
人工智能在功能磁共振成像数据中的自闭症研究综述
2023-11-27 05:34:46钱育蓉王兰兰陈嘉颖冷洪勇马梦楠
计算机工程与应用 2023年22期
顾 剑,钱育蓉,王兰兰,胡 月,陈嘉颖,冷洪勇,马梦楠
1.新疆大学 软件学院,乌鲁木齐830091
2.新疆大学 新疆维吾尔自治区信号检测与处理重点实验室,乌鲁木齐830046
3.新疆大学 软件工程重点实验室,乌鲁木齐830000
4.中南大学 计算机学院,长沙410083
5.北京理工大学 计算机学院,北京100081
自闭症谱系障碍(autism spectrum disorder,ASD)是一种广泛性中枢神经发育障碍,在美国精神障碍诊断与统计手册第5 版(MIDS-5)[1]中将其描述为:(1)社会-情感的缺陷。(2)非语言交际行为的缺陷。(3)理解、发展和维持关系的缺陷。在美国每54名儿童中就有一人被诊断出患有自闭症。2019年,中国发布的《中国自闭症教育康复行业发展报告Ⅲ》数据显示,中国有超过200万的自闭症儿童,患病率约为7%,严重危害儿童的身心健康,给整个家庭带来沉重的负担。中国国家卫健委于2022 年印发《0~6 岁儿童孤独症筛查干预服务规范(试行)》,旨在进一步改善自闭症儿童的身心健康。
相关研究人员强调了早期识别和早期干预对于提高自闭症儿童的语言、交流和健康水平的重要性。然而,由于部分地区医疗条件有限,无法及时诊断并完成干预工作。因此,采用相关人工智能方法加快自闭症智能辅助诊断的研究意义重大。机器学习、深度学习方法等先进技术以提高诊断的准确性、效率和质量为目的应用在该领域中,来提高临床医师对疾病的诊断效果。
1 研究概述
自闭症作为一种普遍的精神发育障碍,在过去几十年中急剧上升,而其成因却一直难以查明,因此越来越多的研究人员投入该领域的研究中[2]。该疾病的临床发病原因多为大脑活动异常,临床诊断多数方法是基于症状学的行为观察,这通常需要大量优质的医疗资源和长时间的观察,才能得出是否患病的结论。通常用ADOS、ADI-R 等量表进行筛查工作。该方法主要的缺点是消耗大量时间进行评估,易错过最佳治疗时间[3]。目前,各类研究人员通过各类实验方法来研究自闭症的最佳诊断方法,例如Liu等人[4]和Jaiswal等人[5]对自闭症患者的眼动、面部表情等行为数据进行识别诊断,Manoli等人[6]从基因组学的角度出发探索自闭症遗传性质。对于自闭症患者的行为、语言、基因等方面探索自闭症的发病机制仍存在一些局限性,因此需要通过其他方法对自闭症发病原因进行剖析。
近年来,医学影像技术和人工智能的快速发展为脑影像研究提供了一个新的方向。功能磁共振成像(functional magnetic resonance imaging,fMRI)是诊断自闭症的重要手段之一。同时,相关方法也广泛应用在精神类疾病的智能辅助诊断中,例如阿尔茨海默症、抑郁症、精神分裂症等精神疾病[7]。不同的神经成像工具已应用于自闭症的研究[8-9],大脑的功能和结构可以通过脑电图[10]、脑磁图[11]、功能磁共振成像[12]和弥散张量成像[13]等多种脑成像技术获得,这些脑成像技术有助于进一步研究大脑的功能和结构。利用相关人工智能技术充分分析发病生物标志物,可以帮助临床医生和神经科学家了解自闭症患者与正常人大脑之间的独特机制。通过磁共振成像扫描技术,医生可以了解患者大脑中不同区域活动程度的变化,从而更好地理解患者的症状和行为[14]。
基于功能磁共振成像技术在医学领域广泛应用于脑部疾病检测。fMRI技术具有无侵入性,高空间、时间分辨率,能够较好地反映不同脑区之间是否存在问题,在自闭症患者的临床早期检测中使用fMRI技术越来越重要。在fMRI的研究中,基于静息态功能连接(rs-function connectivity,rs-FC)展示出不同大脑区域测量的血氧水平依赖(blood-oxygen-level dependent,BOLD)信号的空间和时间相关性,这为脑部疾病的研究开辟新的方向。Anderson 等人[15]于2011 年首次采用功能连接作为特征并通过机器学习方法进行研究,Nielsen等人[16]以此为基础进一步研究,相关研究证明功能连接是探索脑疾病发病机制的关键因素,并具有为疾病诊断提供生物标志物的巨大潜力[17-18]。
机器学习、深度学习相关人工智能方法可以为自闭症的研究和临床诊断提供补充信息并输出预测值,并且可以根据正常人与患者大脑脑区之间的异常,客观地识别生物标志物[19]。经研究统计分析,基于fMRI 数据的智能诊断方法的一般过程如图1所示。首先,对磁共振成像机器所采取的数据进行预处理,对预处理之后的数据计算功能连接矩阵,并作为输入模型前的初始特征;其次,使用机器学习或深度学习等算法进行深层特征提取,得到较为重要的特征进行训练和验证,根据不同的评估指标评判模型的有效性和鲁棒性;最后,与其他模型对比分析其存在的优缺点,利用相关方法探索该疾病发病可能存在的生物标志物。通过以上手段,实现自闭症的人工智能辅助诊断,从而提高诊断效率和准确率。
Pagnozzi 等人[20]从结构、功能磁共振成像的角度总结ASD 智能诊断的方法,并且说明了ASD 个体和正常人大脑之间的区别。该研究主要促进人工智能应用在结构、功能磁共振成像模式的诊断中,叙述内容较为宽泛。Nogay等人[21]从脑成像技术方面介绍了相关机器学习诊断ASD 的文章,并且提出希望能通过机器学习技术开发实用的ASD 诊断工具。Parlett-Pellerit 等人[22]从无监督机器学习的角度对自闭症的诊断进行概括总结,分析了相关临床诊断数据和医学影像数据。由于人工智能方法迭代更新较快,针对该疾病的智能诊断方法有了较大的进展。相比于当前已刊出的文章,本综述主要优势在于总结近5年来基于fMRI数据的自闭症智能辅助诊断的方法,分析其特点,在前人研究的基础上全面分析各类方法当前的研究进展。本文的主要贡献如下:
(1)概述当前人工智能在fMRI 数据中自闭症诊断研究的背景、意义,总结出自闭症分类识别的一般过程。
(2)着重探索基于fMRI数据的研究,归纳总结了机器学习、深度学习中涉及自闭症智能辅助诊断的特征工程方法、模型算法,通过对比分析,得出不同方法的特点和局限性。
(3)总结当前自闭症智能诊断在数据量和模型研究中的局限性以及未来可能的研究趋势。
2 自闭症智能诊断中的挑战
使用人工智能方法,对fMRI 数据处理实现自闭症智能诊断是当前研究的重点之一,极大地促进计算机实现疾病智能诊断的发展。由于大脑的复杂网络结构以及技术的局限性,仍然存在一些不可避免的问题,将从以下三点说明人工智能技术在基于fMRI数据的自闭症诊断中面临的挑战。
(1)自闭症脑成像数据交换数据库(autism brain imaging data exchange,ABIDE)[23]是一个大型的公开数据集,其存储的大规模数据为加速对自闭症神经发病机制的理解带来极大的便利。该数据涉及17个不同站点的数据,由于患者人群、扫描设备的协议不同,导致数据之间的数据异构性、不平衡性剧增[24-25],这直接阻碍传统网络嵌入学习方法的应用。
(2)脑图谱是理解大脑、剖析大脑和全面认知大脑的基石,是衡量不同个体差异化的方法,越是精细化的图谱可以帮助医生及早地诊断疾病。脑图谱是划分大脑的重要因素,起着决定性的作用,一个合适的脑图谱将有利于大脑疾病的诊断。针对于不同脑图谱的构建方法,如何充分利用脑图谱之间的互补信息,提高智能诊断的效率和精确度是一个重要的挑战[26]。
(3)在基于fMRI 数据的ASD 预测研究中,大多数方法提取到的特征维数较高[27]。合理的特征选择方法可以降低样本的特征维数,避免过拟合的问题。由于有较多的特征点,如何选择重要的特征是一个亟需解决的重点问题。
3 基于fMRI数据的自闭症智能诊断方法
3.1 基于传统机器学习的自闭症检测
机器学习是一种数据驱动的方法,通过提取数据的特征,构建相关的模型来预测或分类未知的数据。在基于fMRI数据的自闭症智能诊断中,机器学习从fMRI原始数据中提取功能连接特征并建立区分正常人和患者的模型,主要包括数据预处理、特征提取、模型的选择和训练、模型的评估等内容。本节主要从数据预处理及特征提取、不同算法的角度进行详细概述。
3.1.1 数据预处理及特征提取
当前,基于fMRI 数据的自闭症智能诊断研究中数据的来源通常是网络已公开的数据库,主要包括ABIDE-I、ABIDE-Ⅱ等相关数据。本文主要从ABIDE-I数据集方面探讨当前自闭症智能辅助诊断任务的进展。该数据集包含17个不同站点的数据,共有1 112名受试者的数据(539 名患者和573 名健康人),包括丰富的临床信息,例如年龄、性别、智力水平、惯用手等其他相关信息。该数据集为自闭症的研究提供一个重要的数据来源和研究对象,为未来自闭症的研究做出更深层次的贡献。
基于fMRI 数据的自闭症研究中,其脑影像数据的预处理过程主要包括切片计时校准、头部运动校正、数据标准化、空间平滑等操作,通过以上步骤得到不同脑区的时间序列[28]。对该数据利用皮尔逊相关系数计算相关脑区之间的强度,即功能连接,用来作为输入模型的特征。以HO 脑图谱的预处理为例,首先将HO 脑图谱大脑划分为111 个脑区,即定义为111 个大脑感兴趣区域(region of interest,ROI),求取ROI 中所有体素的平均值,从而获得平均时间序列,利用皮尔逊相关系数计算该脑图谱的ROI之间的功能连接,得到功能连接矩阵,将其作为预测模型的输入实现分类预测,整体流程如图2所示。
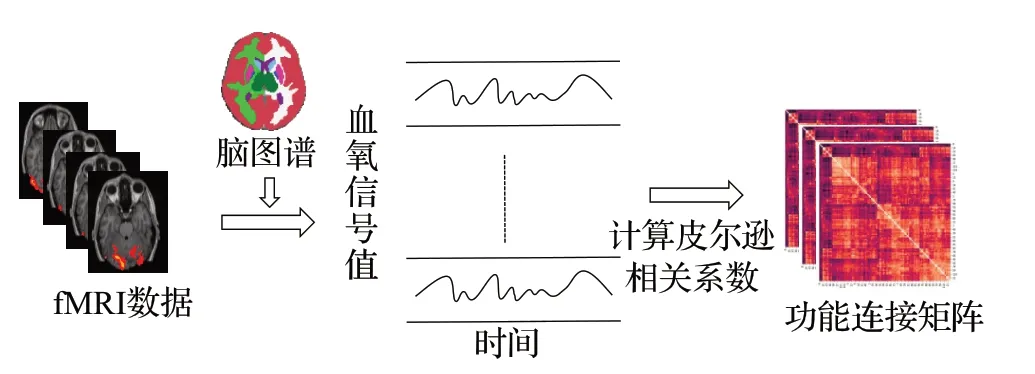
图2 数据预处理框架图Fig.2 Data preprocessing frame diagram
3.1.2 基于不同算法的自闭症检测
经文献调查研究,常用于该领域的方法主要包括支持向量机、随机森林等主流方法。表1总结了诸多机器学习方法对ASD分类的相关工作,着重介绍了研究人员提出的方法,并分析其特点和局限性。Parikh等人[37]、Plitt等人[38]通过各类机器学习实现特征工程与疾病预测,通过多项对比实验验证机器学习模型在该领域中的适用性。
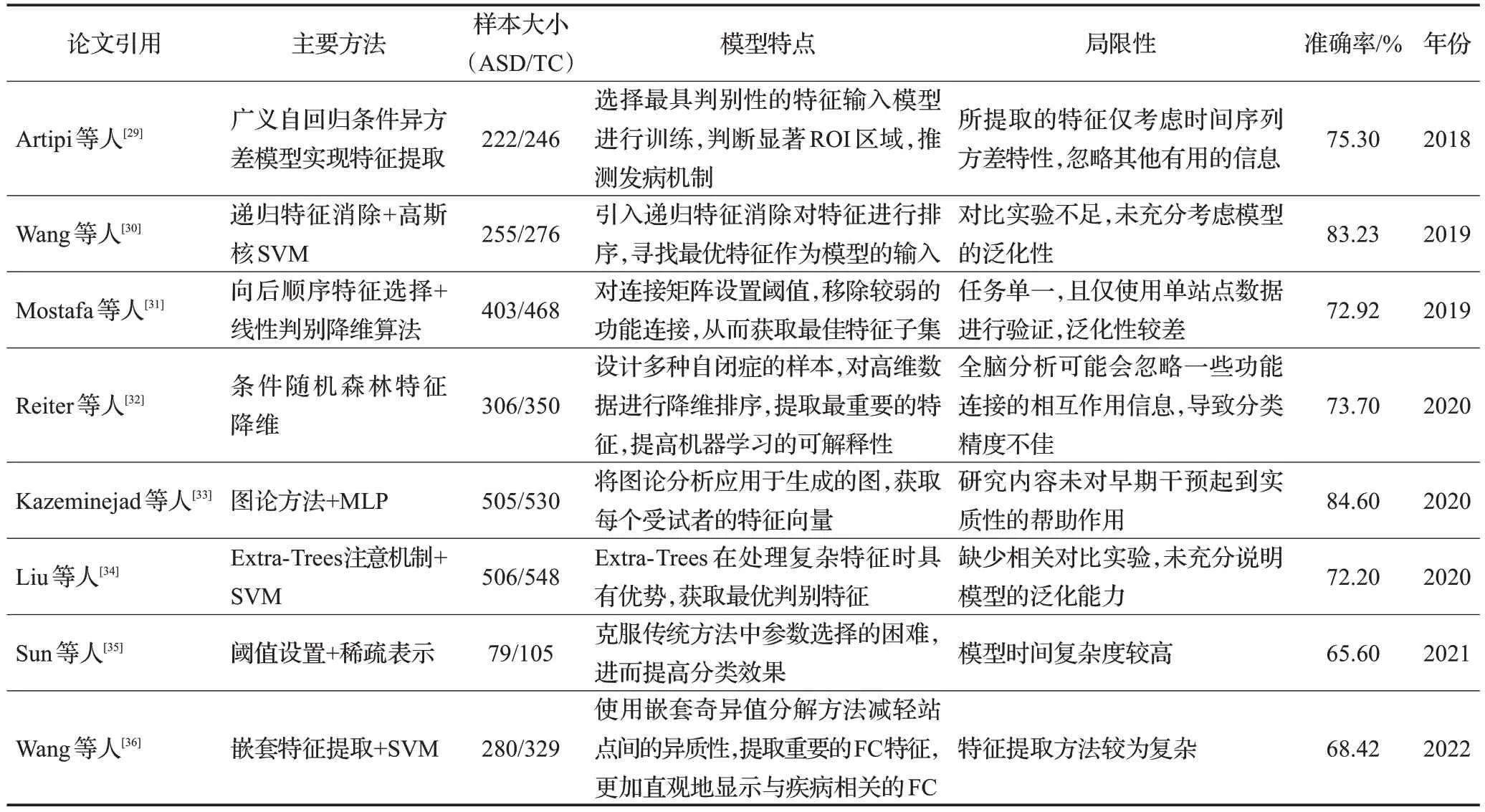
表1 机器学习方法Table 1 Machine learning methods
在机器学习中,特征的构建和选择至关重要,算法的选择和改进同样非常重要,二者缺一不可。在基于fMRI 数据的自闭症检测中,研究者们对于算法的研究旨在利用特征以提高检测的性能,解决数据量少、数据不平衡等现实问题。经典的检测手段时效性较差,原因在于需要进行多次测量而不断评估才能下最终结论,这一过程往往需要耗费较长时间。考虑到这一问题,许多学者对自闭症早期检测进行研究。Emerson等人[39]依据遗传学因素,对59名具有自闭症家族风险的6个月大婴儿进行前瞻性预测,预测其成长过程中是否会患有自闭症。Spera 等人[40]针对6~13 岁男童分析发病机制,计算时间序列对之间的相关性进行判别,实现诊断任务。多项研究表明对早期风险评估以及开发针对自闭症的早期预防干预措施具有重要临床意义,也是该疾病探索最根源的需求。
支持向量机(support vector machine,SVM)是一类按照监督学习的方式对数据进行二元分类的广义线性分类器。SVM可以解决小样本情况下的机器学习分类和回归问题,已广泛应用于医疗辅助诊断领域中[41]。例如:Chen等人[42]对126个ASD患者和126个正常人的小样本数据上进行研究,通过提取不同频段的数据特征,将其输入到预测模型SVM中。实验表明自闭症发病机制与大脑默认网络、视觉和皮层下的有关区域特征最为显著,发现大多数分类权重集中在Slow-4频段,表明自闭症的生物标志物的分布区域是极为复杂的,并且和全局大脑有关。
随机森林(random forest,RF)是利用多棵树对样本进行训练的一种分类器,该算法随机选择特征数目及训练数据,对同一个数据出现最多的标签为最终预测结果。由于fMRI数据维度较高,Katuwal等人[43]构建随机森林树,对fMRI 数据降维提取特征,发现依靠性别、症状严重程度、年龄、认知能力和其他变异因素进行分类。该方法对查明ASD的非典型脑特征至关重要。由于RF方法过拟合现象较为严重,功能随机森林在构建决策树时,每个节点选择一个特征集合进行划分,而不是选择所有的特征进行划分,Feczko 等人[44]提出改进的RF 分类模型识别自闭症患者中的认知亚型,通过评估特征的重要性潜在地解析受自闭症影响的大脑机制的变化。
总体来看,在利用传统机器学习进行自闭症检测上,特征的构建和选择已经较为成熟。Thabtah[45]的研究中强调传统方法的局限性,并提出需要解决的基本问题,包括数据异质性、诊断效率、特征选择方法等。由于当前的研究对于标记数据量较少、模型可解释性不足等现实问题探索较少,在未来的研究中应着重加强。
3.2 基于深度学习的自闭症检测
传统的机器学习方法需要人工构建大量特征,但是构建有效的特征需要耗费研究者的大量时间和精力。深度学习的起源可以追溯到1940 年[46],2006 年Hinton等人[47]提出深度学习的概念。在诸多研究中,尤其是拥有大量数据的情况下,深度学习往往能够表现出较好的性能。与传统机器学习方法相比,深度学习增强学习能力,更有效地利用数据进行特征提取。在深度学习领域中,自闭症诊断的特征提取、分类模型应用广泛。本文将从经典的深度学习方法、基于Transformer的方法、图神经网络三方面进行详细概述。
3.2.1 经典深度学习的自闭症检测
深度学习应用在自闭症诊断中较多,近年来非常流行。本文主要介绍较为经典的深度学习方法,其中主要包括自编码器、卷积神经网络以及其他深度学习模型,如表2所示。
自编码器(auto-encoder,AE)是人工神经网络(artificial neural network,ANN)的一种形式,是一种无监督神经网络,由编码器和解码器两部分构成[62]。由于AE 强大的数据降维和特征提取的能力,2018年Heinsfeld等人[63]使用两个堆叠自编码器(stacked auto-encoder,SAE)模块训练预测模型,使用多层感知机(multi-layer perceptron,MLP)进行微调输出分类结果。研究表明,深度学习可以更可靠地对大型多站点数据集进行分类。考虑到数据不平衡的问题,Eslami 等人[64]在AE 的基础上加入SMOTE(synthetic minority oversampling technique),从而克服数据类别带来的性能损失。为充分研究脑部疾病的空间分布和细微的神经解剖学变化,Pinaya 等人[65]构建深度自编码器在重建误差的基础上诊断自闭症患者和正常人脑区的差异。结果表明,深度自编码器对于评估神经疾病患者大脑的区域神经解剖学提供了一个具有发展前途的深度学习框架。由于单脑图谱信息单一,不同的图谱之间会存在相互补充信息,Wang等人[66]提出一种基于多脑图谱和去噪自编码器的自闭症分类方法,以三种脑图谱提取的功能连接作为特征,使用去噪自编码器进行权重预训练,利用图谱概率加权的方式整合分类结果。结果表明,使用多图谱进行自闭症分类任务是可行的。
卷积神经网络(convolution neural network,CNN)[67]是一类包含卷积计算且具有深度结构的前馈神经网络,它在特征提取和建模上都有着相较于浅层模型的优势,从原始数据中挖掘出来具有代表性的深层特征,是深度学习的代表算法之一。为充分提取fMRI数据的三维空间特征和一维时间特征,Thomas等人[68]采用3D-CNN模型和集成学习的策略,利用fMRI 数据的全分辨率三维空间结构,构建适合非线性预测的模型,克服传统机器学习方法特征提取的局限性。最佳的特征子集是研究自闭症发病机制的关键因素,Ronicko 等人[69]采用偏相关和完全相关方法分析fMRI 数据中的功能连接,使用条件随机森林的条件排列方案计算变量重要性度量并揭示每个特征的实际影响,在深层构建特征后输入CNN 建立分类器模型,实验表明CNN 可以提高异构数据的诊断结果。
3.2.2 基于Transformer的自闭症检测
随着深度学习的纵深发展,2017 年由Google 团队提出强大的Transformer[70]方法。Transformer 核心的思想在于多头注意力机制,对应于输入序列的不同位置以计算该序列的表示能力。fMRI数据自身包含空间和时间两类信息,Deng 等人[71]提出时空Transformer 架构分层提取空间信息和时间序列信息。由于Transformer无法解决数据不平衡问题,在该模型中引入基于高斯GAN的数据平衡方法。实验表明以时间和空间两种方式进行多层次特征提取能够更加有效地识别自闭症。
由于fMRI数据包含较强的时间序列信息可以识别大脑活动异常的区域,其位置信息的表示能力非常重要,Jha 等人[72]利用Transformer 强大的建模能力和对序列数据的处理能力,对fMRI 数据进行编码和处理。该方法由多头注意力和时间整合模块组成,实现更为准确的自闭症诊断,实验表明该方法具有较高的效率和鲁棒性。为了解决fMRI 数据空间特征提取不足的问题,Yang 等人[73]提出Transformer 和3D-CNN 的深层特征提取特征方法。该方法不仅能够分析大脑功能网络间和功能网络内之间的关系,还利用通道注意力机制校准卷积层提取空间特征,从而实现自闭症的智能诊断。实验表明带有注意力机制的模型能够充分学习到fMRI数据所包含的空间特征,并且证实了注意力机制的有效性。
由于解决单一脑图谱诊断的局限性,Niu 等人[74]结合多脑图谱特征提取和受试者的五类表型信息,构建多通道深度注意力神经网络提取特征并实现预测任务。实验表明通道多通道注意力机制可以学习多个图谱的重要信息,并根据不同的数据自适应地调整每个通道的权重,这使得网络能够更好地处理不同图谱数据,具有很好的鲁棒性和泛化性。
注意力机制在自闭症的诊断中主要是利用强大的序列建模能力和对时间序列数据处理的能力,对fMRI数据进行编码和处理,以此来提高自闭症预测的准确率。由于现有文章较少,需要更多的实验验证其在自闭症诊断中的性能和泛化能力。
3.2.3 基于图神经网络的自闭症检测
传统的机器学习和深度学习方法更多地应用在处理欧式数据,图结构是机器学习领域中一种独特的非欧几里德数据,具有强大的表示能力[75];此外,图数据的结构与脑网络的拓扑结构相似,因此将图神经网络应用在脑疾病的诊断中是极为必要的。相关方法如表3所示。图卷积神经网络(graph convolution neural network,GCN)将卷积运算推广到图数据中[76],根据更新方式的不同分为基于谱域和空间域两种方法。2017年,Parisot等人[77]首次将基于谱域的GCN方法应用在自闭症的分类任务中,将种群表示为稀疏图,以节点表示受试者,边权重表示各节点之间的关系。该方法充分使用受试者fMRI数据和表型数据,为相关研究者奠定良好基础。
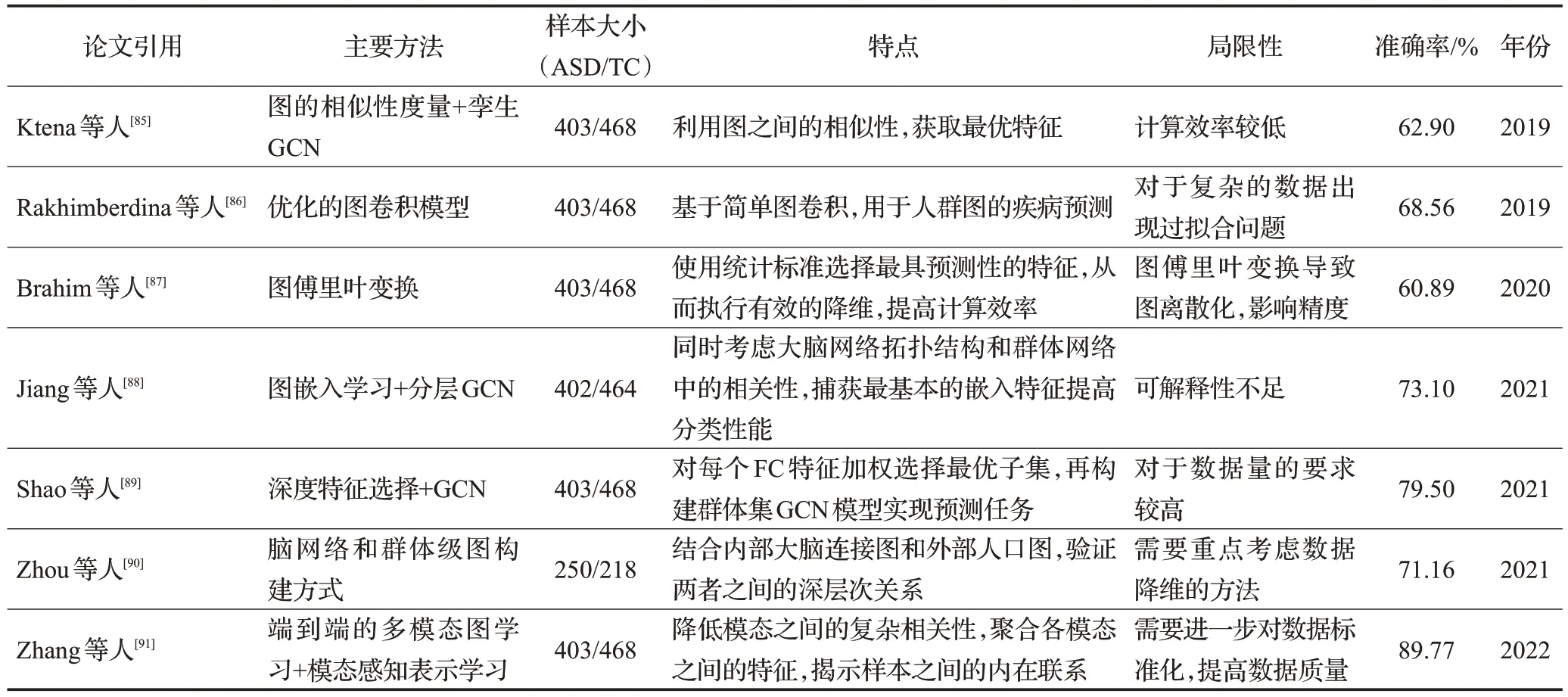
表3 基于GNN的自闭症检测方法Table 3 Autism detection methods based on GNN
Parisot提出的方法具有开创性的作用,但其实验未充分考虑不同站点之间的数据异质性、受试者之间类别数量不平衡的问题。Kazi 等人[78]通过设计具有不同内核大小的过滤器来构建模型架构,能够在卷积过程中捕获图内和图间的结构一致性,降低数据之间的异质性,进一步提高图在脑网络结构中的应用。Felouat 等人[79]使用基于图论的复杂网络分析来表示大脑连接网络的全局和区域拓扑结构,使用拓扑结构和GCN 来创建有助于分类任务的图相关特征。
由于缺乏功能脑网络对于GCN 的影响,模型缺少可解释性,不能通过模型揭示发病机制的生物标志物。Wen等人[80]提出的多视图图卷积网络,以端到端的方式学习大脑网络的有效表示,将图结构学习和图嵌入学习相结合,以提高分类性能。通过该方法研究得出的功能子网络与其他神经影像学得出的生物标志物高度一致,证明通过图结构的学习是具有可解释性的。由于GCN的过平滑问题,大多数基于GCN 的研究处于浅层网络中。为解决图神经网络过深导致的过拟合和过平滑的问题,Cao 等人[81]通过使用深度GCN 模型改进分类器,在模型训练时随机删掉原始图中的边,从而避免梯度消失、过拟合和过度平滑的问题,但是该模型时间复杂度较高,不符合临床应用的高效性,需要进一步优化该方法。
注意力机制已经被广泛地应用到基于序列的任务中,优点是能够放大数据中最重要部分的影响。现有的GCN 方法未达到高度的融合,只是简单地结合成像和非成像数据,并且多数GCN使用浅层结构,使得学习潜在的特征具有挑战性。基于此,Pan等人[82]提出MAMF-GCN方法,利用多通道的相关性融合多模态下不同图谱的特征,应用深度GCN 从更丰富的隐藏层中提取信息。该研究结果表明在现有的节点分类的性能上优于许多现有方法。
不同的脑图谱构建对大脑区域划分不同,样本与样本之间存在紧密联系,不同样本之间的影响需要被充分考虑。Yao等人[83]提出一种用于脑功能连接网络分析的多尺度三元组GCN,利用多脑图谱提取到受试者的多尺度信息,提高分类的准确率。Wang 等人[84]提出基于多图谱GCN的方法,利用6种脑图谱互补信息以及站点和性别信息构建图结构,利用GCN 可以提取样本间关联性的优势进行自闭症分类任务,进一步提高ASD 诊断的精度,在该研究中同时推测出4个生物标志物可能是自闭症发病的因素。在大多数多图谱的研究中,多图谱之间可以互相补充信息,但是数据预处理较为复杂,易受到数据集的干扰。
3.3 小结
目前,人工智能在自闭症的智能辅助诊断中,主要包括机器学习和深度学习两种方法。在智能诊断中,大脑功能异常检测技术在当前医学临床应用中仍处于初级阶段,通过机器学习、深度学习的方法进行人工智能辅助诊断已经取得不错的成果。一般情况下,首先进行数据处理,然后进行特征提取和选择,根据不同的方法提取特征,在下一阶段,使用多个分类器对提取的特征进行分类识别。
相比于传统量表、行为观察识别方法,机器学习可以自动检测数据中存在的模式,处理复杂的非线性数据。针对于机器学习应用在自闭症智能诊断任务的主要优点有:(1)处理小样本数据时,可以快速分析数据,提高工作效率,具有较好的性能。(2)可以根据脑区之间的异常判断发病机制。但是使用机器学习方法进行的研究也暴露出其缺点:(1)当样本量较大时,来自不同受试者的fMRI 数据进行辅助诊断任务时,效果会显著下降。(2)机器学习不同算法的模型泛化性能较差,不能充分应用在其他研究对象中。
与传统的机器学习方法相比较,深度学习方法应用一系列复杂的算法,可以利用不同复杂度的层次结构直接从原始数据中学习到最优策略,具有更强的学习和分析能力[92]。针对于深度学习应用在自闭症智能诊断任务的主要优点有:(1)处理大型多站点数据和不同脑图谱之间的数据时,可提取深层次重要特征,提高诊断性能。(2)针对数据异质性较高的情况,可适应不同的数据分布和噪声的干扰,提高诊断的鲁棒性。(3)结合fMRI数据和表型信息,进一步使用可解释性的智能学习方式探寻自闭症发病机制。(4)可以对不同模态的数据进行融合,构建分类更加准确的模型。深度学习应用自闭症诊断中,仍有一些局限性不可被忽略:(1)对于单站点较少的数据量,导致模型欠拟合,难以得到较好的评估指标。(2)自闭症是一种高度异质性的神经发育性障碍疾病,因此对于自闭症的诊断和治疗需要综合考虑多种因素。深度学习模型往往只能从特定的数据中学习特征,无法涵盖更多可能的因素。(3)深度学习模型的可解释性是一个重点和难点的问题,难以解释模型的决策过程,给在临床应用中的诊断和治疗带来的困难。
综上所述,机器学习和深度学习方法在自闭症智能诊断中具有一定的优点和局限性,需要在实际应用中充分考虑其优缺点并进行合理的选择和使用。
4 挑战与展望
本文首先介绍基于fMRI数据自闭症智能诊断的背景意义、智能诊断的一般过程及相关研究成果,并对相应的机器学习、深度学习方法进行全面的概述。计算机技术的革新给医学影像智能诊断的发展带来了极大的便利,大多数智能诊断方法都取得了较好的效果,并且成功探索自闭症发病相关的脑区,为寻找病因打下了良好的基础。
本文主要总结近5年来基于fMRI数据自闭症智能诊断的相关方法,分别讨论机器学习方法和深度学习方法在该领域中的应用及其不同模型的优劣势。这项工作有利于以后脑影像学智能诊断的研究,更加便捷地探索大脑疾病的发病机制,为神经疾病智能诊断的进一步发展提供参考。在对文献的总结、分析中,进一步分析ASD智能辅助诊断存在的问题,主要包括:ASD数据集中包含的数据量较小、研究模态较为单一、未充分考虑ASD相关亚型、模型的可解释性不足、模型效率较低等。人工智能技术的快速发展,使得基于fMRI 数据的自闭症分类性能取得进一步突破。随着相关硬件、软件技术壁垒的突破,有望在未来中实现ASD的智能诊断,下面将从各方面详细说明研究趋势,如图3所示。
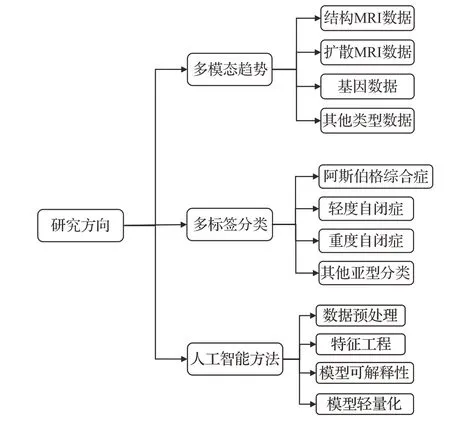
图3 研究趋势思维导图Fig.3 Research trending mind map
(1)扩充ASD数据集样本量
海量的数据是训练深度学习模型的基础,基于fMRI数据的自闭症智能诊断的研究中,部分人员仍采用ABIDE-I数据集。该数据集的体量在深度学习中属于较小的一类,并且数据较为不平衡。虽然现有研究方法通过数据增强、数据生成、分层交叉验证等相关手段解决该问题,但是也导致分析效率降低。因此,在下一步的研究中应将目光定位在如何构建大型数据集上,供更多的科研人员使用,进一步提高诊断效率和精度。
(2)基于多模态数据的研究
fMRI 数据和性别、年龄等表型数据是诊断神经疾病的重要因素,针对不同模态数据的特征融合研究可以显著降低自闭症的异质性[93-94]。因此在未来的研究中可以考虑加入sMRI、扩散MRI、基因、弥散张量成像等其他模态数据,利用注意力机制等方法提取重要特征来实现不同模态间的特征融合,构建最具鉴别性的特征集,实现更加精确的分类模型,准确识别潜在的生物标志物。
(3)基于多标签的自闭症诊断研究
目前,自闭症智能诊断研究内容主要是二分类问题,即是否患病。根据个体具体症状不同,自闭症其他亚型主要包括雷特综合症、非典型自闭症、阿斯伯格综合症等相关类型[95-96]。由于部分症状和特征可能会出现在不同的亚型中,导致亚型之间存在一定的重叠。因此,在未来的研究中,可以将几个亚型组合在一起研究,探索它们之间的共同点和不同点,不仅可以加深对ASD的神经生物学发病机制的理解,还可以促进个性化治疗的发展。
(4)人工智能相关方法研究
神经疾病智能诊断的主要任务是提高医生的诊断效率和找到关键的发病机制[97],从而提供更好的治疗方案和预后判断。然而,深度学习模型很难同时实现高精度和可解释性[98-99],这也是当前研究的瓶颈之一。目前,仅有少数机器学习和深度学习方法可用于揭示潜在的生物标志物。在未来研究中,可以结合不同的数据类型、相关知识和新的算法,探索合适的、具有可解释性的模型,以更好地将机器学习、深度学习等方法应用在神经疾病的智能诊断中。
随着大模型时代的来临,在自然语言处理、图像识别等方向构建的模型都趋向于大体量、大算力。在自闭症智能诊断中由于特征复杂,分类模型难以解释,需要通过模型轻量化来减少模型的计算量,从而提高诊断效率。
综上所述,在未来的研究中主要包括创建大型自闭症数据库、多模态数据集、多标签分类、模型轻量化等。人工智能在医学领域的快速应用,要求健壮精准的医疗模型作为医生临床诊断的重要助手,协助医生以病理的变化作为可依靠的真实数据进行诊断。通过及时分析并预测不同时刻患者的具体情况,提高诊断精度和效果。
5 结束语
近年来,研究人员在自闭症谱系障碍诊断中做出大量贡献,许多成熟的预测算法被提出。但当前大多数算法局限性较强,无法综合利用各类信息更加准确、高效地预测是否患有自闭症。自闭症的预测分类任务将会在数据、模型、隐私保护等模式下不断发展,为自闭症早期干预打下坚实基础。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
文萃报·周五版(2021年14期)2021-06-08 22:33:19
中国生殖健康(2020年7期)2021-01-18 03:02:02
少先队活动(2020年12期)2021-01-14 01:47:40
电影(2018年8期)2018-09-21 08:00:06
海峡姐妹(2017年5期)2017-06-05 08:53:17
中成药(2017年3期)2017-05-17 06:09:01
丹青少年(2017年2期)2017-02-26 09:11:05
领导科学论坛(2016年9期)2016-06-05 14:59:58
