
基于YOLOv5s改进的高精度手语检测算法
2023-12-05 08:14:18郑思远
现代计算机 2023年18期
郑思远
(达尔豪斯大学计算机科学学院,成都 610065)
0 引言
手语是失语者与社会进行沟通的重要桥梁,但手语的学习对于大众具有较高成本,因此,利用现代计算机及算法对手语进行检测识别具有重要的实际意义。对手语进行目标检测并反馈给正常人能促进失语者与社会更好地交流,而手语目标检测能否有良好的人机交互主要取决于手语检测的准确度与进行手语检测的速度[1]。本文通过对YOLOv5目标检测网络进行改进,提出了一种轻量化高精度的手语检测算法。
当前主流的手语识别方法大部分是基于神经网络的计算机视觉技术,Dima 等[2]用原本的YOLOv5 在没有更改其原本框架的基础上利用CNN 提取特征,并在训练前添加相关数据集的预训练模型对美国手语数据集进行训练,最后精度达到95%。Borg等[3]提出了一个使用多层递归神经网络(RNN)进行手语目标检测的方法来增强模型预测能力,并在不同图片数据集进行测试,在视频中的实时测试,精度方面有显著提升。陈帅等[4]的YOLOv5-ASFF-SE 网络通过添加自适应特征融合以及SE 注意力机制去增强模型特征提取和融合的能力,结果证明相比于原有YOLOv5 网络,平均精度提升6%。邢晋超等[5]通过改变K-means 聚类算法,选定更加适配的先验锚框尺寸从而达到更佳鲁棒性的检测效果,并结合CBAM 注意力机制加强原有特征提取,平均精度和召回率提升颇为显著(3.44%和3.17%)。Li 等[6]提出了CNN-LSTM 特征提取结构,在卷积层和池化层后引入LSTM 分类器,消除冗余特征信息提高精度和检测能力。
在文献[2-6]图片数据集中的选择多偏向于近距离大物体检测,背景因素干扰少,当适配于嵌套式设备遇到不同的实时情况时,检测网络容易出现精度下降或者是检测不具备时效性的可能。本文数据集的选定,偏向于远距离小物体手语检测目标数据集。同时在上述研究当中,模型轻量化处理方面略微有所不足,计算量大,同时精度方面还有可以提升的空间,尤其是当实验对象为小物体、干扰因素强的情况下。针对以上问题,本文在YOLOv5s 基础上做了以下改进:
(1)轻量化模型处理,将YOLOv5s 原有多层主干网络替换成MobileNetV3 网络,MobileNet网络特有的特征提取和处理结构极大地减少了YOLO 检测所需要的计算量和参数应用,从而达到轻量化模型的目的。
(2)高精度检测提升,替换的MobileNetV3网络主干MobileNet中的SE注意力机制有效提高特征提取的效率,保证精度下轻量化网络结构。并且,使用GiraffeDet 网络中Generalized-FPN 结构优化YOLOv5s网络颈部,其独特高效的特征融合确保了细节信息的处理,进一步提高网络精度。
1 基于YOLOv5s改进的手语检测算法
YOLOv5s 网络[7](如图1 所示)当中,主干网络部分主要由卷积层以及此C3 模块组成,卷积层用于普通的特征提取,C3 模块中主要由三层卷积层以及残差链接组成,网络Neck 部分主要进行不同程度的下采样来适配特征融合。此网络的主要特点就是对图片局部特征、深层特征以及语义特征的多尺度特征融合。
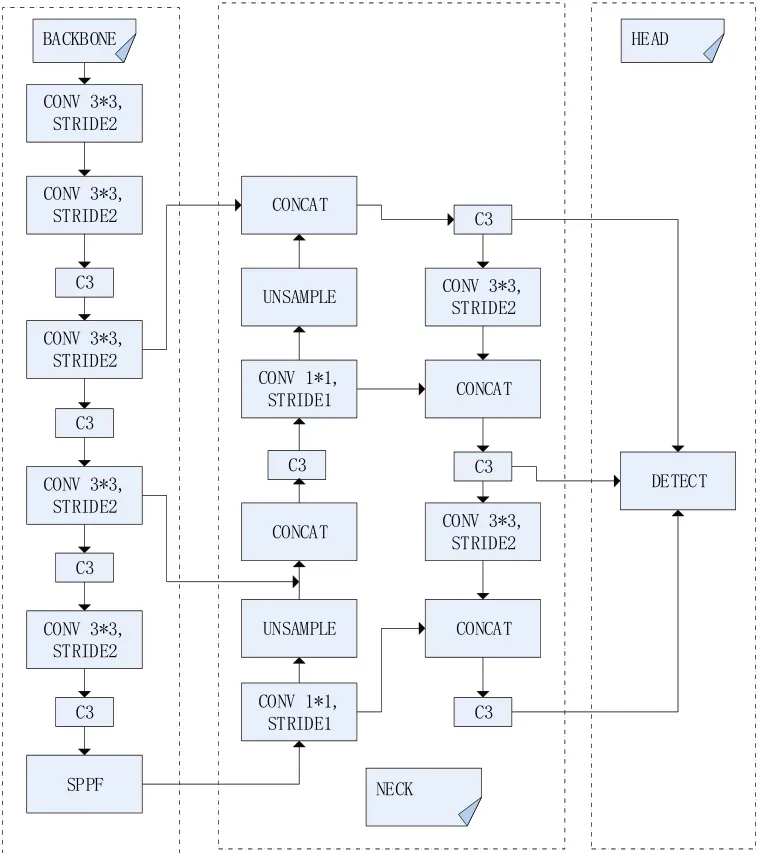
图1 YOLOv5s原网络结构
在改进的YOLOv5s-MOBLILE-GFP(如图2所示)当中,将YOLOv5s 主干部分替换为用三个MobileNetV3 模块构成的主干,在Neck 部分YOLOv5s 特征金字塔(FPN)[7]的高层次与低层次特征交汇聚合的结构基础上进一步加强,去除C3 模块,加入了多层GSPStage(RepGFPN)[8]块,以对手势数据特征进行多层次特征融合,提升网络精度。
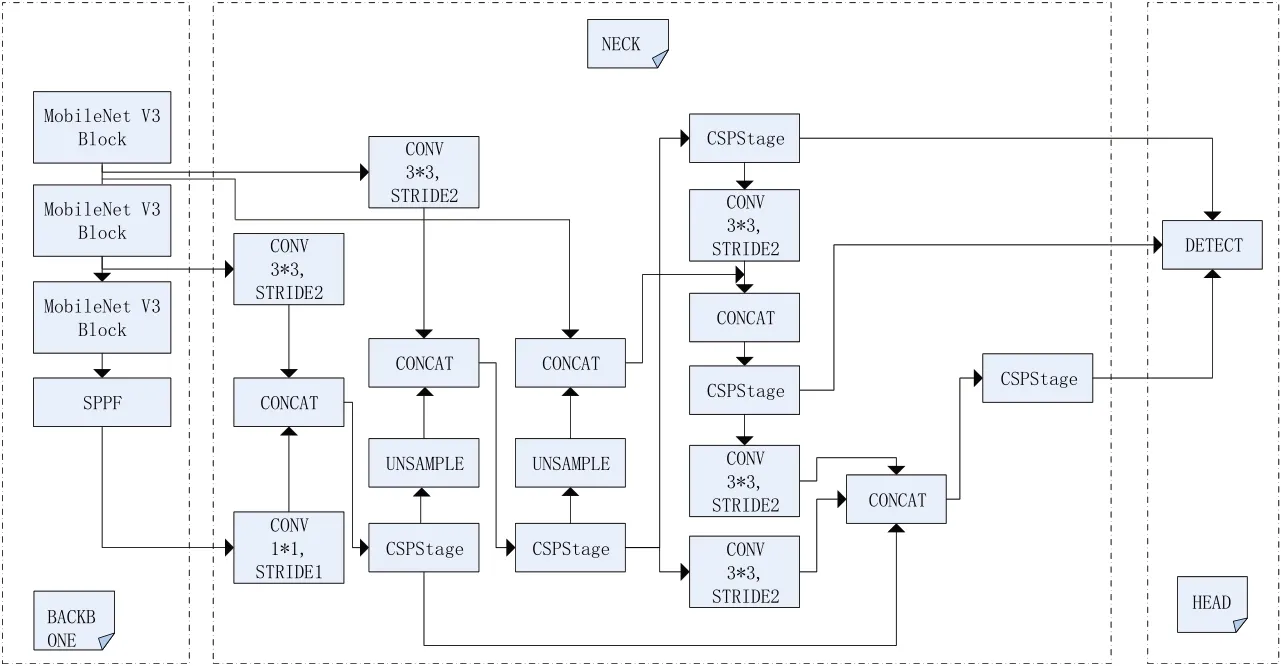
图2 YOLO5s-MOBILE-GFPN网络结构
接下来对YOLOv5s-MOBLILE-GFP 网络结构进行详细展开,从轻量化改进和特征融合模块结构两方面进行实验分析,评估网络结构改进在精度以及速度上的提升。
1.1 轻量化高精度特征提取主干MobileNetV3
深度可分离卷积(Depth-wise convolution)是MobileNetV3 网络块(如图3 所示)的主要构成,是模型参数大幅度减少的关键因素[9]。
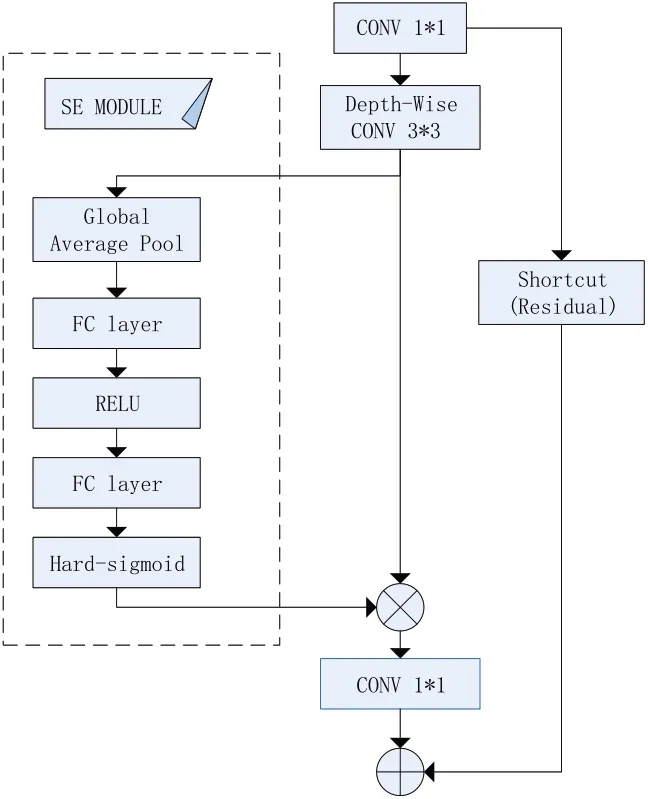
图3 MobileNetV3网络块
Depth-wise 卷积特点在于对图片每一个通道的特征图都进行单独的卷积提取操作[10],相比于传统卷积对整个特征图通道做卷积特征提取,Depth-wise 卷积本身缺少通道间的特征融合,利用逐点卷积对特征图通道特征融合并进行特征图通道维度升降,大幅度减少计算量,轻量化模型结构。
表1 所展示的内容是当传入数据集图片时,新改进主干MobileNetV3 网络的系数展示,相比于原YOLOv5s网络主干参数明显减少,在主干网络减少五层的基础上保持理想的特征提取效果。

表1 网络MobileNetV3主干参数
此外,SE注意力机制(如图3所示)是Mobile-NetV3 网络块精度提升的另一关键因素[9],此结构主要是由全局平均池化层、全连接层和激活函数组成,传入的特征图会根据特征需求的比例大小去进行权重重分配,通过权重相乘的方式可以达到权重重组的目的,激活函数可以降低全连接层特征信息在提取过程中丢失的概率。这样一来需要被着重检测的特征通道会逐渐显示出来,大幅度减少冗余特征对于精度的干扰,特征提取的精度也会随之上升[11]。
在Hu 等[11]提出的原版SE 机制中采用的是sigmoid 激活函数,将传入的权重特征向量压缩在(0,1)间,其缺点在于多次幂运算计算量大,迭代多次后的值过小易出现梯度消失的可能。反观MobileNetV3 网络使用了hard-sigmoid 结构[9],运算梯度迭代过程把幂运算思想换成了max 思想,取最偏向于某类别的最大近似概率,减少了部分计算量的同时也提高分类效率,使模型轻量化[9]。
综上所述,用MobileNetV3 网络块替换的新主干网络结构在深度可分离卷积以及SE 模块的加持下可以在提高特征提取的准确率的同时减少非必要的计算量。
1.2 高精度特征融合Neck-GFPN模块
由Jiang 等[8]提出的GiraffeDet 神经网络目标检测模型在小目标检测中具有较高精度。其中颈部网络Queen-Fusion 特征融合思想的加入是此网络精度提升的关键,该结构特点在于将高层次语义信息和低层次信息特征多层次融合,从而达到对细小特征的高度检测效果。如图4所示,在Concat 处,P5 当前节点不仅会融合本层特征图节点传入的信息,同时也会融合其他层特征,比如上一层P4 特征的最大池化结果,下一层P6 特征的双线性插值的上采样结果以及上一层P4 输出的特征。采用这种深层次的跨层、跨尺度方法,能够有效进行不同网络层的信息交换。在广泛的目标检测实验当中与其他修改后的深度网络形成对比,对于图片中远距离小目标的信息特征检测的匹配率有所提高,图片中小物体检测锚框数量有着明显上升[8]。
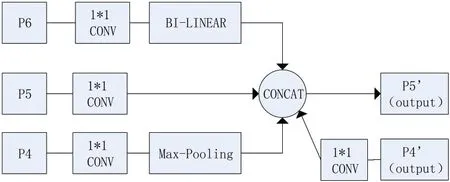
图4 Quene-Fusion结构
本文对YOLOv5s 原网络进行修改的同时也适配了此网络模块的思想,通过修改颈部和头部网络不同特征融合Concat 模块、卷积层以及上下采样层数对应关系达到多尺度多层次特征融合的目的,提升网络对小目标的检测准确度。
将原始网络头部中C3 特征提取模块网络架构替换为如图5 所展示的CSPStage 模块架构,此模块在GiraffeDet[8]网络中作为头部特征提取的主要结构,提高对未来阶段特征再融合信息交汇和最后阶段检测的精度。对比原C3 模块,在此模块中卷积变化首先是1*1卷积搭配批量归一化以及激活函数,此结构能在小步幅提取特征的同时,稳定模型在提取过程中的信息变化幅度,对于特征丢失的可能也引入不同激活函数进行自动适配。
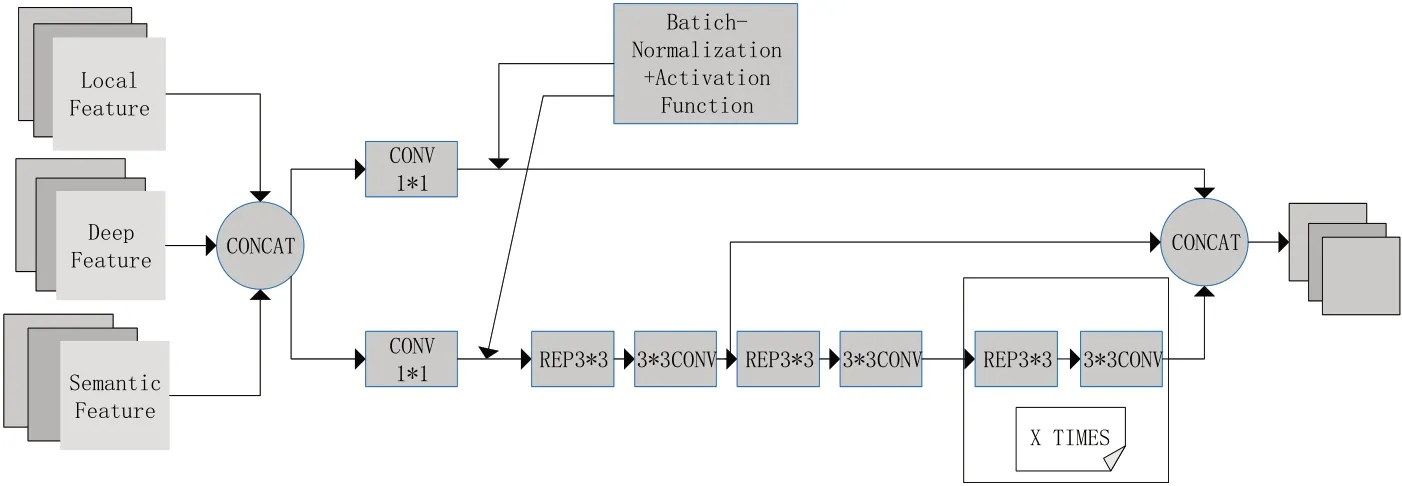
图5 CSPStage结构
在颈部网络中CSPStage 块采用了多次Rep 3*3与3*3卷积搭配的特征提取方式,Rep3*3结构(如图6 所示)[12]是REPVGG 网络的一部分,该模块由三部分组成,残差块、3*3 卷积、1*1卷积。在网络训练阶段,Rep网络用三个分支来提取不同维度特征,使网络在不同的尺度和语义层次上提取特征,以捕捉图像中的多样性信息,保证网络的高检测精度。在网络推理阶段,Rep网络将三个分支卷积层参数相加融合成一个卷积核,这种融合方式在保持检测精度的同时,还能提升推理速度。通过将参数相加而不是在特征层级上进行串行或并行处理,可以减少计算量和内存需求,从而提高网络的推理效率。
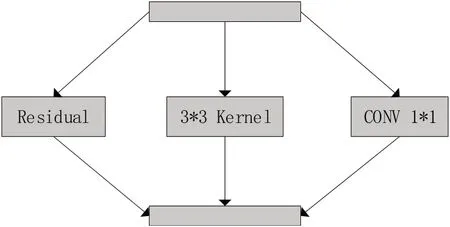
图6 REP3*3块结构
将GiraffeDet 神经网络结构融入到YOLOv5s网络中,构建了一个高精度特征融合网络,虽然增加了网络的颈部和头部的结构参数量,增加了模型计算量,但网络检测精度会较大提升。
2 实验结果分析
2.1 实验系统配置和数据集
本文实验所用到的计算机环境是Windows 11 的22H2 版本,CPU 为因特尔12 TH Gen Intel(R)Core(TM)i5-12400F 2.50 GHz,GPU 采用的是英伟达NVIDIA GeForce RTX 3060,显存12 GB。实验训练环境利用PyCharm 2021.2.4 版本软件,Python 版本为3.8.13,PyTorch 为1.13.0。
本文采取的数据集为Kaggle 官网的开源数据集“Sibi Language Object Detection”,该数据集包括了26种类别,为A~Z英文字母。训练集为1271 张,测试集、验证集随机分配,部分数据集如图7所示。

图7 实验数据集部分展示
2.2 实验参数系数及评估理论
实验超参数的选取,学习率(learning rate)为0.01,批量化训练为300 轮,每轮批量(batch size)为16,传入图片归一化为416*416*3 规格,训练方式采取优化随机梯度下降(SGD)的方式。
本文涉及到的模型评估标准主要包括五个指标,前两个为参数量(Parameter)和计算量(FLOPs),决定了改进模型是否轻量化。参数量过大会导致训练所占用内存过大,训练速度会显著下降;计算量统计了对于神经网络在深度学习时不同单元系数相乘与相加的总次数。另外三个指标分别为精度(Precision)、召回率(Recall)和平均精度均值(mAP)。
Precision 用来评估误检对于模型精度的干扰。表达式为
其中,TP(True Positive)是检测目标正确的正样本数量,FP(False Positive)为误把错误的检测对象当成目标检测对象,相当于负样本检测成正样本的数量。误检数量越小意味着模型的鲁棒性越好。
Recall 是用来评估模型在漏检中的精度概率,和Precision 的差别在于FN(False Negative)和FP的不同,FN是把正样本检测成负样本的数量。表达式为
mAP 是由精度和召回率所绘的PR 曲线决定,本文评估采用IoU 指数为0.5 和0.5~0.95 区间,意味着IoU 区间内综合每一类的精度和召回率的PR 曲线面积和做平均操作。Categories 为检测类别个数,n为指定IoU范围作用于总类别n,AP计算不同区间面积之和。
2.3 精度轻量化实验结果对比
为进一步突出理想模型在精度以及轻量化的良好兼容性,进行了四次批量实验,分别是YOLOv5s 原本网络框架;其次在原有网络基础上替换主干网络到Mobilenet-V3网络进行特征提取;然后引入新特征融合块GFPN 替换原有YOLO 网络颈部网络C3 模块,最后综合以上三方面进行训练。
由表2 可以看出,相比于原有网络对于手语识别的训练结果,在只替换主干到Mobile-NetV3 结构时,平均精度和召回率方面提升大约3.5%,模型参数及计算量分别减少大约70%和80%,但精度方面提升幅度小,还有幅度提升空间。当仅更换颈部网络结构YOLOv5s-GFPN 时,参数利用率和计算量方面上浮77.7%和83.7%,虽然精度相比前一个框架有所上升,但昂贵的计算成本不足以适配嵌套设备。YOLOv5s-Mobile-GFPN 模型是最终优化版本,尽管轻量化方面不如YOLOv5s-Mobile,但在平均精度IoU0.5 和0.5~0.9 时均有9.28%和6.88%的提升,精度提升远超其他模型,参数量相比于原网络减少13.2%,FLOPs 减少37.2%次运算。

表2 模型精度和轻量化参数
2.4 YOLOv5s-Mobile-GFPN 可视化结果训练对比
图8 是最优化模型YOLOv5s-Mobile-GFPN与原YOLOv5s网络平均精度均值和召回率的可视化对比,可以看出优化模型从训练开始到结束的收敛速度远超过原模型,更佳的泛化能力也是本文更新模型的优点之一。在本文系统环境基础下,优化模型训练300 轮所用时间为44.77 min,反观YOLOv5s网络完成时间为49.17 min。
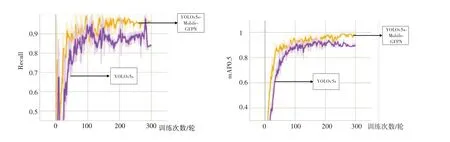
图8 平均精度均值和召回率
在图9中,新改进优化模型整体曲线波动收敛都比原模型在相同条件下训练稳定,并且在损失系数方面新模型比YOLOv5s拟合后效果更好,训练损失和在验证集上损失值收敛快、值域小。可以看出相比于YOLOv5s模型训练结果,YOLOv5s-Mobile-GFPN 在训练锚框、物体以及类别损失分别下降了0.00319、0.001195和0.002956。
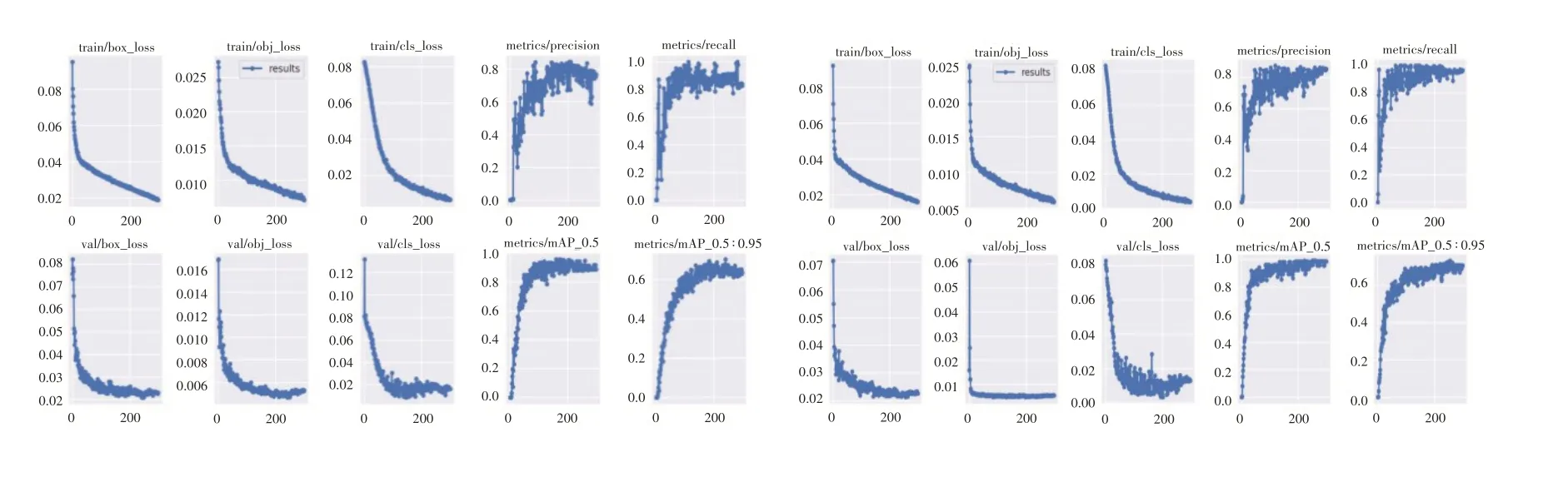
图9 YOLOv5s与YOLOv5-Mobile-GFPN 可视化训练结果
2.5 模型结果预测分析
图10 为改进后优良化模型YOLOv5s-Mobile-GFPN 和原模型YOLOv5s 锚框检测预测效果,可以明显看出在复杂背景、干扰因素多的情况下,锚框置信度呈现跨度式上升,误检概率,如把背景检测成手语的概率下降明显。与此同时,对于背景因素干扰少的图片部分,锚框检测置信度由0.6 提示到0.9 以上,远距离小目标手语数据集检测平均提升16.25%。

图10 YOLOv5s和YOLOv5-Mobile-GFPN 结果验证预测效果图
3 边缘部署
3.1 部署平台
为降低功耗、加速模型推理和决策,本实验采用了AI 边缘部署,将模型部署在了比特大陆Sophon SE5 AI 计算平台上,设备的相关型号参数见表3,该设备采用TPU,是一种针对人工智能计算任务优化的专用硬件加速器,具有高性能、高能效、可拓展等优点。

表3 比特大陆Sophon SE5相关参数
3.2 算法部署与结果验证
算法边缘部署过程如图11 所示,首先对PC端的PyTorch 模型进行了一系列操作,包括量化(quantization)、剪枝(pruning)和转换(conversion),生成Bmodel 模型,以便将模型适配到SE5 平台上进行部署,然后通过Bmodel 创建推理Engine 来进行图像推理。在边缘设备上,通过摄像头采集实时流媒体(RTSP),并对每一帧图像进行推理和分析。最后,处理后的图像被传送到Web 端进行展示或进一步处理。Web 界面展示检测结果如图12所示。
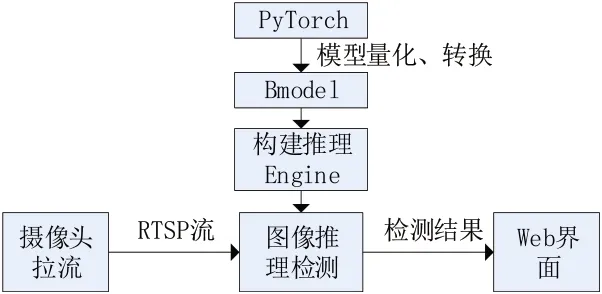
图11 算法边缘部署流程

图12 Web界面检测结果展示
为验证边缘设备低功耗、易部署等性能以及YOLOv5s-Mobile-GFPN 网络高精度、轻量化等特点,分别在3060(GPU)和Sophon SE5 两种设备上部署了原YOLOv5 网络与YOLOv5s-Mobile-GFPN 网络,结果见表4,比较了两种算法在两种不同环境下的检测精度、功耗、检测速度。由表4 可知,将两种算法部署在SE5 上,在模型量化、转换过程中模型产生了部分精度损失,但由于采用了fp16 数据类型,模型精度损失较小,原网络准确度下降了0.78%,YOLOv5s-Mobile-GFPN 网络精确度下降了1.64%。同时SE5 推理速度分别达到了48 FPS 和42 FPS,基本满足实时检测的需求。对比两款设备功耗,SE5只有3060-GPU的22.9%。
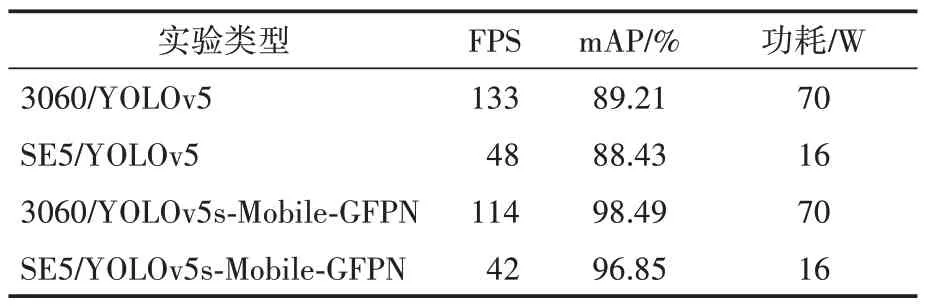
表4 原网络与改进网络在GPU与SE5上的测试结果
4 结语
根据YOLOv5s 神经网络框架,本文提出了YOLOv5s-Mobile-GFPN网络结构的改进方法,重点在于修改网络主干、改变网络层连接关系以及引入新的特征融合模块。这些改进旨在提高手语检测的精度,并能够适应不同情况下的手势姿态。在保持高精度的同时减少了模型参数的幅度,在平均精度IoU 0.5和0.5~0.9方面分别提升了9.28%和6.88%,同时模型参数量相对于原网络减少了13.2%,FLOPs 减少了37.2%次运算。尽管如此,网络仍有通过蒸馏量化进一步减少参数和计算量的空间,未来将进一步测试和改进。为了减少偶然性实验结果,数据集的数量将进行扩充,以扩大实验结果的有效性范围。
本文还将YOLOv5s-Mobile-GFPN 网络分别部署在3060-GPU 和Sophon SE5 两种终端设备上进行了测试。结果显示,网络精度仅下降了1.64%,推理速度减少了36.8%。此外,TPU 设备的功耗只有GPU 的22.9%,具有较高的实用性,未来的研究将集中在如何通过损失较少的精度来实现更快的推理速度。
猜你喜欢
精密成形工程(2022年2期)2022-02-22 05:44:14
活力(2019年15期)2019-09-25 07:23:06
智富时代(2019年2期)2019-04-18 07:44:42
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
专用汽车(2016年1期)2016-03-01 04:13:19
青少年科技博览(中学版)(2015年8期)2015-10-28 21:26:56
专用汽车(2015年4期)2015-03-01 04:09:07
噪声与振动控制(2015年4期)2015-01-01 07:08:21
作文大王·笑话大王(2014年11期)2014-11-13 09:01:43
