
基于项目流行度的个性化重排序模型
2023-12-01 03:44郑馨怡张宇山
软件导刊 2023年11期
郑馨怡,张宇山
(广东财经大学 统计与数学学院,广东 广州 510320)
0 引言
随着智能手机等电子产品的普及,网络用户基数每年不断扩大,在互联网上为用户推荐符合用户偏好项目的推荐系统不在少数。推荐系统通过分析用户的历史数据,为用户推荐可能符合用户个人喜好的项目。有研究指出,推荐多样性和用户满意度之间有着显著的相关性,推荐列表的多样性对用户感知有着积极且重要的影响[1]。由此,一个优秀的推荐系统应该不仅关注推荐结果的准确性,还应该提供多样的推荐选择,以满足用户的个性化需求并提升用户体验。
推荐多样性可以体现在个体多样性和整体多样性两个方面。个体多样性从单个用户的角度衡量推荐的多样性,个体多样性高意味着系统给用户推荐一些彼此相似度很低但是符合用户偏好的项目。整体多样性则是从整个推荐系统角度衡量推荐的多样性,整体多样性高意味着所有用户的推荐结果集合中会覆盖更多不同的项目。有研究显示,由于模型或者是数据的原因,导致推荐系统会放大项目流行度偏差,表现为推荐系统会将流行度高的项目优先推荐给用户[2]。整体多样性偏低,就意味着推荐系统总是给用户推荐更为流行的项目,而忽略长尾项目。当用户的TOP-K 推荐列表里都占据着流行度高的项目时,用户之间的推荐列表就会越来越相似,通过推荐反馈循环导致用户行为同质化,该循环会进一步被更多的循环放大。同质化既发生在种群水平上(所有用户的行为更相似),也发生在个体水平上(每个用户的行为更像它最近的邻居)[3]。这种同质化不仅容易造成用户的审美疲劳、浏览体验感下降,而且还会导致模型泛化能力下降,推荐结果变得越来越不可靠。因此,推荐列表中总覆盖率高并不意味着用户个人推荐列表的多样性也很丰富[4]。
为了改善个性化推荐效果,本文受到Abdollahpouri等[5]研究的启发,从项目的流行度切入,提出一种重排序模型(Personalized Re-ranking,PR),目标在于提升用户TOP-K推荐列表多样性,并向用户推荐更多的新颖性项目。该模型在基线推荐模型的基础上,将项目按流行度降序排列,然后在用户的候选项目集中引入项目流行度和用户偏好组成的补偿分数部分对项目重新排序,并通过调节补偿分数的大小以控制用户最终TOP-K推荐列表新颖项目的比例,达到提高用户个性化推荐列表多样性的效果。本文主要工作包括:①提出一种重排序模型PR:该模型旨在改善个性化推荐系统的效果,提升用户的TOP-K推荐列表的多样性,并向用户推荐更多的新颖项目;②从项目流行度切入:PR 模型根据项目流行度进行重排序,通过降序排列项目流行度,提高低流行度项目被推荐的机会;③改进用户推荐列表的多样性:PR 模型通过调节补偿分数以控制用户最终TOP-K推荐列表中新颖项目的比例;④评估推荐结果的整体多样性和个体多样性,探讨在提高用户个性化多样性的同时,对推荐系统整体多样性的影响程度。
1 相关工作
推荐的多样性可能对用户产生长期影响。例如,在音乐项目的曝光量已经被证明有能力减少用户对未知或者不熟悉文化的刻板印象和偏见的前提下,Porcaro 等[6]使用纵向实验得出结论:暴露于特定水平的音乐推荐多样性可能会对听众的听歌偏好产生长期影响,并且推荐多样性对于用户探究新颖项目的好奇心也会有一定影响。
在整体多样性研究方面,胡春华等[7]考虑用户的实时性和多样性需求,提出能够有效挖掘用户潜在兴趣的实时多样性推荐算法。有研究指出[8-10],提升整体多样性也被称为长尾推荐,其目标是通过增加长尾项目的推荐比例,提供更广泛的选择和个性化的推荐体验,以满足用户的多样性需求。然而,这些推荐方法都是优先考虑整个推荐系统的多样性,而忽略了评估用户的个性化列表多样性。为了提供更好的用户体验,推荐系统需要在追求整体多样性的同时,确保个性化列表中的推荐项目能够尽可能地满足用户的个性化需求和多样性偏好[11]。
在个体多样性研究方面,Ziegler 等[12]使用最大边际相关性(Maximal Marginal Relevance,MMR)重排序模型以优化推荐结果,认为用户满意度优先于推荐准确度,推荐准确度虽然是一个模型的重要度量标准,但是它们无法捕捉到用户的满意度特征。Adomavicius 等[13]提出将初始推荐列表与混合重排结果相结合的方法,该方法中的混合重排步骤将项目按照流行度从最低到最高进行排序,即推荐给用户不那么受欢迎的项目,并且将预测评分从最低到最高对项目进行反向预测评分排序,即推荐给用户非高度相关的预测项目。Ashkan 等[14]提出一种推荐列表多样化方法(Diversity-Weighted Utility Maximization,DUM),该方法利用贪婪策略平衡准确性和多样性,使得模型可以最大化项目效用。Liu 等[15]等提出一种公平感知的重排序算法(Fairness-Aware Re-Ranking,FAR)以平衡排名质量和供应商的公平性,使得来自不同供应商的商品有公平的机会被推荐。Pei 等[16]提出一个个性化的重新排序模型,通过直接使用现有的排序特征向量优化整个推荐列表。Gao等[17]将MMR 模型进行改进,通过在推荐过程中注入随机性和多样性以推广用户的兴趣,并避免过度个性化。上述研究在多样性评估和用户满意度等方面提供了不同的解决方案,但还未从项目流行度的角度切入去研究问题,本文提出的模型不仅能够满足用户的个性化需求,还能够兼顾项目的流行度。这种综合考虑可以帮助推荐系统平衡个性化推荐和流行度推荐之间的权衡,既不会过于偏向热门项目,也不会忽视用户的兴趣和偏好。
2 个性化重排序模型构建
2.1 符号说明
假设在一个推荐任务中,用户集合为U={u1,u2,…,uN},|U| 为用户集合大小;项目集合为I={i1,i2,…,iM},|I|为项目集合大小;populɑrity(i)为项目点击数。
通过基线模型得到的用户u的初始推荐列表为Ru,用户u对项目i的初始预测分数为Ru,i,Ru,i∈Ru;经过重排以后用户的推荐列表为R*u,用户对项目的预测分数为。
2.2 Binary xQuAD 模型
本文将简单介绍Abdollahpouri 等[8]提出的重排序模型。Binary xQuAD 模型不依赖于项目特征,只依赖于项目流行度。补偿分数部分是根据每个用户对长尾项目的历史兴趣以确定其大小。具体模型为:
其中,λ∈[0,1),为超参数,用来调节最终列表的多样性补偿分数大小。H表示热门项目集合,L表示长尾项目集合,S是最终排序列表。p(d|u)是用户历史评分项目中属于类别d的比率,用于衡量不同用户对头部或者长尾项目的偏好。p(i|d)为指示函数:
在使用Binary xQuAD 模型时,用户偏好被进一步放大,推荐的项目都是满足用户兴趣的头部和长尾项目。这时,推荐的整体多样性增加,但是用户个人的推荐列表中都是相似类型的项目,意味着新颖性的增加可能没有意义。例如,电子商务平台的推荐任务总是会避免向一个用户推荐与用户已经购买过的项目属于同类型的项目。再例如,用户在视频网站上观看了《复仇者联盟》这部电影,进而网站推荐给用户同样受欢迎的《复仇者联盟2》《复仇者联盟3》等一系列同类电影。从推荐结果看,推荐准确度相对高,覆盖项目也多,但是用户不一定满意这些推荐,即推荐列表中总覆盖率高并不意味着用户个人推荐列表的多样性也很丰富[13]。相反,推荐给用户符合其偏好,但流行度相对较低的电影可能会激发用户好奇心,提升用户的潜在点击率。
2.3 Personalized Re-ranking 模型
根据上述Binary xQuAD 模型,本文同样针对项目流行度提出一种新的个性化重排序(Personalized Re-ranking,PR)模型,旨在保证推荐精度的同时,降低用户列表内的项目相似度。
首先将项目按照流行度进行划分。如图1 所示,将项目按照点击数降序排列,并进一步划分为热门项目(Head item)、长尾项目(Longtail item)和冷启动项目(Cold-start item)。由于冷启动项目与用户的交互记录太少,模型的预测分数不能很好地代表用户的潜在偏好,这些冷启动项目更应该使用基于内容和混合的推荐技术[5],于是模型只针对热门和长尾项目进行优化。
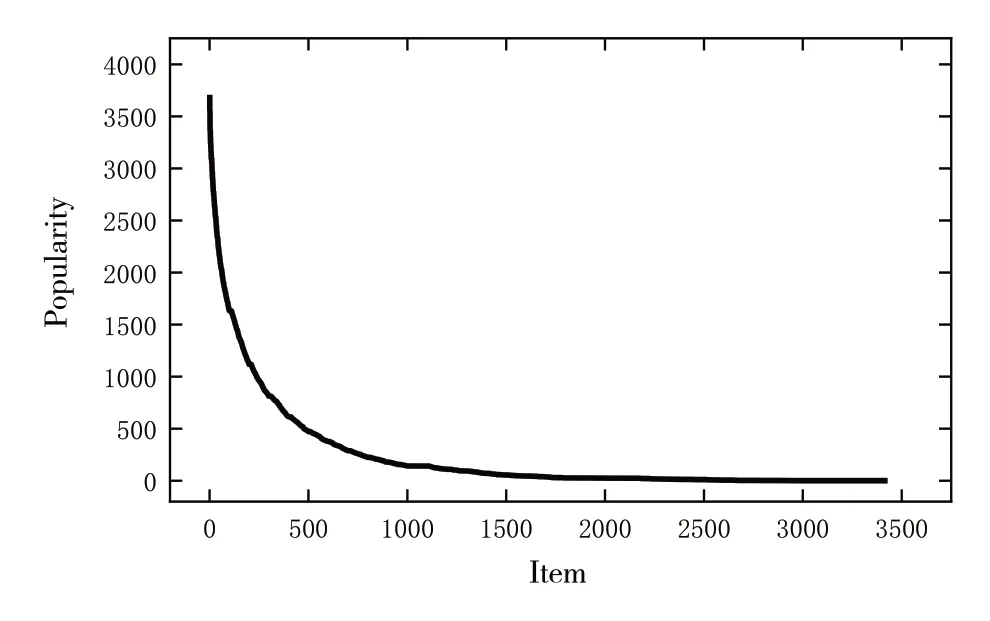
Fig.1 Item popularity distribution图1 项目流行度分布
接着,PR 模型将按以下标准对项目初始得分进行重新排序:
其中,p(i|u)为基线模型预测用户u对项目i的偏好分数,代表了推荐准确度,也代表用户的潜在偏好。式(3)的后半部分代表多样性补偿。λ∈[0,1),为超参数,用来调节最终列表的多样性补偿分数大小。参照Abdollahpouri等[8]的方法,p(i|d)同为指示函数。
对于流行度相差较大的项目,例如第一个头部项目和最后一个长尾项目,两者的也会变得相差很大。为了缩小他们之间的流行度差距,将项目的放大:
其中,ɑ满足以下条件:。
PR 模型的补偿分数部分不仅考虑用户偏好,还更多地考虑项目流行度。根据式(4),可以在每一次推荐中将不同的长尾项目同时推荐给不同的用户,从而增加推荐的新颖性,给予用户发掘新颖项目的机会。使得PR 模型能够更全面地考虑用户个性化需求和项目流行度,提供多样化的推荐结果。
2.4 实现步骤
输入:用户u;项目集合I;项目流行度集合populɑrity(I);类别d;推荐列表长度K。
输出:目标用户u的TOP-K推荐列表。
Step1:根据式(4)计算项目i的,i∈I。
Step2:使用基线模型预测用户u在项目集合I中所有未评分项目的评分值,未评分项目的集合记为,评分值集合记为按照Ru降序排列。
Step4:根据式(3)计算项目i更新后的预测评分,并按照评分值降序排列,取TOP-K个项目作为用户u的最终推荐结果R*u。
3 实验与结果分析
3.1 数据集分析
本实验选择的第一个数据集是Movielens-1M 数据集[18],这是一个电影数据集。此数据集中包含用户个人基础信息、电影基础信息以及用户对电影的评分数据。数据集包含6 040 个用户、3 952 部电影、1 000 209 条评分数据,数据稠密度为4.47%。将评分数据中从未被用户评分过的项目剔除,还剩下3 706 个项目。首先将数据集中评分次数小于20 次的项目划分为冷启动项目,其次按照帕累托原理,将占据剩余评分总数80%的项目划分为热门项目,剩下的项目归类为长尾项目[5]。按照上述划分方式,可以得到612 个热门项目,评分次数均大于506;2 432 个长尾项目;931 个冷启动项目。本实验选择的第二个数据集是FilmTrust 数据集[19],此数据集包含用户对电影的评分数据和用户之间的社交信息。在评分数据中,共有1 508 个用户,2 071 个项目,35 497 条评分数据,数据稠密度为1.14%。将此数据集与Movielens-1M 数据集进行同样的划分,得到36 个热门项目,评分次数均大于448;50 个长尾项目;1 985个冷启动项目。
对数据进行8∶2 划分,其中80%作为训练集,20%作为测试集。实验使用5 折交叉验证,选择ItemCF 作为基线模型,将本文提出的方法与MMR 进行比较。在MMR 中,候选项目集的大小为100,PR 和MMR 的最终的TOP-K列表长度为10。
3.2 评估指标
实验采用归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)、列表内多样性(Intra-List Similarity,ILS)、推荐新颖度(Novelty)、整体多样性(Aggregate Diversity,Agg_Div)4个指标对结果进行评估。
3.2.1 NDCG
该指标常用于评估推荐系统的TOP-K排序质量[17],其值越大表示推荐结果越好。NDCG 来自一个排序列表内所有项目的相关分数。CG 表示对列表TOP-K项目的相关性得分总和,计算公式为:
其中,rel(i)表示为项目i的相关性得分。
在此基础上,若进一步考虑项目所处的排序位置,让排名靠前的项目增益更高,排名靠后的项目得分进行折损,得到DCG:
下一步,考虑理想化的项目排序位置得分信息时,即按照rel(i)进行降序排序的最好列表位置得分,可以得到IDCG:
其中,|REL|表示理想化的项目排序得分信息,即当结果按相关性降序排序时,取TOP-K个结果所组成的集合。
最后,NDCG 是将其归一化处理,使得可以比较不同列表上的排名质量。
3.2.2 ILS
该指标反映单个用户推荐列表的多样性程度[12,20-21]。列表内的多样性反映了单个用户推荐列表的整体多样性程度,当推荐列表中项目的类别越多样化时,ILS 的值越小,即ILS的值越低,个体多样性越好。ILS的计算公式为:
其中,i和j是用户u推荐列表R*u中的项目。
3.2.3 Novelty
该指标可以被分为基于流行度和基于距离两种[22]。本实验使用基于流行度(Popularity-Based Item Novelty)的计算方式,当Novelty 的值越低,说明新颖度越高,即列表中出现了越多用户从未浏览过的项目。Novelty 的计算公式如下:
其中,由于物品的流行度呈长尾分布,因而取对数使得平均值更稳定。
3.2.4 Agg_Div
该指标用于衡量所有用户的推荐列表中唯一推荐项的比例[8,12],其值越高,说明整体多样性越好。Agg_Div 的计算公式为:
3.3 结果与分析
首先,观察Movielens-1M 数据集和FilmTrust 数据集在不同λ取值下的NDCG 变化,实验结果如图2所示。

Fig.2 Experimental results of NDCG indicators图2 NDCG指标实验结果
根据不同的λ取值所得的推荐结果,在Movielens-1M 数据集中,PR 模型推荐质量在λ=0.6 之后快速下降,MMR 模型的推荐质量在λ=0.2 之后开始下降。为了确保推荐质量的下降程度在可接受范围内,同时提高推荐结果多样性和新颖性,PR 模型选择λ=0.6、MMR 模型选择λ=0.2 进行下一步实验。同理,FilmTrust 数据集中PR模型选择λ=0.7、MMR 模型选择λ=0.7 进行下一步实验。实验结果见表1。

Table 1 Experimental results表1 实验结果
表1 的实验结果中,**表示其结果没有通过显著性检验,关于随机性与基线算法的差异不具有统计学意义(Wilcoxon p < 0.05)。表中评价指标旁的向上箭头表示较大的值更好,向下箭头表示较小的值更好。
在推荐系统中,提升个体多样性可能会牺牲整体多样性。原因在于,为了提供多样的推荐结果,系统可能倾向于推荐一些流行度高的项目,而忽视了个体的特定兴趣和偏好。本文提出的PR 模型目标在于提升个体多样性,而其在Movielens-1M 数据集结果显示,增加25.24%个体多样性的同时会损坏1.85%的整体多样性;在FilmTrust 数据集上的结果显示,增加13.70%个体多样性的同时会损坏1.70%的整体多样性。以上结果表明,在损失少量整体多样性的情况下,可以大幅度提高用户推荐列表的个体多样性,在列表中增加很多不同类型的项目,降低推荐列表中的项目与用户历史浏览项目的相似程度。
在Movielens-1M 数据集中,PR 模型在NDCG 指标下降3.10%的情况下,ILS 和Novelty 指标分别降低了37.85%和1.08%,而MMR 模型的ILS 和Novelty 指标不降反增,个性化推荐效果没有得到改善。同理,PR 模型在FilmTrust 数据集中,在NDCG 指标下降17.20%的情况下,ILS 和Novelty 指标分别降低13.70%和1.77%,两个多样性度量指标下降幅度均比MMR 模型大,在指标结果上具备明显优势。说明本文提出的PR 模型能够有效提高个体多样性和推荐新颖性,在改善用户个性化推荐列表的同时保持一定的推荐质量,并有效降低推荐列表的流行度,改善热门项目反复推荐给不同的用户而导致推荐效果不显著的问题。即想要增加推荐的个体多样性和新颖性,PR 模型的表现均比MMR 模型好。
综上分析,本文提出的PR 模型对推荐结果的NDCG影响在可接受范围内时,能够提高推荐结果的个体多样性。因此,PR 模型可以运用于推荐同质化的情况,有利于提升用户个性化列表内的多样性,提升推荐效果。
4 结语
本文针对推荐系统的个性化多样性问题,提出引入项目流行度,通过调节补偿分数的大小控制用户最终TOP-K推荐列表中新颖项目比例的重排序模型,并在公开数据集上通过实验验证了模型的有效性。在未来工作中,可以进一步完善该模型的理论验证,并在更广泛的数据集和场景中进行应用和推广,不断提升个性化推荐系统的效用,并持续优化用户体验。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
小学生学习指导(中年级)(2021年4期)2021-04-27
科普童话·学霸日记(2020年1期)2020-05-08
知识经济·中国直销(2018年11期)2018-11-26
幽默大师(2018年5期)2018-10-27
小哥白尼(野生动物)(2018年2期)2018-05-25
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
