变化规律,整体的特征信息并未得到明显增强(图3a)。FD 光谱曲线经数学变换形态发生极大改变(图3b),反射率在0.005~-0.007 5 范围内围绕零值上下波动,其中400~500 nm 范围内出现明显起伏峰谷,而1 400、1 900 nm 和2 200 nm 处的波谷则是常见的水分吸收峰。MSC 变换后的光谱曲线与原光谱曲线相比,放大了含水率变化对500~2 400 nm范围内光谱反射率变化的贡献,同时削弱了三个土壤水分吸收峰的差异(图3c)。CR 处理的数据较原始数据在400~2 400 nm 的波段范围内局部光谱反射率变化得到了增强,主要体现在1 400、1 900、2 200 nm 三个水分吸收峰处的差异性(图3d)。
在党的十九大报告以及同各界优秀青年代表座谈时的讲话中,习近平总书记多次提到与青年相关的话题,他指出:“广大青年要坚持面向现代化、面向世界、面向未来,增强知识更新的紧迫感,如饥似渴学习。既扎实打牢基础知识又及时更新知识,既刻苦钻研理论又积极掌握技能,不断提高与时代发展和事业要求相适应的素质和能力。”入学教育,可以使新生明确学习目的,端正学习态度,增强学习动力,帮助新生了解研究生阶段的生活特点和基本要求,顺利完成从本科到研究生的角色适应和角色转变,尽快步入科学发展轨道。然而与本科生相比,研究生新生入学教育的关注度远远不够。

图3 砂姜黑土4种光谱变换曲线Figure 3 Four spectral transformation curves of Vertisol
2.3 最佳特征波段选取
2.3.1 相关性分析
SR、LOG(1/R)、FD、MSC和CR五种光谱数据分别与土壤含水率进行皮尔逊相关性与显著性分析,获得显著波段信息(表3)及光谱反射率相关系数曲线(图4)。通过相关系数曲线图可以看出SR、LOG(1/R)的相关性曲线均较为平滑且平稳,整体相关性都比较高,相关性曲线中最大值分别为-0.892 和0.894。砂姜黑土SR 光谱反射率相关系数曲线整体呈现负相关,但经MSC变换后在400~1 400 nm呈正相关,1 400~2 400 nm 呈负相关,相关系数曲线不再呈单一相关性,经MSC 变换后的砂姜黑土光谱反射率与含水率的相关性在1 406 nm 波段得到最大值(-0.978),提高了整体相关性。经FD变换后相关系数曲线上下起伏频率变快,与土壤含水率整体相关性下降但仍有部分波段相关性较SR有所增强,显著相关波段数量最少,即实现了数据降维。砂姜黑土的CR相关系数曲线频繁上下波动,变化趋势与MSC相关性曲线大致相似。

表3 五种光谱反射率与土壤含水率相关系数最大值及对应波长Table 3 Maximum correlation coefficient between reflectivity and soil moisture content and corresponding bands
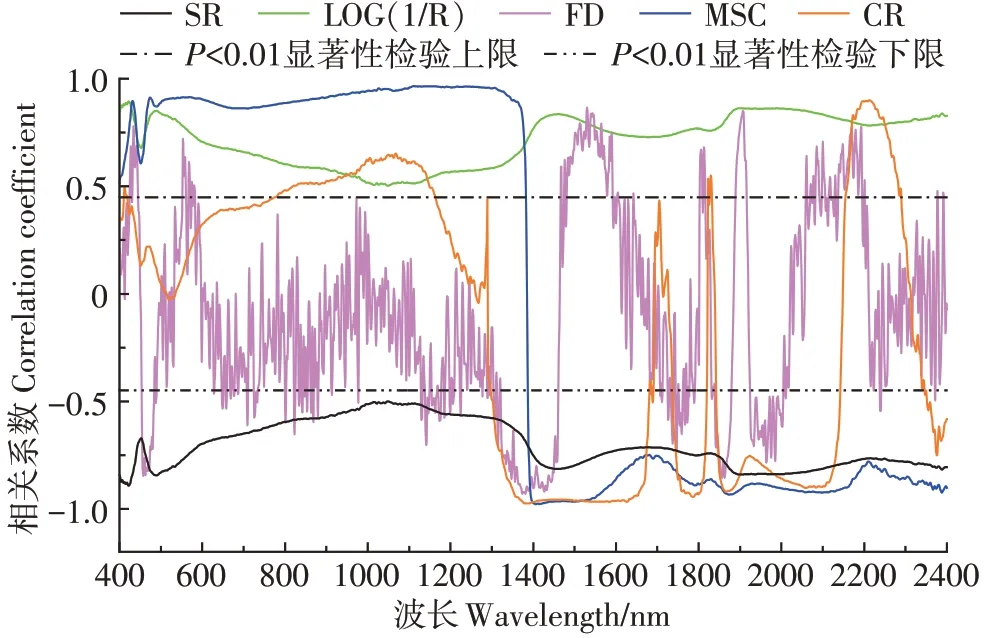
图4 变换光谱反射率相关系数显著性曲线Figure 4 Correlation coefficient significance curve of transformation spectral reflectance
2.3.2 SPA算法选取最佳特征波段
综合上述五种光谱数据相关系数曲线与显著性检验结果,初步筛选出在P<0.01显著水平上显著相关的特征波段集,在Matlab软件中使用SPA算法分别对SR、LOG(1/R)、FD、MSC和CR的特征波段集进行二次筛选,得到最佳特征波段集(表4)。SR与LOG(1/R)曲线形态近似对称,故有近乎一致的最佳特征波段,分布在400、650、1 000~1 100、1 400 nm 范围附近,属于可见光及近红外部分;FD 曲线呈现频繁波动,在SPA算法筛选后保留了8个波段,但几乎全部集中在480、800~900 nm 范围附近;MSC 曲线的特征波段分布在400、1 385、1 694 nm 和2 193 nm 附近,可以看出经过MSC 变换后红外光谱部分的信息被放大提取;而CR曲线筛选后的波段集中在800、878、1 270 nm 附近,全位于近红外范围内。
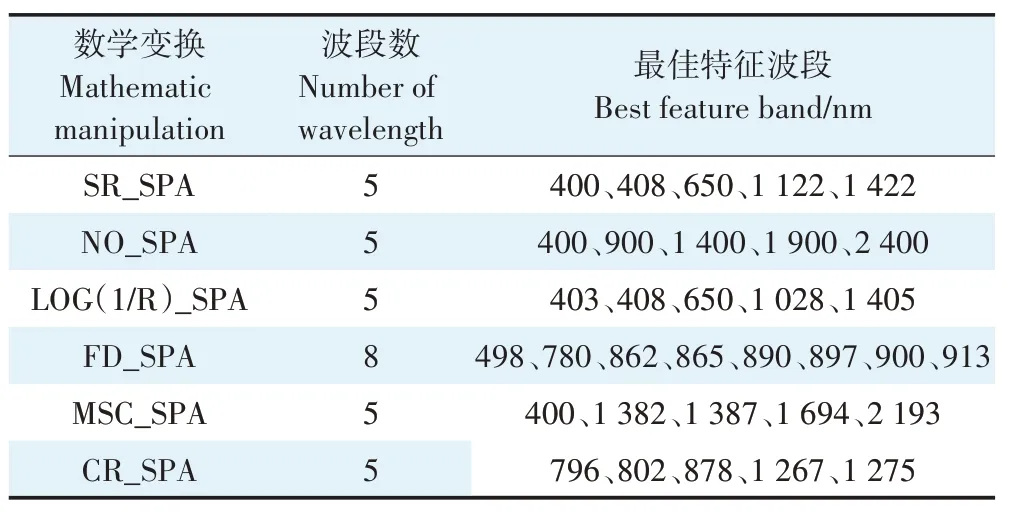
表4 砂姜黑土最佳特征波段Table 4 The best spectral characteristic band for the moisture content of Vertisol
此外,在SR光谱曲线中选择400、900、1 400、1 900nm 和2 400 nm 波长的反射率作为没有经过SPA 算法筛选的对照波段组(NO_SPA),用来对比验证SPA 特征选择算法对模型构建的优化。
2.4 土壤含水率反演模型遴选
在每次4折交叉验证中,将32个样品数据随机分成4 份,依次以其中1 份为验证集,其余3 份为建模集进行4 次训练,取每次训练的RMSE、R2、RPD的均值作为一次交叉验证模型的精度。分别计算三种建模方法在50 次交叉实验中的RMSE、R2、RPD的均值作为该模型的最终评价结果(表5)。
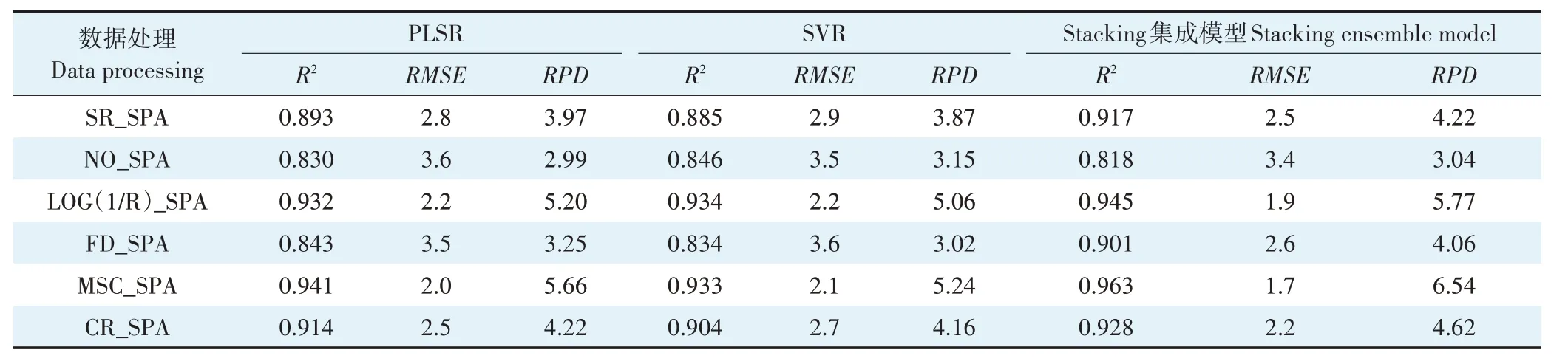
表5 土壤含水率反演模型的精度评价Table 5 Accuracy evaluation of soil moisture content inversion model
从表5 中可以看到没有经过SPA 算法筛选的波段集NO_SPA 建模精度最低,R2最高的模型为SVR 模型(0.846),而经过SPA 筛选的SR_SPA 建模精度基模型R2最高达0.893,集成模型R2为0.917,具有明显提升;从光谱变换的效果分析,除FD光谱外,LOG(1/R)、MSC 及CR 光谱建模效果都很好,单模型和集成模型R2均在0.9以上,均比SR 模型精度高,而以FD 为基础的集成模型R2也在0.9 以上。以上所有模型的RPD值均大于2,说明所有模型都具有较好的预测性,其中以MSC 变换为基础进行建模效果最好,单模型与集成模型的R2介于0.933~0.963 之间,RPD值最高达6.54。
从不同的模型构建方法来看,PLSR 模型和SVR模型效果相近,相同光谱的两种单模型精度各有优劣但差异不大。而除了NO_SPA 波段集外,以PLSR 模型和SVR 模型为基模型进行集成的Stacking 集成模型的精度均高于两个基模型,说明集成法可有效提升模型精度。
将5 种光谱最佳特征波段集和1 个对照波段集,分别输入到对应的6 个集成模型中得到砂姜黑土含水率预测值,结合含水率实测值绘制预测拟合散点图(图5)。从图5 中可以明显看出FD 集成模型(图5c)的预测值与实测值的散点更分散,说明该模型稳定性最低;而NO_SPA 集成模型(图5f)的散点拟合直线斜率最小,最偏离直线y=x,说明该模型预测性最差;MSC 集成模型(图5d)的预测值散点整体上更集中于直线y=x,说明其具有优越的预测能力。
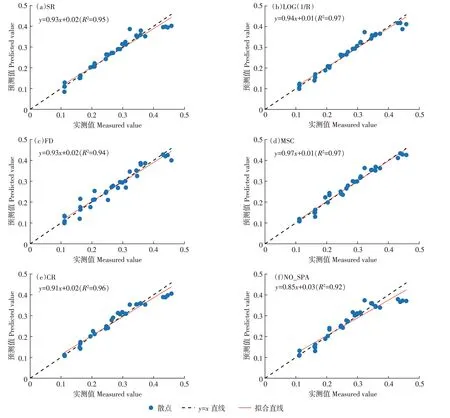
图5 砂姜黑土含水率预测值散点图Figure 5 The scatter diagram of predicted value of moisture content in Vertisol
3 讨论
3.1 土壤光谱反射率影响因素剔除
土壤样品光谱反射率受土壤结构、质地、养分等多因素影响。姚艳敏[8]在研究东北黑土土壤水分高光谱反演时认为,由于只在室内进行测定,土壤属性空间分布的非均质性可以不予考虑。本研究中土壤样品与姚艳敏研究样品类似,同样基于剔除不必要影响因素,凸显土壤含水率对反射率的影响,故将来自不同地块的同类土壤均匀混合[25-26],以获得相对均质的土壤样品,减少模型的不确定性。本研究模型R2介于0.818~0.963 之间,与韩陈等[25]的研究模型(R2=0.86~0.99)接近,均比较稳定。
3.2 土壤含水率模型预测精度
精度是评价模型是否构建成功的关键指标。本研究中集成学习下的模型R2为0.963,较集成前R2提高了0.022~0.030,相较于姜传礼等[27]使用的BPNN 模型R2(0.941)提高了0.022,也高于张颖帝等[2]研究砂姜黑土含水率反演的多元线性回归模型R2(0.89)。原因可能有两个方面:一是在制备样品时,姜传礼和张颖帝未考虑不同区域土壤样品组分差异;二是两个研究使用的多元线性回归模型和多元逐步回归模型都是线性或单一模型,无法很好地处理数据的共线性或非线性问题[28]。本研究中SPA 算法可有效处理自变量之间的多重共线性[29],从而提高模型的稳定性和可靠性;SVR 模型可处理非线性关系[30],故预测性能提高。
3.3 土壤含水率模型泛化能力
泛化能力是指模型对新鲜样本的适应能力[31]。本研究发现,Stacking 集成模型的RMSE较PLSR 和SVR模型降低了0.1~0.9,表明泛化能力明显增强。增强原因可能是Stacking综合利用了PLSR模型的特征提取能力和SVR模型的非线性建模能力,深层次原因还需进一步探索研究。
4 结论
(1)多元散射校正(MSC)是增强砂姜黑土土壤含水率信息最多的光谱变换方式。
(2)连续投影算法(SPA)可有效提取砂姜黑土高光谱中含水率特征信息,并能够实现高维数据降维。
(3)砂姜黑土含水率最佳反演模型是经反射光谱MSC 变换后由偏最小二乘回归(PLSR)和支持向量机回归(SVR)集成的Stacking 集成模型(R2=0.963)。与传统单一算法模型相比,Stacking 集成模型提高了模型的精度及泛化能力。
猜你喜欢
河北农业(2023年8期)2023-09-04
中国化肥信息(2022年8期)2022-12-05
印制电路信息(2022年11期)2022-11-30
海洋通报(2022年4期)2022-10-10
中国农业信息(2022年2期)2022-07-15
光谱学与光谱分析(2022年4期)2022-04-06
农业工程学报(2022年1期)2022-03-25
土壤学报(2022年1期)2022-03-08
工程技术研究(2020年9期)2020-06-20
电子器件(2017年2期)2017-04-25
