
基于YOLOv5的涉密场所敏感行为检测研究
2023-11-25 02:19吴燕菊胡峰源徐崭董岱豪
电脑知识与技术 2023年28期
吴燕菊,胡峰源,徐崭,董岱豪
(陆军工程大学指挥控制工程学院,江苏南京 210001)
0 引言
近年来,为加强涉密场所如值班室、实验室等的安全管理,各级管理部门不仅出台了一系列管理制度,还通过加装监控设备如摄像头等进行实时监管。然而,在对视频中违规行为进行识别时,目前仍多采用安全泄密事件发生后的人工鉴别方式。
在监控视频中检测违规行为,一方面需要耗费大量人力和精力。另一方面,依靠人工检测的方式容易出现误报和漏检,同时也无法实现实时处置和预报。因此,如何从海量监控视频中提取有用信息并提高对违规行为的识别能力,对于加强涉密场所的安全管控具有重要的应用价值。
目标检测提供了识别涉密场所敏感行为的一种方法。本文结合监控设备中敏感行为的目标特征,梳理了该领域存在的技术难点,并总结了传统目标检测方法和深度学习检测方法的基本流程。同时,提出了一种基于YOLOv5 的涉密场所敏感行为检测方法,分析了采用的数据集及检测结果,这些研究成果对未来涉密场所敏感行为检测方面的研究具有重要参考价值和推动作用。
1 基本概念和技术难点
1.1 涉密场所和敏感行为概念
所谓涉密场所[1],即保密要害部位,是指集中制作、存放、保管国家涉密载体、涉密信息的专门场所。
敏感行为,是指有可能引发泄密或者危及涉密人员人身安全的行为。本文主要侧重泄密行为,设定在涉密场所携带手机和滞留手机为敏感行为。
1.2 技术难点
1)实际数据与训练数据差异性较大
训练数据上大部分来自网络,目标多位于中央,光照条件好。实际涉密场所内较昏暗,监控摄像头在采集视频时画质较差,分辨率和像素低,不易从视频中更好地提取特征,如若天气糟糕时会进一步恶化,影响着目标检测的质量。
2)目标尺度复杂多变
目标处于移动状态,容易随着角度和距离等参数发生相对变化。监控摄像头位置较高时,容易产生模糊目标和小目标,二者较近时,容易产生目标不全,或者大的目标出现;另外,不同的拍摄角度也会产生不同的效果,从而加大了检测难度。
2 目标检测算法与YOLOv5
2.1 目标检测算法
目标检测算法根据是否运用了深度神经网络,将其分为传统的目标检测算法和基于深度学习的目标检测算法。
2.1.1 传统目标检测算法
传统目标检测算法流程如图1所示。

图1 传统目标检测算法流程
首先,在目标图像上利用滑动窗口依次选取以下候选区域,而后对这部分区域利用SIFT,HOG 等进行特征提取,最后使用预先训练好的分类器,例如SVM进行分类。就传统目标算法而言,存在两大缺陷[2]:
1)滑动窗口选择区域,选择时针对性不强,时间复杂度高。
2)人工选择设计的目标多样,鲁棒性不足。
2.1.2 深度学习目标检测
深度学习目标检测算法是人工神经网络的改进,并且是一种常用的AI技术图像目标检测算法,相比传统目标检测算法在检测性能和效果上获得了明显改善。文献[3]中提到针对人群中检测异常行为时存在的高算法复杂度和低精确度的问题,提出了基于改进的SSD算法,该算法将特征提取网络替换成了轻量级别网络,减少了模型内参数,加快了模型运行速度,从而能够更加精确地检测异常行为。文献[4]提出了传统目标检测算法在特征提取上存在不足,因此在YOLOv3 网络中采取了合并归一化到卷积层、修改损失参数、添加池化等方式以提升网络的性能和检测精度。然而该算法仍然存在运行速度慢、使用范围小、灵活性差等问题。为提高涉密场所的安全性能,本文利用YOLOv5 模型来检测敏感行为,该模型具有小尺度、低成本部署和高灵活性等优点,检测速度快[5]。
2.2 YOLOv5算法
YOLOv5 是一种基于深度学习的目标检测算法,它是YOLO[6](You Only Look Once) 家族的代表算法。根据使用深度和宽度两种参数控制4种结构,主要包括的结构有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,深度上依次加深,宽度亦然,精度上虽在不断提高,但是速度上不能互相匹配,在不断降低。考虑到YOLOv5s 是4 者中最轻量化且深度与宽度最小,因此本文采用YOLOv5s网络结构进行模型训练,其网络主要可以分为4 部分:输入端、骨干网络、头部网络和输出端[6]。
3 基于YOLOv5训练模型
训练的具体流程如图2所示。

图2 目标检测算法处理流程图
3.1 数据集收集
由于涉密场所的保密性,且存在实际数据与训练数据差异性较大的问题,所以本文通过自建数据集训练模型,主要来源于在模拟涉密场所环境以及各种天气下拍摄的敏感行为视频,并将视频进行分帧,如图3所示。

图3 部分数据集展示
针对存在的目标尺度复杂多变的问题,本文采用数据增强技术对样本进行随机裁剪、缩放和旋转,以增加训练样本的多样性和丰富性,最终得到12 000张图片,如图4所示。
3.2 数据集预处理
使用标注软件Labelimg[7]对原始数据进行标注,所有数据集采用YOLO 格式进行标注。图片标注过程如图5所示,标注结果以XML格式存储,XML文件中包括图像信息、目标名称、目标所在位置等信息。
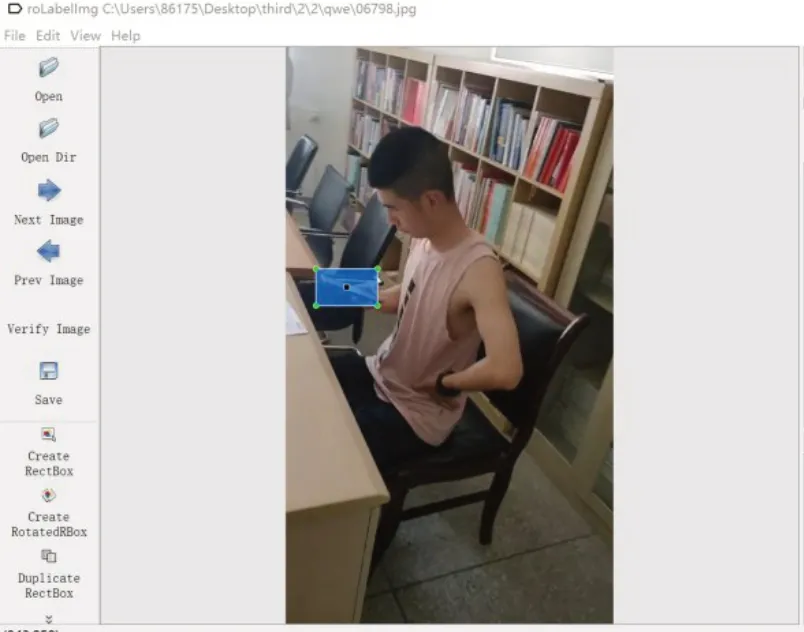
图5 标注图片
将XML 文件转换成YOLO v5s训练所需要的TXT文件,如图6所示,并将数据集划分为训练集和验证集,其比例为4:1,如表1所示。

表1 数据集分类

图6 部分TXT文档展示
3.3 模型训练
3.3.1 环境配置
本文采用深度学习框架PyTorch进行YOLOv5s模型的训练,其余软件环境和版本如表2所示。

表2 实验环境配置
其中操作系统为Windows11,处理器为11th Gen Intel(R) Core(TM) i7-11370H,主频为3.30Hz,使用本地GPU,输入图像大小为640 mm×640 mm;输入通道数为2,选代次数设置为300 次,在Anaconda3 创建的虚拟环境中进行训练其属于一个开源的Python 发行版本,可以利用conda进行package和environment的配置且包含Python 相关的配套工具,同时在CUDA 和CUDNN解决GPU在运行时的复杂问题。
3.3.2 数据集评价
在YOLOv5学习中,会使用精确度(Precision)和召回率(Recall)作为评估参数。精确度描述的是实际预测正确的数据在正样本数据中的比例;召回率描述在数据集合中正类别被确切检测出来的比值。两者公式分别为式(1)和式(2)。
其中,NTP为预测正确的数据样本数目,NFP为预测错误的数据样本数目,NFN其中为出现错漏的样本数目。
平均精度均值(mean Average Precision,mAP)是精确度和召回率的综合平均精度(average、precision)的平均值,如式(3)和式(4)所示:
其中,P、r分别为精确度和召回率,k表示种类,K表示实验的种数总和。
3.3.3 算法训练
如图7所示将搭建好的YOLOv5s的环境,根据硬件配置及逆行参数的设置,如图7所示。

图7 参数调试
如图8所示,模型训练到200次时开始收敛,其中训练集的BOX是bounding box(边界框)定位损失,可以看出模型预测框与真实框差值逐渐变小,准确度越来越高;Objectness 为置信度损失,可以看出其损失越来越小,对于目标的检测准确度越高;Classification 是分类损失,可以看出损失基本为0,分类上的准确度越高。另外看出训练集中的损失函数变化总体已经降到最低水平。Prection 和Recall 都处于逐步上升的趋势,符合本实验预期结果,对于两者形成的面积,即为所求的测试集mAp_0.5值,其最大值可以达到95.2%。

图8 训练结果
训练后的YOLOv5s最佳模型如图9所示。

图9 训练后的最佳模型
3.4 数据识别
直接检测图片,完成一张640×384 mm 的目标图片,检测大概需要0.1s,检测速度较快,如图10所示。
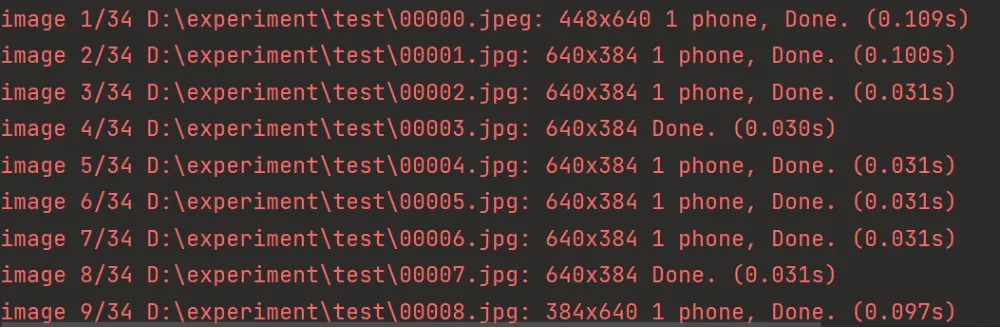
图10 检测识别过程
然后对携带手机和滞留手机的视频进行检测识别,最终效果如图11所示。

图11 系统检测效果图
4 涉密场所敏感行为检测系统的实现
结合YOLOv5s 训练模型,将其运用到检测系统中,具体流程如图12所示。

图12 系统检测流程图
4.1 系统实现
将训练后所得的模型文件放于源代码中,进行系统的测试与实现,本系统由罗技4K 高清摄像头负责进行实时拍摄,并自动上传到软件中进行检测,同时也支持由于特殊情况下的人工手动上传。检测效果如图13所示。

图13 系统检测效果图
从结果中可以看出。界面可划分为以下5 个区域:
1)敏感行为留存区:存在违规携带手机和使用手机进行拍摄的行为会被捕获出来。
2)风险等级预警提示区:发现敏感行为后会立即发出预警以及对应风险等级。
3)敏感行为次数统计区:统计一天内敏感行为的次数。
4)人员类别、相关地点、所属单位等信息的历史记录区,以便后期进行相关的提醒教育处理。
5)视频显示区:将实时视频在界面中展示。
该系统能够动态检测敏感行为,识别出携带手机、拍照等行为,并提供实时报警和历史记录,为管理人员提供决策支持,从而提高了涉密场所的安全系数。
5 结束语
基于YOLOv5 的涉密场所敏感行为检测系统,通过自建数据集对YOLOv5s模型进行训练,得到训练权重文件,对所需架构进行搭建,完成涉密场所敏感行为的检测。提高对于涉密场所视频监控下的安全系数,对后续涉密场所敏感行为检测研究具有一定参考价值和推动作用。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
现代装饰(2020年7期)2020-07-27
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
小学生必读(中年级版)(2019年6期)2019-01-11
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
中国现当代社会文化访谈录(2016年0期)2016-09-26
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年1期)2008-03-20
