
融合注意力机制与知识图神经协同推荐算法
2023-11-27 05:34:58杜雨晅郑小丽何婷婷
计算机工程与应用 2023年22期
张 闯,王 巍,3,杜雨晅,郑小丽,何婷婷
1.河北工程大学 信息与电气工程学院,河北 邯郸056038
2.河北工程大学 河北省安防信息感知与处理重点实验室,河北 邯郸056038
3.江南大学 物联网工程学院,江苏 无锡214122
随着信息时代的快速发展,购物、新闻、音乐、电影等平台和各种社交媒体平台应用的不断发展,用户需要在庞大的数据信息中寻找所需物品。推荐系统是缓解信息过载和提升用户体验的重要工具,能够帮助用户从海量数据中推荐所需要的物品,广泛应用于音乐推荐[1]、电影推荐[2]和网上购物[3]等场景。
目前推荐系统的研究都专注于基于协同过滤(collaborative filtering,CF)[4-5]的方法,虽然CF 方法具有普遍性和有效性,但是该方法存在数据稀疏和冷启动的问题。近年来,基于知识图谱(knowledge graph,KG)[6]的推荐算法可以有效缓解数据稀疏和冷启动的问题,因此该算法成为研究方向的热点。然而基于CF方法忽略了用户和物品属性特征等辅助信息对推荐的影响,为了利用项目属性和上下文信息等辅助信息,基于监督学习(supervised learning,SL)的推荐模型将这些辅助信息转换成一个通用的嵌入向量来表示,输入到监督模型中进行预测得分。例如FM(factorization machine)[7]、NFM(neural factorization machines)[8]、Wide&Deep[9]、xDeepFM[10]等模型将辅助信息转化为有监督的学习问题,这种SL模式的推荐在业界得到了广泛的应用[11-12]。该方法把用户项目交互的建模作为一个独立的实例,而忽略实体之间的关系,很难捕捉实体之间存在的关系信息。为了聚合实体间关系信息,2018 年王鸿伟等[13]提出RippleNet模型,在知识图谱中计算项目和头实体在空间中关系的相似度来聚合邻居的信息,2019 年王鸿伟等[14]提出KGCN(knowledge graph convolutional networks)模型,通过计算用户在知识图谱中关系的偏好相似度来聚合邻居信息。KGCN 模型虽然对用户关系信息进行聚合,但是没有引入实体间关系信息,实体之间的关系信息也会影响推荐结果。2019 年王翔等[15]提出了KGAT(knowledge graph attention network for recommendation)模型,通过计算头实体和尾实体在空间中关系的距离来聚合邻居信息。KGAT模型虽然考虑实体间的信息,但是忽略用户之间的关系信息。
综上所述,基于知识图谱辅助的推荐系统可以有效缓解数据稀疏和冷启动的问题,但是知识图谱中还存在一些潜在关系信息难以被捕捉,因此为了挖掘知识图谱中存在的潜在关系信息,提出了一种融合注意力机制与知识图神经协同推荐算法(neural collaborative recommendation algorithm based on attention mechanism and knowledge graph,AKGCF)。首先根据用户与项目的历史交互数据与项目属性信息构建知识图谱,并利用注意力机制来学习知识图谱中潜在关系信息并进行聚合;其次需要综合考虑用户的长期与短期偏好进行推荐,因此结合用户的长短期偏好通过门控循环神经网络进行训练,不但可以获取用户最终偏好,还可以有效缓解用户偏好的长期依赖性问题;最后利用内积的方式,得出用户对项目的偏好概率值,进行Top-N推荐。本文的主要贡献如下:
(1)AKGCF算法利用知识图谱辅助进行推荐,并融合注意力机制与知识图谱挖掘用户的潜在偏好。该算法利用注意力机制来捕捉知识图谱中的潜在关系信息,通过计算知识图实体间关系传递信息的权重值,聚合得到用户的偏好表示。
(2)结合用户的长短期偏好进行推荐。该算法利用门控循环神经网络对用户的长短期偏好进行处理,通过重置门控和更新门控对用户的偏好信息进行筛选,从而获取用户的最终偏好表示。
(3)基于书籍与电影两个不同场景的数据集,将AKGCF 算法与基准算法进行实验,并利用准确率、召回率、命中率和NDCG(normalized discounted cumulative gain)四个评价指标进行对比分析,通过实验结果证明了AKGCF算法的有效性和合理性。
1 相关工作
1.1 基于知识图谱的推荐算法
基于协同过滤的方法的主要思想:利用用户历史行为数据(购买历史、关注、收藏等)挖掘相似用户的偏好,预测用户可能喜欢的物品并进行推荐。传统的CF算法存在数据稀疏的问题,目前基于知识图谱的推荐系统的研究可以有效缓解这一问题,并在推荐的准确性和可解释性方面表现出了巨大的潜力[16],成为当今研究的热门话题。知识图谱[17]实质上是一种语义网络,是一种由多种类别的实体构成的结构化网络,以更加直观的图来展现,并且存储了实体间关系信息。构建知识图谱需要根据实体间的关系序列进行拓展,知识图中可以引入物品属性等特征信息,可以有效地缓解数据稀疏性的问题,更容易捕捉知识图中存在的潜在关系信息。推荐系统中对知识图谱的引用主要有三种方式:基于嵌入的方法、基于路径的方法和联合学习的方法。
基于嵌入的方法(embedding-based method)直接利用知识图谱丰富用户或项目信息来表示。为了充分映射相关信息,利用KGE(knowledge graph embedding)算法将知识图谱中的实体和关系信息映射到低维向量空间中,不仅简化操作,并且保留原有的结构。KGE 算法主要有两类:基于翻译的模型,例如TransE[18]、TransR[19]等。TransR模型考虑了实体是一个多属性的复合体,对每个三元组,将实体信息投射到相应的关系空间中,通过投影的方式建立关系,对于每一个关系r,TransR定义投影矩阵Mr,将实体信息投影到相应的关系r的子空间,用h⊥和t⊥表示,可以得到h⊥=Mr h,t⊥Mr。语义匹配模型通过实体与关系的底层语义匹配来衡量知识的合理性,如DistMult[20],提出了一种简单的多功能双线性表示方法,使实体间的关系能够集成到单一的空间中。
基于路径的方法(path-based method)将具有高层次信息路径引入预测模型,利用知识图谱中的连通性进行推荐。基于路径嵌入的方法是直接将学习连接的用户和项目之间的显性路径嵌入,直接对用户与项目的关系建模。如Wang等[13]提出了RippleNet模型,把知识图谱中的路径信息和实体信息作为辅助信息引入推荐算法中,将用户的偏好比喻成水波的形式传播,再对传播的各层预测结果进行相似度计算,根据预测值进行推荐。
联合方法(unified study method)的主要思想是基于嵌入传播的方法,将基于嵌入的方法和基于路径的方法有效结合起来,发掘知识图中各种潜在信息来提高推荐的准确度。基于路径和嵌入的方法都仅利用知识图谱中的单方面信息,忽略了知识图中可能影响推荐效果的信息。而联合方法是将路径连通信息与实体和关系的语义表示相结合。例如KGAT模型,利用知识图注意网络捕捉实体间的局部邻接结构,根据连接关系并通过注意力机制学习实体之间的关系信息进行聚合,得到用户的偏好进行推荐。
1.2 循环神经网络的应用
将循环神经网络应用到协同过滤算法中,将协同过滤看成一个序列预测的问题。循环神经网络(recurrent neural networks,RNN)的特点是能将信息永久化,能对信息进行存储,但是在训练时存在梯度爆炸和消失的问题。长短时记忆(long short-term memory,LSTM)网络是一种循环神经网络的变形[21],将长短时记忆的神经网络应用于协同过滤,能学习到长期依赖关系,在应用中比RNN 更加高效,其主要通过输入门、遗忘门、输出门对信息,但训练过程繁琐。循环门单元(gated recurrent unit,GRU)是LSTM的一种变形,其通过更新门,重置门和激活函数对用户的长期偏好进行更新和重置来解决长期依赖性问题。考虑实际情况,GRU的操作简单,训练速度快,效果更加高效,应用比较广泛。
循环神经网络在推荐系统中也被广泛应用。贾丹[22]提出了一种基于用户会话的推荐算法,利用隐性反馈数据挖掘用户潜在兴趣,并引用图嵌入方法,构建了一个基于用户会话的GRU 排名推荐算法;李全等[23]提出了一种融合时空信息的双向GRU 下一个地点推荐算法,通过深度学习神经网络的GRU 模型对用户的签到序列、时间信息和距离信息提取特征进行推荐;因此,GRU在推荐系统领域有重要的作用。
基于知识图谱辅助的推荐方法以及知识图谱中存在的潜在关系信息会影响推荐结果,因此本文提出了一种融合注意力机制与知识图神经协同推荐算法,通过融合注意力机制与知识图谱捕捉知识图谱中的潜在关系信息并聚合得到用户短期偏好表示。该算法综合考虑用户的长期与短期偏好对推荐的影响,通过结合循环门单元来对用户的长短期偏好进行训练,获取用户最终偏好,还有效地缓解了用户偏好的长期依赖性问题,最后利用内积的方式得出用户对项目的偏好概率值,生成推荐列表。
2 AKGCF模型
2.1 AKGCF模型整体框架
本文提出融合注意力机制与知识图神经协同推荐模型的整体框架如图1 所示。该模型主要有三部分:(1)嵌入层,根据用户与项目的历史交互二部图与项目的属性构建的知识图谱进行组合,并利用TransR算法通过优化翻译原则来学习嵌入每个实体和关系信息,知识图嵌入的方法可以有效地将实体和关系参数化为向量表示;(2)注意力层,利用注意力机制学习知识图中的关系权重并聚合得到用户短期偏好向量表示;(3)预测层,将用户的长期与短期偏好向量通过门控循环神经网络训练得到用户最终偏好表示,利用内积的方法得到用户的偏好概率值,生成推荐列表。
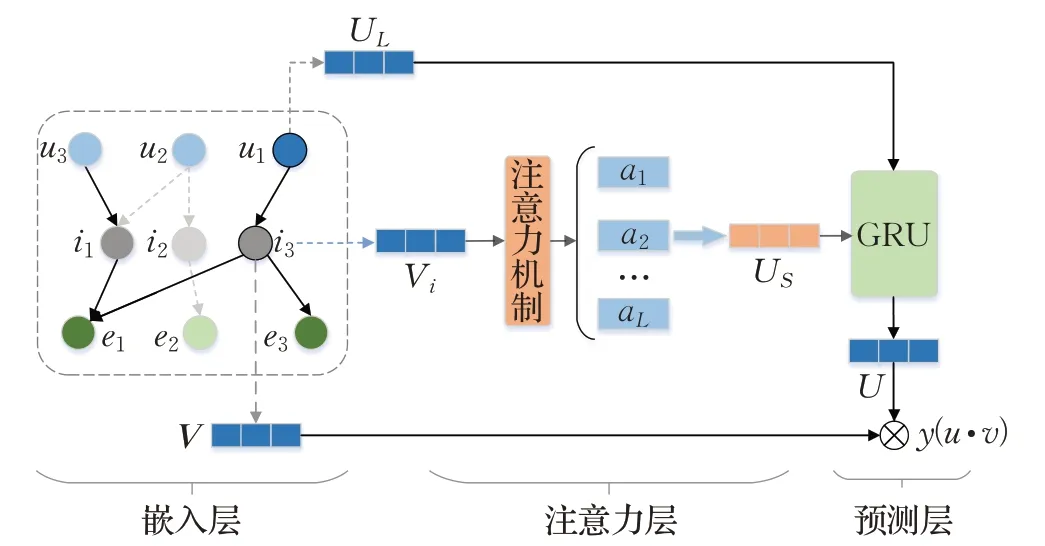
图1 AKGCF模型整体框架Fig.1 Overall framework of AKGCF model
2.1.1 嵌入层
本文将用户与项目的交互二部图与知识图谱组合成一个知识图,通过将项目与其属性联系起来打破独立交互假设。在该模型中,给定用户集合U={u1,u2,…,un}和项目集合V={v1,v2,…,vm},实体集E={e1,e2,…,ep},n、m与p分别表示用户与项目和实体的总数;利用交互矩阵Yij来定义用户是否浏览了电影或书籍,若Yij=1,则用户与项目之间发生过交互,若Yij=0,则未发生交互。定义含有结构化信息的知识图谱G={(h,r,t)|h,t∈ε,r∈R},其中每个三元组表示头实体h和尾实体t之间有一个关系r,ε、R分别表示不同实体的集合和不同连接关系的集合。
知识图嵌入方法可以将实体与关系参数转化为向量表示,本文采用TransR方法利用特定的关系矩阵来将实体和关系映射到不同的语义空间R中。具体来说,根据知识图的三元组表示(h,t,r),通过优化基于翻译算法的基本原理建立关系≈来学习嵌入实体与关系的嵌入向量,eh、er和et分别表示(h,t,r)的嵌入向量,其中eh,et∈Rd与er∈Rk;而与代表在关系r空间中的投影表示。通过给定的三元组(h,t,r),其合理性得分公式如下:
其中,Wr∈Rd×k为变换矩阵,它将实体从d维的实体向量空间投影到k维的关系向量空间表示,其函数得分越低,则表明三元组表示越真实。
2.1.2 注意力层
根据嵌入层得到项目的向量表示,利用注意力机制来学习知识图谱中实体间的关系信息并进行聚合。该聚合方式既考虑了用户的信息,又引入了知识图谱中的实体信息,综合考虑知识图谱中实体的高阶关系。如图2 所示,用户看电影《肖申克的救赎》,该电影的导演是弗兰克·德拉邦特,主演是蒂姆·鲍顿。《肖申克的救赎》在知识图谱中的对应关系,头尾节点分别为用户(头节点),尾节点为(导演:弗兰克·德拉邦特和主演:蒂姆·鲍顿),根据用户的喜欢程度通过注意力机制学习分配权重来聚合邻域信息,需要结合实体间的关系和头尾节点来综合考虑。

图2 示例图Fig.2 Example diagram
注意力机制的训练过程如图3所示,根据嵌入层以项目为中心的知识图谱,通过随机采样节点数和注意力机制计算权重得分。首先需要得到两个实体之间的关系,再通过注意力机制学习权重,可以得到一阶实体表示,再向L阶扩展即得到L阶实体表示。

图3 注意力机制层Fig.3 Attention mechanism layer
这里对第一阶的训练过程进行分析,再向L层结构进行扩展。其中式(2)表示两个实体之间的关系,式(3)计算用户对关系和实体信息偏好的权重值。对于一个项目v0,表示与v0相连的一跳邻居集合,(r,i,j)表示实体ei和ej之间的关系,并利用注意力机制公式计算权重值。
其中,u∈Rw,ri,j∈Rw和ej∈Rw分别为用户、两个实体间关系和尾实体的表示,w为向量维度,σ为非线性函数,W1为权重参数,b1∈Rd为偏置参数。u∈ri,jej表示用户对关系和实体信息的偏好程度。
为了得到项目v0的邻居信息向量表示,需要通过式(4)计算项目v0邻居的线性组合。
其中,e0是项目v0邻居实体的向量表示,并进行归一化处理。
其中,W2为权重参数,b2为偏置参数。σ为非线性函数。
为了挖掘高阶实体信息,将模型从一层扩展到多层,可以得到L阶向量表示,实体的L阶向量表示是聚合了L-1 跳邻域实体的信息。通过式(7)可以计算项目的L阶最终项目向量表示vL。
最后聚合得到用户的短期偏好表示,其中{vu,1,vu,2,…,vu,N}为用户N阶偏好表示。
其中,αi为注意力系数。注意力系数的得分取决于知识图谱内实体在空间关系的距离,计算方法如下:
2.1.3 预测层
为了缓解获取用户的最终偏好表示,将嵌入层得到的向量表示作为用户的长期偏好,而通过注意力机制训练聚合得到的向量表示作为用户的短期偏好,将用户的长期和短期偏好通过门控循环神经网络训练得到用户的最终偏好表示,再利用内积的方法得到用户对项目的偏好概率值生成推荐列表。门控循环神经网络(gated recurrent neural network)还可以有效解决用户偏好的长期依赖性问题。门控单元GRU如图4所示,主要通过重置门(reset gate)和更新门(update gate)来控制用户信息的流动。

图4 门控循环神经单元Fig.4 Gated recurrent unit
将嵌入层的用户偏好向量与注意力层的短期偏好向量输入到GRU 中进行训练,在GRU 单元中,更新门Zt的作用是对历史信息进行选择传递,用来控制当前时刻输出的状态ht中要保留多少历史状态ht-1,而重置门Rt的作用是选择信息遗忘,用来控制历史状态ht-1的信息不能传入状态ht。
其中,σ为激活sigmoid函数,ut为输入向量,Wz、Wr为更新门和重置门的权重参数,bz和br为偏置参数。
重置门的作用是重置记忆信息,直接利用隐藏单元记录历史信息,候选隐藏状态表示对上一时刻的状态1的依赖程度,计算公式如下:
其中,σ为激活tanh函数,ut为输入向量,Wh为重置门的权重参数,为偏置参数。
更新门用来计算当前时刻隐藏状态的输出ht,隐藏状态的输出信息是前一时刻的隐藏状态信息ht-1和当前时刻的候选隐藏状态控制的信息传递,计算如下:
根据嵌入层用户历史交互数据训练得到用户的长期偏好表示,将用户的长期偏好表示uL与短期偏好表示uS通过GRU 模型训练,取一层隐藏层,并进行归一化处理,得到用户的最终偏好表示u:
其中,σ 为激活softmax 函数,W4为协同循环神经网络权重参数,b4为偏置参数。
最后将用户向量u和待推荐项目向量v内积得到用户偏好的概率值,并根据概率值进行排序生成推荐列表。
2.2 联合学习
为了将推荐系统与知识图谱相结合,本文提出一种端到端的联合学习框架,通过联合训练知识图嵌入和协同过滤算法的损失函数来同时获得推荐系统(用户、项目)和知识图谱(实体、关系)中各元素的嵌入向量表示。
本文提出模型的整体损失函数是知识图谱部分的损失函数与推荐部分的损失函数加上正则化项,计算如下:
注意这里KG 与CF 部分的损失函数如下:TransR训练要考虑有效三元组和无效三元组的相对顺序,为了优化模型中参数,使用BPR推荐算法中的损失函数学习模型中存在的参数[24]。
其中,(h,r,t′)代表通过随机替换有效三元组中的一个实体而构造的无效三元组;Ω代表数据集中的数据,θ代表模型中可训练的参数,λ代表正则化项的超参数。采用Adam 优化算法来优化参数[25],使得计算局部最优解更加迅速。
3 实验分析
为了验证AKGCF 模型的有效性,将提出的模型在MovieLens-1M和Amazon-Book两个公开数据集上进行实验,通过实验结果进行分析验证。
3.1 实验数据集
实验中使用的数据集,分别是电影领域和购物领域两个公开真实的数据集。
MovieLens-1M:是在电影推荐中使用最多的数据集,其中包括6 040 个用户和大约3 900 部电影,根据用户对电影的显式评分(分值为1~5间的整数)构成约100万个用户对电影的评价,稀疏度为95.81%。
Amazon-Book:是在购物推荐中使用最多的数据集,是Amazon-Review 数据集中的子集,该数据集包括8 026 324 个用户和2 330 066 本书籍,根据用户对购买书籍的显示评分(分值为1~5间的整数)组成约2 000万个用户对购买书籍的评价,稀疏度为99.7%。
由于上述两个不同的数据集在稀疏度和规模大小方面互不相同,为了实验的顺利进行,需要对数据集进行处理。首先,将两种显式反馈数据集中用户对项目的评分转换为0或1的隐式交互数据,并使用正例交互(评分大于3)进行训练和测试。其次,在MovieLens-1M中,使用评分大于等于3 的项目数据,获得最终数据集,6 040 个用户3 629 部电影组成的836 478 次交互;在数据集稀疏性较大的Amazon-Book 中,根据时间筛选出2014年2月到7月之间的交互数据,并通过10核过滤的方式来保证质量,获得最终数据集,11 978个用户11 042本书籍组成的286 507 次交互。最后需要为每个数据集构建项目-实体之间的链接,对于MovieLens-1M 和Amazon-Book两个数据集,通过ID匹配的方式,建立相关的知识子图。MovieLens-1M和Amazon-Book两个实验数据集的统计如表1所示。
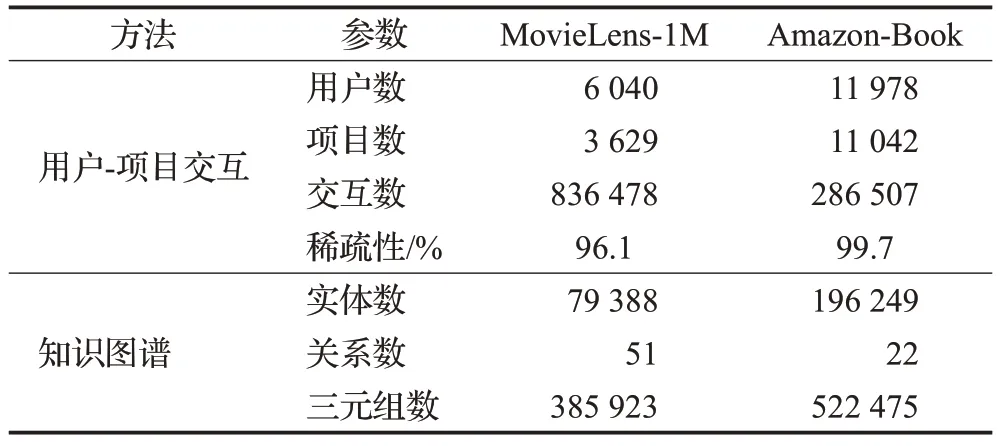
表1 实验数据集的统计Table 1 Statistics of experimental datasets
3.2 实验评价指标
在实验中,对用户u使用推荐算法所产生的物品集合I={i1,i2,…,in},其中表示用户u产生的第n个推荐物品。定义ir为用户在测试集中真实选择过的历史项目集合,I为用户在测试集所有测试集合。使用Precision@N、Recall@N、Hit@N、NDCG@N指标来评估Top-N推荐的性能。
准确率是当前推荐算法所产生的推荐项目中用户偏好项目所占的百分比:
召回率是一种计算所有相关项目中相关项目分数的方法:
命中率是一种计算在N大小的排名项目列表中有多少个命中的方法。如果至少有一项在I中称为一次命中:
归一化折损累计增益是为了让排名靠前的结果能影响靠后的结果。其中reli代表i这个位置上的相关度,按照相关性大到小的结果排序,取前p个结果组成的集合。
3.3 基准算法及实验设置
本次实验使用以下基准算法:
(1)FM[7]:一种基于矩阵分解的机器学习模型,可以自动学习两个特征间的关系,但无法学习多个特征之间的关系,对于稀疏数据具有较好的学习能力。
(2)CKE[26]:一种基于协同过滤的推荐系统,利用知识图谱学习特征,在协同过滤的框架中整合多方面辅助信息,利用TransR算法中的语义嵌入来增强矩阵分解。
(3)KGECF[27]:一种基于知识图谱的推荐模型,从知识图谱中提取与项目相关的知识信息,并与历史交互项目进行链接,构建子知识库,设计一种端到端的联合学习模型。
(4)KGCN:一种图卷积网络的推荐模型,通过计算头实体和尾实体在关系空间的距离来聚合邻居信息进行推荐。
(5)KGAT:一种基于图的推荐模型,利用注意力机制计算知识图谱中的头实体和尾实体在空间中关系的距离,并通过聚合机制得到用户项目的最终表示,通过内积的方式进行推荐。
将本文提出的AKGCF模型在Python3.6、PyTorch1.7环境下完成与基准算法的对比实验。为了实验的顺利进行,首先根据用户维度来构建训练集、验证集和测试集,并按照8∶1∶1 的比例对数据集进行划分。AKGCF模型超参数的设置如表2 所示。其次将模型学习轮数(epochs)设置为300,训练时如果评测指标的数值在验证集上10轮内无明显变化则训练停止。为了证明AKGCF的有效性,设置基准算法嵌入维度、学习率、批量处理大小以及正则系数的参数值与AKGCF 算法相等,其他超参数默认值与原始论文一致。针对Top-N的推荐任务,将N设置为{5,10,15,20,25,30,35,40,45,50}。实验目的是为待推荐用户在测试集中推荐排名前N个项目,并使用评价指标Precision@N、Recall@N、Hit@N、NDCG@N来评估模型的性能。
3.4 实验结果分析
3.4.1 与基线算法比较
在实验中,推荐个数的不同会影响推荐效果,设置不同的Top-N进行实验。为了更好地分析AKGCF模型与基准算法的评价指标结果,将推荐个数N值分别设置为{5,10,15,20,25,30,35,40,45,50},并在MovieLens-1M和Amazon-Book两个数据集上进行实验,Precision@N与Recall@N的指标如图5、图6所示。
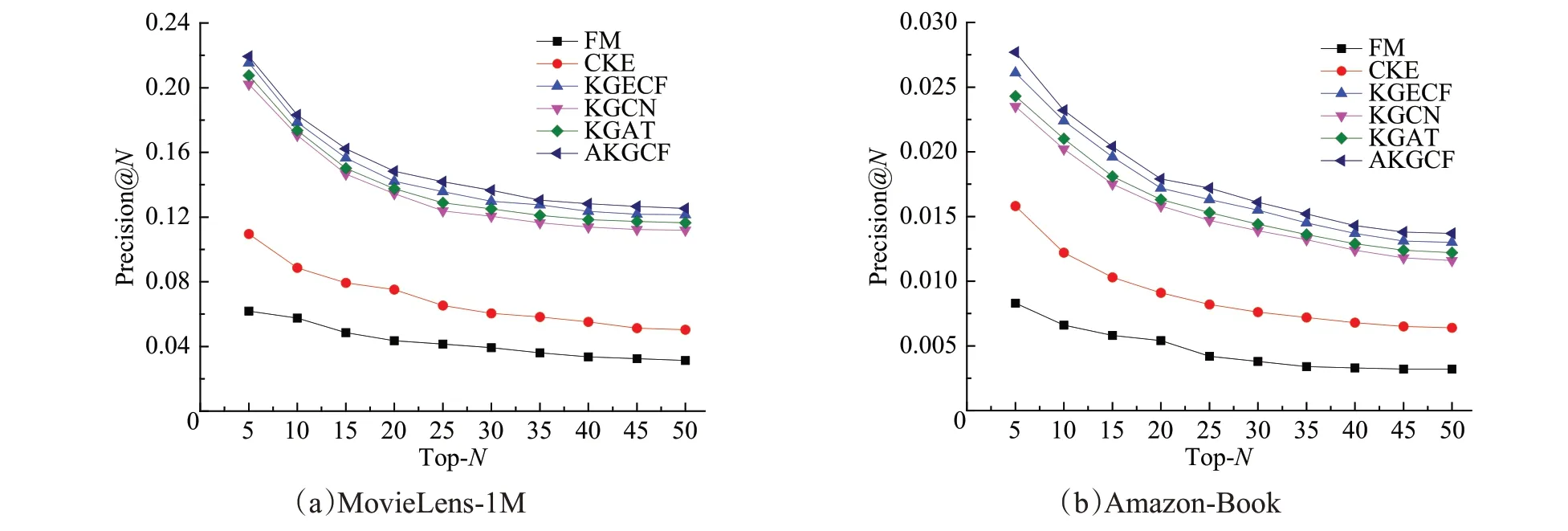
图5 AKGCF与基准算法准确率的比较Fig.5 Comparison of accuracy between AKGCF and benchmark algorithms

图6 AKGCF和基准算法召回率的比较Fig.6 Comparison of recall between AKGCF and benchmark algorithms
由图5、图6可知,AKGCF和基准算法的Precision@N值与Top-N推荐成反比;AKGCF和基准算法的Recall@N值与Top-N推荐成正比;当推荐个数不断增加时,所提算法和基准算法的准确率和召回率都趋于稳定。在MovieLens-1M 与Amazon-Book 数据集上AKGCF 相比FM、CKE、KGECF、KGCN、KGAT 这5 个基准算法的Precision 与Recall 评价指标均有提升,证明了本文所提算法AKGCF的有效性。
对实验结果进行分析,基于矩阵分解FM的推荐模型性能表现不佳,而基于知识图谱的推荐模型性能均高于基于矩阵分解FM 的推荐,可知利用知识图谱作为辅助信息进行推荐可以有效地提高推荐性能。CKE、KGECF、KGCN、KGAT都是基于图的推荐算法,CKE采用TransE 方法学习知识图谱中的信息,推荐性能较弱,表明TransE 不能有效地学习知识图谱中的信息。KGCN与KGAT推荐性能较好,KGCN模型在聚合邻居信息时计算用户对知识图谱中的关系信息,但是忽略了引入实体信息的影响,KGAT模型虽然通过计算头实体和尾实体在空间中关系的距离来聚合实体信息,但是忽略了用户的信息影响。KGECF 与AKGCF 推荐性能较为接近,都是利用知识图谱作为辅助信息结合协同过滤方法进行推荐,有效提高了推荐的性能。本文所提方法AKGCF不仅利用注意力机制有效挖掘知识图谱中高阶关系信息进行聚合,还结合用户的长期与短期偏好,通过门控神经网络进行训练,获取用户最终偏好进行推荐,提高了推荐的准确性。
3.4.2 嵌入方法对推荐的影响
为了验证知识图嵌入方法对AKGCF 推荐结果的影响,分别采用TransE 与TransR 两种方法对结构化知识进行建模,将实体与关系参数转化为向量表示。在MovieLens-1M数据集上进行Top-N推荐实验,其中N={10,20,30,40,50},利用Precision作为评价指标进行评估,实验结果如图7所示。

图7 嵌入方法对比Fig.7 Comparison of embedding methods
由图7可知,TransE方法的推荐效果低于TransR方法。由于实体是多种属性的综合体,不同关系关注实体的不同属性,而不同的关系拥有不同的语义空间,TransE方法对处理复杂关系的实体具有局限性,而TransR可以利用特定的关系矩阵来将实体和关系映射到不同的语义空间中,并在对应的关系空间中进行实体与关系的建模。因此本文利用TransR 方法将实体与关系参数转化为向量表示,提高了推荐算法的性能。
3.4.3 验证注意力机制与GRU对推荐的影响
为了验证引入注意力机制捕捉知识图中的潜在信息以及结合用户长短期偏好通过GRU训练对推荐结果的影响,首先构建KGCF 模型,直接由嵌入层得到的偏好向量通过GRU 训练得到用户最终偏好进行推荐;其次构建AKG 模型,只利用注意力机制学习知识图中的高阶信息得到用户偏好表示进行推荐;最后将上述两个模型与本文所提AKGCF模型与基准模型KGAT进行实验对比分析。根据召回率和准确率的实验结果可知,随着推荐个数增加,评价指标相对稳定,因此设置推荐个数N={10,20,50},并使用Hit、NDCG作为评价指标,并在MovieLens-1M数据集上进行实验,结果如表3所示。

表3 各方法在MovieLens-1M上的实验结果Table 3 Experimental results of each method on MovieLens-1M
对实验结果分析可知,KGCF 推荐效果表现不佳,表明知识图中实体间的潜在信息关系会影响推荐结果;而AKG指标略高于基准算法KGAT,主要因为KGAT忽略了知识图中用户关系信息对推荐的影响,而AKG 模型通过注意力机制捕捉知识图中潜在关系信息,综合考虑了各个实体间的潜在关系并聚合得到用户偏好进行推荐,可以得到较好的推荐结果;而本文所提AKGCF推荐效果最优,其不仅通过注意力机制来捕捉知识图谱中的潜在关系信息,还综合考虑用户长短期偏好对推荐结果的影响,通过结合用户的长短期偏好,利用GRU网络训练可以得到更精准的用户偏好进行推荐,获取更优的推荐结果;通过AKGCF 与基准模型KGAT 进行对比分析,当推荐个数为10时,AKGCF相对于基准模型KGAT在MovieLens-1M 数据集上的评价指标Hit 与NDCG 分别提高了1.11%、2.69%,当推荐个数为20时,Hit与NDCG分别提高了1.11%、4.43%,当推荐个数为50时,指标Hit与NDCG 分别提高了1.79%、1.81%,证明了AKGCF 算法的有效性与合理性。
3.4.4 向量嵌入维度数的影响
根据之前的研究发现,向量嵌入维度数会影响模型的推荐效果。为了研究知识图谱中实体、关系嵌入维数k对推荐结果的影响,将k值分别设置为{16,32,64,128},在MovieLens-1M 和Amazon-Book 上进行实验。当推荐个数为10时,根据评价标准Recall@10和NDCG@10的结果对模型进行评估,其他参数值保持不变。AKGCF在向量嵌入维数下Recall@10 和NDCG@10 的结果如图8、图9所示。
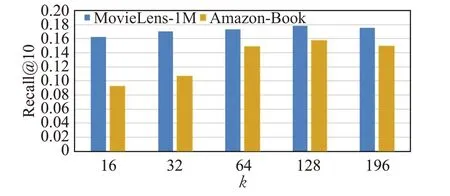
图8 不同维数下AKGCF的召回率比较Fig.8 Comparison of recall of AKGCF under different dimensions

图9 不同维数下AKGCF的NDCG比较Fig.9 Comparison of NDCG of AKGCF under different dimensions
由图8、图9 可知,当推荐数量为10 时,随着嵌入维数k的增加,AKGCF 在两个数据集上的两个评价指标都随之上升,当嵌入维数为128时,评价指标达到最佳,嵌入维数为192 时,指标随之降低,可见向量嵌入维数会影响推荐性能。对两个数据集进行对比分析,由于MovieLens-1M 和Amazon-Book 数据集的稀疏程度不同,模型的推荐效果也不同。根据实验结果发现,当嵌入维数为{16,32,64,128}时,随着向量嵌入维数的增加,在稀疏程度更高的Amazon-Book数据集上的实验结果表现更优于MovieLens-1M 数据集,表明在一定程度上,增加嵌入向量的维数,可以有效地捕捉知识图谱中的潜在关系信息,缓解了数据稀疏性对推荐性能带来的负面影响,提高了推荐系统性能,可以得到更好的推荐结果。
3.4.5 负采样率对模型的影响
以往的研究经验发现,负采样率会影响模型的推荐效果,为了研究负采样率对模型的影响,将负采样个数设置为{1,3,5,7,9},在MovieLens-1M和Amazon-Book上进行实验。当推荐个数为10 时,根据Recall@10 和NDCG@10的评价标准对模型进行评估,其他参数保持不变。AKGCF模型随着采样数的增多在两个数据集上的Recall@10和NDCG@10如图10所示。
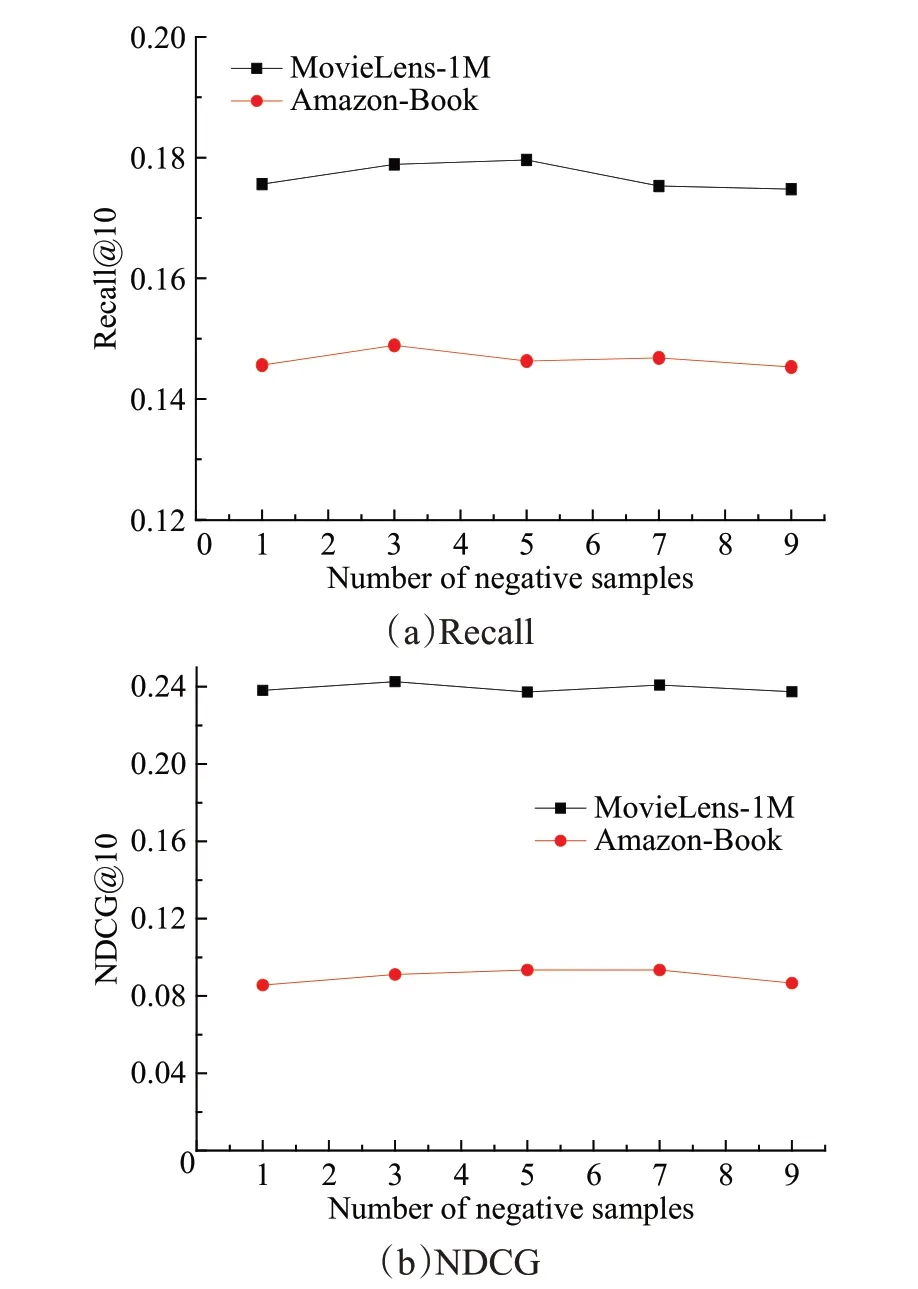
图10 负采样率对AKGCF模型Recall和NDCG的影响Fig.10 Effect of negative sampling rate on Recall and NDCG of AKGCF model
由图10分析可知,随着负采样个数的增加,AKGCF模型在两个数据集上有提升的趋势,推荐模型的效果逐渐变好,但是当达到一定数量时,模型的推荐效果又会变差。由实验结果分析可知,当负采样个数为3 时,在两个数据集上Recall@10 和NDCG@10 的结果相对较优。在MovieLens-1M数据集上,当负采样个数为5时,Recall@10 的值最高,超过5 时,指标逐渐降低;当负采样个数为3时,NDCG@10的值最高,但是负采样个数超过3 时,指标会逐渐下降。在Amazon-Book 数据集上,当负采样个数为3时,Recall@10的值最高,超过3时,指标逐渐降低;NDCG@10 的变化趋势与MovieLens-1M的一致。
使用负采样策略不仅可以平衡正负样本比例,还可以提高训练时的运行效率,提升训练速度,减少训练时间,提高推荐系统的准确度。但是负采样的个数并不是越多越好,随着负采样个数的增多会影响推荐效果,使推荐鲁棒性变差,训练时间变长,不利于模型的训练。综上所述,该模型负采样个数的最佳范围为1到3。
4 结束语
本文提出了一种融合注意力机制与知识图神经协同推荐算法,利用知识图谱辅助进行推荐。首先根据用户与项目的历史交互数据构建知识图谱,并利用注意力机制来学习知识图谱中潜在关系信息并聚合得到用户短期偏好;同时结合用户的长期与短期偏好,通过门控循环神经网络训练获取用户最终偏好进行推荐,有效缓解了用户偏好的长期依赖性问题;最后利用协同过滤方法生成推荐列表。本文所提算法利用知识图谱辅助进行推荐,有效缓解了数据稀疏性和冷启动的问题,通过在MovieLens-1M与Amazon-Book两个数据集上进行实验,将提出的算法与FM、CKE、KGECF、KGCN、KGAT进行比较,并使用准确率、召回率、命中率和NDCG进行评估,实验表明本文提出的算法在两个数据集上的评价标准均优于基准算法,得到了更优的推荐结果。
AKGCF算法通过融合知识图与注意力机制来捕捉知识图谱中高阶关系并聚合邻居信息,该算法容易受噪声影响并缺乏对用户个性化偏好的使用,如用户购买时机等。在未来的研究中,需要考虑用户的个性化偏好的特征并进一步缓解数据稀疏性的问题。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
传媒评论(2017年3期)2017-06-13 09:18:10
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
领导科学论坛(2016年9期)2016-06-05 14:59:58
