
基于Adaboost 与卷积神经网络的人脸定位研究*
2023-11-30 11:30王文智罗安飞廖清静
科技与创新 2023年22期
王文智,罗安飞,廖清静
(贵州警察学院,贵州贵阳 550000)
人脸定位是动态人脸识别过程中的一项关键技术,能够定位视频图像序列中是否存在人脸、人脸位置及其在图像中人脸的大小。目前,人脸定位的方法比较多,大致可以分为基于知识的方法、基于学习的方法。
基于知识的方法有:①文献[1-2]采用YCgCr 色彩空间的人脸肤色模型,对图像进行肤色分割,利用人脸的几何特征筛选出人脸区域;②文献[3]提出了一种彩色图像序列中的人脸定位和跟踪的方法;③文献[4]从不同视角下统计若干关键人脸特征点位置;④文献[5-6]通过Haar 滤波分解面部特征的轮廓,实时进行人脸关键点定位。
基于学习的方法有:①文献[7-10]通过编码人脸特征,自适应定点优化Adaboost 算法特征匹配进行有效的定位;②文献[11-12]通过Adaboost 算法提取人脸和非人脸的特征,利用支持向量机和CNN 来定位人脸;③文献[13-17]借助卷积神经网络(CNN)的强大特征学习能力,提出利用级联卷积神经网络(MTCNN)实现快速人脸检测和人脸对齐。
这些方法在人脸定位上取得了较好的效果,但是仍然有一些类人脸区域被定位为人脸区域,而且在定位人脸过程中每次都是对整幅图像的全部像素进行搜索和定位,在空间上会消耗大量的处理时间,因此,本文提出了Adaboost 与卷积神经网络相结合的人脸定位方法。
1 Adaboost 与CNN 相结合的人脸定位方法
1.1 CNN 算法概述
CNN 是一种多层感知器,网络包括3 层,即输入层、特征层、输出层,特征层中含卷积层和采样层。
卷积层是特征提取层,是用上一层的图像和一个参数模板的加权和,再经过一个偏置参数及激活函数后得到的一张特征图,卷积表达式如下:
采样层是为了减少网络的拓扑结构,采样层中有采样函数down(·)、权值参数β及偏置b,采样层的表达式如下:
1.2 CNN 算法人脸训练
1.2.1 传统CNN 结构
通常用于人脸检测的传统字符CNN 结构如图1 所示,输入层为32×32 的图像,经过5×5 卷积核卷积得到C1 层的特征图像,C1 层的图像大小为28×28;S2层是采样层,用2×2 的块采样得到14×14 特征图;C3层是卷积层,由16 个5×5 的卷积核卷积所得,C3 层的特征图大小为10×10;S4 是对C3 层特征图像进行采样得到,其大小为5×5;C5 层由120 个5×5 的卷积核卷积S4 层的特征图,得到1×1 的特征图120 个,并把C5 层的这120 个1×1 的特征作为全连接层的输入;F6 是含有84 个节点的隐含层;输出层为10 个节点。
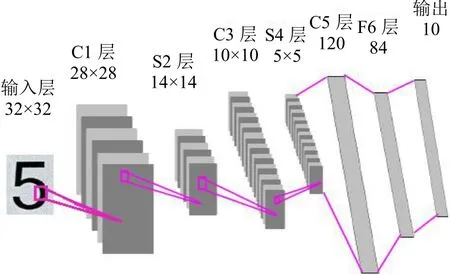
图1 CNN 结构
1.2.2 人脸与非人脸图像的存储形式
CNN 是二维图像识别的网络,其输入层为二维的图像数据,具体数据如下:假设有人脸和非人脸各为n1与n2张灰度图像,图像尺寸归一化为m×n,则人脸与非人脸图像的存储形式可以表示为如图2 所示的形式。
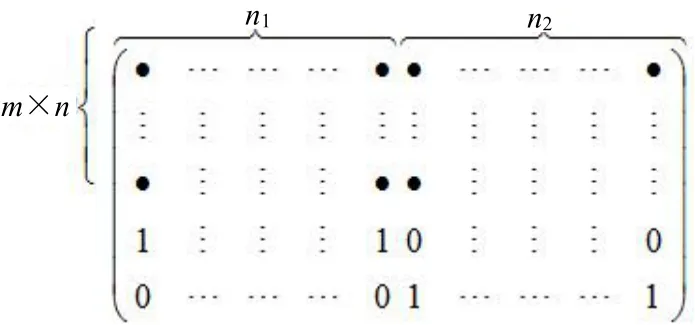
图2 图像的存储形式
图2中人脸与非人脸数据的矩阵大小为(m×n+2)×(n1+n2),上面的数据矩阵中的每一列表示一张图像的数据及类别,每一列的前m×n个数据就是用一张图像的每一行首尾相连接组成的,每一列的后2 个数据代表图像的类别,比如人脸图像的后两个数据是用1 和0来表示,非人脸图像则用0 和1 表示。
1.2.3 权重初始化
卷积层是通过对人脸图像进行卷积后得到的特征图像,每一个卷积有一个卷积核和一个偏置参数,初始化卷积核公式如下:
式中:kerl,i为第l层网络的第i个特征图的卷积核矩阵;rand(5)为任意生成大小为5×5 的随机矩阵;fan_in为上一层(l-1)特征图与卷积核kerl,i的连接个数,即fan_in=inmapsl×25,inmapsl=outmapsl-1;fan_out为这一层l的特征图与卷积核kerl,i的连接个数,即fan_out=outmapsl×25,inmapsl、outmapsl分别为第l层的输入特征图与输出特征图。
对于第l层网络的第i个特征图bl,i设置为0。采样层中的参数只有块采样权值参数βl,i及一个偏置bl,i,一般情况下,采样层中选取2×2 的图像块进行均值采样、最大值采样、像素点概率采样。采样层的目的是保持图像中旋转、平稳、伸缩等的不变性,如均值采样的参数,初始化偏置b仍设置为0。
在全连接层中,第l层的权值矩阵初始化公式如下:
式中:t_outl为生成大小为inmapsl×outmapsl的(0~1)任意值的随机矩阵。
1.2.4 前向传播计算误差
假设CNN 有L层,网络中第l层为卷积层或者采样层时设第l层的特征图数目为outmapsl张,在网络中若第l层为全连接层的节点个数设outmapsl,则网络进行前向传播时,按如下代码进行操作:

1.2.5 反向传播修改权重
由前向传播可计算出网络的误差,所以利用传统BP 算法的反向方法修改各参数,则网络进行反向传播按如下代码进行操作:


即,权重更新如下:

1.3 建立高斯混合模型背景,提取运动目标
混合高斯模型是一种图像背景建模方法,其利用时间序列对每一点像素建立背景,故在t时刻图像中某点i的像素值I(i,t)的混合高斯模型定义如下:
式中:I(i,t)为i点t时刻的像素值;K为高斯个数,一般为3~5,本文取4;ω(i,t,k)为i位置t时刻的第k个高斯分布的权重,且有为第k个高斯分布的均值;δ(i,t,k)为第k个高斯分布的方差。
建立好背景后就可以进行运动目标检测了,假设t时刻i点的像素值为I(i,t),则二值化的运动目标区域D(i,t)表示为:
式中:T1为根据场景设置的一个经验值(本文T1=30)。
1.4 运用Adaboost 与CNN 在运动目标区域内定位人脸
Adaboost 是一种将多个弱分类器级联在一起形成强分类器来定位特定目标的算法,表达式如下:
式中:T为弱分类器的个数;αt为第t个弱分类器在强分类器中所占权重的数值;ht(x)为样本x的第t个弱分类器。
当使用级联分类器进行人脸定位时,由于运动目标区域的背景与目标本身都可能存在类似人脸的情况,所以用Adaboost 算法定位人脸时,可能定位到虚假的人脸,因此,还需要再次判别人脸区域。再次定位人脸区域就是将Adaboost 算法定位到的人脸再一次输入到1.2.1 节训练好的CNN 网络中,判别是否为人脸,若CNN 网络判别的图像为人脸时,则一定为人脸,否则所定位到的图像就不是人脸。
2 实验结果与分析
为了验证本文所提的方法,对视频序列图像进行分类实验,实验结果如图3 所示。

图3 本文人脸定位过程
图3是在不同场景下所进行的人脸定位结果图,第一、第二行为幼儿园小女孩的人脸定位过程,第三、第四行为幼儿园小男孩的人脸定位过程,第五、第六行为中年男子的人脸定位过程,第七、第八行为中年女性的人脸定位过程。
图3中第一列为人脸定位系统中用来定位人脸的当前帧图像,第二列为运用混合高斯模型所建立的背景与当前帧图像做差后得到的二值化运动目标区域,第三列为在运动目标区域使用Adaboost 算法进行人脸粗定位,第四列为利用粗定位的人脸区域图像再次进行精确判断得出的精定位人脸区。
由图3 可以看出,虽然第二列二值化目标出现了空洞现象,但是也不影响Adaboost 算法与CNN 算法在目标图像区域中对人脸定位的准确度。从第三列Adaboost 算法定位的人脸可以知道,Adaboost 算法定位的人脸不够准确,容易产生多框和虚框的现象。然而再次经过卷积神经网络的细定位人脸第四列中,则可以消除Adaboost 算法所产生的不足,蓝色框表示CNN 判别为非人脸区域,红色框为人脸区域。从图3的结果可以看出,Adaboost 算法不能解决虚假人脸时,使用本文的方法则可以排除虚假人脸检测。
3 结论
本文首先利用高斯背景提取运动目标区域,然后再通过Adaboost 算法粗定位人脸,最后再使用训练好的CNN 网络对粗定位人脸区域进一步精定位;方法中通过高斯背景提取目标区域,大大减小了Adaboost 算法对全图搜索粗定位人脸的时间。此外,再利用CNN网络进一步定位人脸区域,克服了Adaboost 算法在定位时多框及虚框等不足的现象。实验结果表明,本文的方法可以定位到准确的人脸区域,对后续的人脸识别等工作具有一定的指导意义。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
