
基于深度强化学习的多无人艇协同目标搜索算法
2023-12-04 02:37邢博闻张昭夷王世明娄嘉奕王五桂
兵器装备工程学报 2023年11期
邢博闻,张昭夷,王世明,娄嘉奕,王五桂
(1.上海海洋大学 工程学院, 上海 201306;2.津泰海洋工程研究有限公司,江苏 常熟 215500;3.中国船舰研究设计中心,武汉 430064)
0 引言
近年来,海洋资源的勘探和开发日益受到重视,海洋资源显示出巨大的价值[1-2]。无人艇(unmanned surface vehicle,USV)是一种小型且智能化的多用途无人海洋运载平台,因其自主性强、灵活性高、探测范围广、全天候工作等优点,已经成为海洋勘探的重要工具。无人艇在科研、军事和民用领域都得到了广泛的应用,特别是在海上联合搜救、多目标搜索和环境监测等复杂任务中[3-5]。
对于海上联合搜救、多目标搜索等任务而言,仅依靠单艘无人艇难以完成任务,需要多无人艇协同合作解决,如何对多无人艇进行有效的协同控制和路径规划是这类任务中的一项重要的关键技术[6-7]。目前,已经有很多基于多智能体的协同控制和路径规划的研究。其中,Wu等[8]提出了一种基于改进粒子群优化算法的新型协同路径规划算法,该方法以最大化搜索空间和最小化终端误差为目标,以集中式或分布式方式生成路径。Chen等[9]提出了一种基于多智能体深度强化学习算法的多船协同避碰方法,该方法通过将每艘船舶建模为一个独立的智能体,由深度Q网络算法(deep Q network,DQN)控制智能体决策,最后通过仿真实验验证了所提方法的可行性。石鼎等[10]提出了一种强化学习驱动的多智能体协同作战仿真算法,该算法在多智能体深度确定性策略梯度算法(multi-agent deep deterministic policy gradient,MADDPG)的基础上引入了解耦的优先经验回放机制和注意力机制,同时设计了一种多尺度奖励函数,通过仿真实验验证了所提算法可应用于多无人艇协同作战。
相较于传统多智能体路径规划算法,以MADDPG算法为代表的多智能体深度强化学习算法能解决动态环境下的多智能体协作与对抗问题,更加贴合现实的海上多目标搜索任务,因此,本文中提出采用MADDPG算法来解决海上无人艇多目标搜索问题。
MADDPG是一种基于Actor-Critic算法框架的多智能体深度强化学习算法,目前已经广泛应用于多智能体间的交互问题,包括多智能体完全协作、完全竞争和混合竞争等关系的场景[11]。然而,海上无人艇多目标搜索任务环境往往比较复杂,使用传统的MADDPG算法模型解决该问题时,由于经验数据利用率较低,导致收敛速度通常比较缓慢,且收敛不够稳定的情况。
针对上述问题,提出了一种新的MADDPG算法,该算法通过引入优先级经验回放机制,结合A3C算法[12]提出的异步学习训练框架,有效提高了模型的经验数据利用率,提升了算法收敛速度。称为基于优先经验回放的异步多智能体深度确定性梯度策略算法(asynchronous multi-agent deep deterministic policy gradient based on PER,PA-MADDPG)并且,针对海上多无人艇目标搜索问题修改了模型奖励函数,以增强目标搜索的引导,并根据奖励函数构建了仿真环境进行模型训练,验证本文中提出算法模型的收敛性。然后,将本文中提出算法的效果与PER-MADDPG算法[13]、MADDPG算法和MAPPO算法的效果进行对比,验证本文算法的实用性。
1 任务描述与建模
1.1 多无人艇目标搜索任务
碰撞问题是多无人艇目标搜索任务中亟需解决的重要问题之一,碰撞问题的产生是由于多艘无人艇在同一片存在障碍物的区域内执行多目标点搜索任务,而搜索过程中生成的路径容易发生交叉重叠,导致无人艇之间发生碰撞。同时,在搜索过程中无人艇也可能与任务区域内的障碍物发生碰撞。
对多无人艇目标搜索任务的描述如下:同一片任务海域内存在N艘无人艇、N个目标点以及N个障碍物。无人艇、目标点和障碍物的位置随机生成,多艘无人艇从各自的起始位置同时出发,根据距离目标点的距离和安全性约束进行调整,直到完成所有目标点的搜索。具体而言,在搜索过程中,每艘无人艇都需要与其他无人艇保持安全距离,防止无人艇之间发生碰撞,同时,无人艇还需要完成对任务区域内障碍物的避障。为了更贴近真实的情况,障碍物包括静态障碍物和动态障碍物,在本文中考虑的多无人艇目标搜索的场景下,无人艇之间可互相视为动态障碍物。
1.2 无人艇运动模型
因为多无人艇目标搜索问题具有高维度、高复杂性的特点,所以为简化研究问题,将多无人艇目标搜索任务的运动环境设置在二维空间中。考虑二维平面区域里的多无人艇目标搜索,并且构造笛卡尔直角坐标系,表示无人艇和障碍物的位置信息和运动状态,如图1所示。

图1 无人艇和障碍物运动模型Fig.1 USV and obstacle motion model
将无人艇简化为半径为ri的圆形智能体i,其搜索的目标点设为半径为rgi的圆形空间,障碍物为半径为roi的圆形区域。用Dgi表示无人艇与目标点之间的距离,Doi表示无人艇与障碍物之间的距离,Dij表示无人艇之间的距离。智能体i的位置用Pi=(xi,yi)表示,速度用vi表示,速度角用φi表示。
则无人艇的简化运动模型定义为

(1)
式(1)中: (xi,yi)表示无人艇的位置坐标;vi表示无人艇的速度;φi表示无人艇的速度角;ωi表示无人艇的角速度。
无人艇的连续轨迹可建模为一系列的连续离散点,由于速度是矢量,则每2个相邻时间步对应的智能体位置之间都有一个方向,二维位置和相应的时间步构成了每个智能体的运动轨迹。
设无人艇i下一时刻的位置为P′i=(x′i,y′i),速度角为φ′i,运动时间间隔为t,则无人艇i在下一时刻的状态为

(2)
障碍物的运动模型和无人艇的运动模型相似。
1.3 马尔可夫决策模型
强化学习由智能体和环境2个部分组成,智能体模型已经在1.2节介绍。目前,在强化学习问题中,马尔可夫决策模型是使用最广泛的环境模型。对于多智能体运动规划问题,需要建立联合空间,包括智能体的观测空间、动作空间和奖励函数等。本节将对文章使用的马尔可夫决策模型进行简单介绍。
1) 观测空间
考虑智能体只能观测到环境局部信息的情况,因此智能体的观测空间存储的是局部的环境观测信息。智能体接收一个观测值作为输入,其中包括智能体的当前位置、与其他智能体的距离、与目标的距离以及与障碍物的距离的信息。因此,将智能体的观测空间用一个元组((xi,yi),Dij,Dgi,Doi)表示。并且,观测值是连续的,因此将观测值归一化在范围内。
2) 动作空间
考虑智能体采用连续动作的情况,因此智能体i的动作空间是连续的。智能体i的动作由它的速度和速度角决定,智能体可以选择一个速度(0和最大速度之间的值)和一个角度(和之间的值)。因此,将智能体的动作空间用一个元组(vi,φi)表示。
3) 奖励函数
奖励在引导智能体学习有效的导航策略中起着至关重要的作用,本文考虑的奖励通过智能体的位置、智能体与目标、障碍物及其他智能体的距离来计算。基础奖励为距离最近的目标点的距离的负数,发生碰撞或者智能体越界则额外减5。则奖励函数如下:

(3)
1.4 运动规划过程描述
本文中考虑的任务目标是多智能体能够在存在障碍物的任务区域内,以最小的碰撞和时间步完成目标搜索,到达所有目标点。因此,对于智能体i,其目标可表示为
Pi=Pig
(4)

(5)
式(4)中:Pi和Pig分别表示智能体位置和目标点位置;π表示所有智能体的策略集合;LTi表示目标函数。上述目标的约束可表示为

(6)
由式(6)可知,任何时刻,智能体都不能与障碍物、其他智能体及区域边界发生碰撞。
2 PA-MADDPG算法
2.1 基础MADDPG算法
由于在多无人艇的环境中,每一艘无人艇都是独立的智能体,都在不断地学习且更新策略。因此,对每个智能体而言,环境是不稳定的。并且,大量智能体与环境交互将大大提升计算成本,传统强化学习算法容易发生维度爆炸问题[14]。针对上述问题,学者们提出了多种基于多智能体环境的强化学习算法,其中,MADDPG算法在多智能体合作和博弈中表现良好,为多无人艇目标搜索问题提供了新的解决方案。
MADDPG算法沿用了传统Actor-Critic算法的基本思想,并采用集中训练,分散执行的方法框架进行了改进。在训练阶段,智能体的Critic网络允许引入全局信息。而在测试阶段,智能体的Actor网络只允许使用局部信息。MADDPG算法的框架如图2所示。

图2 MADDPG算法框架Fig.2 MADDPG algorithm framework
相对于传统DDPG算法,MADDPG算法环境中共有n个智能体,用πi表示第n个智能体的策略,θi表示其策略参数,则第i个智能体的累积期望奖励为

(7)
式(7)中:π=(π1,π2,…,πn)为策略参数集合;pπ为状态分布;a=(a1,a2,…,an)为联合动作;πθi为动作策略;γ为折扣因子;ri,t为t时刻智能体的奖励。
则针对随机策略,第i个智能体的策略梯度为

(8)
进一步将策略梯度扩展到确定性策略,则第i个智能体的策略梯度为
(9)
式(9)中:μi为个连续策略;D为经验池。Critic网络的更新方式借鉴了传统强化学习算法中的TD-error思想。利用预测值和真实值之间的误差来更新算法,式(10)和式(11)分别表示预测值和真实值:

(10)
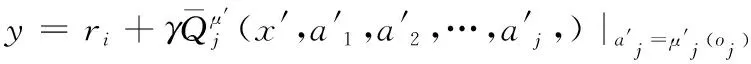
(11)
2.2 基于优先经验回放的MADDPG算法
经验回放(experience replay,ER)是一种强化学习技术,用于打破连续经验之间的时间相关性,从而促使智能体更稳定的学习。然而,并不是所有的经验对学习都同样重要,有些经验更具有学习价值。MADDPG算法同样采用了经验回放机制。但是采用均匀采样,忽略了经验池中经验数据之间的重要性差异,导致算法出现采样效率不高、算法学习效率低和模型收敛速度慢等问题。
针对上述问题,2016年,Schaul等[15]提出优先经验回放(prioritized experience replay,PER)技术,并且已经广泛应用于DQN、DDPG等单智能体强化学习算法中,解决了均匀采样问题。该技术通过引入TD-error对每个经验数据进行重要性标记,同时,使用随机优先采样法,根据标记的TD-error大小指定采样的策略,采样到设置为重要样本的经验数据的几率更大。本文中将上述单智能体的优先经验回放技术引入到基于MADDPG算法的多智能体任务中。
优先经验回放的核心理念是更频繁地回放非常成功或极其糟糕的经验,因此,界定衡量经验价值的标准是核心问题。强化学习算法采用TD-error的值对动作价值函数Q(s,a)的估计进行修正,因此,TD-error的值可以间接地反映智能体从经验中学习的程度。TD-error的绝对值越大,则对动作价值函数的修正作用越大。在这种情况下,具有较大TD-error的经验可能具有更高的价值,可以帮助智能体更好地学习。此外,智能体表现不佳的动作和状态对应着具有较大负TD-error的经验,更频繁地回放这些经验,可以帮助智能体逐渐学习到在相应状态下错误行为的后果,避免再次做出相同的错误行为,从而提高算法整体性能。因此,选取TD-error的绝对值作为衡量经验值的指标。则对经验j的TD-errorδi,计算公式如下:
δi=r(st,at)+γQ′(st+1,at+1,ω)-Q(st,at,ω)
(12)
式(12)中:Q′(st+1,at+1,ω)为ω参数的目标动作价值网络。
当δi值较大时,目标网络的预测值与该经验的实际值存在较大误差,此时,需要增加该经验的采样频率,尽快耦合目标网络和现实网络的值,以优化训练效果。因此,引入采样概率经验,定义经验j的采样概率为

(13)
引入采样概率可以看作是在选择经验时加入随机因素,这样TD-error较小的经验也有机会被回放,进而保证了采样的多样性,有助于防止神经网络过拟合。
然而,由于本文更倾向于频繁回放具有高TD-error的经验,将会改变状态访问频率,导致神经网络训练过程容易出现震荡甚至发散的问题。为解决这个问题,又引入重要性采样权重ωj:

(14)
式(14)中:S表示经验池大小;P(j)表示经验的采样概率;参数β控制重要性采样权重在学习过程中的影响。
2.3 改进的PA-MADDPG算法
当环境中智能体和障碍物数量增多,环境复杂程度上升时,智能体的探索空间也将扩大,直接进行随机探索的效率较低,导致训练耗时长、训练不稳定及收敛缓慢的问题。2016年,DeepMind提出异步优势行动者评论家算法(asynchronous advantage actor critic,A3C),该算法提出的异步训练框架能有效提高探索效率,加快训练速度。
因此,针对上述问题,在2.2节介绍的引入优先经验回放机制的MADDPG算法基础上,采用并行计算的手段,引入了异步训练框架,提出一种训练速度更快的多智能体强化学习算法,称其为PA-MADDPG算法。
PA-MADDPG算法采用异步训练的框架,但仍保留MADDPG算法中集中训练,分散执行的框架。PA-MADDPG算法使用的异步框架如图3所示。
图3中的全局网络(Global Network),即主进程,保留了集中训练,分散执行的框架,包含一个集中训练的价值网络和一个分布式的策略网络。在主进程之下并行了个子线程(worker),每个子线程的网络结构都和主进程网络结构一样,且每个子线程将独立和环境交互得到经验数据,子线程间互不干扰。当一个训练周期结束后,每个子线程将计算自己的神经网络损失函数和梯度,然后将这些信息传回主进程,进而更新主进程中的神经网络参数,但并不更新子线程中的网络。同时,每隔一定周期,主进程也会复制参数到各个子线程中,进而指导后续的环境交互。

图3 PA-MADDPG异步训练框架Fig.3 PA-MADDPG asynchronous training framework
由此可知,主进程中的神经网络模型是智能体需要学习的,而各个子线程中的神经网络模型只用来更好地训练智能体与环境进行交互,从而促使智能体拿到更多高质量且多样化的交互数据来帮助主进程模型训练,加快模型收敛。
综上,本文中提出的PA-MADDPG算法框架如图4所示。

图4 PA-MADDPG算法框架Fig.4 PA-MADDPG algorithm framework
3 结果与分析
3.1 实验设计
采用文献[16]使用的MPE多智能体强化学习实验平台,基于实验平台中多智能体合作导航的simple spread实验场景,对实验场景进行修改,增加了固定障碍物,修改后实验场景如图5所示。修改后的MPE环境由连续空间和离散时间的智能体、固定障碍物和目标点组成。n个智能体合作导航以到达各自的目标点,在寻径的过程中需要避开障碍物和其他智能体,目标是学习使智能体以最少的碰撞和最短时间步到达目标点的有效策略。

图5 多智能体合作实验环境Fig.5 Multi-agent cooperation experiment environment
实验将在上述实验场景中,对比本文中提出的PA-MADDPG算法、引入PER机制的MADDPG算法、MADDPG算法和MAPPO算法效果,进而验证改进PA-MADDPG算法的有效性。实验将使用3个指标来衡量算法在多目标搜索路径规划中的性能,指标是全局奖励、碰撞次数(智能体和障碍物以及智能体之间)和目标搜索成功率。实验超参数如表1所示。

表1 实验超参数
3.2 实验结果与分析
本实验对比使用PA-MADDPG、PER-MADDPG、MADDPG和MAPPO算法的智能体在相同实验环境下,合作进行多目标搜索路径规划的效果。
图6为4种算法在经过5 000个回合训练后的全局平均总奖励对比曲线。由图6可知,4种算法的全局平均总奖励都取得了收敛的效果。原始MADDPG算法和MAPPO算法收敛较慢,都大约在4 000回合后才收敛,且MAPPO算法的收敛过程波动较大,效果也不稳定。PER-MADDPG算法和本文中提出的PA-MADDPG算法都大约在1 000~1 200回合训练后就进入平稳收敛状态,且收敛效果稳定,但本文中提出算法的收敛过程波动更小。

图6 回合平均总奖励Fig.6 Episode average reward
总而言之,本文算法相较于原始MADDPG算法和MAPPO算法,收敛速度明显提升,大约在1 000~1 200个回合训练回合就收敛,且前1 000个回合训练收敛过程的波动明显更小。相较于PER-MADDPG算法,虽然本文算法在收敛速度方面没有明显优势,但本文算法在前1 000个回合收敛过程波动更小。
图7为4种算法在5 000个回合训练中,智能体与障碍物、其他智能体以及环境边界的碰撞次数总和对比。由图7可知,相较于其他算法,本文中提出的PA-MADDPG算法的智能体总碰撞次数在1 000回合训练后就已经收敛,且收敛前智能体的总碰撞次数也远低于MAPPO算法和MADDPG算法。原始MADDPG算法难以收敛,1 000回合训练后仍频繁发生碰撞,智能体避碰效果最差。

图7 总碰撞次数Fig.7 The total number of collisions
图8为4种算法在3个不同实例回合下的任务成功率,本实验定义所有智能体在最大回合数内成功到达各自的目标点为任务成功。由图8可知,显然本文提出算法的任务成功率最高,MAPPO算法的成功率最低。相较于其他3种算法,本文中提出算法的任务成功率提高了5%~10%。
图9为本文中提出的PA-MADDPG算法模型经过训练后得到的无人艇轨迹图。
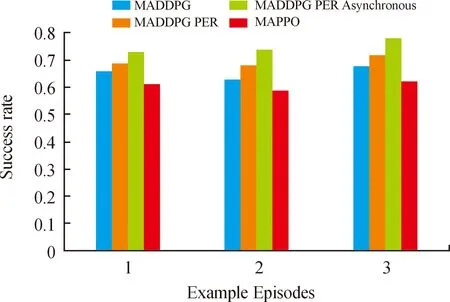
图8 多目标搜索任务成功率Fig.8 Multi-agent search task success rate

图9 无人艇轨迹图Fig.9 The trajectory of USV
4 结论
针对海上无人艇多目标搜索问题,提出一种基于优先经验回放的异步MADDPG算法模型。主要结论如下:
1) 针对传统MADDPG算法模型存在的经验数据利用效率不高和模型训练速度较慢等问题,在传统MADDPG算法的基础上引入了优先经验回放机制和基于A3C算法的异步学习训练框架。
2) 提出的PA-MADDPG算法在针对无人艇多目标搜索任务有着较好的应用效果,相比于PER-MADDPG、MADDPG和MAPPO算法有着更好的表现,在1 000~1 200个回合训练后模型就达到了收敛,智能体总碰撞次数也在1 000个回合后趋于0,任务成功率提高了5%~10%。
在下一步研究工作中,考虑将本文中提出的算法扩展到三维环境的海面无人艇多目标搜索问题中,同时,将固定的目标点改成移动目标点,以求能近一步接近真实的海面搜索状况。
猜你喜欢
党课参考(2021年20期)2021-11-04
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
小哥白尼(军事科学)(2019年2期)2019-04-17
小哥白尼(军事科学)(2019年6期)2019-03-14
小哥白尼·趣味科学画报(2019年12期)2019-02-28
党课参考(2018年20期)2018-11-09
岷峨诗稿(2017年4期)2017-04-20
新高考(英语进阶)(2017年12期)2017-02-26
都市丽人(2015年4期)2015-03-20
