
基于DeformMobileViT 的城市地下管道异常样本判别*
2023-11-29 11:26吴培德李波姚为李鑫程立
数字技术与应用 2023年11期
吴培德 李波,2 姚为,2 李鑫 程立,2
1.中南民族大学计算机科学学院;2.国家民委信息物理融合智能计算重点实验室
城市地下管道是城市的重要基础设施,对地下管道的定期检测是一项重要工作,关系到城市的正常运行。文章针对目前地下管道缺陷检测中的问题,提出了一种DeformMobileViT 分类模型,将可变形卷积网络与MobileViT 结合,并基于迁移学习训练建模,从管道设备获取的地下管道图像样本中,判别出可能存在各类缺陷的样本。实验结果表明,本文提出的模型F1normal 分数达到94.15%。本文工作可以有效降低人工检测的工作量,并提高检测精度,具有良好的应用价值。
1 相关工作
随着城市化发展,地下管道负荷越来越大,不仅容易出现管道开裂、变形、腐蚀、有沉积物等缺陷,而且容易造成城市内涝,道路坍塌等事故,对其进行缺陷检测非常重要。地下管道缺陷一般需要由专业人员来辨别。然而,人工判断过程需要大量专业检查人员和时间,并且直接到地下管道中检测非常不安全[1]。目前有很多学者已经在基于深度学习的地下管道缺陷检测领域做了很多相关工作,也取得了许多成果。例如,在2019 年,Hassan 等人提出基于对AlexNet 进行变换学习的模型,该模型能够识别6 种主要的裂纹类型[2]。Xie 等人使用了两级分层的深度CNN 模型,在多个基准数据集上获得了超过94%的分类准确率[3]。2021 年,奥尔堡大学(AAU)在地下管道缺陷的研究中基于数据集SewerML[4],使用12 种来自多标签分类和地下管道自动检测领域的模型进行了评估,使用Xie 的两级模型方法在其他模型上实验得到自己的基准算法,F2CIW 得分为55.11%,F1normal 分数为91.8%[4]。目前的研究中,只有Xie 的研究中有地下管道异常样本判别,且是作为第一阶段网络的工作,并通过冻结卷积层的参数和微调全连接层来实现第一阶段学习到的参数转移到多分类模型中。
在地下管道异常缺陷检测研究中,目前传统卷积神经网络模型是提取图像特征最主要的方法,但是卷积神经网络的卷积核大小是固定的,这使得它只能局部地提取图像特征,需要通过多层叠加才能获取更高级别的特征信息,然而这也容易导致梯度消失和梯度爆炸问题。使用残差连接优化的网络,虽然能一定程度上优化这个问题,但是网络越深需要的资源就越多,不便于部署于移动设备中。
本文是基于上述问题对MobileViT 模型进行研究,在本文研究中,将地下管道的各种异常缺陷统称为缺陷样本,本研究将存在缺陷的样本检测出后,交由专业人员进行进一步复核,目前不对具体的缺陷类型进行判别。
2 DeformMobileViT 模型
2.1 可变形卷积
可变形卷积(Deformable Convolution)[5]即卷积位置可以进行变形。与传统卷积不同,传统卷积只对N×N个网格进行卷积,这种方式可能会忽略掉一些重要的特征。相比之下,可变形卷积可以更加准确地提取所需的特征,因为它不受矩形框的限制。在滑动采样时,一般会在卷积核上均匀采样一些点,并根据学习到的偏移量来计算采样点在输入特征图上的位置。具体地,可以将输入特征图上的每个像素看作一个坐标点,然后在卷积核上均匀采样一些点,再通过学习到的偏移量将这些采样点映射到输入特征图上。这样,在进行卷积操作时,每个采样点就可以根据自己的位置对应到输入特征图上的不同像素,从而实现可变形卷积的自适应形状采样[5]。
需要注意的是,由于采样点的位置是通过学习得到的,因此在可变形卷积的训练过程中,需要额外学习偏移量参数。这些参数的学习可以通过反向传播算法来进行,从而使采样点能够自适应地学习到最优的位置,以便更好地适应输入特征图的变化。
2.2 MobileViT 模型
MobileViT 模型的主要构成是MobileNetV2 模块和MobileViT 模块,其中MobileViT 模块可以被看作是一种将卷积操作和Transformer 相结合的特征提取模块。MobileViT 模块主要由局部特征提取模块、全局特征提取模块以及特征融合模块三部分组成,通过多个Transformer的堆叠,从输入图像中提取全局和局部特征。
MV2 模块的核心部分是借鉴了逆残差(Inverted Residuals)的思想,包括一个扩展层、深度可分离卷积层和线性投影层。该模块的设计旨在提高神经网络的非线性表达能力,并通过减少计算量和参数数量来实现更好的性能。
2.3 DeformMobileViT 模型
为了分辨出图像中管道缺陷轮廓像素,本文提出的DeformMobileViT 在MobileViT 网络中加入可变形卷积层,DeformMobileViT 结构如图1 所示。

图1 DeformMobileViT 模型结构,图中红色虚线框中为本文加入的可变形卷积层Fig.1 DeformMobileViT model structure, in which the deformable convolution layer added in this paper is shown in the red dotted box
可变形卷积层(Deformable Convolution)[5]通过引入偏移量,增大感受野,同时使感受野可以适应不同尺寸、形状的管道缺陷轮廓,使模型实现更好的分类效果。将MobileViT 网络的第1 阶段和最后阶段的卷积调整为可变形卷积,而中间阶段保留为标准卷积层,以减小引入可变形卷积带来的网络参数量的增加对网络负荷的影响。
因为浅的网络层宽度与高度较大,有一个比较大的视野才能更全面地提取缺陷的特征,并且提取到的信息会一直前向传播,所以第一层网络可以提取到更好的特征很重要;最后一层卷积输出进行全局池化后进行全连接输出Logits,也有着十分重要的作用,于是本文将MobileViT 模型中第一块和分类器前的卷积网络替换为可变形卷积。中间阶段保留为标准卷积层,是为了减小引入可变形卷积层增加的网络参数量对网络的负荷所产生的影响。这样的设计可以在保持较小的计算代价的同时,进一步提高网络的性能。
3 实验结果与讨论
3.1 实验数据集及预处理
本文基于公开数据集SewerML 进行实验。
数据集Sewer-ML 中有超过130 万张地下管道图片,本章选择13004 样本作为研究对象,按照训练集、验证集、测试集划分进行训练、验证及测试,其比例接近7:1.5:1.5,如表1 所示。
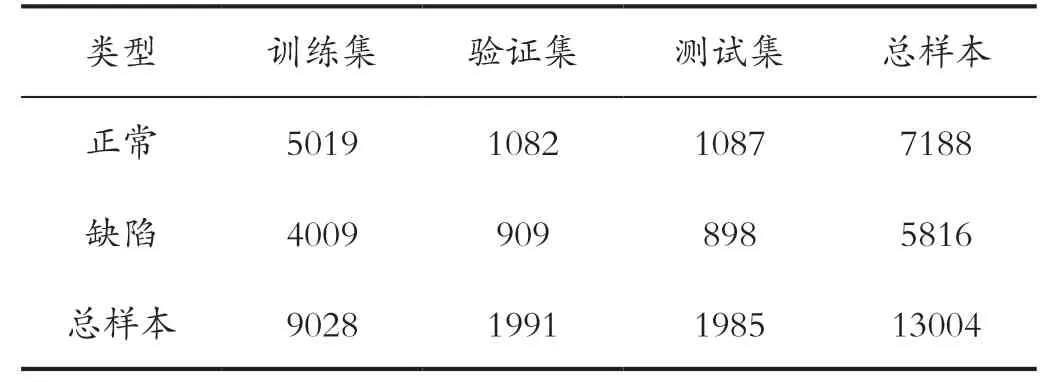
表1 数据集划分Tab.1 Data set partitioning
为提高模型的泛化性,一般要对训练数据做增强处理。本文通过将图像大小调整为224×224,以50%的概率水平翻转,将亮度、对比度、饱和度和色调抖动为原始值的±10%,使用训练分割通道平均值和标准偏差对数据进行归一化,并对训练数据进行预处理。
3.2 实验环境与参数设置
在本研究中,我们使用了基于GPU 的服务器作为实验环境,并在服务器上安装了Pytorch 深度学习框架。Python是我们主要采用的编程语言。处理器为Intel (R) Xeon(R)CPU E5-2630 v4@2.20GHz,GPU 为NVIDIA Tesla P40 24GB。模型训练参数设置Epochs 为50,BatchSize为32,优化器选择SDG,损失函数使用Focal loss 函数。
3.3 实验结果
FLOPs 表示模型计算量,精确度相同情况下,一般计算量越小越好,更小的计算量代表消耗更少的计算资源。Param 表示模型参数总量,参数一般也是越小越好;精度使用F1score、Accaury(准确率)及AP 进行评价。
如表2 所示,可以看出与传统的CNN 神经网络相比,将CNN 与Transformer 结合的MobileViT 网络具有明显的优势。在通用数据集上进行预训练之后,该网络在更轻量化的情况下比一般的CNN 网络具有更高的准确率。Hasson2019 使用的是AlexNet 网络,鉴于当时的硬件资源限制,其结构复杂、参数很庞大,达到217M,精度相较后面提出的ResNet 网络系列和DenseNet 较低,精确度仅达到78.76%,F1normal 有82.19%[6]。
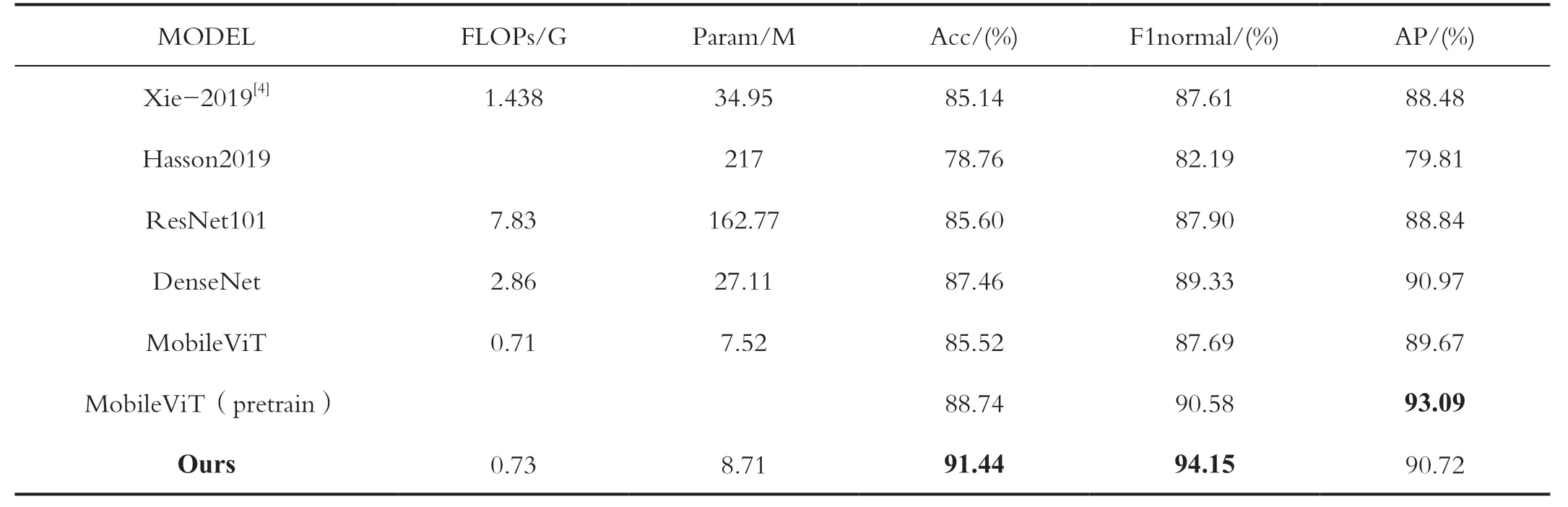
表2 缺陷分类实验结果对比Tab.2 Comparison of experimental results of defect classification
Xie 等人使用的两级分层的深度CNN 模型,准确度有85.14%。MobileViT 参数量仅有7.52M,计算量指标FLOPs 也仅有0.71G,相比卷积网络模型相对轻量。
MobileViT 将参数转移学习后,精确度、F1 及AP值分别提升了3.22%、2.89%和3.42%。MobileViT 引入两个卷积网络后,构建为DeformMobileViT 模型,计算量指标FLOPs 增加了0.02G 也就是20M,参数量增加了1.19M。迁移学习后的DeformMobileViT 模型相比迁移学习后的MobileViT 模型精确率和F1 得分均提高了2.7%和3.57%,最后精确度达到91.44%,F1 值达到94.15%,AP为90.72%。
4 结论
本文将轻量、准确率高的模型MobileViT,与可变形卷积网络结合,设计的DeformMobileViT 分类模型,能更加准确地提取特征,从而在分类表现上有显著提升。相比于原始模型,DeformMobileViT 在准确率上提升了2.7%,F1normal 分数提升了3.57%。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中华诗词(2020年1期)2020-09-21
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
小学生作文(中高年级适用)(2018年5期)2018-06-11
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
中学生数理化·七年级数学人教版(2017年11期)2017-04-23
数学大王·中高年级(2016年12期)2016-12-26
