
机构内网信息优化配置
2023-11-29 11:26福建师范大学林馨
数字技术与应用 2023年11期
福建师范大学 林馨
随着科技的发展和互联网的普及,各种组织机构的内部人员常需要从互联网获得工作、学习等相关信息。通常可以通过直接访问外部网络或将常用数据存储到本地服务器以获取信息,两种方式都会产生一定的费用。本文将综合两种获取信息的方式,从节约成本的角度,给出优化策略。
1 问题
随着现代科技的发展,网络上的资讯也丰富多样,互联网成为我们学习工作生活中不可分割的部分。各种组织机构,如学校、医院、企业等日常都需要从网络获取各类信息,以提高工作效率,提升产品或服务的质量等。
从网上获取信息会产生网络通信费。若机构将一些经常需要访问的数据块下载存储到本地服务器,就可以节省部分由于访问外网所产生的通信费用。同时我们注意到,购买以及维护本地服务器也需要一定的费用,因此我们要在二者之间找到平衡点,设计出既经济又合理的方案。
假设已知每个本地服务器的存储容量、购买价格以及维护费用,机构所要获取的数据块并以日常访问频次确定每个数据块的重要性权重,以及从网络获取每个数据块所需通信费用。如图1 所示给出了内网配置方案所需考虑的因素。

图1 内网配置方案需考虑的因素Fig.1 Factors for Intranet configuration scheme
引用[1]中已探讨了当数据块不可分割且服务器中存储单位数据量的成本相同时,购买服务器以及数据块的存储方案。本文将考查数据块可分割存储且服务器中存储不同数据块单位数据量的成本不同时,需要购买的服务器数量,选择存储哪些数据块以及如何将数据块存储在服务器上,从而给出使机构能获取所需信息,同时又能节约成本的方案。
2 求解
设总共有m个数据块,其中第i个数据块的数据量为Qi,从外网获得第i个数据块时产生的通信费用为Bi,则第i个数据块单位数据量的通信费是Fi=Bi/Qi.设每个服务器的存储容量为W,价格是V,则服务器单位容量的价格为P=V/W。由于不同数据块访问频次不同,服务器存储第i个数据块单位数据量的维护费为Si,因此服务器存储第i个数据块单位数据量的成本Ci=P+Si.
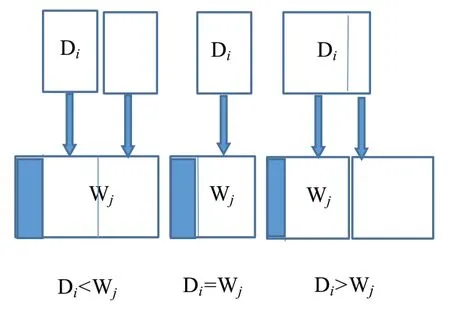
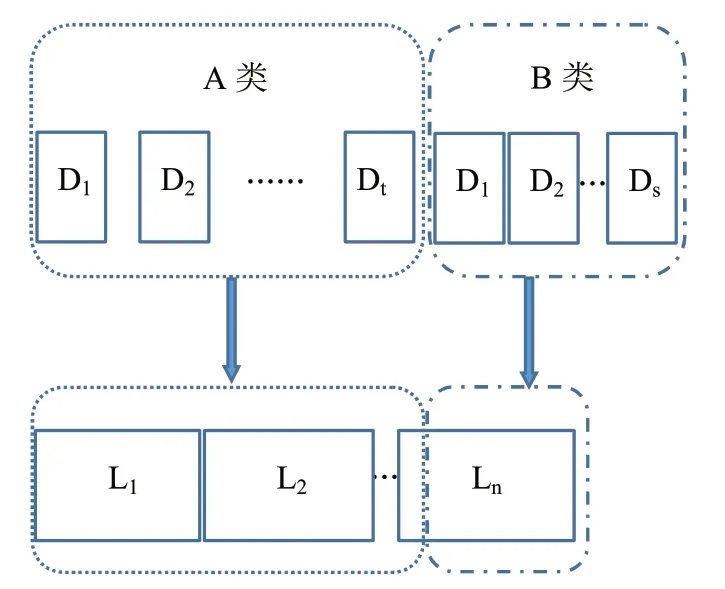
求解思路:对第i个数据块的单位数据量而言,若访问外网产生的通信费大于服务器存储成本,即Fi>Ci时,则将第i个数据块存储到服务器;将满足以上条件的所有数据块归为A 类并全部存储在服务器中,从而确定需购买的服务器数量;若存储了所有A 类数据块后,服务器有剩余容量,则对剩余的满足0.95Ci 我们先将数据块归为A 类以及B 类[1]。假设A 类共有t个数据块,B 类共有k个数据块。完成数据块分类之后,我们利用贪心算法将数据块存储到服务器。 贪心算法[2]是通过一系列的选择来得到一个问题的解。它所作的每一个选择都是当前状态下某种意义的最好选择,即贪心选择,并希望通过每次所作的贪心选择导致最终结果是问题的一个最优解。 所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。贪心算法所作的贪心选择可以依赖于以往所做过的选择,但绝不依赖于将来所作的选择,也不依赖于子问题的解。因此贪心算法是自顶向下,以迭代的方式做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题。 一个典型的贪心算法如Kruskal 算法求简单无向图的最小生成树:首先把所有顶点看作孤立点作为初始图,将所有的边权按从小到大排序,每次选出权值最小的边,若加入该边不产生回路,就将其加到图中,直到得到最小生成树,如图2 所示。 图2 Kruskal 算法求图(a)的最小生成树(f)Fig.2 Kruskal algorithm for MST (f) of graph (a) 将数据块存入服务器的基本步骤:(1)将A 类数据块存到服务器。首先,将A 类数据块按Fi-Ci的值降序排列;之后,按顺序将数据块存入服务器:若当前数据块数据量不超过当前服务器剩余容量,则直接存储;若当前数据块数据量超过当前服务器剩余容量,则将此数据块分割,一部分填满当前服务器,另一部分存入下一个服务器;重复这个过程,直到将A 类数据块全部存储直服务器,这时统计所需服务器数量以及服务器剩余容量。(2)将部分B 类数据块存储到服务器。首先,将B 类数据块按Ci-Fi升序排列;之后按顺序将数据块存入服务器:若当前数据块数据量不超过当前服务器剩余容量,则直接存储;若当前数据块数据量超过当前服务器剩余容量,则将此数据块分割,一部分填满当前服务器。至此,所有A 类数据块和部分B 类数据块已存入服务器。 算法1:将A 类数据块存储到服务器。 Step1. 将A 类数据块按Fi-Ci的值降序排序[3],得D1,D2,...Dt,i=j=1,Wj=W; step2. 若i>t,则转step4;否则,转step3; step3. 若Di step4.n=j,停止。 我们由算法1 知,共需要n个服务器,在存储了A类数据块中总共t个数据块之后,服务器Ln的剩余容量为Wn,如图3 所示。 图3 A 类数据块存入服务器的三种情形Fig.3 Threeways type A data stores at servers 虽然B 类数据块的单位数据量所产生的通信费小于服务器单位容量的存储成本,但若是存储完A 类数据块,服务器仍有剩余空间,我们将部分B 类数据块存入可充分利用服务器的存储空间。 算法2:将B 类数据块存储到服务器的剩余空间。 Step1. 将B 类数据块按Ci-Fi的值升序排序[3],得D1,D2,...Dk,i=1; step2. 若Wn=0,则停止;否则,转step3; step3. 若Di Step4. 若i>k,s=i-1,停止;否则,转step3。 由算法1、算法2 知,服务器总共存储了A 类共t个数据块,以及B 类共s个数据块,且服务器无法再存储B 类中剩余数据块,如图4 所示。至此,服务器存储了A 类中所有数据块以及B 类中部分数据块,其余需要数据都通过访问外网获得,产生通信费用。 图4 数据块存入服务器的总体方案Fig.4 Overall scheme for data storage at servers 本文通过优化算法给出了将哪些数据块存储到本地服务器以及存储的方案,从而使得组织机构能在较低的成本下,为其内部成员提供所需的数据信息。由于从网络上获取信息存在风险,而计算机系统是通过多个防御层来防止遭受恶意活动的攻击,包括政策(安全审核、个人使用限制、培训等)和技术(防火墙、反病毒、入侵检测系统、漏洞扫描、数据冗余等)在内的防御措施,将会对机构的风险类型产生各种影响。因此,在本文的基础上,还可进一步探讨机构网络安全策略,即在尽量减少成本的前提下选择适当的防御措施。
3 结语
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16东北师大学报(自然科学版)(2021年1期)2021-03-27电脑爱好者(2020年19期)2020-10-20电子制作(2019年13期)2020-01-14铁道通信信号(2019年9期)2019-11-25网络安全和信息化(2017年10期)2017-03-08知识产权(2016年8期)2016-12-01网络空间安全(2016年3期)2016-06-15风能(2015年8期)2015-02-27风能(2015年5期)2015-02-27
