
基于常规检验数据的原发性肝癌风险预测模型的建立与评价*
2023-11-27 08:53:30曹晓强高颢瑾杨大干海南医学院第二附属医院检验科海口57011厦门大学公共卫生学院福建厦门61104浙江大学医学院附属第一医院检验科杭州1000
临床检验杂志 2023年8期
曹晓强,高颢瑾,杨大干(1.海南医学院第二附属医院检验科,海口 57011;2.厦门大学公共卫生学院,福建厦门 61104;.浙江大学医学院附属第一医院检验科,杭州 1000)
原发性肝癌是最常见的恶性肿瘤之一,外科手术切除是肝癌最主要的根治手段[1-3]。肝癌晚期患者的存活期一般仅3~6个月,早期诊断肝癌是延长患者生存时间的最有效手段。目前,肝癌风险预测模型有:REACH-B评分模型[4]适用于无肝硬化的慢性乙肝患者,该评分表的检验指标包含性别(Sex)、年龄(Age)、丙氨酸氨基转移酶(ALT)、乙型肝炎病毒e抗原和乙型肝炎病毒DNA。Johnson等[5]用于原发性肝癌辅助诊断的(GALAD)模型,包含Sex、Age和甲胎蛋白(AFP)、甲胎蛋白异质体比率、异常凝血酶原,诊断早期肝癌的敏感性和特异性分别为85.6%和93.3%,有助于AFP阴性肝癌的早期诊断。2019年,基于乙型肝炎病毒感染和中国人群大样本数据的优化的类GALAD模型[6],适用于中国人群原发性肝癌的早期诊断。aMAP评分基于Age、Sex、清蛋白(Alb)、总胆红素(T-Bil)和血小板(PLT),针对慢性肝病患者可跨病因、跨种族的预测肝癌风险[7]。ASAP肝癌风险评估模型包括Sex、Age、AFP和异常凝血酶原,敏感性为73.8%、特异性为90.0%[8]。但是,甲胎蛋白异质体比率、异常凝血酶原等并非常规检验项目,在怀疑肝癌时才会检测。本研究用常规检验数据作为模型筛选指标,利用SQL进行数据收集,采用DxAI智慧科研平台,通过机器学习建立原发性肝癌的风险预测模型,探索原发性肝癌风险预测的性能。
1 材料与方法
1.1病历数据收集和处理 回顾性收集2020年1月至2022年10月浙江大学医学院附属第一医院(简称医院A)和2021年11月至2022年10月海南医学院第二附属医院(简称医院B)收治的原发性肝癌患者、疾病对照者和健康体检者的临床、病理和随访资料。采用PL/SQL Developer用SQL语句设定条件将有关病历资料导成XLSX格式,包括血常规22项、生化32项、出凝血5项、肿瘤标志物12项、乙肝6项常规检验指标。将检验项目名称统一,如有多次结果选择其首次诊断后的检验结果,所有项目的检测时间相差不超过2周。缺失值分组别进行处理,其中正态分布用均数替换,非正态分布用中位数替换,非数值型数据用众数替换。
纳入标准:临床、病理和随访资料基本完整。原发性肝癌组:(1)根据《原发性肝癌诊疗指南(2022年版)》[9]初次确诊为原发性肝癌;(2)未合并其他恶性肿瘤。肝硬化对照组:(1)确诊为肝硬化;(2)未发展为肝癌。肝炎对照组:(1)确诊为肝炎;(2)未发展为肝硬化。健康人对照组:(1)健康体检人群;(2)诊断结果无肝病;(3)乙型肝炎病毒表面抗原和乙型肝炎病毒e抗原阴性。
排除标准:(1)同时患有其他影响筛选指标的疾病、妊娠等;(2)服用会影响筛选指标的药物等;(3)检测数据30%以上缺失。原发性肝癌组:接受过其他抗肿瘤治疗,如介入、消融或放化疗等;对照组排除标准:AFP≥200 μg/L的患者。
医院A最终纳入1 180例,其中原发性肝癌298例,肝硬化280例,肝炎244例,健康体检者358例。医院B有493例用于外部验证,其中原发性肝癌178例,肝硬化122例,肝炎共34例,体检人群159例。纳入研究的所有病历经过双人核对确认。本研究通过浙江大学医学院附属第一医院临床研究伦理委员会批准(批准文号:浙大一院伦审2023研第0035号]。
1.2实验方法
1.2.1特征变量的筛选 初步收集变量包括Age、Sex、检验指标等约100余项。首先,根据数据分布和类型,采用不同的显著性分析方法,将患者诊断作为因变量,特征变量作为自变量,选择差异有统计学意义的特征变量。其次,应用机器学习测试数据,通过多次尝试发现XGBoost模型的整体性能最好,选用该算法并基于方差分析(ANOVA F-value)进行特征变量进一步筛选。最后,通过测试机器学习的结果不断地优化和性能比较,筛选出建立模型的特征变量组合。
1.2.2机器学习模型构建和评价 机器学习是指从有限的观测数据中学习出具有一般性的规律,并利用这些规律对未知数据进行预测的方法[10-11]。采用Z-score法,对入选特征进行归一化处理。通过5折交叉验证的方法建立模型。机器学习算法采用决策树(Decision Tree)、逻辑回归(Logistic Regression)、极限梯度提升(XGBoost)、随机树林(Random Forest)和梯度提升(Gradient Boosting)。基于训练集数据进行机器学习分析的特征选择与模型优化,在验证集数据处理中选择ROC曲线下面积(AUCROC)、阴性预测率[NPV=TN/(TN+FN)×100%]、阳性预测率[PPV=TP/(TP+FP)×100%]、准确度、敏感性、特异性作为模型评价指标。
aMAP评分为:({0.06×Age+0.89×Sex(男性:1,女性:0)+0.48×[(lgT-Bil×0.66)+(Alb×-0.085)]-0.01×PLT}+7.4)/14.77×100,其中Age以年为单位,项目的单位分别为T-Bil(μmol/L)、Alb(g/L)和PLT(103/mm3)[7]。
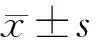
2 结果
2.1研究人群的人口学特征 研究人群的人口学特征见表1,医院A和B部分组的年龄和所有组的性别存在统计学差异(P<0.05),可用于验证风险预测模型在不同地区和来源的人群中的稳定性。
2.2特征变量筛选过程 特征变量除Age、Sex外,剔除缺失值<30%的检验指标后,剩余82个检验指标。经秩和检验有统计学差异(P<0.05)的有36个特征变量。经t检验有统计学差异(P<0.05)的10个特征变量。经卡方检验有统计学差异(P<0.05)的8个特征变量。
将54个特征变量作为自变量,患者诊断作为因变量,XGBoost模型的验证集AUCROC为0.96,性能明显优于其他模型。选用XGBoost模型进一步筛选特征变量,纳入AFP(缺失率7.21%)、C-反应蛋白(CRP)(缺失率17.38%)、糖类抗原125(缺失率8.73%)、糖类抗原199(缺失率7.38%)、半胱氨酸蛋白酶抑制剂C(CysC)(缺失率7.97%)、胆碱酯酶、ALT、血糖、γ-谷氨酰基转移酶、凝血酶原时间、腺苷酸脱氨酶、乙型肝炎病毒表面抗原、碱性磷酸酶、纤维蛋白原(Fib)、癌胚抗原(缺失率7.38%)、血小板压积、Alb、尿酸、T-Bil、Sex、Age共21项特征变量,称为X21。
对X21进行多次删减与组合,不断地调整模型的指标种类和数量,得到2种6个参数的特征组合且AUCROC不低于0.95。X6共有的特征参数包括Sex、Age、AFP、CRP、CysC。X6a的特征参数还有Fib,X6b的特征参数还有Alb。调整过程中特征变量种类、数量与权重的变化如图1所示,AFP是风险预测模型中最重要的特征参数。

图1 特征变量的权重变化图
2.3原发性肝癌风险预测模型建立和评价 将X6a和X6b分别作为模型建立的自变量,患者诊断作为因变量,应用机器学习建立模型,使用的算法为Decison Tree、Logistic Regression、XGBoost、Random Forest及Gradient Boosting,X6a建立的模型依次称为Model1-5,X6b建立的模型依次称为Model6-10,见表2,其中Model3是X6a为参数所建立的最优模型,Model8是X6b为参数所建立的最优模型。656例数据进行了aMAP评分,>50分为中高风险,<50分为低风险。肝癌人群298例,被评为中高风险250例,低风险48例。健康体检人群358例,被评为中高风险121例,低风险237例。aMAP评分的结果准确率为74.24%,错误率为25.76%。
2.4原发性肝癌组与肝硬化组、肝炎组、体检组的模型性能和评价 用原发性肝癌组和肝硬化组、原发性肝癌组和肝炎组、原发性肝癌组和健康体检组的数据独立作为数据集,选用XGBoost算法,分别将X6a、X6b作为自变量,患者诊断作为因变量,进行机器学习,建立模型ModelA和ModelB、ModelC和ModelD、ModelE和ModelF,其性能指标见表3。

表3 原发性肝癌组与对照组ModelA-F验证集的性能指标
2.5Model3、Model8外部验证结果 Model3在医院B的外部验证性能指标:AUCROC(95%CI)0.829(0.787~0.870),NPV 0.828,PPV 0.726,准确度0.793,敏感性0.685,特异性0.854。Model8在医院B外部验证性能指标:AUCROC(95%CI)0.816(0.774~0.859),NPV 0.802,PPV 0.771,准确度0.793,敏感性0.607,特异性0.898。Model3外部验证的评分图和ROC曲线见图2,Model8外部验证的评分图和ROC曲线与Model3相似。

注:图A中蓝色代表非原发性肝癌病例,红色代表原发性肝癌病例。左侧的红色为判断错误的阳性样本,可能是因为部分原发性肝癌患者未出现明显的血清学特征;右侧蓝色为判断错误的阴性样本,原因可能为部分患者已处于原发性肝癌早期而临床尚未确诊。图2 Model3外部验证的评分图(A)和ROC曲线(B)
3 讨论
机器学习是人工智能的一个重要分支,高质量数据和机器学习算法是人工智能的核心。风险预测模型的建立需提供经数据标注、高质量、完整的资料。传统的数据收集方法,需要在电子病历、检验系统中根据患者ID等逐个手工收集数据,过程繁琐、效率低且耗时长。可借助工具用SQL在数据库中批量筛选患者的诊断信息来收集所需要的数据,再进行数据确认、标化和预处理,能提高数据收集的效率。
风险预测模型的预测效能与特征参数的选择和组合密切相关。基于检验现有的数据资料,应用统计学方法,通过显著性、单/多因素、算法权重等分析确定特征参数,避免了主观影响,参数的组合也存在更多的可能性,能更好地挖掘出检验项目的未知价值。不同的模型可能包含不同的指标组合,如aMAP评分包括T-Bil、Alb和PLT等指标[7],REACH-B评分包括ALT、乙型肝炎病毒表面抗原等指标[4],ASAP模型包括AFP和异常凝血酶原等[8]。从图1可见,X21、X16模型时,几乎包括与肝癌有关的检测指标,如乙型肝炎病毒表面抗原、ALT、T-Bil等,但进步一优化为X11、X6a、X6b模型时,检测指标减少,只剩下权重最高为AFP,还有CRP、Fib、Alb、CysC等指标。AFP主要作为原发性肝癌的血清标志物,用于原发性肝癌的诊断及疗效监测[9]。CRP在原发性肝癌患者中的水平显著高于其他良性肝病[5]。Fib在原发性肝细胞癌患者中的水平高于肝硬化组,表明肝硬化患者Fib升高时,应加强随访[12]。Alb具有检测肝癌的潜在能力,肝癌患者的Alb降低,可能是因为肿瘤坏死产生的毒性物质引起机体代谢紊乱[13]。CysC也是模型中的一个重要参数,虽有文献报道与恶性肿瘤细胞增殖分化的相关[14],但是将其用于原发性肝癌相关诊断的研究较少,有待于进一步研究。
模型建立时选用的特征参数的数量越少,尽可能选用常规检验指标,可提高模型的临床适用范围。模型建立过程中,尝试了多种参数的组合方法,不同的参数所建立的模型有不同的效果。根据X11建立的XGBoost模型的验证集AUCROC为0.962,相比Model3和Model8多了5个检验指标,但AUCROC的提高只有0.01。在保证模型性能的同时减少参数数量的原则,X11建立的模型并不好。将特征参数AFP、CRP、CysC、Age和Sex建立的XGBoost模型的验证集AUCROC为0.946,相比Model3和Model8而言仅减少了1个指标Fib/Alb,但预测模型的性能有所下降。Model3和Model8所涉及的参数仅为医院A和B常见的检验项目并具有较好的预测性能。因此,模型参数的选择方法诸多,不同的研究在参数选择时有不同的依据,也可能有更好的常规参数组合未被发现。
不同机器学习算法建立的模型的诊断效能不同。对比内部验证的性能指标,结果显示XGBoost算法的AUCROC、准确度等均高于其他模型,在模型构建过程中表现出与数据特征优良的适配性,是最佳的风险预测算法。Model3和Model8的验证集AUCROC均达到0.95以上,外部验证AUCROC均达到0.80以上,表明对原发性肝癌的预测能力和区分度较高。本文为多中心研究,模型的建立和内部验证数据与外部验证数据的来源不同,可以体现出模型在不同地区、不同人群中应用的稳定性,符合临床真实情况。
近年来,已有研究建立了原发性肝癌的风险预测模型,包括GALAD模型(AUCROC=0.917,准确度=0.847)[5]、C-GALAD(AUCROC=0.89,准确度=0.819)[6]、ASAP(AUCROC=0.915,准确度=0.858)[8]等。aMAP=60时,特异性为56.6%~95.8%,PPV为6.6%~15.7%[7]。表2结果可见,Model3和Model8的性能指标优于大多数已有模型[5-8],虽然已有模型仍有部分性能指标(如敏感性)优于Model3和Model8,这与应用甲胎蛋白异质体L3、异常凝血酶原、循环肿瘤DNA等特殊的检验项目有关,而体检和常规筛查中一般不包括这些项目,不利于模型的普及和应用。另外,表3结果显示,建立的原发性肝癌组与肝硬化组、肝炎组、健康体检组的预测模型ModelA-F,AUCROC均大于0.93,且具有较高的敏感性和特异性,其中原发性肝癌组与健康体检组的数据建模效果最好,与肝炎组其次,与肝硬化组最差。Model3和Model8选用的检验指标为AFP、CRP、CysC和Fib或Alb,是临床常用的检验项目,可以保证模型的普及率,充分挖掘常规检验结果的价值,提高原发性肝癌的早期诊断率。临床诊疗中,如果某患者做了模型中的检验项目,必要时可在信息系统中提醒患原发性肝癌的风险概率,来辅助医生的临床决策。
本文存在以下局限性:回顾性研究,存在一定的选择偏倚和研究设计缺陷,且患者数据量较少。虽使用独立验证集进行外部验证,但验证数据仅1家,还要进行更多外部验证。不同医院的仪器、试剂存在差异,需要进一步标准化和同质化。
总之,本文运用深睿医疗智慧科研平台,基于临床常规检验项目,选择五种算法进行机器学习,建立了原发性肝癌的风险预测模型,Model3适用于住院患者,Model8适用于门诊患者和体检人群。
猜你喜欢
肝博士(2020年4期)2020-09-24 09:21:36
天津医科大学学报(2019年3期)2019-08-13 06:53:08
中国临床医学影像杂志(2019年1期)2019-04-25 06:49:42
解放军健康(2017年5期)2017-08-01 06:27:34
中国卫生标准管理(2015年4期)2016-01-14 05:16:45
肿瘤预防与治疗(2015年1期)2015-09-26 07:26:20
天津医科大学学报(2015年3期)2015-06-05 12:21:49
中国当代医药(2015年16期)2015-03-01 02:03:11
肝胆胰外科杂志(2015年4期)2015-02-27 11:12:34
癌变·畸变·突变(2015年4期)2015-02-27 06:15:25
