
基于LSSA-BP 神经网络的煤层瓦斯含量预测方法研究
2023-11-29 10:04侯恩科荣统瑞卫勇锋夏冰冰谢晓深
煤矿安全 2023年11期
侯恩科 ,荣统瑞 ,卫勇锋 ,夏冰冰 ,谢晓深
(1.西安科技大学 地质与环境学院,陕西 西安 710054;2.陕西省煤炭绿色开发地质保障重点实验室,陕西 西安 710054;3.陕西陕煤黄陵矿业有限公司,陕西 黄陵 727307)
煤层瓦斯含量既是瓦斯地质规律分析的主要内容,也是预测瓦斯涌出量和煤与瓦斯突出危险性的重要参数[1]。但瓦斯含量受诸多地质因素影响,各因素条件复杂多样,且对煤层瓦斯含量影响程度大小也存在较大差异,具有不确定性、动态性和复杂性的特点[2-3]。因此,精准预测煤层瓦斯含量对煤矿瓦斯灾害事故的预防与治理具有重要意义[4]。
近年来,国内外学者提出众多方法来解决煤层瓦斯含量预测问题,如多元回归、灰色理论[5]、神经网络[6]、支持向量机[7]和极限学习机[8]等算法被应用于煤层瓦斯含量预测研究中。其中,由于BP 神经网络预测煤层瓦斯含量的效果较好而被广泛运用。吴观茂等[9]以煤层深度、煤层厚度、煤层顶底板岩性、井田地质构造和煤的变质程度为主要影响因素,建立了比多元回归分析预测精度更高的煤层瓦斯含量预测模型;沈金山等[10]运用灰色关联分析选取影响瓦斯赋存的主要因素进行建模预测,证明了灰色理论与神经网络预测模型的可靠性;为了克服BP 神经网络模型收敛速度慢和易陷入局部极小的问题,刘景艳等[11]采用粒子群算法优化BP 神经网络的神经元个数和连接权值,建立了粒子群算法优化BP 神经网络预测模型(PSO-BP);曹博等[12]先采用主成分分析降低变量间的相关性,然后用遗传算法优化BP 神经网络的权值和阈值,建立了PCA-GA-BP 神经网络预测模型,证明该模型可以准确预测煤层瓦斯含量;赵伟等[13]提出了自适应混沌海鸥算法(ACSOA),建立了基于自适应混沌海鸥算法优化BP 神经网络的瓦斯含量预测模型(ACSOA-BP),证明该模型具有更高的预测精度和稳定性;马磊等[14]提出了遗传算法(GA)和模拟退火算法(SA)混合初始化BP 神经网络的瓦斯含量预测模型(GASA-BPNN 模型),该模型将GA 和具有时变概率突跳性的SA 整合为GASA 算法协同初始化BPNN 的权值和阈值,有效提高了BPNN 的参数学习能力。由于影响煤层瓦斯含量的因素众多且各因素之间存在复杂的非线性关系,使得预测模型的精度和效率还有待提高[11]。综上,为了解决瓦斯预测的精度和效率,利用Logistic 混沌映射算法麻雀种群进行初始化,增加麻雀种群位置的多样性,提升麻雀算法的全局搜索能力,再将改进的麻雀搜索算法用于优化BP 神经网络,使得LSSA-BP 预测模型较其他模型,收敛速度更快、预测精度更高、稳定性更佳[15]。
因此,以黄陵一号煤矿为例,先采用灰色关联分析法筛选出影响煤层瓦斯含量的主控因素作为BP 神经网络输入层神经元,建立基于Logistic 混沌映射改进的麻雀搜索算法优化BP 神经网络的煤层瓦斯含量预测模型(LSSA-BP),并通过将该模型的预测结果与麻雀搜索算法优化BP 神经网络模型(SSA-BP)及标准BP 神经网络模型的预测结果进行综合对比分析,以期得到准确率和稳定性更优的预测模型。
1 模型原理
1.1 麻雀搜索算法(SSA)
麻雀搜索算法(sparrow search algorithm, SSA)是由XUE 等[16]受麻雀捕食过程引导启发而提出的一种新型群智能优化算法,主要通过麻雀的捕食和反捕食行为进行迭代寻优,包括发现者、跟随者和预警者3 种群体。捕食行为主要与算法中的发现者和跟随者相对应,一般占种群的70%,作为发现者在迭代寻优过程中适应度较高,具有更广泛的搜索能力,其作用是为跟随者的捕食行为提供向导,随后交由跟随者进行捕食;而反捕食行为则与算法中的侦查预警机制相对应,一般占据种群的20%,种群的部分麻雀作为预警者,其作用是根据捕食过程中危险的出现与否来决定是否放弃捕食。
发现者位置更新如式(1):

跟随者位置更新如式(2):

式中:Xbest为全局最优位置;β为步长参数,服从[0,1]的正态分布;K∈[-1,1]为随机数;fi为适应度值;fg、fw分别为全局最优和最差的适应度值;ε为常数。
1.2 Logistic 混沌映射
利用logistic 混沌映射如式(4):
式中:yn(t)为logistic 混沌映射对麻雀种群分布进行初始化后的序列;t为迭代次数;υ为控制参数。
对式(1)中的麻雀种群分布进行初始化,以增强种群多样性,并扩大种群搜索区域范围,其中yn∈ [0,1],y0为初始条件,其产生的映射序列是非周期性的且不收敛,此外生成的映射序列必于某一特定值收敛; υ为控制参数,决定该算法的演变过程,一般1≤υ≤4,随着 υ值的增大,映射序列的取值范围也随之增大,且映射分布更均匀,并当υ=4 时均匀性达到顶峰[17]。
2 LSSA-BP 预测模型的建立
2.1 LSSA-BP 模型
BP 神经网络预测模型的精度是通过不断调整模型的权值和阈值来提高的。因此,可使用SSA算法解决由权值和阈值随机初始化导致模型局部最优的问题,并引入logistic 混沌映射初始化麻雀种群位置,增加麻雀种群位置的多样性,扩大麻雀种群的搜索范围[18],从而提升LSSA-BP 模型的预测精度、收敛速度和稳定性。LSSA-BP 模型预测流程如图1。

图1 LSSA-BP 模型预测流程Fig.1 LSSA-BP model prediction flowchart
2.2 煤层瓦斯含量预测指标选取
以黄陵一号煤矿2#煤层为例,该矿瓦斯地质较为简单且瓦斯资料数据有限,根据前人对煤层瓦斯含量预测的研究,将影响煤层瓦斯含量X0的样本数据初步选取为以下7 个具有代表性且易于量化表达的影响因素:煤层厚度X1、煤层埋深X2、煤层上覆基岩厚度X3、煤层顶板20 m 内砂岩(粗粒砂岩、中粒砂岩、细粒砂岩)厚度X4、煤层顶板20 m 内泥岩厚度X5、挥发分X6和灰分X7。选取45 组瓦斯含量及影响因素的数据作为模型的数据集,其中数据前80%的部分作为训练集,剩余数据作为测试集,瓦斯含量及影响因素数据见表1。
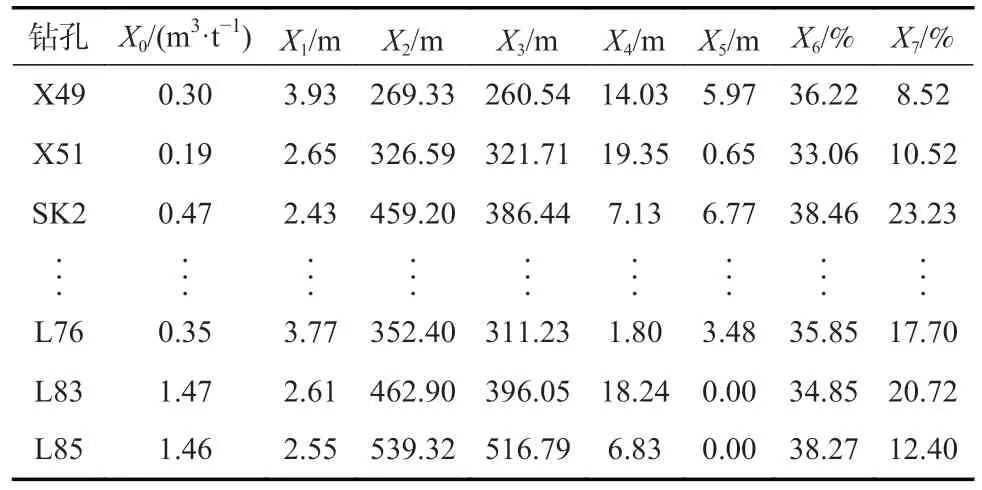
表1 瓦斯含量及影响因素数据Table 1 Gas content and influencing factors dat a
借助MATLAB R2021a 平台,利用灰色关联分析法筛选主控因素作为模型的输入层节点数[19],步骤如下:
1)确定参考序列和比较序列。瓦斯含量X0为参考序列,影响瓦斯含量的7 个因素为比较序列Xe。
2)数据按式(5)进行归一化处理。
式中:re为关联度; θ 为 样本数量;wk为指标权重。
灰色关联度分析结果见表2。

表2 灰色关联分析结果Table 2 Gray association analysis results

由表2 可知:7 个影响因素的关联度均高于0.7,当关联度不小于0.8 时,认为关联性很好,因此选取关联度在0.8 以上的作为模型的输入层节点数。影响因素X6和X7的关联度值一致,说明这2 个因素对瓦斯含量的影响效果一样,只需保留1 个即可,剔除X7。最终确定将煤层厚度、煤层埋深、煤层上覆基岩厚度、煤层顶板20 m 内砂岩厚度和煤的挥发分共5 个影响因素作为模型的输入层节点数。
2.3 模型参数设置
为验证LSSA-BP 模型的稳定性、预测精度和运行速度,借助MATLAB R2021a 平台,将筛选出的5 维样本数据按照图1 预测流程进行训练,并利用SSA-BP 模型和BP 模型与该模型的预测结果进行综合对比。经过BP 模型的反复训练,隐含层节点数和均方误差见表3。

表3 隐含层节点数与均方误差Table 3 Implied layer node count and mean squared error
当隐含层节点数为11 时,BP 神经网络训练集的均方误差最小。因此,将构建结构为5-11-1的BP 神经网络,训练次数设置为1 000,学习速率为0.01,训练目标最小误差为0.000 01。SSA 算法中的初始种群规模为20,最大迭代次数为30,发现者占比为全部种群的70%,其余作为跟随者,预警者比重为20%,安全值为0.6。
3 模型预测结果
3.1 训练结果
优化收敛曲线如图2。

图2 优化收敛曲线Fig.2 Optimizing convergence curves
由图2 可知,LSSA-BP 模型在迭代15 次后达到全局最优,具有较强的寻优能力,而SSA-BP 模型在迭代25 次后才趋于平稳,且LSSA-BP 模型训练的均方误差更低;LSSA-BP 模型较SSA-BP模型具有更强的全局搜索能力、更高的预测精准度和更快的收敛速度。
3.2 预测值及预测误差对比
为验证LSSA-BP 模型在煤层瓦斯含量预测方面的有效性和优越性,选取数据样本中的后9 组数据作为预测样本进行预测,LSSA-BP 模型预测结果见表4,预测样本预测值与实测值对比如图3,预测结果绝对误差对比如图4。

表4 LSSA-BP 模型预测结果Table 4 SSA-BP model prediction results

图3 预测样本预测值与实测值对比Fig.3 Comparison of predicted and measured values of predicted samples

图4 预测结果绝对误差对比Fig.4 Comparison of absolute error of prediction results
由图3 可知:LSSA-BP 模型中除钻孔L83 的预测值与实测值相差较大外,其余钻孔的预测值与实测值在整体上接近程度较高;SSA-BP 模型,虽然部分钻孔的预测结果较好,但是其中钻孔L73 和L76 的预测值与实测值偏离幅度较大;而BP 模型的预测值与实测值偏离幅度总体较大,预测结果较差。
由图4 可知:LSSA-BP 模型的预测稳定性较其他模型最好,在整体上最接近于0,且较为平缓,其中钻孔L83 的预测误差最大,误差达到了0.734 4 m3/t,小于SSA-BP 模型的最大误差1.304 2 m3/t;而单一的BP 模型预测误差总体上均较大,最大误差高达2.191 9 m3/t。
由以上各模型的预测值以及预测误差对比可知,LSSA-BP 模型预测结果准确度较高且稳定性更佳。
3.3 预测精度对比
为了能够有效反映模型预测的精度,选择平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)4 个指标作为模型预测精度的评价指标[20-21]。模型精度指标见表5。

表5 模型精度指标Table 5 Model accuracy indexes
LSSA-BP 模型的4 项指标均优于SSA-BP 模型和BP 模型;较SSA-BP 模型4 项指标分别提升了 0.059 5 m3/t、 0.181 4 m3/t、 0.179 7 m3/t 和18.385 3%,其中在MSE、RMSE 和MAPE 这3 项指标的提升效果较明显。
LSSA-BP 模型的4 项指标较BP 模型4 项指标分别提升了0.867 8 m3/t、1.672 2 m3/t、0.943 2 m3/t 和76.598 0%;总体提升效果非常明显,表明LSSA-BP 模型在煤层瓦斯含量预测方面具有一定优势;而对BP 模型的4 项指标数值均较大的情况,是由于BP 模型在搜索过程中易陷入局部极小值,且搜索效率较低,甚至出现“过拟合”现象的原因。
通过对比3 种模型预测结果的4 项指标,LSSA-BP 预测模型的各项指标均为最优,可满足在煤层瓦斯含量准确预测的需要。
4 结 语
1)通过灰色关联分析法计算出各个因素与煤层瓦斯含量之间的关联度,可筛选出影响煤层瓦斯含量的主控因素,从而能确定模型的输入层节点个数,降低模型的数据维度,减小模型的计算量和预测误差。
2)利用Logistic 混沌映射初始化麻雀种群,可增加种群多样性,扩大全局搜索能力,并通过LSSA 对BP 神经网络权值和阈值的优化,所建立的基于LSSA-BP 的煤层瓦斯含量预测模型,有效解决了单一BP 模型收敛速度慢和易陷入局部极小的问题。
3)就训练结果对比,LSSA-BP 模型较SSABP 模型对数据的学习迭代次数明显减少,具有较强的寻优能力。通过对比LSSA-BP、SSA-BP 和BP 模型预测结果,LSSA-BP 模型的预测值与实测值贴合度较好,具有更佳的稳定性。同时,LSSABP 模型的平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)分别为0.346 9 m3/t、0.172 1 m3/t、0.414 9 m3/t 和27.403 6%均优于其他模型,具有较高的精准度。由此表明,LSSA-BP 模型在煤层瓦斯含量预测方面具有一定的优势,可为煤矿瓦斯灾害防治提供比较可靠的分析和决策依据。
4)在本次煤层瓦斯含量预测研究中,样本数据初步选取为7 个具有代表性且易于量化的影响因素,并且样本数量有限;在今后的研究中,进一步丰富样本数据的类型和数量预测效果会更佳。另外,当训练样本数目较多时,LSSA-BP 模型训练耗时较长,未来需在这方面有进一步的优化提升,以提高模型在煤层瓦斯含量预测方面的实用性。
猜你喜欢
今日农业(2022年15期)2022-09-20
作文小学中年级(2019年10期)2019-11-04
建材发展导向(2019年5期)2019-09-09
新世纪智能(高一语文)(2018年11期)2018-12-29
红土地(2018年7期)2018-09-26
趣味(语文)(2018年2期)2018-05-26
山东工业技术(2016年15期)2016-12-01
江西煤炭科技(2015年1期)2015-11-07
河南科技(2014年7期)2014-02-27
当代畜禽养殖业(2014年10期)2014-02-27
