
多尺度注意力引导的全景分割网络
2023-11-27 05:35:26瞿绍军
计算机工程与应用 2023年22期
付 都,瞿绍军,付 亚
1.湖南师范大学 信息科学与工程学院,长沙410081
2.国网湖南超高压变电公司,长沙410004
图像分割是计算机视觉领域一个基础且非常重要的研究方向,对图像分割算法的研究至今已有几十年的历史。早期的图像分割通常是根据图像的纹理、颜色等特征来进行区域划分,此类技术单一,使得计算机处理分割任务时常常遇到各种困难且分割准确率也不高。随着深度学习的蓬勃发展和广泛应用,图像分割也发展到新的阶段,实现了更高的准确率。全景分割(panoptic segmentation)作为图像分割的一个重要分支任务,于2018 年由Facebook 人工智能实验室的Kirillov 等[1]提出,该任务实现了传统意义上相互独立的语义分割(semantic segmentation)和实例分割(instance segmentation)的统一。语义分割将图像划分成具有特定语义信息的区域块,并将相应的语义类别标签分配给这些区域块,最后得到所有像素都被语义标注的分割图像[2];实例分割首先从图像中检测出不同类别的实例,然后在此基础上结合目标检测在同一类别中进行逐像素标记以区分出单个实例对象,并给每个个体分配相应的实例ID[3];全景分割则是基于这两大类分割任务,首先将图像按其语义类别分成不同的区域块并分配语义标签,然后在此基础上区分出每个物体实例并标记实例ID,最后将具有相同语义标签和实例ID的像素判定为属于同一个目标,即实现了对图像背景语义信息和前景实例对象的同时处理。
近几年,全景分割任务因其新颖性及具有挑战性,吸引了众多研究者对其进行探索,并取得了很大进展。通过采用共享的主干网络实现了架构的统一,提高了资源利用率,但对于重叠的实例掩码、重复的像素级语义预测等冲突问题,研究者们虽然已通过预测的置信度分数[1]、类别之间的成对关系[4]来解决重叠的实例掩码,或者是开发全景头(panoptic head)等高级模块来融合语义和实例分割结果[4-5]等,这些操作在一定程度上缓和了上述冲突问题,但由此也产生了一些额外的预测、后处理以及融合操作,这在一定程度上会减慢整个系统。因此研究者们开始致力于设计一个真正意义上的统一算法,使固定形状的things实例对象和未定形的stuff区域能以相同的方式进行分割预测,在一定程度上解决这个问题。基于此,Li等[6]提出了全卷积全景分割网络(fully convolutional networks for panoptic segmentation,PanopticFCN),通过将每个things 实例对象或stuff 类别编码为特定的卷积核权重,并与得到的高分辨率特征直接卷积结合来产生全景预测。PanopticFCN的关键思想是在完全卷积的管道中用生成的卷积核权重均匀地表示和预测things 和stuff,其在性能和效率方面也都优于以往大多全景分割算法,但对于全景分割任务中前景实例对象特别是远距离小目标分割精度不高的现象,仍无法有效改善,背景未定形区域的分割效果也有待进一步优化。
针对全景分割模型中存在的上述问题,本文以PanopticFCN 为基准来进行改进优化,提出一种多尺度注意力引导的全景分割网络(multiscale attention-guided panoptic segmentation network,MAPSNet),主要包括如下两个改进工作:
(1)多数图像分割任务均采用残差网络(ResNet)[7]作为主干网来进行特征提取,然后添加特征金字塔网络(feature pyramid networks,FPN)[8],通过自顶向下上采样操作和横向连接,将高层强语义信息融合到低层特征中,以获取丰富的多尺度特征。但高层特征中仍缺少低层细节信息,因此参照自顶向下路径的操作,添加一条自底向上的辅助路径,通过逐级下采样操作和横向连接,将低层细节信息融合到高层特征中,获取图像丰富的细节信息,进一步增强主干网络的图像特征获取能力。
(2)在卷积核权重生成过程中,提出一种注意力模块ASAM,通过聚合多尺度空间特征信息和关注通道特征信息来引导卷积核权重的生成,提高匹配准确率,进而提高实例级分割准确率及全景分割预测质量。
1 相关工作
早期的全景分割算法主要遵循文献[1]的处理方法,将已有的语义分割和实例分割算法中性能表现较好的独立模型进行组合,然后通过融合处理来得到全景分割结果。虽然这类算法在全景分割性能上也均获得了不同程度的提升,但因使用了完全不同的网络模型,在实例分割和语义分割之间几乎不执行任何共享计算,使得整体模型计算复杂,计算量和占用内存也较大。Xiong等[4]提出了一个统一的全景分割网络(unified panoptic segmentation network,UPSNet)。该模型以特征金字塔网络[8]作为共享主干来提取图像丰富的多尺度特征,采用了基于可变形卷积[9]的语义分割头和Mask R-CNN[10]风格的实例分割头,最后还引入了一个无参数的全景头,通过其融合两个子任务来解决全景分割任务。UPSNet以更快的推理速度实现了性能的提升,但其未充分有效地利用高分辨率特征图中的细节信息,对图像中的小目标分割效果不是很理想。特征金字塔全景分割网络(panoptic feature pyramid networks,PanopticFPN)[5]、注意力引导的统一全景分割网络(attention-guided unified network for panoptic segmentation,AUNet)[11]以及轻量级全景分割网络(lightweight panoptic segmentation network,LPSNet)[12]等也均是采用了类似分支结构来实现全景分割任务,通过增强主干网、添加注意力机制以及建立分支子任务之间的联系等各种方法来进一步提高全景分割性能。但这些方法都忽略了目标位置的重要性。针对此问题,Chen等[13]提出了空间流(SpatialFlow),通过构建能在各个子任务中进行传递的多级空间信息流,将图像中对象的空间位置信息应用到整体模型中,依次增强了网络提取对象位置细节的能力,提升了网络理解输入图像的能力,使模型能够实现空间位置感知。Cheng等基于DeepLabv3plus[14]设计了一个简单、快速的全景分割网络Panoptic-DeepLab[15]。它采用了特定于语义和实例分割的双空洞空间金字塔池化(dual-atrous spatial pyramid pooling,Dual-ASPP)和双解码器(Dualdecoder)结构来进行分割预测,具有较快的推理速度,同时还可以实现与其他方法相当的性能。分组卷积全景分割网络(grouped convolutional panoptic segmentation network,GCPSNet)[16]在此基础上进一步对Dual-ASPP 结构中空洞卷积的扩张率进行调整,以此来提高模型对特定分割任务的适应性,并对Dual-decoder结构进行分组整合以实现单路分组解码,这样不仅简化了网络模型结构,降低了解码网络参数量,还不会影响图像的语义和实例特征表达。Axial-DeepLab[17]则引入了自我注意的思想,提出将经典的二维自我注意力沿着高度轴和宽度轴分解为两个一维的自我注意力,这样处理不仅降低了计算复杂度,还能够在更大甚至是全局区域内进行注意,将分解后的自我注意力与添加了相对位置编码的位置敏感型自我注意进行融合,产生的位置敏感的轴对称注意力(Axial-attention)大大减少了全景分割模型的参数量和计算复杂度。
全景分割任务尽管已提出了各种有效的改进算法,但仍存在计算效率和精度不足的问题,Mohan 等[18]在EfficientNet[19]的基础上提出了高效全景分割(efficient panoptic segmentation,EfficientPS)算法,该算法采用双向FPN构建了一种更强大的共享主干网络,能够对语义丰富的多尺度特征进行有效的编码和融合,并以端到端方式联合优化整个网络,得到了更高效、更快速的全景分割结果。
目前,学者们对于全景分割算法的研究,已涵盖主干网络、特定任务特征细化处理以及计算优化等各个方面,提出了各种类型的分割算法,全景分割任务的综合性能也在不断提升。但通过研究分析发现,不管是PanopticFCN 还是上述这些分支式全景分割算法,其在Cityscapes 数据集上均存在前景实例对象分割不够准确,实例级全景分割质量不高的现象。针对这些问题,本文提出一种基于PanopticFCN 改进的全景分割网络。首先,对特征提取网络进行增强处理;其次,对卷积核权重生成模块进行优化,通过提出一种注意力模块提高卷积核权重的匹配准确率,有效提高了实例级分割准确率,进而提升了全景分割的综合性能。
2 多尺度注意力引导的全景分割网络
2.1 网络整体结构
PanopticFCN 是一个端到端的图像全景分割网络,它实现了以统一的方式来表示和预测前景实例对象和背景未定形区域。本文遵循该网络结构进行改进优化,设计了多尺度注意力引导的全景分割网络MAPSNet。如图1 所示,MAPSNet 模型主要由四部分组成,分别是基于残差网络和特征金字塔网络优化的特征提取主干网、特征编码器、卷积核生成器以及卷积核融合模块。
MAPSNet 分别采用ResNet-50 和ResNet-101 作为主干网络,因为顶层特征所包含的特征信息较为单一,为了获取丰富的多尺度特征,在ResNet 之后采用FPN来聚合多尺度信息,并得到多个不同尺度的独立特征图,可为后续多阶段迭代处理提供不同特征层上丰富的特征图[8]。为了进一步增强主干网络的特征提取能力,本文额外添加一条自底向上的优化辅助路径。关于此路径将在2.2 节详细介绍;在卷积核生成器中,位置头(Position Head)用于同时预测实例对象和无定形区域的定位和分类。核心头(Kernel Head)则是根据对象中心和无定形区域的位置来产生相应的卷积核权重,为了提高所生成卷积核权重的准确度,借鉴DeepLabv3plus中ASPP[14]思想、挤压和激励网络(squeeze-and-excitation networks,SENet)[20]中通道注意力思想,提出了引导卷积核权重生成的注意力模块(ASPP-SE attention module,ASAM)。关于ASAM 将在第2.3 节详细介绍。对于特征编码器和卷积核融合模块则遵循PanopticFCN 中的设置。首先通过语义FPN[5],将主干网输出的多个特征图P3~P5 上采样恢复至P2 的大小,再通过相加进行融合,生成高分辨率特征Fh,然后特征编码器应用Coord[21]策略对高分辨率特征Fh编码位置线索并生成编码特征Fe,卷积核融合模块则将生成的多个阶段的重复卷积核权重进行合并得到K,最后将卷积核权重K与编码特征Fe进行卷积操作即可得到最终的全景预测结果。
2.2 增强的特征提取主干网
MAPSNet的主干网基于残差网络和特征金字塔网络进行扩展优化来提取丰富的多尺度特征,其结构如图2所示。图中蓝色框中主要采用ResNet-50和ResNet-101中相应模块,其详细结构如表1所示,输入图像首先经过Stem 模块,即步长为2 的7×7 卷积,以及3×3 的最大池化层,输出通道数为64;然后依次经过多个Res 模块获取多个阶段特征,Res具体结构如图3所示(以Res2为例),由一个卷积块ConvBlock和n-1 个基本块Base-Block(Res2中为2个)组成,每个块都包含残差结构,其中卷积块ConvBlock 通过Shortcut 增加维度。基本块BaseBlock 则不改变维度,表1 中矩阵外的“ ×n”(Res2为“×3”)即表示每个Res结构中ConvBlock和BaseBlock的数量和。

表1 ResNet-50和ResNet-101的结构Table 1 Structure of ResNet-50 and ResNet-101

图2 增强的特征提取主干网Fig.2 Enhanced feature extraction backbone

图3 主干网中的Res模块结构Fig.3 Structure of Res module in backbone
由残差网络产生的高层特征语义强但分辨率低,特征金字塔网络通过自顶向下进行上采样操作,然后将上采样后得到的特征与横向连接中相邻低层高分辨率特征依次求和,将高层强语义信息附加到各低层特征中,生成了高分辨率且语义强的多尺度特征表示。FPN 以一种比较简单的方法指出了不同层之间特征融合的重要性,但对于各层特征信息的利用仍不够充分,高层特征中缺少低层特征丰富的细节信息。路径聚合网络(path aggregation network,PANet)[22]、NAS-FPN[23]、BiFPN[24]以及Bi-Yolov3-tiny[25]等研究遵循FPN的思想,尝试了各种融合方法来充分利用各层特征中包含的丰富图像信息,借鉴这些思想,针对FPN中存在的不足,通过在原始FPN 自顶向下操作的基础上添加一条自底向上辅助路径,将低层细节信息附加到各高层特征中,来生成包含丰富细节信息的多尺度特征表示,进一步实现特征增强。如图4 所示,将原始图像(a)分别输入到FPN 主干网和改进后的主干网中进行处理,并将高层特征图(P5)提取出来进行可视化对比。从图中可以看出,后者得到的效果(c)相比于前者效果(b)获取到了更多的特征信息,所包含的细节信息也明显要更加丰富。其结构如图2中红色框所示,具体操作类似于自顶向下模块,不同之处在于与横向连接进行聚合时,采用求均值而不是求和的方式来得到与原始FPN各阶段输出同尺度的特征,最后再将两者求均值得到具备各种丰富信息的多尺度特征,即低层特征具有了强语义信息,高层特征也包含了丰富的细节信息。
2.3 引导卷积核权重生成的注意力模块
近几年,注意力机制被广泛应用于图像分割、自然语言处理、图像识别等各种深度学习任务中,其主要思想是借鉴人类视觉系统的选择性这一特点,对卷积神经网络中的特征图进行差异性处理,从而能将有限的计算资源重点投入到模型的主要任务中,并能根据任务结果来反向指导特征图的权重更新,达到高效快速地完成相应任务的目的[26-27]。
根据注意机制的这一特性,并结合空洞空间金字塔池化ASPP 和SENet 中通道注意力的思想,提出在卷积核权重生成过程中建立新的注意力模块ASAM,来引导生成准确度更高的卷积核权重。其详细结构如图5 所示,ASAM通过利用不同扩张率的空洞卷积对输入特征进行多尺度并行采样处理,以捕捉图像多个不同尺度的空间上下文信息,将其聚合可有效获取图像的全局特征信息,增强像素之间的依赖性,其特征图可视化结果如图6(c)所示,相比图(b)PanopticFCN中直接通过3个3×3卷积操作而不进行多尺度处理的方式,所得图像整体效果明显更佳;然后在此基础上再进行挤压操作,将全局信息压缩到各通道中进行处理,最后通过激活函数得到代表每组特征图重要性程度的权重向量,并利用此向量来激励特征图,引导权重不断向着有利于任务的方向更新[27],缩小对任务来说不重要的特征的权重,同时放大对于任务更加重要的特征的权重,将单个阶段处理后的256个通道的权重提取出来进行融合,然后作用于图像并进行可视化,得到如图6(d)所示效果。通道注意力思想的引入,使网络关注到图像不同通道之间的关系,并学习不同通道的重要程度,进一步加强对图像局部特征信息的捕获。
ASAM模块的具体操作如式(1)~(3)所示:
式(1)中输入Xi指的是主干网中输出的独立多尺度特征图(P3~P7)。Concat表示级联拼接操作。f1表示1×1卷积和组标准化(group normalization,GN)操作,采用1×1 卷积是为了防止空洞率过大而造成卷积核参数不能完全利用[2],而组标准化也是一种深度学习标准化方式,解决了批标准化(batch normalization,BN)操作对批次大小依赖的影响,因此可以替代BN。f2表示采用不同扩张率的空洞卷积来扩大图像感受野,通过实验验证,当扩张率取值为(12,24,36)时取得的综合效果最佳,具体实验细节将在第3.3节中详细介绍。P表示全局平均池化操作(global average pooling)。式(2)和式(3)即是对拼接后的特征进行具体通道注意操作。首先通过全局平均池化操作P对每张特征图进行挤压,得到一个具有特征图上全局注意力信息的实数,将得到的挤压实数进行组合,构成每组特征图的权重向量,将此向量依次通过全连接层fc1与ReLU 激活函数R,全连接层fc2与sigmoid激活函数S进行归一化处理;最后再利用Softmax激活函数即可得到代表特征图重要性程度的向量。
3 实验
3.1 数据集和评估指标
本文模型在实验时使用城市街道场景数据集Cityscapes,该数据集记录了来自50 个世界不同城市的街道场景,拥有5 000张高质量像素级标注的图像,被分为包含2 975张图片的训练集、500张图片的验证集以及1 525张图片的测试集,包括地面类、车辆类、自然类、建筑类、天空类、小物体类、人类和道路标志类等8 个大类,具有19 个类别的密集像素标注[28],给研究者们提供了无人驾驶场景下的图像分割数据。Cityscapes中每张图像的分辨率均为1 024×2 048,为了更好地衡量模型对小目标的有效性,基于各类目标的尺寸,将pole、traffic light、traffic sign、person、rider、motorcycle、bicycle 等小于32×32像素的类别定义为小目标,所有其他12种类别均定义为大目标[29-30]。
全景分割任务在提出的同时,为了更好地衡量任务执行的性能表现,引入了全景质量(panoptic quality,PQ)度量标准[1]。全景质量能综合衡量全景分割的关键性能特征,它以统一的方式对待所有的实例对象和未定形区域,其详细计算方式如式(4)所示。
其中,IoU(p,g)是预测对象p和真值g之间的交并比(intersection over union)。交并比即检测相应物体准确率的一个测量标准,是对象类别分割问题的标准性能度量[31]。TP(true positive)表示正确匹配的区块,即预测块与真值标注块之间的IoU 达到阈值0.5 以上的区域。FP(false positive)和FN(false negative)则分别表示被模型判定为正值的负样本和被判定为负值的正样本,二者被添加到分母中以惩罚没有正确匹配的部分。
如式(5)所示,为了更好地解释分割结果,可将PQ分解为分割质量(segmentation quality,SQ)和识别质量(recognition quality,RQ),它可以看作是SQ和RQ的乘积,SQ 表示匹配后的预测块与真值标注块之间的平均IoU,RQ则是用来计算全景分割中每个实例对象识别的准确性[1]。但最终PQ 并不是简单的组合语义和实例分割度量,而是针对每一类实例对象和未定形区域按照式(5)分别进行计算,测量出单个类别的PQ、SQ 和RQ值,然后再将得到的所有类别的相应值分别取均值,如式(6)所示,其中Nc为总共计算的类别数,后续实验结果中的PQ、SQ 和RQ 值均为式(6)中的PQavg、SQavg、RQavg。
3.2 实验设置
本文实验基于PyTorch-1.6.0+CUDA-10.1框架实现,由于Cityscapes 的训练图像相对较少,使用在ImageNet数据集上预先训练的权重来对模型进行初始化操作。首先对图片进行尺度裁剪等预处理操作,将大小调整为512×1 024 作为网络的输入,然后在两张Tesla-T4 GPU上以8张图像的批量大小来训练模型(每张GPU 4张图像),在训练过程中采用焦点损失(focal loss)[32]优化对象中心和未定形区的位置信息,如式(7)所示:
其中WDLoss 表示加权骰子损失函数,Pj和分别表示分割预测结果和真实值;N表示全部实例对象和未定形区卷积核权重产生的实例预测数量。将两者相结合作为网络的损失函数,如式(9)所示:
其中λpos和λseg为平衡因子,分别设为1.0和3.0来平衡位置损失和分割损失之间的权重。模型其他相关参数则根据实际训练情况遵循实验PanopticFCN 在Detectron2框架中的配置规律进行调整。具体来说,将初始学习率设置为0.01,动量和权重衰减系数设置为0.9和1.0×10-4,然后进行6.5×104次迭代训练。
3.3 实验定量分析
为了验证所添加的自底向上辅助路径和引导卷积核生成的注意力模块的有效性,比较MAPSNet 模型的改进效果,保持使用相同的环境并设置相同的学习率、迭代次数等参数,采用ResNet-50 作为网络主干,在Cityscapes 数据集上进行相关消融和对比实验,结果如表2 所示。在单独添加自底向上辅助路径后,网络的IoU 提高了约1 个百分点,推理500 张图像时的单张图像平均计算时间也稍有降低,但全景分割质量并未提升;而在单独添加注意力模块后,网络的全景质量提升了1.63个百分点,IoU也稍有提升,但效果不太明显,其平均计算时间有所损耗;综合这两个模块的优势和不足,同时将其添加到网络中,如表2中第2行和第5行所示,全景质量提高了1.94 个百分点,IoU 也提高了1.13个百分点,其单张图像的平均计算时间也和基准网络相当,模型的综合性能达到最佳。此外,MAPSNet中的小物体如交通灯(traffic light)和摩托车(motorcycle)的分割准确率显著提高了4.4个百分点和8.3个百分点,对于大面积的未定形区域如墙体(wall)提高了8.8 个百分点,道路、围栏等其他类别也稍有提升,具体各类别的准确率如表3 所示。MAPSNet 在牺牲少量参数量和内存的轻微代价下,实例级分割质量显著提高了2.74个百分点(表4 中第五、第六行)。综合来说MAPSNet 的整体效果明显优于PanopticFCN,证明所提模型可以更好地提升图像前景实例、背景未定形区域的分割准确率乃至全景分割综合性能。

表3 Cityscapes数据集上各个类别的准确率Table 3 Accuracy for each category on Cityscapes dataset
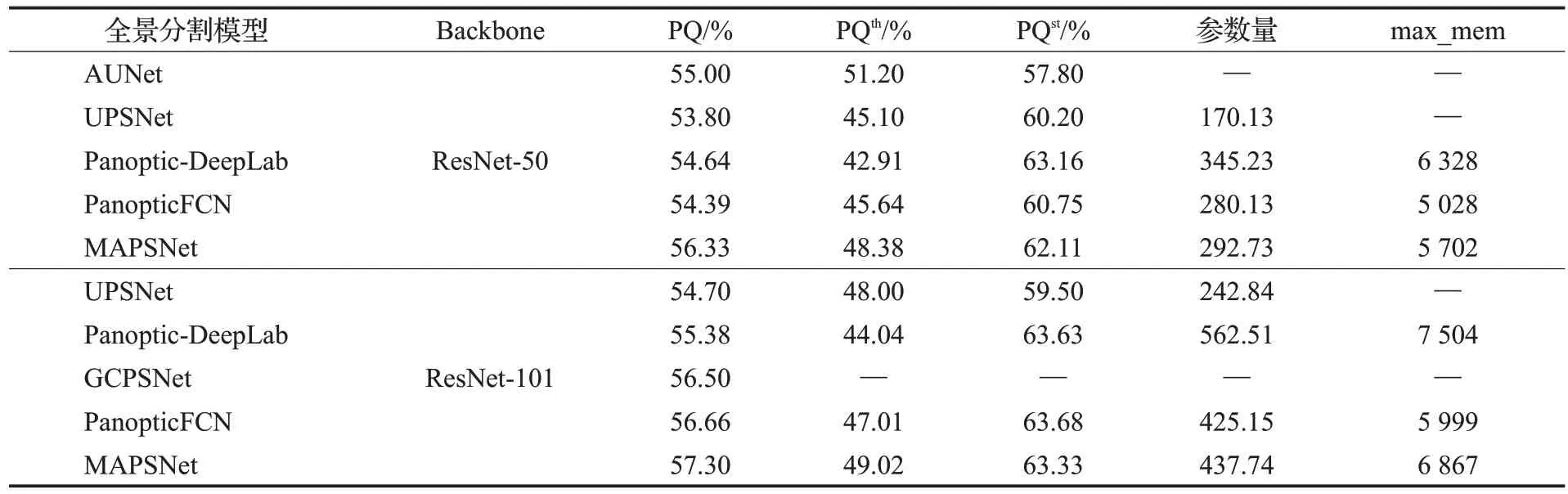
表4 MAPSNet与其他全景分割模型的实验对比Table 4 Experimental comparison between MAPSNet and other panoptic segmentation models
在相同的实验环境及配置下,将MAPSNet 模型与其他以ResNet-50和ResNet-101为主干的全景分割模型进行对比,如表4所示。MAPSNet得到的全景分割性能不仅要优于PanopticFCN,与UPSNet 相比,全景质量分别提高2.53 个百分点和2.6 个百分点,对比Panoptic-DeepLab整体效果则提升更多,在参数量和内存都更低的情况下全景质量也还分别高出1.69 个百分点和1.92个百分点,即使与AUNet 等在更好的硬件环境下(8 个GPU)训练的网络相比也能达到相当性能水平。
ASAM 中使用了不同扩张率的空洞卷积的级联。空洞卷积是指在卷积层中通过引入扩张率来增加处理数据时各值之间的间距。原始普通卷积如图7(a)所示,扩张率为3 和6 的空洞卷积分别如图7(b)(c)所示。空洞卷积能够扩大感受野以减少图像冗余信息,通过设置多个不同扩张率的空洞卷积,可以获得更加丰富,精度更高的多尺度信息。考虑到不同扩张率所达到的效果不同,对ASAM中采用不同扩张率组合的空洞卷积进行对比实验,结果如表5所示。随着空洞卷积扩张率的整体增大,全景质量也不断提升,表明通过空洞卷积增大感受野对于特征增强是有效的,其不仅很好地过滤了一定的特征冗余信息,同时对于有用特征信息的提取也在增多。但当扩张率增大到一定大小后,由于扩张率的持续扩大会损失信息的连续性,反而导致特征冗余信息的增多,因此其增强效果也开始变缓甚至降低[16]。如表5中最后一行数据所示,在扩张率增大到(12,24,36)时,识别质量SQ 开始降低,未定形区域全景质量PQst的增长也变缓,故在后续实验中即采用扩张率为(12,24,36)的空洞卷积。

表5 ASAM中采用不同扩张率的实验对比Table 5 Experimental comparison of different dilation rates in ASAM 单位:%

图7 不同扩张率的空洞卷积对比Fig.7 Comparison of atrous convolutions with different dilation rates
对于第2.2节介绍到的自底向上辅助路径采用的聚合方式,为了比较不同聚合方式对于网络模型实际效果的影响,分别采用求和及求均值的方式来进行实验对比验证,结果如表6 所示。不难看出,在采用求均值的聚合方式时,模型整体效果更佳。

表6 辅助路径中不同聚合方式实验对比Table 6 Experimental comparison of different aggregation methods in auxiliary path 单位:%
3.4 实验定性分析
图8 直观地展示了PanopticFCN 和MAPSNet 模型在Cityscapes数据集上的可视化全景分割效果对比。从图中的红色框标记可以看出,图(c)中PanopticFCN模型对于图像中远距离的交通标识、信号灯等小物体未能正确检测出来,而在图(d)中MAPSNet模型则将其准确地识别并分割出来。此外,从第二行和第四行中的黄色框标记可以看出,MAPSNet模型对于人、小型车等前景实例对象的识别分割准确率更高,而对于背景未定形区域,从第一行和第三行中的黄色框标记可以看出,MAPSNet模型在处理区域边缘时相较PanopticFCN 要更清晰完整,但对于复杂的边界仍然无法很好地进行分割(如第一行和第四行中绿色框标记所示)。因为相邻的像素对应感受野内的图像信息太过相似,若其均属于目标分割区域的内部,那么是有利于分割的,但若相邻像素刚好位于目标分割区域的边界上,则会导致边缘分割的不准确问题。目前针对此问题采用的主要方法为对网络输出的分割边界增加额外的损失,或在网络中添加边缘检测子任务以进行精细处理。后续将对边缘检测方法进行进一步深入研究,并在当前研究的基础上进一步提出相应详细的改进方法。
综上所述,MAPSNet相比PanopticFCN可以更好地增强全景分割中实例对象的分割效果,且同时不会影响甚至能提高图像背景未定形区域的分割质量,进而提升全景分割综合性能。
4 结束语
针对全卷积全景分割网络在Cityscapes数据集上前景实例对象分割准确率不高的问题,本文提出了一种改进的全景分割模型,通过在主干网络中融合添加一条自底向上的辅助路径,增强了网络的特征提取能力,丰富了多尺度特征。同时还提出了一种引导卷积核生成的注意力模块,在不影响图像背景未定形区域分割质量的情况下,提高了前景实例尤其是远距离小物体的分割准确率,进而提升了全景分割综合性能。实验结果表明,在相同的环境配置下,相较于基准全景分割网络模型PanoptiFCN,本文所提出的多尺度注意力引导的全景分割网络,在一定程度上有效提高了模型的实例级全景分割质量以及综合全景质量。但本文模型还存在一定的不足,对于背景未定形区域,大部分类别的提升效果甚微,且对于复杂的边界仍然无法很好地进行分割。未来将进一步研究改善这些问题,并在保证分割质量的同时进一步提高分割效率,简化模型的复杂度,增强模型的实时性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
家庭影院技术(2020年11期)2020-12-28 01:22:36
英美文学研究论丛(2018年1期)2018-08-16 03:00:54
传媒评论(2017年3期)2017-06-13 09:18:10
家庭影院技术(2017年12期)2017-02-06 02:32:12
特别文摘(2016年21期)2016-12-05 17:53:36
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
