
融合注意力机制的IETM细粒度跨模态检索算法
2023-12-04 05:08翟一琛顾佼佼宗富强姜文志
系统工程与电子技术 2023年12期
翟一琛, 顾佼佼, 宗富强, 姜文志
(海军航空大学岸防兵学院, 山东 烟台 264001)
0 引 言
交互式电子手册(interactive electronic technical manual,IETM)是一种实现装备技术资料信息化的技术手段,是装备信息保障领域的关键技术之一,其克服了传统纸质技术手册不便携带、查询困难等弊端,在舰船、航空等领域均应用广泛,提升了装备保障的工作效率[1]。
目前,随着装备信息化、智能化的发展,装备维修保障信息日益庞杂、数据逐渐呈现出多模态的特点。现有IETM的检索功能多采用传统的关键字索引等方式,无法高效地检索庞大的图像、文本等多模态数据,且数据录入过程需要遵循严格的规范与步骤,使用存在一定的局限性。跨模态检索是实现不同模态数据间相互检索的技术。图像和文本两种模态的数据经常同时出现,其本身蕴含的信息又能够相互补充。通过在维修保障领域应用跨模态检索技术,实现图像、文本之间的相互检索,可以提高检索数据的效率,进而提升IETM系统智能化水平。
跨模态检索研究的目的在于挖掘不同模态样本之间的关系,通过一种模态样本来检索具有相似语义的另一种模态样本[2]。与传统的单一模态检索相比,其难点主要在于图像与文本的表示形式不同,两者分布在不同的语义空间,无法直接通过传统的余弦距离等方式直接度量二者的相似度[3-4]。目前基于深度学习的跨模态检索主要有跨模态相似性度量、公共特征空间学习等方法。基于公共特征空间学习的方法可以离线获得文本和图像表示,是目前跨模态检索的主流研究和应用方向,其主要思想是通过可解释的距离函数约束图文关系,优化不同模态数据之间的分布关系,将不同模态数据映射到同一公共空间内,再进行相似性度量,这类方法的缺点是特征融合不够充分[5-7]。
Bahdanau等[8]在2015年首次提出注意力机制,并将其应用于机器翻译领域,注意力机制可以聚焦重要信息,并同时具备不同特征空间以及全局范围内的特征聚合能力,将其应用于跨模态检索领域,可以有效缓解模态间交互不充分的问题。文献[9]中使用的草图数据集与本文自建数据集图像相似,图像内容均以大量线条为主,通过加入通道注意力机制[10]关注图像的关键信息,实现了对模型效果的大幅提升。文献[11]使用目标检测模型快速区域卷积神经网络(faster region convolutional neural network, Faster-RCNN)[12]先对图像进行目标检测,再对检测到的目标分别进行特征提取而得到细粒度特征,之后通过堆叠交叉注意力实现了良好的检索性能。文献[13]证明了同时使用注意力机制进行模态间语义对齐和模态内语义关联的有效性。文献[14]提出在跨模态检索中单独的目标检测模型可能不是必要的,使用ViT (vision transformer)[15]模型进行图像特征抽取后直接构造边界框损失的方法可以达到最先进的跨模态检索性能。
本文自建数据集来自于航空行业IETM相关技术手册,图像数据多为飞机及相关维修设备原理图、曲线图等黑白图像。这些图像通过大量线条组合而成,与通用数据相比,具有较强的抽象性,部分实例之间十分相似,仅抽取粗粒度信息往往难以对其进行区分。针对此问题,本文改进提出一种融合注意力机制的细粒度跨模态检索算法,通过在特征提取与模态交互阶段引入注意力机制,实现对图文细粒度特征的提取和特征间的细粒度对齐。在Pascal Sentence数据集[16]及自建航空行业IETM相关技术手册数据集上进行跨模态检索实验,并对结果进行可视化展示,验证所提算法的有效性。
1 跨模态检索模型
本文采用深度监督跨模态检索(deep supervised cross-modal retrieval, DSCMR)[17]为基础模型,其网络结构如图1所示。首先,图像和文本分别通过Image卷积神经网络(convolutional neural network, CNN)和Text CNN得到图文特征表示;然后,经过全连接层进行特征抽象,并在最后一层共享权值将图文特征映射到同一公共表示空间;最后,再连接一个线性分类器,预测每个样本的类别并构造标签损失。此外,模型使用了公共空间的辨别损失,分别约束图像和文本、图像和图像、文本和文本之间的相似性。
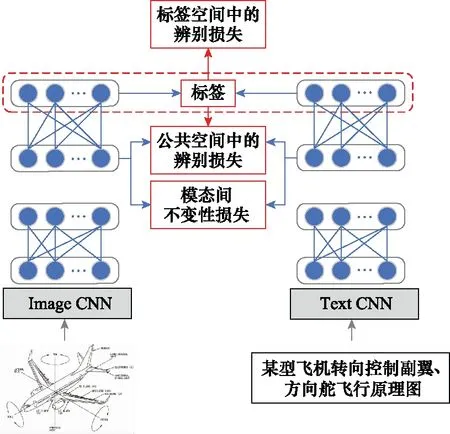
图1 DSCMR网络结构图Fig.1 DSCMR network’s structure
本文在直接使用DSCMR模型用于自建数据集图文跨模态检索时,平均精度均值(mean average precision, mAP)达到了0.745。针对数据集特点,可以进行改进的方向主要有两点:① 改进特征提取模块以提取图文细粒度特征;② 在特征交互阶段融合注意力机制进行图文间的细粒度对齐。
2 融合注意力机制
本文自建数据集内的图像数据样式较多,包含大量的曲线图、零件原理图,难以合适地标注有意义的目标,无法使用Faster-RCNN目标检测的方案进行局部特征的提取。因此,本文使用基于注意力机制的图像编码器ViT进行特征提取。首先将图像进行分块,通过图像编码器输出每个图像块的特征表示作为图像的局部特征;文本编码模块使用基于注意力机制的Transformer编码器[18],得到文本的局部特征表示。在特征交互模块,提出模态内注意力机制和整体-局部模态间注意力机制融合图像特征和文本特征。模型整体结构如图2所示。

图2 模型结构Fig.2 Model’s structure
2.1 图像特征提取模块
本文采用ViT模型提取图像特征。首先将输入图像I的尺寸调整为224×224像素大小,并将其分割为图像块{p1,p2,…,pN},N为切分图像块个数,然后按顺序展平转化为特征向量输入到预训练的ViT模型中,最终得到图像的特征表示V=[vcls,v1,…,vi,vN]。其中,vcls表示图像的整体信息,vi表示第i块图像块pi的信息。本文选取图像块大小为16×16像素,得到的图像块特征向量数N为196。
2.2 文本特征提取模块

2.3 图文交互模块
在图文跨模态检索模型中,注意力机制用于关注并聚合图像或文本中的关键信息。本文分别设计了模态间全局-局部注意力机制模块和模态内注意力机制模块进行图文特征对齐。
2.3.1 模态间全局-局部注意力机制模块
模态间注意力机制的目的是生成一个融合另一模态局部特征的全局特征表示,对于图像特征V=[vcls,v1,…,vN]和文本特征U=[up,u1,…,uT],其全局特征表示的计算过程如下:
(1)
(2)

(3)
s(ui,vcls)=tanh(Wvvcls)⊙tanh(Wv,uui)
(4)
(5)
式中:Wv,Wv,u均为前馈神经网络参数;⊙表示元素对应位置相乘;P矩阵的作用在于将文本特征的加权向量映射到图像特征向量维度。

(6)
(7)
式中:⊕表示向量拼接操作。
2.3.2 模态内注意力机制模块
在特征提取模块,本文使用了基于注意力机制的ViT模型和Transformer编码器提取图文的全局特征和局部特征,在编码器内部进行了大量的对图像块之间与单词之间的注意力计算。此时,模态内区域到区域和单词到单词注意力的计算并未考虑另一模态的影响。但在不同的情景下,即使同一模态内关注的内容也应当不同,所以模态内注意力的计算也应该考虑到另一模态的内容。故在特征交互阶段,本文考虑另一模态信息的影响,再次对模态内注意力进行计算。具体做法为:取出当前模态内对另一模态影响力最大的局部特征,将该局部特征与当前模态剩余的所有局部特征进行注意力计算,得到基于影响力最大特征的模态内局部特征加权向量。
由模态间注意力权重αcls,αp可得最大影响力局部特征Vi,Uj,其中i=argmaxαcls,j=argmaxαp。
(8)
(9)
s(·)的计算过程同公式(4),再将输出向量与原向量进行拼接,得到图像和文本的局部特征向量输出:
(10)
(11)
(12)
(13)
本文采用了文献[16]的损失函数,共分为3部分。首先,为了保持样本对于不同类别的辨别力,将输出向量进行线性层映射到类别空间,并与类别向量Y进行F范数度量,类别分辨损失定义如下:
(14)
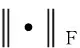
接着,对于同属于一个类别的图像,文本构造似然函数。
(15)
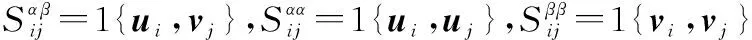
(16)
最后,为了缓解模态间差异,使用F范数约束图文表示间的距离:
(17)
组合公式,得到最终的联合损失函数表示:
J=J1+λJ2+ηJ3
(18)
式中:λ、η为超参数。
3 实验验证
3.1 数据集构建
自建数据集源自航空行业IETM相关技术手册PDF文档,由于部分图册不包含具体的图像描述且各文档格式不统一,对于无描述文本的图像采用其所在手册名、标题名和图像自身的图名进行拼接并作为图像描述。通过使用PDF文档自动化抽取技术以及正则匹配、人工补全和修正等方式,共获取3 112幅相关数据的图像样本和相关描述,并根据所在手册不同将其分为维修、检测、零件、飞行等10类。图3所示为数据集样例,从左到右依次为类别标签、图像和文本描述。近似按照6∶2∶2的比例划分数据集,得到1 912对样本作为训练集,600对样本作为验证集、600对样本作为测试集。

图3 自建数据集部分类别图像及对应文本示例Fig.3 Some category images and corresponding text examples of the self-built dataset
Pascal Sentence数据集源自Pascal VOC[20]数据集,包含1 000对图文数据,每张图片对应人工标注的5段文本描述,数据集共分为20个类别,800对样本作为训练集,100对样本作为验证集,100对样本作为测试集。
3.2 数据增强
针对自建数据集学习样本少的问题,对文本样本进行数据增强处理,以减少过拟合现象的发生。
通过在文本嵌入层添加扰动构造对抗样本,提高模型的泛化能力。使用Goodfellow提出的快速梯度算法[21],其公式为
(19)
式中:y为标签;θ为模型参数;radv为对输入x的线性扰动。
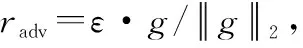
3.3 实验配置
模型使用Adam优化器,学习率设置为1e-4,输入图像大小统一缩放为256×256分辨率。采取余弦相似度并使用mAP和查准率-查全率(precision-recall, PR)曲线作为特征表示评价指标。
mAP指标综合考虑了排名信息和精度,被广泛应用在跨模态检索研究中[22]。PR曲线以召回率(Recall)和精确率(Precision)为横纵坐标绘制,反映了不同召回率下精确率的变化。
3.4 模型对比分析
为验证本文方法的有效性,本文选取了DCCA[23]、ACMR[24]、MAN[25]、SDML[26]等跨模态检索模型作为基准模型进行对比,所选对比方法均使用ResNet50[27]提取的4 096维图像特征和训练文本CNN分类模型得到的256维文本特征,部分方法额外采取了与本文特征提取网络相同的预训练ViT模型和Transformer编码器,作为特征提取器进行对比。由表1实验数据可知,本文提出的方法在Pascal Sentence数据集中相较于最好的基准方法DSCMR,以图检文的mAP从0.936提升到了0.963,以文检图的mAP从0.928提升到了0.964,mAP的平均值从0.932提升到了0.964。由表2实验数据可知,在自建数据集中相较最好的基准方法SDML,以图检文的mAP从0.848提高到了0.961,以文检图的mAP从0.871提升到了0.958,mAP的平均值从0.860提升到了0.959。在这两个数据集上,本文方法的mAP均最高,证明了所提方法的有效性。表1和表2中,*表示使用ViT、Transformer编码器作为特征编码模块。

表1 跨模态检索方法mAP(Pascal Sentence数据集)
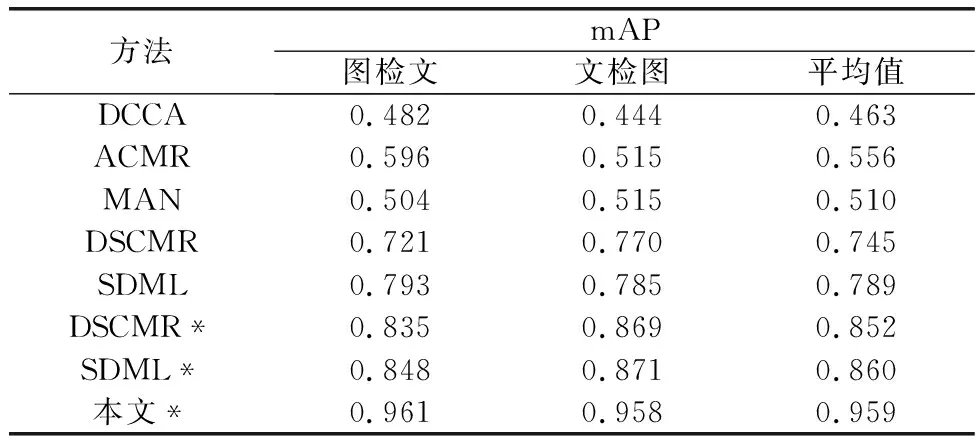
表2 跨模态检索方法mAP(自建数据集)
两个数据集指标提升的差异性主要体现在图像内容的不同以及文本长度上的差异。Pascal Sentence数据集中多为日常生活背景下的彩色图像,将5条文本描述进行拼接后,文本长度相较本文自建数据集文本也更长,所以直接采用在通用数据集上预训练的ViT模型及适合较长文本序列建模的Transformer编码器就会获得较大提升。
为进一步验证本文方法的有效性,在自建数据集上绘制精准率召回率(precision recall, PR)曲线如图4和图5所示,特征提取器分别为ViT和Transformer。由图4、图5可以直观看出,在图检文和文检图任务中,本文方法都优于文中选取的所有基准方法。

图4 图检文PR曲线Fig.4 PR curve of image retrieval text

图5 文检图PR曲线Fig.5 PR curve of text retrieval image
3.5 消融实验
设计消融实验,在自建数据集上验证各模块对模型性能的影响,实验结果如表3所示,mAP指标及损失变化如图6和图7所示。方法1为基准模型DSCMR,均采用CNN模型对图文进行特征提取。之后分别增加文本对抗增强、改变特征提取模型,增加模态间注意力及模态内注意力,验证所提方法对检索性能的影响。可以看出,方法2在增加文本对抗增强后,有助于模型性能的提升。方法3和方法4显示,由于自建数据集的大部分文本属于短文本,在不进行后续特征交互的情况下,使用基于注意力机制的Transformer编码器比使用文本CNN模型的效果要差。将方法4与方法2、方法5与方法3作对比可以看出,图像特征抽取模块使用预训练的ViT模型较预训练的CNN模型ResNet50大幅提升了模型检索准确率。方法6和方法7显示,抽取细粒度特征及在之后的图文交互阶段引入模态间注意力和模态内注意力,模型检索准确率都会取得显著提升。

表3 消融实验mAP结果对比(自建数据集)

图6 不同方法的mAP曲线Fig.6 mAP curve of different methods

图7 验证数据集损失变化Fig.7 Loss change of verification data set
3.6 参数分析
式(18)中包含λ、η两个超参数,本文在自建数据集上进行实验,采取固定一个参数、调节另一个参数的方法选择合适的超参数。实验结果如图8所示。由图8可以看出,当λ=1e-3,η=1e-1时,mAP达到了最大值。

图8 不同参数值对mAP的影响Fig.8 Influence of different parameter values on mAP
另外,本文对特征提取模块中隐空间图文特征的映射维度进行实验,分别设置维度为128维、256维和512维进行实验,实验结果如表4所示。可以看出,当映射特征维度取256维时,模型性能最佳。

表4 不同映射特征维度的mAP结果
3.7 注意力可视化分析
对模型交互阶段的图文注意力权重进行可视化分析。图9展示了自建数据集图解零件类手册中两例图文对的注意力可视化结果。从图9(a)可以看出,文本对图像注意力分别在图像的两个主体(即飞机发动机细节和发动机整体)剖视面图上,图像对文本的注意力权重主要分布在“发动机”“剖视面”词语上,二者与图中注意力关注的区域都有很强的相关性。同时,由于文本数据在处理过程中可能会出现一定的倾向性,对于出现次数较少的词语或未登录词语,使用字符代号“UNK”替代。这类结果的可视化分析如图9(b)所示,文本对图像注意力多关注在图像空白区域,而图像对文本的注意力权重则主要分布在“UNK”上。这表明模型注意力并不一定关注在人们通常认为的图像或文本的关键信息部分。对于有大范围空白的图像,其注意力可能会关注在模型认为区分度较强的空白区域和文本中的“UNK”符号上。以上两种情况均表明图文之间建立了一定的联系。

图9 注意力可视化分析Fig.9 Visual analysis of attention
4 结 论
针对现有IETM检索功能模态单一的问题,本文以航空行业IETM中的10类图文数据为研究对象,改进提出一种融合注意力机制的细粒度跨模态检索算法。构建飞机技术手册跨模态检索数据集,并根据数据集特点,对DSCMR跨模态检索模型进行改进,使用基于注意力机制的特征提取模块抽取图文细粒度特征,在图文交互模块引入模态间整体-局部注意力机制和模态内注意力机制进行图文细粒度对齐。同时,针对数据量少的情况,使用文本对抗训练,提升模型泛化能力。所提算法在一个公开数据集和自建数据集上进行了验证,mAP值较所选的最好基准算法分别提升了0.032和0.099。最后,在自建数据集上进行消融实验和参数实验,并进行注意力可视化分析,进一步验证了所提算法的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
文萃报·周二版(2022年3期)2022-01-20
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
海外英语(2013年9期)2013-12-11
海外英语(2013年10期)2013-12-10
轴承(2010年2期)2010-07-28
