
Automatic depression recognition by intelligent speech signal processing: A systematic survey
2023-12-01 10:37PingpingWuRuihaoWangHanLinFanlongZhangJuanTuMiaoSun
Pingping Wu | Ruihao Wang | Han Lin| Fanlong Zhang | Juan Tu |Miao Sun
1Jiangsu Key Laboratory of Public Project Audit,School of Engineering Audit,Nanjing Audit University,Nanjing, China
2School of Information Engineering, Nanjing Audit University,Nanjing, China
3Key Laboratory of Modern Acoustics(MOE), School of Physics, Nanjing University, Nanjing,China
4Faculty of Electrical Engineering, Mathematics& Computer Science,Delft University of Technology,Delft, The Netherlands
Abstract Depression has become one of the most common mental illnesses in the world.For better prediction and diagnosis, methods of automatic depression recognition based on speech signal are constantly proposed and updated, with a transition from the early traditional methods based on hand-crafted features to the application of architectures of deep learning.This paper systematically and precisely outlines the most prominent and up-to-date research of automatic depression recognition by intelligent speech signal processing so far.Furthermore, methods for acoustic feature extraction, algorithms for classification and regression, as well as end to end deep models are investigated and analysed.Finally, general trends are summarised and key unresolved issues are identified to be considered in future studies of automatic speech depression recognition.
K E Y W O R D S acoustic signal processing, deep learning, feature extraction, speech depression recognition
1 | INTRODUCTION
Depression has become a global health crisis in recent years with younger and faster growth and wider coverage.According to the data of World Health Organization, it is estimated that 5% of adults suffer from the disorder globally.Over 300 million people in the world have depression while over 54 million in China[1].However,only 10%of depressed patients seek medical treatment in China while COVID-19 pandemic brings more challenges[2–4].Depression can increase the risk of suicide in severe cases.People with depression are 20 times more likely to commit suicide [5].In addition, depression has become the fourth leading cause of death among people aged 15–29 [6].Accordingly, depression not only burdens patients with a heavy financial burden, causing huge losses to individuals but also affects families and communities, and hinders the sustainable development of nations.
At present, the diagnosis of depression is usually made by questionnaires such as the Hamilton Rating Scale for Depression(HAM-D)[7],the Beck Depression Inventory-II(BDI-II)[8],the Patient Health Questionnaire(PHQ)[9],the Quick Inventory of Depressive Symptomatology[10],the Youth Mania Rating Scale(YMRS)[11],the Montgomery Åsberg Depression Rating Scale(MADRS)[12],and the Diagnostic and Statistical Manual of Mental Disorders-IV (DSM-IV) [13].Besides,objective physiological indicators are supplemented.However,such diagnostic methods rely on patient's cooperative attitude,expressiveness, and familiarity with the questionnaire.At the same time, a large amount of clinical data is also required to support the diagnosis.What's more, there are other types of depression in addition to the most common major depressive disorder (MDD), further increasing the difficulty of diagnosis.Misdiagnosing the depression type or using the wrong treatment may delay or even worsen the patient's condition.Therefore,it is of great significance to find accurate, effective and objective diagnostic features for different types of depression.
Recently,automatic depression recognition and analysis has received extensive attention in the fields of medicine,psychology,and computer science.Since depressed patients and normal people behave differently in facial expressions, body postures,speech signal,physiological signals,and audio,researchers have tried to collect and analyse above information of depressed patients to predict the level of depression.In this article, we focus on automatic depression recognition by intelligent processing of speech signal as speech signal can reflect the depression tendency of subjects with slowed speech rate, prolonged pause,and different pitch changes[12,14].Specifically,in acoustics,the fundamental frequency F0 of the patient has a limited change while the second formant F2 is significantly reduced and the degree of variation in low frequency spectrum is decreased.Hence,the correlation of speech acoustic features with depression makes it a reliable objective marker for depression assessment [15].Moreover, speech signal can be acquired non-intrusively,remotely,and the cost is relatively low,speech depression recognition(SDR)is easier to start than the research based on other modalities.In specific, SDR has undergone a transition from the early traditional methods based on hand-crafted features to the application of architectures of deep learning,from the usage of only acoustic features to the current application of multiple features[16–18].However,there is still a lack of a research review to systematically and precisely sort out methods of automatic depression recognition by intelligent speech signal processing so far.
On the basis of extensive literature reading, this paper makes a systematic and in-depth summary of SDR, and gives an overview of the development history of the methods used in different stages.The main contributions of this paper are:(1)Introduce and sort out the most prominent and up-to-date literature in SDR in recent years in chronological order; (2)Investigate major trends in SDR and analyse their corresponding pros and cons; (3) Explore promising research directions for SDR in the future.The rest of this paper is organised as follows:Section II provides a detailed description and discussion of research evolution; Section III is about public datasets employed for automatic depression recognition.Section V gives conclusion and future work of SDR.
2 | RESEARCH EVOLUTION
Acoustic signal processing and machine learning technology jointly push the development of SDR.Figure 1 shows the development history accordingly.As proved in previous works,the acoustic features of depressed patient are different from healthy individuals[19–21].Therefore,in the early stage of the studies of SDR, the main work is to learn acoustic features related with depression and explore feature set for better performance [22, 23].In the meantime, traditional machine learning algorithms are employed in SDR such as Support Vector Machine (SVM) [24–27], Hidden Markov Model [28],Gaussian Mixture Model (GMM) [[27, 29, 30], K-means [31,32], Boosting Logistic Regression [33–35], multi-layer perceptron [30, 35], etc.
In recent years, deep learning methods have made breakthroughs in the research fields of both Computer Vision(CV)and Nature Language Processing (NLP).Therefore, many studies have shifted from the traditional hand crafted acoustic features to the framework based on deep learning for SDR[36].There are two application ways for deep learning methods in this field.One is to extract hand-crafted features from speech signals and then input them into deep neural network[37],where deep framework is only used as classifier.The other is to apply an end-to-end deep architecture, which feeds the original audio signal or spectrum to deep network to learn high-level features automatically [38].As it could solve the problems encountered in hand-crafted features, such as high threshold, labour cost and low feature utilization rate, deep learning slowly becomes the leader in the field of machine learning.In addition,different neural network architectures are employed such as Convolutional Neural Networks(CNN)[39],Recurrent Neural Networks (RNN) [40], Long Short-Term Memory networks (LSTMs) [41], and Transformer [42].
However, in recent study, speech signal processing has received renewed attention because vocal features capture psychomotor activity associated with depression.Specifically,depressed patients have worse vocal tract coordination, so vocal tract variables and articulatory coordination features can be represented by channel delay correlation matrix, improving recognition performance effectively in SDR [43, 44].Accordingly, acoustic features combined with deep learning become the most popular architectures in SDR.
2.1 | Speech depression recognition based on hand‐crafted features
2.1.1 | Extraction of hand-crafted features
As mentioned in previous section, depressed patients have cognitive and psychomotor differences compared to normal people.Owing to the sensibility of speech, slightly physical or cognitive change could result in obvious acoustic change[20, 45, 46].In earlier research of SDR, low-level acoustic features are regularly used together with statistical features while some feature extraction tools are employed to extract features directly such as COVAREP, OpenSMILE.The commonly used acoustic features are as follows:
Prosodic features include changes in pitch and loudness,as well as changes in the length of syllables,words and phrases[33, 47–49].Among them, fundamental frequency (F0) and energy are used to represent pitch and loudness perception characteristics [50].
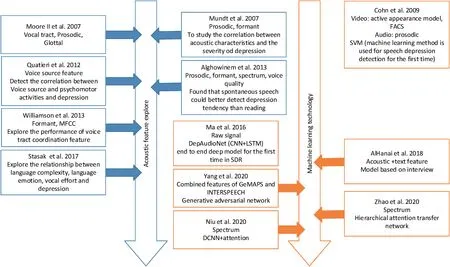
F I G U R E 1 Development history of speech depression recognition (SDR)
Voice quality features capture characteristic information of speech generating sources.These features can parameterise the airflow from lung to glottis and vocal tract motion including:Normalised Amplitude Quotient (NAQ), Quasi Open Quotient, Harmonic Difference H1-H2 and H2-H4, spectrum perturbation and amplitude perturbation[33,43,49,51].
Formant features include information about vocal tract resonance and pronunciation efforts, which reflect the characteristics of physical vocal tract.The first three formants (F1-F3) are usually used as formant characteristics in SDR [47, 50].
Spectral features represent the correlation between vocal tract shape changes and articulator movement including spectral flux, energy, slope and flatness [49, 52], Mel- Frequency Cepstrum Coefficient (MFCC) [33] and Linear Predictive Cepstrum Coefficient [49, 52, 53].
In recent years, acoustic features regain researchers'attention as it is found that fusion of acoustic features can improve the performance of SDR.As shown in Table 1,typical acoustic Low Level Descriptors (LLDs) and their statistic features in SDR are enumerated.Besides, Articulatory Coordination Features(ACF)has achieved great success in SDR by quantifying the time change of pronunciation action [43, 54].By investigating the correlation between MFCC and formant,Williamson et.al achieve excellent recognition result in SDR[54].Besides, some following studies show good prospect of ACF-based vocal tract variable features in SDR [55, 56].
2.1.2 | Classification algorithms
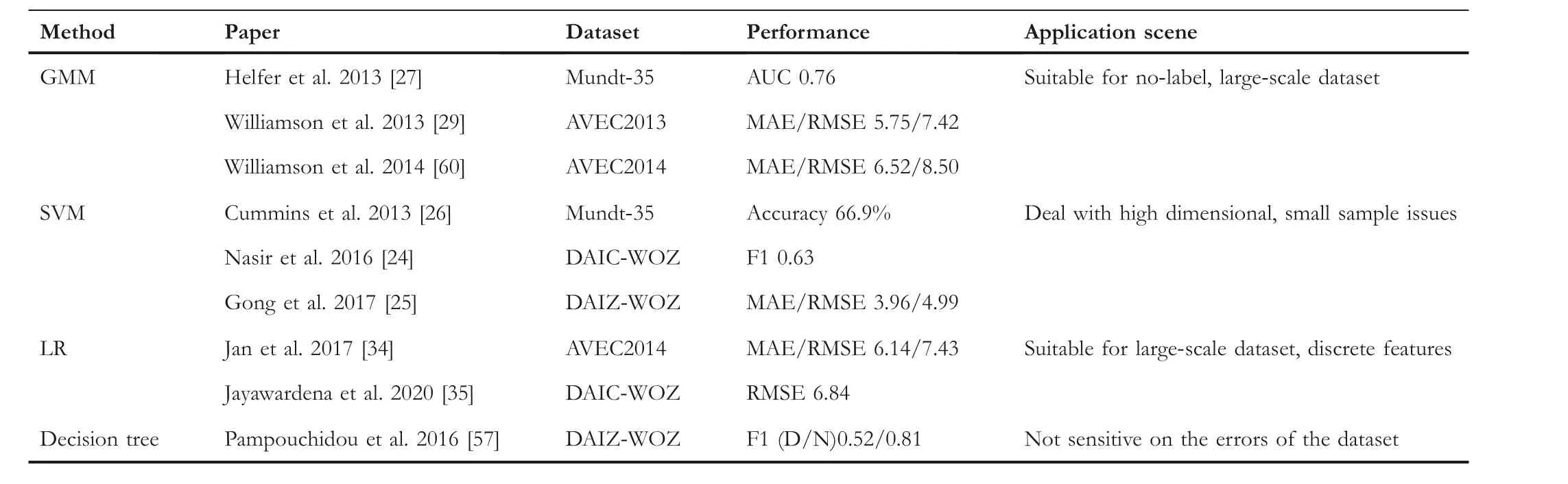
In early research of SDR,traditional classification or regression algorithms are employed after feature extraction such as Support Vector Machine (SVM), Logistic Regression (LR),Random Forest, Decision Tree, Gaussian Mixture Model(GMM), K-means, etc., which are as shown in Table 2.
Support Vector Machine is a classical machine learning algorithm based on statistic, which shows excellent performance in high-dimensional, small sample and nonlinear problems.Due to the high-dimensional extracted acoustic features, small-scale depressive speech dataset, SVM became the most popular classification algorithm in early research of SDR [24–27, 58].For example, Gong et al.employed a topic modelling-based approach to explore context-relevant information in depressive data (audio, video, text) using a Support Vector Regressor(SVR)with three kernels(linear,polynomial,radial basis functions) for his prediction task [25].However,this algorithm is slow to train and its performance is affected by the combination of kernel functions and model parameters,and results are slightly less interpretable.
Logistic Regression (LR) is also a common classification algorithm based on statistics.Despite similar to SVM, LR is usually applied in large-scale dataset and can only process discrete features.Due to its discretisation feature, logistic regression is chosen to use for its fast speed,strong robustness,easy crossover and feature combination[33–35].Zaremba et al.designed an integrated algorithm based on logistic regression[33], which can preserve the diversity of feature subspace andextract more discriminative features, which shows better performance than GMM, SVM, random forest, decision tree and AdaBoost.

T A B L E 1 Typical acoustic Low Level Descriptors (LLDs) and their statistic features in SDR
T A B L E 2 Some traditional classification and regression algorithms applied in speech depression recognition (SDR)
Gaussian mixture model (GMM) uses Gaussian distribution as the parameter model and is trained by expectation maximum, which shows outstanding performance in no-label,large-scale dataset.As a clustering algorithm,it is employed in early research of SDR[27,30,59,69].Moreover,GMM-based regression methods such as Gaussian Staircase Regression(GSR) are proposed, where each GMM consists of an ensemble of Gaussian classifiers [29, 54, 61, 62].In specific,firstly, speech features are mapped to different partitions of clinical depression score,then the mapping results are used as the basis of regression analysis.
2.2 | Speech depression recognition based on deep learning
Due to the successful application in CV and NLP, deep learning is introduced to SDR.Compared with traditional methods,no human intervention is needed after the model and parameters are determined.The essence of deep learning is to learn high-level abstract features automatically by building more hidden layer models to improve the accuracy of classification or score prediction.
There are two ways to employ deep learning in SDR: (1)Build a structure combined acoustic features with deep learning method.Traditional acoustic features or deep acoustic features are then put into the deep classifier for training,recognition or prediction.When used as a feature extractor,deep learning can avoid high labour cost and large-scale loss of feature, and the extensibility is better than traditional method.When used as a classifier, deep classifiers have many advantages,including dealing with complex structures and functions,and unlabelled and incorrectly labelled data.(2) Build an endto-end deep architecture and then push raw signal or spectrogram into deep architecture to let model learn high-level features by itself.
2.2.1 | Deep learnt features
In Speech Emotion Recognition, deep speech features through pre-trained deep network have made remarkable performance and are robust to noise changes [63, 64].Accordingly, deep features are employed in SDR.Yang et al.[65] used DCNN-DNN to forecast depression severity score.Firstly, push multi-modal features in DCNN to learn high global features with tight dynamic information.Then lead these features in DNN to forecast PHQ-8 score.Finally, the PHQ-8 scores of each mode are fused to obtain the final result.Dong et al.learnt the deep feature from the original signal and spectrum through ResNET, and then calculated the correlation coefficient of delay multi-channel change with the Feature Variation Coordination Measurement algorithm to obtain the coordination feature and learn the time information of the deep feature [66].Seneviratne et al.designed a double-layer neural network architecture of dilated CNNLSTM [43].In the first layer, dilated convolution neural network (dilated CNN) was used to extract articulatory coordination features (ACF).In the second layer, the channel delay matrix was constructed to solve the problems of repeated sampling in traditional methods and discontinuity on the boundary of adjacent sub matrix.Also, Huang et al.used the model of all channel coordination convolution neural network (FVTC-CNN) to predict depression, in which the expanded convolution neural network was used to extract the characteristics of channel coordination [44].
Recently, auto-encoder shows its good prospect in SDR as a deep feature extractor [38, 65, 67–70].Auto-encoder consists of two parts: encoder and decoder, encoder is used to learn the abstract features of the input data, and the function of the decoder is to remap the abstract features back to the original space to obtain the reconstructed data.The optimization goal is to optimise the model by minimising the reconstruction error to learn the abstract features of the input data.The advantage of automatic encoder is that it belongs to unsupervised learning and does not rely on annotation of data.Therefore, automatic encoder can be regarded as an unsupervised nonlinear dimensionality reduction feature extraction method.Then several improved models are proposed for different scenarios, including denoising auto-encoder [71], sparse auto-encoder [72],convolution auto-encoder [73], variational auto-encoder [74],adversarial auto-encoder [75].For example, Sardari S., et al.extracted deep features from speech depression data by convolution auto-encoder [76].Due to the outstanding performance of processing local data, convolution auto-encoder has stronger feature learning ability than auto-encoder, which also solves the problem of sample imbalance in the data set by resampling method based on clustering.The experimental results show that the recognition effect is better than the previous ensemble CNN, DepAudioNet, SVM and other methods.
2.2.2 | Deep classifiers
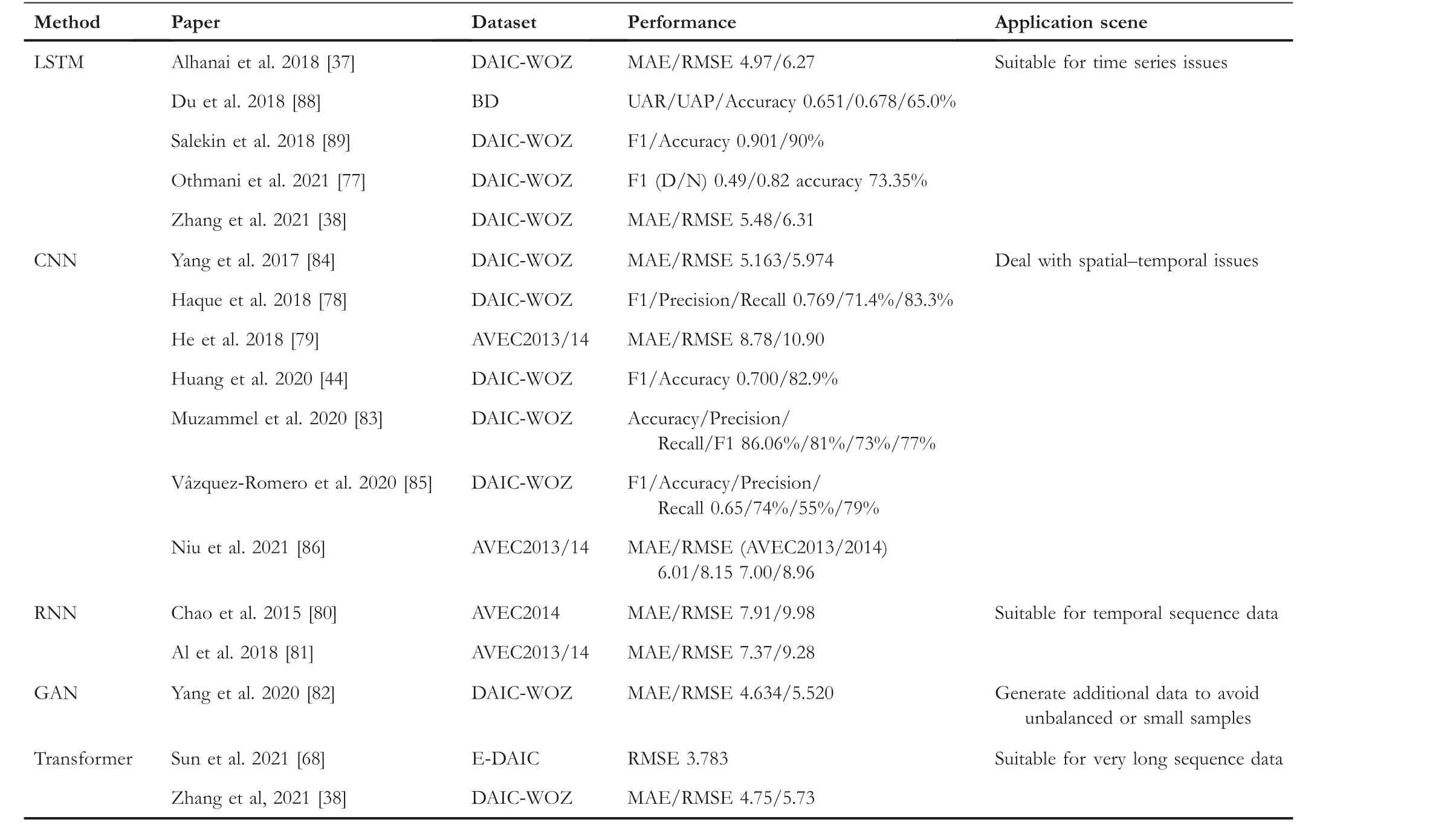
In SDR, the commonly used deep classifier algorithms including Recurrent Neural Network (RNN), Deep Belief Network, Convolution Neural Network (CNN), etc.As Table 3 shows.
In specific, CNN could capture spatial properties of features and has the ability of parallel computing.Therefore,CNN can be used as a classifier for MFCC,spectrum or some other deep learnt features [38, 44, 68, 77, 83–86].Aiming at characteristics of depressed patients with more speech pauses and slower speech speed, and the problem that LSTM does not perform well in long sequences, Haque et al.proposed causal convolution neural network (C-CNN) to deal with audio [78], text and video data to get multi-modal sequencelevel feature instead of LSTM.In addition, ensemble learning can improve recognition performance by combining multiple models and the performance of ensemble convolutional neural network model (integrating 50 one-dimensional convolutions) is also utilised in SDR [85].The research shows that the effect of integrating CNN is significantly better than normal CNN method when the convolution kernel size is appropriate((1,3),(1,5),(1,7)).In recent,Niu et al.proposed a CNN model based on attention mechanism, namely timefrequency channel attention (TFCA) block [86], which is used to emphasise the timestamp,frequency band and channel related to depression detection.TFCA block solved the problem that CNN global pooling cannot consider time domain information of data.Although CNN is favoured by researchers because of its excellent characteristics such as local connection, weight sharing, pooling operation and multi-layer structure, but at the same time, it should also realize its training difficulty and performance problems in very deep networks.
RNN is a network based on sequence information, where adjacent information is interdependent.Normally, this interdependence is useful in predicting the future state.Like CNN,it was born at the end of the last century.The great brilliance of RNN in deep learning originated from[87]while LSTMs is the most common RNN model in SDR.It avoids problems such as gradient disappearance to a certain extent,and can relatively learn information of long time series, so it is suitable for time series data such as speech.Since deep learning methods have been popularised in the field of SDR,a number of RNN-based studies have been carried out[37,38,77,88,89].Alhanai et al.employed LSTM to detect depression with Audio/Text feature and came to a conclusion that the performance of context-free model is better than context-weighted model [37].Du et al.proposed a novel LSTM module, namely IncepLSTM [88], by combining inception module and LSTM to adapt to the situation that bipolar disorder occurs irregularly in different time periods.However, RNN-related algorithms have high time cost due to their poor parallel ability,and RNN cannot be able to cope with data that is too long.
2.2.3 | End to end deep architectures
Compared with methods of performing feature extraction and classification separately,an end to end deep architecture pushes raw signal or spectrogram into its model to learn and give results as shown in Figure 2.End to end deep architecture have advantages like that it does not require scholars to have a priori knowledge, deep networks can learn better features and give better classification result.However, there are a few issues which limit end-to-end deep architectures, such as large-scale data supporting, overfitting easily and poor interpretability.
Ma et al.designed a deep model combined DCNN with LSTM instead of previous SDR method based on acoustic feature [36], named DepAudioNet.In their research, CNN is applied to extract high-level feature from raw wave while LSTM is used to learn the temporal change of Mel scale filter feature, which achieved good results on the DAIC-WOZ data set, and also strongly promoted the follow-up end-to-end model research.
Othmani et al.designed a deep neural network architecture called EmoAudionet [77], input the preprocessed spectrum into DCNN network and combine it with CNN network based on MFCC features to improve performance.The results show that the accuracy of EmoAudionet training in DAIC-WOZ is 73.25%, while the F1 score is 82%.
T A B L E 3 Some deep classifiers applied in speech depression recognition (SDR) and their performance
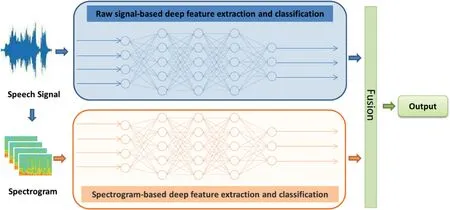
F I G U R E 2 Framework of an end to end deep architecture
End-to-end deep model is difficult to determine the contribution of each module in the architecture due to its endto-end characteristics, limiting further performance improvement.In a word, end-to-end deep architectures have not yet been widely used in the field of SDR because of its poor interpretability,flexibility and current limited dataset scale.For now, the most popular method is still the combination of acoustic features and deep classifiers.
3 | DATASETS
Different from speech emotion datasets, acted and evoked datasets are difficult to apply directly to SDR.Generally,speech depression datasets are recorded during the conversation from clinical doctor with depressed patients by face-toface, telephone interviews or virtual interviewers.In some data collection processes, other modality information, such as depression scale data, facial expression data, physiological dynamic information,etc.,are also recorded at the same time for auxiliary analysis.
Normally, a SDR dataset is composed of three parts:interactive interviews with subjects, descriptions of pictures,and recitations.Study finds that results of gender-specific SDR are affected by different parts of the data.For male subjects,descriptions of pictures performed best for SDR.However,for female subjects, interactive interviews performed best.Therefore,designing different data acquisition schemes for gender is an option worth considering.Moreover, it has been studied whether positive, neutral, or negative speech affects the result of SDR, but a unified conclusion has not yet been reached.Jiang et al.[90]believed that these three affective states had no significant effect for SDR.However, the results of the study[67]showed that the overall accuracy of SDR was reduced after removing negative speech.Therefore, further research is required to verify the association of different affective states with depression.
3.1 | Representative datasets
The collection of speech depression data is the basis for conducting research of SDR.Table 4 lists representative datasets in SDR.
AVEC2013 dataset and AVEC2014 dataset are the subset of Audio-Visual Depression Language Corpus.Particularly, the Audio-Visual Emotion Challenge (AVEC) is a competition event aimed at comparison of multimedia processing and machine learning methods for automatic audio, visual and audiovisual emotion analysis.For AVEC2013, there are 340 videos in German, which are recorded when participants performed human-computer interaction tasks in front of webcam and microphone.Video files include free speech, reading, singing,and picture-seeing association tasks while BDI-II is used to annotate depression severity score of participant's interview records.For AVEC2014,it is a subset of AVEC2013,consisting of 300 videos in German,where duration of each video clip is shorter than the clip in AVEC2013.
Distress Analysis Interview Corpus - Wizard of Oz(DAIC-WOZ)is a part of Distress Analysis Interview Corpus annotated by PHQ-8,employed for AVEC2016&AVEC2017.Distress Analysis Interview Corpus - Wizard of Oz adopts a virtual interviewer as it is considered that being confronted with a virtual interviewer makes subjects more willing to speak out than a real person and emotion status of an interviewer needs to be strictly controlled during the interview.Audio,video and deep sensor modalities are collected in the dataset.Besides,it also contains information of galvanic skin response(GSR),electrocardiogram(ECG),participants'respiratory data.
E-DAIC is an extended version of DAIC-WOZ which is collected from semi-clinical interviews designed to support the diagnosis of psychological distress conditions such as anxiety and depression [97].The dataset contains 163 development samples, 56 training samples and 56 test samples, and the participants' data are marked with age, gender and PHQ-8 score is labelled.This database is employed for AVEC2019[98].
The Bipolar Corpus, a new Turkish Audio-Video Bipolar Disorder Corpus, is collected by Elvan et.al used for effective computing and psychiatric research.This corpus is also employed for bipolar disorder sub-challenge of AVEC2018,which is annotated by Youth Mania Rating Scale (YMRS).Videos of the dataset are recorded under seven tasks to describe the state of bipolar disorder, such as explaining why you went to the hospital,attending an activity,describing happy and sad memories,counting to 30,describing two pictures that evoke emotions, etc.
MODMA is the first Chinese multi-modality depression database available to our knowledge, including participant's audio and EEG information from 23 patients and 29 healthy.Audio information is recorded during the tasks of an 18-question interview from the Depression Scale, read aloud and a description of emotional pictures.Table 5 shows the results of some benchmark works on the representative datasets measured by F1 score, mean absolute error (MAE) and root mean square error (RMSE).
3.2 | Dataset annotation
Depression dataset annotation is an important and difficult task, the accuracy of which has a direct impact on the followup research.A complete annotation of speech depression database is normally consisted of three parts: transcription,analysation and annotation.Transcription is to transcribe audio and linguistic information into text form; Analysation is to further mark the acoustic features such as prosodic information, speech speed, volume and tone changes on the basis of transcription; Annotation is to mark the depression score of a sentence.AVEC 2013 is annotated by BDI-II from the two dimensions of Arousal and Valence.In DAIC-WOZ, the ELAN tool is used in the transcription part, where psychological states of the interviewee as well as the content of the dialogue and non-verbal behaviours are analysed and annotated; For MODMA, all recordings were manually segmented and annotated by Statistical Manual of Mental Disorders(DSM-IV).Table 6 includes the range of score and the corresponding depression level for different questionnaires.
3.3 | Existing issues
Although SDR has made progress with existing datasets, the following issues with datasets hinder the further development.
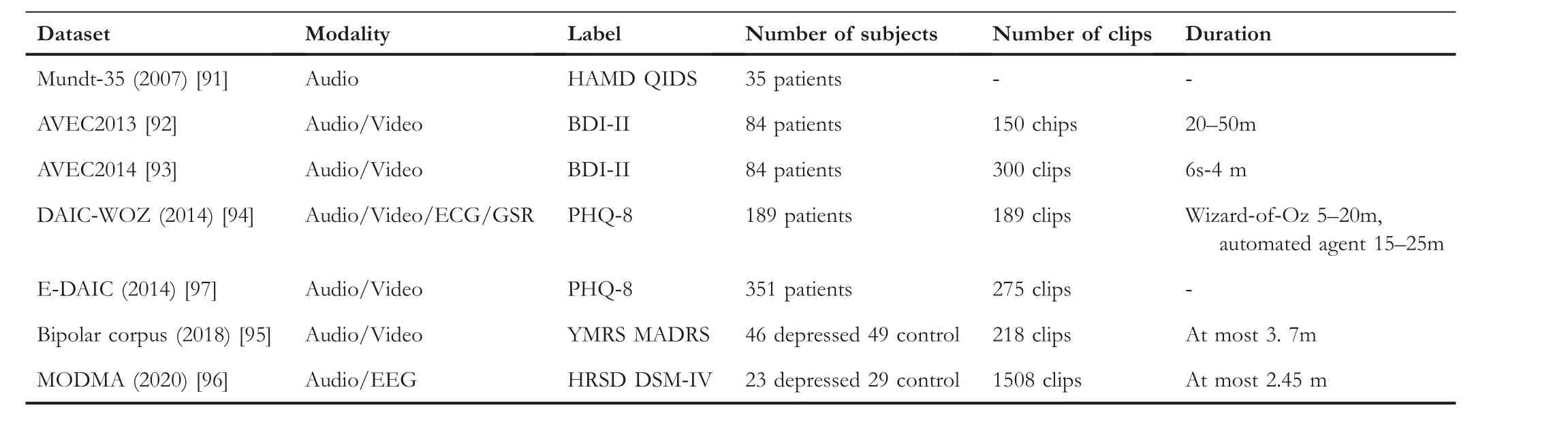
T A B L E 4 Representative datasets in speech depression recognition (SDR)
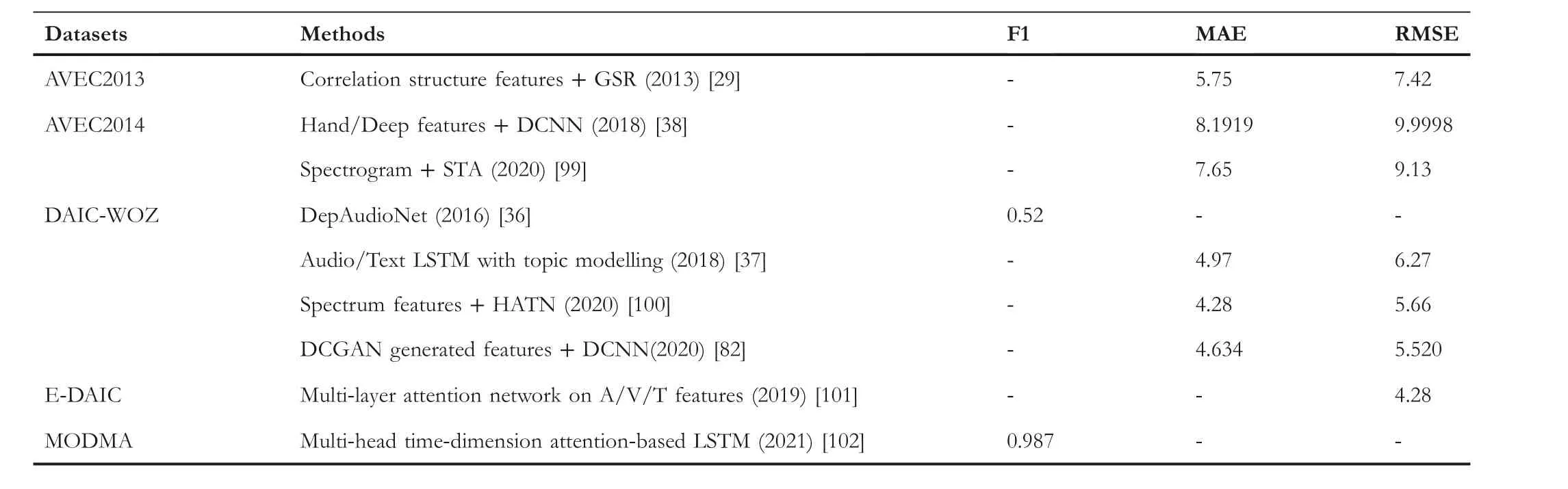
T A B L E 5 Performance of different methods on the representative datasets

T A B L E 6 Depression rating for different questionnaires
(1) Objectivity of database annotation:Data annotation is the basis of further work, however, the cognition of annotators is not completely accurate, and the distribution of depression scores will affect the performance of the constructed model.
(2) Unavailability and small in scale: Due to the sensibility of depression speech and the ethics problem, most institutions could not obtain sufficient samples.At present,public depression databases available are AVEC2013,AVEC2014, DAIC-WOZ and BD, which are far from needs of scientific research.Addressing ethical issues is important for the publication of datasets.
(3) Non- universality: Currently, datasets employed in SDR research come normally from interactive clinical interview,in which the questions are carefully designed and there is no noise interference like in real life.Therefore,these data cannot fully reflect the normal life state of patients with depression.Besides, the issue of cross language and cultural has not yet been considered.
4 | CONCLUSION AND FUTURE WORK
Depression is a common mental disorder, the effective and accurate diagnosis of which requires coordinated efforts among clinical psychology,brain science,affective computing and other fields.It is of great significance for both academic research and clinical care to develop an automatic and objective evaluation system.This paper systematically and comprehensively sorts out depression recognition based on intelligent speech signal processing.As stated in the paper,it can be found that the research of SDR has undergone a shift from exploring acoustic features to deep model research.At present, CNN and LSTM have become the most popular deep models due to their advantages in processing spatiotemporal features.In order to better apply methods of deep learning,it is increasingly important to collect large-scale unified data.Although great progress has been made in the field of SDR,there is still a long way for it to be put into practical use.To achieve a breakthrough, the following challenges must be considered and overcome.
(1) Availability and limitations of the baseline dataset: Database building is the basis of the research.However, there are some restrictions of the existing databases caused by different collection scenarios and methods, inconsistent labelling, small data scale, and non-disclosure due to privacy.It is a key to breakthroughs in depression analysis based on speech signal to create a large-scale database with open standards, accurate and consistent labelling, crosscultural and cross-language.
(2) Model generalization: Most studies are limited to a single or a few small-scale datasets, which makes the models perform poorly when faced with other datasets or data from other languages.Therefore, it is also a necessary study to improve the model generalization and robustness across corpora, cultures, languages, and under noisy environments.
(3) Unknown underlying correlation mechanism of acoustic information: The medical mechanism of depression on speech is a prerequisite for machine learning-based depression analysis research.To further improve the recognition accuracy, it is necessary to collect and extract clinical information on depression.Therefore, the following research should increase the communication and cooperation with other relevant professionals.It is a longterm and important topic to explore the underlying acoustic mechanism of speech in depression.
(4) Different types of depression:As mentioned before,there are different types of depression.For example, bipolar disorder differs from the most common MDD in terms of pathogenesis and performance.So far, little research has been done on the difference between the two through the speech signal.
(5) Multi-modality fusion mechanism: Combining multiple modalities for accurate and effective depression analysis is an inevitable trend in future research, because different modalities can effectively complement each other.However, the success of multimodal research is based on an effective and appropriate fusion mechanism.
ACKNOWLEDGEMENTS
This work is supported by the National Natural Science Foundation of China(NSFC,no.61701243,71771125)and the Major Project of Natural Science Foundation of Jiangsu Education Department (no.19KJA180002).
DATA AVAILABILITY STATEMENT
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
ORCID
Han Linhttps://orcid.org/0000-0001-5136-5059
 CAAI Transactions on Intelligence Technology2023年3期
CAAI Transactions on Intelligence Technology2023年3期
- CAAI Transactions on Intelligence Technology的其它文章
- Fault diagnosis of rolling bearings with noise signal based on modified kernel principal component analysis and DC-ResNet
- Short‐time wind speed prediction based on Legendre multi‐wavelet neural network
- Iteration dependent interval based open‐closed‐loop iterative learning control for time varying systems with vector relative degree
- Thermoelectric energy harvesting for internet of things devices using machine learning: A review
- An embedded vertical‐federated feature selection algorithm based on particle swarm optimisation
- An activated variable parameter gradient-based neural network for time-variant constrained quadratic programming and its applications