
基于机器学习算法的森林火灾风险评估研究
2023-11-30 16:51:54李史欣张福全林海峰
南京林业大学学报(自然科学版) 2023年5期
李史欣,张福全,林海峰
(南京林业大学信息科学技术学院,江苏 南京 210037)
研究森林火灾驱动因素,建立火灾预测模型,生成火灾风险图对林火防护具有重要意义[1]。森林火灾的驱动因素包括气候、植被燃料、地形等自然驱动因素和人为驱动因素。
气候因素与可燃物的含水量有直接关系[2],当气温较低时,可燃物的水分蒸发较慢,不易着火。归一化植被指数在一定程度上反映了地表植被等可燃物的分布情况。地形因素包括海拔、坡向、坡度等[3]。坡度陡缓影响着火灾强度,是分析火灾强弱的重要因素,坡度越陡,降水流失越严重,可燃物易干燥,植被易燃性更高[4]。 海拔高低和坡向差异导致可燃物温湿度、植被的干燥程度都有差异[5]。地形湿度指数在一定程度上量化了地形径流流向和蓄积的影响[6],许多火灾发生于地形湿度比较低的条件下[7],地表可燃物的含水率低,更易助长火灾的燃烧。
火灾发生很大程度上与道路和居民点相关[8]。道路修建和居民不经意间丢掷的烟头都有可能作为火源引起森林火灾。与无人居住和无道路地区相比,道路和靠近人类居住的区域发生火灾的概率会更高。
机器学习在林火预测方面具有较好的性能[9]。周振伟等[10]采用层次分析法(analytic hierarchy process,AHP)和地理信息系统(geographic information system,GIS)方法,通过获得森林火险因子确定权重引入AHP,达到森林火险预测的目标;许志卿等[11]利用支持向量回归机的方式进行森林火险预测;崔亮等[12]利用呼伦贝尔草原火灾的相关数据,建立了逻辑回归模型来预测草原空间上的火险情况。逻辑回归根据林火发生的驱动因素和历史火灾数据,预测林火发生的风险[13]。逻辑回归模型具有实现速度快、输出结果简单的优点,在林火预测方面具有较好的适用性[14],但它在处理非线性和复杂关系的时候容易受限。而随机森林模型是一种灵活评估变量之间复杂关系的非参数型方法[15],可以自行选择更为重要的变量。不同决策树之间没有关联,输入数据样本时,每棵决策树对输入数据判断分类,输出对应的分类结果,依据分类结果的众数决定随机森林结果,在具有多种变量的林火预测方面具有适用性[16]。
安徽省滁州市韭山拥有着许多珍贵的动植物资源,近年来,林火发生有逐渐增加的趋势,更新和优化消防管理方法显得尤为重要。然而,韭山目前依然依靠传统的巡护方式进行林火防护,并没有对应的火灾风险图,如果能结合火灾风险图进行防火资源分配和重点区域监测,则会显著降低人力防护成本,提高林火监测能力。本研究通过提取韭山林火的驱动因素,建立逻辑回归和随机森林模型,进行相关性分析,利用混淆矩阵和接受者操作特性曲线(ROC)进行准确性评估,绘制韭山林火风险图,帮助消防管理员制定林火防护策略,提升防火能力。
1 材料与方法
1.1 研究区概况
韭山位于安徽省滁州市境内,地处凤阳县南部山区(117°19′~117°48′E,32°37′~32°46′N),地貌以丘陵为主,地势相对平缓,占地面积达249.12 km2。韭山所属北亚热带季风气候,地处冷暖气团交汇区,年均气温14.9 ℃,年均降水量876 mm。在季风盛行时期,最热月平均气温高于22 ℃,最冷月气温为0~5 ℃。韭山地处南北植物区系过渡地带,林分结构以壳斗科的落叶阔叶树和松科的常绿针叶树为主[17],著名的旅游景点韭山国家森林公园坐落其中,每年的11月到翌年4月属于韭山的防火期。
1.2 研究方法与数据处理
通常林火建模基于“假设历史火灾法”[18-19],通过对数据的初始化分析,选择影响火灾发生位置的相关因素。本研究将林火的相关因素数据作为模型的输入数据,使用ROC曲线和混淆矩阵统计指标对模型结果进行评估分析,结合两种模型预测火险结果绘制火灾风险图,火灾风险预测流程如图1所示。

图1 火灾风险预测Fig. 1 Fire risk prediction
林火相关数据可分为自变量数据和因变量数据[20],自变量数据包括地形、人类活动、植被和气象因素,因变量数据包括火点数据。本研究采用的是2019年3月地理空间数据云90 m分辨率数字高程模型(DEM)数据和2019年3月的30 m分辨率Landsat8OLI的数据,研究数据如表1所示。

表1 模型自变量
1.3 模型自变量计算
1)坡度
在ArcGis10.2中,采用公式(1)计算研究区域的坡度。
(1)
式中:s为坡度;dz/dx为中心像元水平方向上的变化率,dz/dy为中心像元垂直方向上的变化率[21]。依据式(1)得到坡度,将其分为5类[22],如图2a所示。

图2 林火相关因素分类Fig. 2 Classifications of forest fire related factors
2)坡向
南坡光照时间长,植被比较干燥,含水率低,容易发生火灾;其次是西坡[23];北坡受到太阳辐射能量少,植被含水率大,发生火灾可能性小。因此,南坡和西坡更容易发生火灾。通常坡向分为9类[24],如图2b所示。
3)海拔
海拔和火灾有着密切关系。地势越高,地表植被含水率越高,相对湿度增大,不易燃烧。提取DEM数据,将海拔分为图2c所示的5类[25]。
4)地形湿度指数
地形湿度是DEM数据的水文分析。考虑地形和土壤特性对土壤水分的分布作用,首先填满研究区域内的凹陷地形,然后计算水流方向和水量,基于上述数据依据公式(2)[26]计算地形湿度指数。将研究区域地形湿度指数分为图2d中5类[24]。
(2)
式中:ITW为地形湿度指数;S为单位等高线上地表水流经的面积,m2,可以通过汇流累积量的面积与流向宽度计算得到;β代表了地形的坡度。
5)到道路的距离
相对无道路区域,林区道路边缘发生火灾的可能性相对较高。下载并提取道路路网,利用ArcGis10.2软件的空间分析工具,根据到道路的距离,将研究区域内到道路的距离划分为图2e所示的5类[27]。
6)到居民点的距离
和无人居住区域相比,靠近居民点区域发生火灾的可能性相对较高。如图2f所示,根据居民点经纬度进行标注,将研究区域到居民点距离划分为5类[27]。
7)归一化植被指数
归一化植被指数是监测植被生态环境的有效指标[28]。通过NDVI归一化来消除结果差距过大而导致的波动,其范围为-1~1。提取Landsat8 OLI图像中近红外波段和红光波段,在ENVI5.3里依据公式(3)[29]得到归一化植被指数,通常NDVI植被指数分为5类[27],如图2g所示。
INDV=(RNI-R)/(RNI+R)。
(3)
式中:INDV表示归一化植被指数;RNI表示近红外波段,R表示红外波段。
8)温度
采用大气校正法的温度反演方式获得研究区域内的2019年3月春季的日均气温[29]。温度反演流程:
①辐射定标。
②基于NDVI计算植被覆盖度(vegetation cover,式中记为Vc);
(4)
式中:INDV,Soil为土壤的植被指数;INDV,Veg为植被覆盖像元最大值的NDVI。
③基于黑体辐射亮度计算地表温度。
T=1 321.08/ln(774.89/b1+1)-273。
(5)
式中:T表示地表温度;b1为计算出的黑体辐射亮度值。最终将温度分为以下5类[25],如图2h所示。
1.4 模型因变量计算
由于缺乏实际的火灾记录数据,所以选择提取火点作为历史火灾数据对火灾风险图进行验证。从哥白尼数据中心(https://scihub.copernicus.eu/)下载时间分辨率为10 d、空间分辨率为60 m的哨兵2号数据,通过波段运算提取2018—2020年火点共396个。为了匹配其他数据的空间分辨率,使用欧州航天局(European Space Agency)的SNAP软件作为预处理工具,将下载的数据重采样为30 m×30 m的栅格,提取近红外波段(NIR,式中记为RNI)和短波红外波段(SWIR,式中记为RSWI),最后使用公式(6)的归一化火烧指数法(NBR,式中记为INBR)进行波段运算[30]。
(6)
利用过火区光谱反射率在SWIR上升和在NIR下降的特征,有效分离过火区与其他地物。本研究采用哨兵数据的时间分辨率是10 d,当火灾发生时,被燃烧的区域在一定时间内其状态不会改变,所以使用哨兵2号数据,并不会对提取火点的数据产生较大影响。
1.5 模型建立
1.5.1 逻辑回归模型
逻辑回归(LR)算法用来描述自变量X和因变量Y之间的关系,对因变量Y进行预测。本研究通过分析各类驱动变量与火点发生概率之间的相关性,进而预测韭山内各个栅格发生火灾的概率。模型使用算法条件概率分布的形式来表示G(Y|X);随机变量X,表示影响火点发生火灾概率的驱动变量;因变量Y,表示火灾发生的概率。当预测概率≥50%时,Y值为1;当预测概率<50%时,Y值为0。
逻辑回归算法计算式为:
(7)
(8)
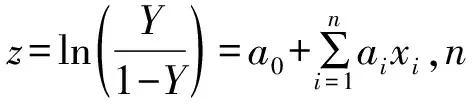
1.5.2 随机森林模型
随机森林(RF)算法基于多个决策树分类器实现,结果取决于决策树分类结果的众数[13]。当森林火点发生概率≥50%时,编码标注为1,认为是着火点;当森林火点发生概率<50%时,编码标注为0,认为是非着火点。着火点和非着火点是二元分类,火点编码表示因变量。
为后续结论对比分析,对数据进行统一性划分,训练样本占数据集的70%,验证样本占数据集的30%。模型将原始数据集随机分为训练样本和验证样本进行拟合。最后,提取森林火灾相关因子的值,计算变量重要性。
1.6 性能评价指标
混淆矩阵和接受者操作特征曲线(ROC)作为特定的指标来衡量模型的好坏,是两种广泛用于精度评估的方式[31]。
1.6.1 混淆矩阵
混淆矩阵是一种总结分类模型预测结果,展示分类学习算法的性能矩阵。一般针对二分类的问题,依据真阳性(TP)、真阴性(TN)、假阳性(FP)、假阴性(FN)4个基础指标得到混淆矩阵。
基于混淆矩阵,延伸出5个统计指标评估:总体准确率、灵敏度、特异性、阳性和阴性预测值[32]。
1.6.2 ROC曲线
接受者操作特征曲线(ROC)是反映灵敏性和特异性连续变量的综合指标[31]。曲线下方面积(AUC)是评估分类器分类精度的常用参数,AUC值越大,表明模型准确性越高。在ROC曲线上,越接近坐标图左上方,灵敏度和特异性越高。
2 结果与分析
2.1 森林火灾驱动因素相关性
8种森林火灾影响变量在森林火灾敏感性预测中所显示的预测能力见表2。由表2可知,6种影响变量的P<0.001,相关性极显著,2种影响变量的P<0.05,相关性显著,所以在本次分析中无须排除任何因素,变量均为相关因素。相关性程度最高的是到道路的距离,其次是NDVI,相关程度较差的是地形湿度和坡向。

表2 森林火灾驱动因素相关性
2.2 混淆矩阵精度评价结果
两种模型混淆矩阵精度评价结果见表3,结果显示逻辑回归模型的准确率为71.07%,随机森林模型的准确率为84.91%。

表3 RF和LR模型的混淆矩阵精度评估结果
由表3可知,在逻辑回归模型中,验证数据的阳性预测值,即该模型正确地对森林火点分类的概率为65.22%;阴性预测值,即该模型正确分类非火点的概率为79.10%。
在随机森林模型中,该模型正确对森林火点分类的概率为82.05%;该模型正确分类非火点的概率为87.65%。
2.3 ROC评估结果
使用ROC曲线和AUC面积检测逻辑回归模型和随机森林模型的全局性能。在逻辑回归模型下,AUC为0.717 2,表明该模型与训练数据集有略高的拟合优度,模型的预测能力为71.07%;在随机森林模型下,AUC为0.850 1,表明该模型与训练数据集有较高的拟合优度,模型的预测能力为84.91%。两种模型的ROC曲线如图3所示。当AUC指标大于0.5,指标越接近1,表明模型拟合效果好。因此随机森林模型的预测准确性高于逻辑回归模型。

图3 逻辑回归(LR)和随机森林(RF)模型的ROC曲线Fig. 3 ROC curves for LR and RF models
2.4 模型火险预测结果
根据逻辑回归模型和随机森林模型,生成韭山的火灾风险图。将火险分为5个等级:极低(0,0.2]、较低(0.2,0.4]、中等(0.4,0.6]、较高(0.6,0.8]、极高(0.8,1.0][33]。
提取出的火点如图4所示,从图4中可以发现,火点主要集中在区域的西部和南部区域,该区域的路网密集,人类行为可能造成火灾。

图4 研究区火点提取结果Fig.4 Extract the fire point of the study area
本研究的LR和RF生成的火灾风险预测图见图5,逻辑回归模型预测下的高和极高等级火险,占总体的20.27%;随机森林模型预测下,占总体的11.91%(29.36 km2)。逻辑回归的火险预测图上,其高风险等级点的个数远远多于随机森林模型。通过对比发现,相比于LR,RF的分类更加精准,逻辑回归预测准确率不高导致的低火险等级点被划分为高等级火险。

图5 逻辑回归及随机森林模型火险预测结果Fig.5 Logistic regression and random forest model fire risk prediction results
植被因素是造成火灾的重要因素之一。火灾风险等级高、极高区域在植被覆盖度高的地区更易发生火灾。从图2g可以看到,植被覆盖度较高区域占比超过了50%,所以韭山地区的火灾风险较高。
人类行为活动是林火发生的重要原因之一。进奉的香火、靠近道路边行人无意间丢弃未熄灭的烟头等都可能会引起意外的森林大火,所以靠近马路和居民点的林区都会增加森林火灾发生的风险。在本研究中,简单划分了森林到道路和居民点的距离,图2e将森林到道路的距离划分为了5个等级,越靠近道路的行人和人类行为活动越多,越容易造成森林火灾。依据韭山区域内的实际道路情况,选择400 m作为划分道路距离的间隔,大多数人类活动范围不会超过道路距离1 600 m,可见道路距离的划分是合理的。图2f到居民点小于500 m的范围大多是人类活动密集区域,距离大于3 500 m的大多是人类活动较少、火灾风险并不高的区域。
基于相同的8个驱动变量的基础之上进行预测时,随机森林模型的预测准确度高于逻辑回归模型的预测准确度。随机森林的整体准确度为84.91%,逻辑回归的准确度为71.07%。因此,随机森林模型的预测准确性高于逻辑回归模型的预测,其性能也更好。
2.5 火险分区与火灾防控
选择使用哨兵2号数据提取火点数据,并利用该数据进行模型验证,验证得到LR和RF模型的准确度分别为71.07%和84.91%。从图5可以看出,区域的西部和南部地区在LR和RF模型下都被划分为火灾中高风险地区,这部分区域也对应图4中的火点区域;结合图2e中的到道路距离可以发现,该部分区域路网密集,说明该区域人类活动频繁,并且到道路距离要素在模型中的相关性最高,因此针对这部分高风险地区的防控主要是预防人为因素,可以在道路沿途部署摄像头进行监测,并在道路和森林之间设置防火带,以防止道路车辆事故、乱扔烟头等造成的森林火灾。区域的中部被划分为低风险区域,这部分区域有部分道路和人类居住点,这主要是为了方便旅客参观各个景点,虽然这部分区域的风险较低,但是依然不能够忽视,因为这部分区域覆盖了大范围的森林,并且有大量的古迹、保护物种等,一旦发生火灾,将会以极快的速度蔓延,大面积的火灾会造成大量的资源损失,所以这部分区域仍然需要保护。可以在各个景点设置消防栓等防火设备,并可以考虑建设消防局,这样可以在火灾发生时以最短的时间内到达火灾现场并灭火,同时禁止燃香、祭扫等活动,以防止火灾的发生。
3 结 论
1) 逻辑回归和随机森林两种模型同时表明,影响火灾预测准确性因素中,植被因素为主要驱动因素。在所有分析的地形因素中,到道路的距离和到居民点的距离对火灾发生的影响最大,人类在道路和居民点周边活动的足迹很大程度上影响着火灾的发生,是火灾发生的潜在因素。其他因素中,气候因素是火灾发生的重要因素。
2) 对逻辑回归和随机森林模型进行评估显示,ROC曲线的AUC值越大,表明模型有更好的预测能力。5个统计指标结果并不完全相似,随机森林模型ROC曲线结果要优于逻辑回归模型。
3) 随机森林模型在预测森林火灾风险等级上,准确率高于逻辑回归模型。因此,随机森林模型更适用于韭山地区的火灾预测。
当前韭山内的林火主要依靠人力巡察和瞭望塔监测,巡察路径往往依据经验,瞭望塔监测范围受限,防护方式落后,根据火灾风险图来进行人员巡察,结合生成的火灾风险图来观察和部署瞭望塔。针对森林高风险和极高区域,相对合理地布防林区并分配防火资源,在易发生火灾区域设置防火隔离带,加强火灾监控力度;在森林中低风险地区设置检查站、巡逻队,可能是一种林火防护的有效方法。在发生火灾前采取预防措施,将自然资源和群众生命财产损失降到最低。火灾风险图有望在未来的森林火灾监测中发挥越来越重要的作用。
猜你喜欢
江苏安全生产(2022年11期)2023-01-11 06:29:40
农业灾害研究(2022年2期)2022-05-31 23:30:07
山西林业(2021年2期)2021-07-21 07:29:28
红外技术(2021年1期)2021-01-29 01:41:54
中国新闻周刊(2020年6期)2020-03-08 14:20:46
家庭科学·新健康(2019年10期)2019-11-18 08:28:38
鹿鸣(2018年1期)2018-01-30 12:05:42
中国环境监察(2016年7期)2016-10-23 05:36:26
当代工人(2015年13期)2015-08-25 22:53:26
河北遥感(2015年3期)2015-07-18 11:12:29
