
Leveraging hierarchical semantic‐emotional memory in emotional conversation generation
2023-12-01 10:46:02MinYangZhenweiWangQianchengXuChengmingLiRuifengXu
Min Yang| Zhenwei Wang | Qiancheng Xu| Chengming Li | Ruifeng Xu
1Shenzhen Institutes of Advanced Technology,Chinese Academy of Sciences, Shenzhen, China
2School of Electrical and Computer Engineering, Georgia Institute of Technology,Atlanta,USA
3School of Intelligent Systems Engineering,Sun Yat-Sen University,Guangzhou,China
4School of Computer Science,Harbin Institute of Technology(Shenzhen),Shenzhen, China
Abstract Handling emotions in human-computer dialogues has emerged as a challenging task which requires artificial intelligence systems to generate emotional responses by jointly perceiving the emotion involved in the input posts and incorporating it into the generation of semantically coherent and emotionally reasonable responses.However, most previous works generate emotional responses solely from input posts,which do not take full advantage of the training corpus and suffer from generating generic responses.In this study, we introduce a hierarchical semantic-emotional memory module for emotional conversation generation (called HSEMEC), which can learn abstract semantic conversation patterns and emotional information from the large training corpus.The learnt semantic and emotional knowledge helps to enrich the post representation and assist the emotional conversation generation.Comprehensive experiments on a large real-world conversation corpus show that HSEMEC can outperform the strong baselines on both automatic and manual evaluation.For reproducibility, we release the code and data publicly at: https://github.com/siat-nlp/HSEMEC-code-data.
K E Y W O R D S deep learning, emotional conversation generation, semantic-emotional memory
1 | INTRODUCTION
In recent years, conversation systems have attracted considerable attention due to its board applications, ranging from entertaining chatbots to technical support services.Building a conversation system that is able to express emotion and offer informative responses is a long-standing goal of artificial intelligence.The prior work [1] found that addressing emotion in conversation systems could improve user satisfaction and contribute to a more positive perception of the human–machine interaction.Many breakdowns in human-machine conversations can be avoided by endowing machines with the capability of identifying the emotional state of a user and responding to her/him sensitively.Therefore,it is necessary to develop affectdriven conversational systems that can generate informative responses with appropriate emotions given the posts.
Earlier efforts in emotional conversation generation were mostly inspired by psychology findings, which focussed on designing a set of rules and templates to generate responses[2, 3].For example, Polzin et al.[2] explored the prosodic,verbal and spectral cues in the dialogue utterances, and designed a human-computer interface which captured the emotion within the conversation.Skowron et al.[3]developed a conversation system that could identify and capture users'affective states, and provided meaningful and affective responses based on pre-defined response candidates.Nevertheless, the above studies usually suffer from generating innovative emotional responses that are tailored to the provided posts.The generated responses rely heavily on the so called hand-crafted templates and rules.Moreover,it is labourintensive and time-consuming to define sufficient templates and rules,which creates a substantial barrier for extending the learnt emotional conversation systems to new domains.
With the availability of large-scale conversation data online,much attention has been given to full data-driven neural conversational systems.The sequence-to-sequence model is a typical dialogue generation approach [4–6], which employs a recurrent neural network (RNN) encoder to encode the conversation history as a representation, and then feeds this conversation representation into another RNN decoder to generate emotional responses word by word.The conversation systems implemented with the sequence-to-sequence techniques have overwhelmingly established state-of-the-art performances in response generation, since they are learnt in an end-to-end way and can be scale to large-scale corpora,which could generate responses with good quality and flexibility.However, these methods do not consider the emotional factor in the process of generating dialogue responses.Subsequently, several studies attempt to generate emotional responses with a pre-specified emotion category [7, 8].One representative work was proposed by Zhou et al.[7], which employed an emotional chatting machine(ECM)to model the emotion factor in dialogue generation using internal and external emotion memory.
Despite the remarkable progress of existing studies, there remain some challenges in successfully generating informative and emotional conversations.First, most previous methods generate emotional words(e.g.‘happy’and‘lonely’)based on a hand-crafted emotion lexicon explicitly.These models are prone to generating monotonous responses that usually contain highfrequency words or phrases when the same emotion category is given.These responses are usually of low informativeness and are incoherent with the post.Second, prior methods focus on generating emotional conversation by relying solely on insufficient input posts.These models would generate responses that cannot respond informatively and adequately in most cases,especially when the input posts are really short since it is challenging to comprehend the short posts deeply and provide highquality emotional responses without commonsense knowledge.As shown in Table 1, the ECM model tends to generate noncoherent responses for the given queries.
To deal with the aforementioned issues, we introduce an end-to-end hierarchical semantic-emotional memory module for emotional conversation(HSEMEC)model that leverages a hierarchical semantic-emotional memory for emotional conversation generation.HSEMEC learns abstract conversational patterns and emotional knowledge from the training corpus automatically without any manual efforts, which enriches the post representation and assists the emotional response generation.The HSEM contains a semantic memory layer and an emotional memory layer.Specifically, we first cluster postresponse pairs in the training corpus into multiple dialogue groups according to the semantics of the post representations,and the common semantic characteristics of each dialogue group can be memorised by the semantic memory.Then, we further divide each dialogue cluster learnt in the semantic memory layer into multiple classes based on the responses emotion, and the common emotional characteristics of each subgroup can be memorised by the emotional memory.Finally,the learnt abstract semantic patterns and emotional knowledge are incorporated into the decoder for generating semantically coherent and emotionally reasonable responses.
The primary contributions of this manuscript are shown as follows:
• We propose the HSEM to learn abstract conversational patterns and emotional knowledge from the large training corpus automatically without any manual efforts.The learnt knowledge can enrich the post representation and help the conversation system to generate a semantically coherent and emotionally reasonable response;
• We investigate two different strategies to incorporate the emotional information into the decoder: one way is to feed an emotion vector into the decoder at each time step, and another way is to incorporate the emotion vector into the decoder by introducing an adaptive emotion gate;
• We conduct extensive experiments to evaluate the effectiveness of the proposed HSEMEC method on a real-life conversation dataset.The experimental results demonstrate that the proposed HSEMEC method significantly outperforms the strong baseline methods in terms of various evaluation metrics.
2 | RELATED WORK
2.1 | Open‐domain conversation systems
The goal of open-domain response generation is to generate coherent, informative, and natural dialogue responses conditioned on the input dialogue history.Building a human-like conversation system is an essential but challenging task in information retrieval and natural language processing (NLP)communities.The paper proposed in ref.[9] presented a large

T A B L E 1 Example responses generated by emotional chatting machine (ECM) and our hierarchical semantic-emotional memory module for emotional conversation (HSEMEC)
Note: Emotion words are in red and informative words are in blue.number of prior methods and datasets for implementing the dialogue systems.Motivated by the significant achievements of the sequence-to-sequence models in conditional text generation, numerous works have been introduced to produce responses with the seq2seq framework [4–6].These models could be learnt and optimised in the end-to-end way and have good flexibility in generating innovative responses.The main idea of the seq2seq methods is to utilise an RNN to encode the dialogue history into a low-dimensional representation which is then passed into another RNN decoder to generate the response.Shang et al.[10] was a representative method for generating responses given short posts with the seq2seq framework.Subsequently, there have been a variety of models being leveraged to enhance the quality of dialogue systems from different perspectives, such as diversity promotion [11],prototype editing [12], and personalisation [13, 14].
Recently, there has been increasing interest in taking advantage of both the seq2seq framework and the reinforcement learning algorithms in generating human-like dialogues[14–16].Li et al.[16] proposed the policy gradient algorithm[17] to produce highly rewarded dialogues that are natural,coherent and informative.Bahdanau et al.[15] generated sequences using the actor-critic algorithm, which optimised the evaluation measures directly by training an extra critic network to produce the task-specific score of each token that the network would receive.Yang et al.[13]proposed a personalised dialogue generation method, in which a dual learning framework was employed to train the response generation and post generation tasks simultaneously.In addition,four rewards were designed to characterise high-quality responses with the policy gradient algorithm.Yang et al.[18] investigated the performances of three reinforcement learning algorithms (policy gradient, Q-learning and actor-critic), and revealed that the actor-critic algorithm achieved the best results.
The aforementioned approaches mainly worked on general dialogue generation without considering the emotion factor.Different from these models, the proposed HSEMEC incorporates the emotion into dialogue generation effectively by proposing a HSEM module.
2.2 | Emotional conversation systems
Building an affect-driven conversational system is a crucial but challenging task.Prior studies [1, 3] have shown that an empathetic conversation agent can not only improve user satisfaction but also avoid many breakdowns in humanmachine communications.
Early studies developed emotional conversational systems by applying manually defined conversation templates or rules[2, 3, 19].Polzin et al.[2] explored the prosodic, spectral and verbal cues in the conversation utterances, and designed a human-computer interface which captured the emotion states expressed in the conversation.Pelachaud et al.[20] tried to develop interactive embodied agents, which formalised and implemented the rules in the construction of conversation systems.Ochs et al.[19]proposed an empathetic dialogue agent that could express emotions based on numerous event-handling rules.Skowron et al.[3]developed a conversational system that could identify and capture the users'affective states,and provide meaningful and affective responses based on pre-defined response candidates.These methods mainly relied on welldesigned hand-crafted rules, which made it hard to generate innovative emotional sentences or scale to new domains.
Motivated by the remarkable success of the seq2seq model[21]in open-domain conversation systems[22],several studies have been introduced for the data-driven emotional conversation generation,which generates emotional sentences using the seq2seq models.Ghosh et al.[23]introduced an affect language model to produce emotional conversations with varying affect strengths.The affect category was inferred from the preceding context by using keyword spotting from an emotion lexicon.Hu et al.[24] enhanced the variational autoencoders by using a discriminative model as learning signals to guide the training of the generative model.However, these studies generated sentences continued the emotion of the preceding context.
Subsequently, Zhou et al.[7] proposed an ECM, which incorporated pre-specified emotion factor into emotional response generation with internal memory and external memory.Similar to ECM,Song et al.[25]built an interactive machine(EmoDS), which employed an emotion classifier to guide the response generation process and could express the expected emotions either explicitly or implicitly.Peng et al.[26]proposed a topic-enhanced emotional conversation system that incorporated the pre-specified emotion category and attentive topic information into the response generation given the input post.However, these methods do not consider the additional information behind the training corpus and rely heavily on extra emotion lexicon.Wei et al.[27] proposed an emotion-aware dialogue system, which leveraged a prior and a posterior network to learn better semantic and emotion information for dialogue generation.Liang et al.[28]introduced a heterogeneous graph network to exploit emotional information from foursource knowledge for emotional dialogue generation.Abdollahi et al.[29] developed a multimodal emotion sensory by combining an emotion recognition method and an emotion expression system.Liu et al.[30] presented a three-stage exploration-comforting-action framework for emotional dialogue generation.
The aforementioned approaches usually relied on emotion lexicons or emotional multi-source knowledge to incorporate the emotion factors into dialogue generation.Different from the previous methods, the proposed HSEMEC does not rely on any pre-prepared hand-crafted module.It automatically learns the dialogue patterns and emotion information from the training corpus by a HSEM module.Thus, it is possible for HSEMEC to add more conversational associated information into the generated responses.
2.3 | Text style transfer
Recently,style transfer of texts has attracted much attention in natural language generation [31], which aims at changing the style of input texts to the target style while preserving the content as much as possible.Style transfer can facilitate various NLP applications, such as sentiment modification [32] and customer care response generation[33].For example,Golchha et al.[33] attempted to automatically generate the courteous response via style transfer,given the conversation history and a generic response.Generally, there are two main challenges for text style transfer:(1)there is limited parallel training data;and(2) it is difficult to disentangle the style information from the content.
Theoretically, we can generate emotional response by transferring the response with specific emotion into the response with target emotion via style transfer techniques.However, in this way, the emotional conversation generation process would be divided into two stages: generic response generation and style (emotion) transferring.This pipeline framework for emotional conversation generation may suffer from error accumulation and need parallel data to train a highquality emotion transfer model.
3 | METHODOLOGY
3.1 | Task definition and model architecture
3.1.1 | Problem formulation
Given a post sequenceX= {x1,x2, …,xn} and an emotion categorye∈{‘Anger’, ‘Disgust’, ‘Happiness’, ‘Like’, ‘Sadness’,‘None’}, the goal of emotional conversation generation is to generate an emotional responseY= {y1,y2, …,ym} that is semantically coherent and emotionally reasonable.
3.1.2 | Architecture of our methodology
As illustrated in Figure 1, the proposed HSEMEC model follows a two-step procedure.First, we propose a HSEM module to extract and memorise abstract conversational patterns and emotional information from the large training corpus.Second, HSEMEC learns a post-response mapping conditioned on the desired emotion categoryeand an extracted emotional memory Merelated to the given post by maximisingP(Y|X,e,Me).Next,we will introduce the HSEM module and the conversation generation module in detail.
3.2 | Hierarchical semantic‐emotional memory module
The objective of the HSEM module is to extract and memorise the abstract semantic dialogue patterns and emotional knowledge from the post-response pairs in the training corpus.HSEM contains a semantic memory layer and an emotional memory layer.Specifically, we first cluster post-response pairs in the training corpus into multiple dialogue groups according to the semantics of the post representations, and the common semantic characteristics of each dialogue group can be memorised by the semantic memory.Then,we further divide each dialogue cluster learnt in the semantic memory layer into multiple classes based on the responses emotion, and the common emotional characteristics of each subgroup can be memorised by the emotional memory.We introduce a semantic-emotional framework rather than an emotional-semantic framework since we need to incorporate the fine-grained emotion value into the decoder for emotional dialogue generation.

F I G U R E 1 The architecture of hierarchical semantic-emotional memory module for emotional conversation(HSEMEC).Solid arrows show the data flow at both the training and test phase(the prediction branch in the upper left box);dashed arrows show the data flow at only the training phase(the reconstruction branch in the lower left box).The right box shows the write operation of our hierarchical semantic-emotional memory(HSEM)module.BI-GRU,bidirectional gated recurrent unit; MLP, multi-layer perceptron
Generally speaking, we propose HSEM based on two considerations of the motivation:(1)The training corpus can be divided into multiple groups according to the semantic dialogue patterns,and the common characteristics of each group can be memorised with the semantic memory.For example, the answers of ‘when’ questions should always contain time information; (2) In addition, the emotion information contained in different dialogue groups should be different, which can be learnt and memorised by the emotional memory.For example,the word‘unpredictable’could be related to the‘Like’emotion category in the conversation about the movie (e.g.‘unpredictable plot’) but belongs to the ‘Anger’ emotion when talking about automobile(e.g.‘unpredictable steering’).

3.2.1 | Semantic memory layer
The semantic memory layer is used to extract and memorise the abstract dialogue patterns at the semantic level.Inspired by ref.[34], we adopt k-means clustering to divide the training corpus into multiple groups and extract common characteristics of each group.First, we learn the representations of all post-response pairs (denoted asRep(X) andRep(Y)) in training corpus D with a bidirectional gated recurrent unit(Bi-GRU) encoder, where X and Y represent all the posts and responses in D respectively.The implementation details of Bi-GRU are explained in Section 3.3.Then, we divide the post representationsRep(X) intoKclasses using the k-means clustering algorithm, where the centre vector of theith cluster (Ci) represents the semantic key ski.Formally, each semantic key skican be calculated as follows:
The semantic value svifor the semantic key skiis a set of response representationsRep(Yi) for the posts in clusterCi.
3.2.2 | Emotional memory layer
The emotional memory layer is used to extract and memorise the abstract emotional patterns within each dialogue group(each semantic value svi) learnt in Section 3.2.1.Based on the

3.2.3 | Memory operations
Our HSEM memorises and accesses the abstract dialogue patterns and emotion information hidden in the training corpus by using two main operations: the write operation and the read operation.

Read operation
At the decoding phase,given a post representationRep(X)and a user-specified emotion categorye,we use theread operationto search the HSEM and output the best-matched emotional value Meby a two-step procedure.First, we compute the similarity betweenRep(X) and each semantic key skiin the semantic memory layer by dot-product operation and choose the dialogue cluster with the highest semantic similarity toRep(X).Second,for the extracted semantic cluster,we further search the emotional memory for the cluster whose emotional key corresponds toeand output its emotional value as Me.The process ofread operationcan be formulated as follows:
3.3 | Emotional memory for conversation generation
Our conversation generation module consists of two branches:a prediction branch and a reconstruction branch, as shown in the left part of Figure 1.At the training phase, both the prediction branch and the reconstruction branch are trained given the input posts and golden responses.At testing, only the prediction branch is used given test posts, while the reconstruction branch is not involved in the testing.
3.3.1 | Prediction branch
As demonstrated in Figure 1 (the upper left box), the prediction branch is based on the typical seq2seq framework with a Bi-GRU encoder and a GRU decoder,which is widely adopted in the end-to-end dialogue generation such as neural machine translation[21].Specifically,given a post sequenceX={x1,x2,…,xn}, thetth hidden state of the Bi-GRU encoder can be computed as follows:
The HSEM module can abstract most conversational patterns and emotional information from the training corpus.However, the emotional memory learns the emotion expressions in an implicit way,and some situations cannot be covered in the training corpus, for example, some emotional information may be missing.To alleviate the above problems, we propose two strategies (i.e.HSEMEC-V1 and HSEMEC-V2)to incorporate the emotion cue into HSEMEC explicitly and strengthen the emotional relevance between the generated responses and the given emotion categories.
HSEMEC-V1


whereWcis a weight matrix.The context vectorctis derived by applying global attention on the hidden states from the Bi-GRU encoder.The attentional hidden vectors~tis then fed through the softmax function to obtain the prediction distribution.In particular, thetth target word is sampled from the output probability distribution as follows:
whereWsindicates a weight matrix.
HSEMEC-V2
As discussed in ref.[35], simply introducing an additional emotional cue (i.e.the emotion vector) at each decoding step will lead to the problem of disturbing the emotion cue gradients, since the gradients on those emotion-irrelevant words could distort the representation learning of the emotional cue.To solve this problem, we proposed HSEMEC-V2, which introduces an adaptive emotion gategeto determine when and to what extent to incorporate the emotion cue into the GRU decoder.Formally, we modify Equation (8) into Equations (11)–(13) as follows:
whereWgis weight matrix,bgrepresents a bias term,andσ(⋅)is a sigmoid function.
3.3.2 | Reconstruction branch
We introduce the reconstruction branch to learn high-quality response representations for HSEM, inspired by Tian et al.[34].The reconstruction branch is implemented by a conditional autoencoder (CAE) that has a similar network structure(i.e.Bi-GRU encoder and GRU decoder) with the prediction branch.As demonstrated in Figure 1 (the lower left box), the goal of the reconstruction branch is to reconstruct the golden response conditioned on the golden response and post representations.Formally, given a golden response sequenceY= {y1,y2, …,ym} for postX, the encoder and decoder of CAE are formulated as follows:

T A B L E 2 Statistics of the NLPCC2013&2014 dataset and the relabelled NLPCC2017 dataset
where the superscript(r)represents variables in the reconstruction branch.
3.4 | Training objective
We combine the prediction loss and the reconstruction loss to form the overall joint training objective,which can be computed as follows:

4 | EXPERIMENTAL SETUP
4.1 | Experimental data
To verify the effectiveness of the proposed HSEMEC methods,we conduct extensive experiments on the emotional conversation generation dataset published on NLPCC20171http://tcci.ccf.org.cn/conference/2017/.There are a total of 1,119,207 post-response pairs with emotion labels in the corpus.After removing the posts or responses whose length is smaller than 3 or greater than 25,there are about 85.7%samples in the cleaned dataset.
Since the original emotion labels are noisy, we relabel the NLPCC2017 dataset with our own emotion classifier with an accuracy of 0.6452.The emotion classifier is implemented with a Bi-LSTM encoder [36].In particular, we trained the emotion classifier on NLPCC20132http://tcci.ccf.org.cn/conference/2013/and NLPCC20143http://tcci.ccf.org.cn/conference/2014/emotion classification datasets(NLPCC2013&2014 dataset for short)following Zhou et al.[7].There are eight emotion categories in the NLPCC2013&2014 dataset(i.e.‘Anger’,‘Disgust’,‘Happiness’,‘Like’, ‘Sadness’, ‘None’).The infrequent emotion categories(‘Fear’and‘Surprise’)are quite noisy and are removed.We apply a well-trained Bi-LSTM emotion classifier to relabel the NLPCC2017 dataset with six emotion categories.Finally, the relabelled NLPCC2017 dataset is randomly partitioned into training, validation,and test sets with a ratio of 0.98:0.01:0.01.The detailed statistics of the NLPCC2013&2014 dataset and the relabelled NLPCC2017 dataset are shown in Table 2.
4.2 | Baseline methods
In the experiments, we compare our model with several representative baseline methods:
• Seq2Seq is a general sequence-to-sequence model with the attention mechanism [21];
• Seq2Seq-emb is the seq2seq that incorporates an additional emotion vector into the decoder;
• ECM is the ECM that incorporates emotion factor into dialogue generation with emotion and external memory networks [7];
• EmoDS-EV is the emotional dialogue system(EmoDS)that incorporates an external emotion lexicon into conversation generation in an explicit or implicit manner [25].
4.3 | Implementation details
Both the encoder BiGRU and the decoder GRU have 600 hidden cells, but they apply different parameters.The word embeddings are initialised with pre-trained Chinese word embeddings provided by Li et al.[37], and we set the size of the word embedding to be 300.The vocabulary size is limited to 20,000 and the out-of-vocabulary (OOV) tokens are replaced with a special token‘UNK’.We set the hidden size of encoder as 620.The size of the emotion vector is set to 100.The max length of the input sequence is set to 30, and the exceeded tokens are padded.The parameters of the prediction branch and the reconstruction branch are initialised separately and not shared.
The proposed HSEMEC method is implemented with PyTorch, and we apply the stochastic gradient descent [38] algorithm to optimise the HSEMEC method.We set the minibatch size to be 128.The initial learning rate is set to 0.1 and the weight decay is set to 0.000001.The number of training epochs is set to 20.We set the gradient clipping to be 5.In order to produce diverse dialogue responses, we employ the beam search with the size of 10 and force the first word of each candidate sequence to be different.The emotional memory sizeKis 300 and the hyperparameterλis 0.1.We adopt dropout to alleviate overfitting and set the dropout rate to 0.2.
4.4 | Evaluation metrics
We conduct extensive experiments on a large-scale read-life dialogue corpus to verify the effectiveness of the proposed HSEMEC model by performing both automatic evaluation and human evaluation.
4.4.1 | Automatic evaluation metrics
BLEUSimilar to the evaluation metrics proposed by Zhou et al.[7],we use the bilingual evaluation understudy (BLEU) metric to automatically verify the dialogue systems at the semantic-level,which estimates whether the generated responses are relevant to the ground-truth responses.In particular, BLEU measures the n-gram string matching scores between the ground-truth dialogue responses and the generated dialogue responses.In this paper, we report the BLEU score withn= 4, similar to previous work [7].Specifically, we calculate the BLEU score(n= 4) for the generated dialogue response ^Yas:

whereYand ^Yrepresent the ground-truth and generated dialogue responses.In addition,P(Y, ^Y) denotes the 4-g precision for the generated dialogue response ^Yas:
whereY~denotes the set of candidate 4-gη(Y~,Y) represents the number of 4-g in the responseY.
Distinct metrics
Following the work in ref.[39],we estimate the diversity of the obtained dialogue responses by counting the numbers of distinct unigrams and bigrams in the produced dialogue responses.We divide the distinct numbers by the total numbers of unigrams and bigrams,and denote the ratios as‘Dist-1’and‘Dist-2’ respectively.These two distinct metrics ‘Dist-1’ and‘Dist-2’are indicators of word-level diversity for the generated dialogue responses.
Perplexity

whereMrepresents the total number of words in the test set.p(Yi) represents the probability of generating the responseYiby the model.Prepresents the average log probability under the model.The lower perplexity indicates better generation performances of dialogue systems.
Emotion accuracy
We design anemotion accuracy(denoted asEmo-Acc) metric to evaluate the emotional appropriateness of the produced dialogue responses automatically.In particular,we compute theEmo-Accmetric as the agreement between the user-specified emotion category and the predicted ones by the Bi-LSTM sentiment classifier.
4.4.2 | Human evaluation metrics
We employ human annotation to evaluate the emotional conversation generation systems from the semantics and emotion perspectives.From a semantic perspective, we use two evaluation metrics(i.e.FluencyandLogic)to estimate the quality of the produced dialogue responses.Specifically, we employ theFluencyscore to estimate whether the produced response is fluent and grammatical.TheLogicmetric is designed to estimate whether the response logically matches to the corresponding post.From an emotion perspective,we use theEmotionscore to measure whether the emotion expressed in the obtained dialogue response is apparently appropriate to the given post.
We choose 200 posts from the testing set and invite three human annotators to score the produced responses based on theirFluency,Logic,andEmotion.The annotators are asked to assign each response a score of 0 (bad), 1 (not bad), 2 (satisfactory) for each of the human evaluation metrics.The final human evaluation scores are then averaged for each factor.
5 | EXPERIMENTAL RESULTS
5.1 | Automatic evaluation results
We summarise the automatic evaluation results in Table 3.We conduct statistical significance tests (t-test) to investigate whether the main results of our model are statistically significant or not.Values with‘*’indicate that the improvement from HSEMEC is statistically significant compared to the best performing baseline method (p< 0.05).We can observe that HSEMEC significantly and consistently outperforms the competitors by a noticeable margin on all automatic metrics.This indicates that the proposed HSEMEC methods can generate more diverse, fluent, and informative responses with the correct emotion category by extracting, memorising, and utilising various emotional response patterns from the training corpus.HSEMEC-V1 performs better than HSEMEC-V2 in terms of BLEU, diversity, and perplexity, while HSEMEC-V2 performs better on emotion accuracy.This verifies that employing the emotion adaptive gate improves emotion accuracy but meanwhile reduces the dialogue quality from dialogue content (fluency and informativeness) perspectives.
5.2 | Human evaluation results
We summarise the overall human evaluation scores in Table 3(in the right).We observe that HSEMEC achieves the highest overall scores on all manual metrics.Specifically, HSEMEC yields a significant performance improvement over the best baselines (e.g.ECM and EmoDS-EV), indicating that the HSEM mechanism succeeds in learning the abstract dialogue patterns and emotional knowledge from the training corpus.In addition,we observe similar trends as in automatic evaluation.HSEMEC-V1 achieves better performance than HSEMEC-V2 in terms of content quality (Fluency and Logic perspectives),but performs worse than HSEMEC-V2 in terms of emotion accuracy.
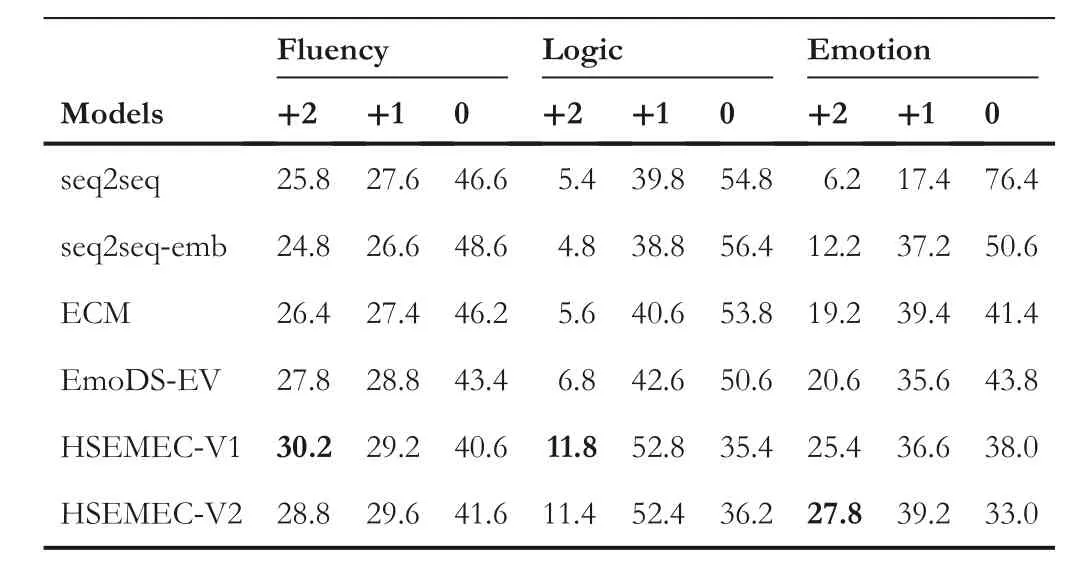
In Table 4,we also report the score distribution of human evaluation in terms of fluency, logic and emotion.From the results we can observe that HSEMEC can get much more‘+2’scores and less‘0’scores than the compared methods,showing the ability of HSEMEC to generate semantically coherent and emotionally reasonable responses.
5.3 | Results of ablation study
To analyse the effect of each component of HSEMEC,we also perform ablation tests of HSEMEC in terms of discarding the emotional memory layer in HSEM (denoted as w/o EM) and the reconstruction branch (denoted as w/o recons).The ablation test results are summarised in Table 5.We can observe that the emotion accuracy of both HSEMEC-V1 and HSEMEC-V2 drops sharply when removing EM on both automatic and manual evaluations, while w/o EM achieves comparable results with HSEMEC-V1/V2 on the content relevant metrics.This is because the emotional memory can capture the emotional knowledge contained in the training corpus without sacrificing the content quality.On the contrary,the reconstruction branch contributes great improvement to dialogue content, while it has a limited impact on emotion accuracy.This is within our expectation since the reconstruction branch is leveraged to make the response embedding dependent on the post embedding without considering the emotion factor explicitly.
5.4 | Case study
To measure the proposed HSEMEC method qualitatively, we randomly select four posts from the test set and report thegenerated responses by HSEMEC and ECM in Tables 6 and 7.The first two cases are positive responses that contain not only the appropriate emotion but also the coherent content with respect to the given posts.For example,HSEMEC successfully learns the relationship between ‘Dangdang’ and ‘Taobao’,which are popular e-commerce platforms in China.In addition, HSEMEC can generate a natural response contained the‘Like’ emotion.

T A B L E 3 Overall experimental results for all methods in terms of both automatic and human metrics
T A B L E 4 The score distribution of human evaluation in terms of fluency, logic and emotion
5.5 | Error analysis
In general, our HSEMEC model achieves more superior performance than the baseline methods.However, there are still some bad cases by checking the human evaluation data(whose average semantic score is smaller than 1 or emotionfitness score is 0).To examine the limitations of the HSEMEC model, we carry out an analysis of the errors made by HSEMEC.We manually examine the post-response pairs from the human evaluation data, which have low overall evaluation scores by the HSEMEC model.The error analysis results reveal two major reasons for obtaining low human evaluation scores.

T A B L E 5 Ablation test results in terms of automatic and human evaluations on NLPCC2017 dataset

T A B L E 6 Responses generated by hierarchical semantic-emotional memory module for emotional conversation (HSEMEC) and emotional chatting machine (ECM).The informative words are in blue and the emotion words are in red

T A B L E 7 Two bad cases generated by hierarchical semantic-emotional memory module for emotional conversation (HSEMEC)
5.5.1 | Incoherent responses
First,some responses produced by HSEMEC are not coherent to the corresponding posts.For example,as shown in the first case in Table 7, the response ‘black silk stockings’ cannot respond to the post ‘black frame glasses’.This situation is because that HSEMEC has not exactly captured the phrase matching relationships and only considers the word ‘black’ in the post.One possible solution is to employ a regularisation to encourage HSEMEC to consider intact post topics and emotion information to generate both coherent and emotional responses.In addition, dialogue pre-training techniques [40,41] may help the dialogue systems learn better dialogue patterns.
5.5.2 | Lack of informativeness
HSEMEC struggles to understand the commonsense knowledge involved in the posts, and thus fails to generate factual and informative content in some cases,as shown in the second case in Table 7.This is because the learnt emotional memory may contain some frequent uninformative responses with‘Sadness’ emotion.One possible solution is to incorporate commonsense knowledge from an external commonsense knowledge base into emotional conversation generation since people are prone to knowing and using the external commonsense knowledge during a conversation.This might contribute to building highly applicable and versatile dialogue systems.
6 | CONCLUSION AND FUTURE WORK
The goal of this paper is to learn abstract conversational patterns and emotional knowledge from the training corpus without any manual efforts.Specifically, we first cluster postresponse pairs in the training corpus into multiple dialogue groups according to the semantics of the post representations, and the common semantic characteristics of each dialogue group can be memorised by the semantic memory.Then, we further divide each dialogue cluster learnt in the semantic memory layer into multiple classes based on the responses emotion, and the common emotional characteristics of each subgroup can be memorised by the emotional memory.Finally, the learnt abstract semantic patterns and emotional knowledge are incorporated into the decoder for generating semantically coherent and emotionally reasonable responses.The experimental results in terms of automatic evaluation and human evaluation showed that HSEMEC was able to generate better responses from content and emotion perspectives than the compared methods.
In the future, we would like to design more powerful semantic and emotional memory networks,which could support deep reasoning.In addition, we also plan to incorporate external commonsense knowledge into the emotional dialogue generation, which is expected to improve the informativeness and coherence of the generated dialogues.Moreover, we will explore Transformer and dialogue pre-training techniques to further enhance the performance of emotional conversation systems.
ACKNOWLEDGEMENTS
This work was partially supported by the National Natural Science Foundation of China (No.61906185, 61876053), the Natural Science Foundation of Guangdong Province of China(No.2019A1515011705 and No.2021A1515011905), the Youth Innovation Promotion Association of CAS China (No.2020357), the Shenzhen Basic Research Foundation (No.JCYJ20210324115614039 and No.JCYJ20200109113441941),and the Shenzhen Science and Technology Innovation Program (Grant No.KQTD20190929172835662).
CONFLICT OF INTEREST
The authors declared that they have no conflicts of interest to this work.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available from the corresponding author upon reasonable request.
ORCID
Min Yanghttps://orcid.org/0000-0001-7345-5071
Qiancheng Xuhttps://orcid.org/0000-0002-0542-4510
 CAAI Transactions on Intelligence Technology2023年3期
CAAI Transactions on Intelligence Technology2023年3期
- CAAI Transactions on Intelligence Technology的其它文章
- Fault diagnosis of rolling bearings with noise signal based on modified kernel principal component analysis and DC-ResNet
- Forecasting patient demand at urgent care clinics using explainable machine learning
- A federated learning scheme meets dynamic differential privacy
- SRAFE: Siamese Regression Aesthetic Fusion Evaluation for Chinese Calligraphic Copy
- Wafer map defect patterns classification based on a lightweight network and data augmentation
- Kernel extreme learning machine‐based general solution to forward kinematics of parallel robots