
基于PP-YOLOv2电厂场景的安全帽佩戴检测
2023-11-24 23:18:58辜诚炜谌志东罗仁强周宏贵郑春华
现代信息科技 2023年18期
辜诚炜 谌志东 罗仁强 周宏贵 郑春华

摘 要:在电厂作业现场因未佩戴安全帽而导致人员伤亡的事件时有发生,人工监测方式不能做到及时发现实时提醒,且容易因视觉疲劳而错过一些目标,从而造成不必要的人员伤亡。基于此,文章提出一种基于PP-YOLOv2电厂场景的安全帽佩戴检测方法。基于百度飞桨深度学习框架,使用PP-YOLOv2神经网络,向训练数据集中添加电厂数据并使其占比超过1/3,可训练安全帽识别mAP(Mean Average Precision)高达94%的神经网络模型。同时,文章举例了电厂摄像头景深较深的画面,人在摄像头画面中占比较小,而公开数据集数据的景深较浅,在训练前该团队成员对部分数据进行了重新标注,增强了模型在电厂应用的泛化能力。
关键词:深度学习;安全帽佩戴检测;PP-YOLOv2网络;神经网络
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)18-0114-05
Safety Helmet Wearing Detection Based on PP-YOLOv2 Power Plant Scenario
GU Chengwei1, CHEN Zhidong2, LUO Renqiang2, ZHOU Honggui2, ZHENG Chunhua2
(1.Shenzhen Datang Baochang Power Supply Co., Ltd., Shenzhen 518110, China;
2.Hunan Datang Xianyi Technology Co., Ltd., Changsha 410001, China)
Abstract: There are frequent incidents of casualties caused by not wearing safety helmets at the power plant operation site. Manual monitoring methods cannot detect real-time reminders in a timely manner, and it is easy to miss some targets due to visual fatigue, resulting in unnecessary casualties. Based on this, this paper proposes a safety helmet wearing detection method based on the PP-YOLOv2 power plant scenario. Based on the Baidu Feijiang deep learning framework, the PP-YOLOv2 neural network is used to add power plant data to the training dataset and make it account for more than 1/3. It can train a neural network model with a helmet recognition mAP (Mean Average Precision) of up to 94%. At the same time, the paper provides examples of images with deep field in power plant cameras, where humans make up a relatively small proportion of the camera image, while the depth of field in public dataset data is relatively shallow. Before training, the team members re annotate some of the data, enhancing the application generalization ability of the model in power plant.
Keywords: deep learning; safety helmet wearing detection; PP-YOLOv2 network; neural network
0 引 言
一直以來,施工人员佩戴安全帽是一项硬性规定。有研究表明,在建筑工地及巡检现场中,接近90%的脑损伤因未正确佩戴安全帽引起[1]。尽管电厂管理明确规定,任何人进入电厂必须佩戴安全帽,却仍有临时工、民工等外单位人员进入电厂作业未佩戴安全帽,安全意识薄弱,存在很大的安全隐患[2]。传统的安全帽检测通常是人工现场监督,或通过摄像机使工作人员在监控室进行监控,在电厂环境下,面对几十甚至上百个监控画面,因监控人员责任心、工作状态、视觉疲劳等各种因素的影响下,整个视频监控系统的有效性无法得到保证,通常存在漏检的风险。
近年来,为了智能化检测安全帽的佩戴情况,涌现出大量新颖算法,主要是基于传感器和图像处理两种方式。基于传感器的检测主要通过定位技术采集人、机、材的信息位置,提供给安全风险识别系统进行风险评估[3-5],但该模式受设备精度以及传感器实际应用推广难度大。随着深度学习的发展,使用神经网络训练识别安全帽佩戴的模型层出不穷。基于深度学习的检测算法因其检测速度快、准确性高等特点,成为当前安全帽检测的主流算法[6]。
虽然深度学习在目标检测领域深受欢迎,但针对安全帽这样的小目标识别准确率及检测速度并不能满足工程需求。直到文献[7]提出了Faster R-CNN神经网络模型后,研究人员将该网络进行改进并应用于安全帽检测。文献[8]提出了Faster R-CNN+ZFNet的组合应用在安全帽的检测,mAP高达90.3%,检测速度可达27 FPS。文献[9]提出基于YOLO的半监督学习安全帽佩戴识别算法,在一般场景下视频流的建筑工人与安全帽检测准确率在85.7%~93.7%。文献[10]使用卡尔曼滤波和Hungarian匹配算法跟踪人员轨迹,配合YOLOv3实现安全帽检测,获得了18 FPS的检测速度和89%的准确率。文献[11]将SSD算法和Mobilenet网络融合,取得89.4% mAP。文献[12]使用RetinaNet作为检测网络,对快速移动的安全帽佩戴情况进行检测,测试集上实现了72.3% mAP,处理速度14 FPS。然而,针对电厂的应用场景,安全帽在整个视频画面中占比很小,若非人使用先验知识,也无法分辨出安全帽。作者仅使用公共数据集训练神经网络模型,虽然训练完成正确率最高可达98.6%,但部署在电厂700多路摄像头,每分钟取一帧图片进行识别,一天的误报可达数万条(包含误报重复告警的情况),模型的泛化能力较差。通过分析数据、模型,发现训练数据与测试数据之间的特征像素点相差较大,且电厂场景包含大量的钢管设备、关照条件不均衡等因素导致误报严重。本文研发团队采集一个月的电厂数据,数据清洗后将其标注并添加到公共数据集一同参与训练,使用百度飞浆的PP-YOLOv2模型,训练出识别率较高的网络模型,并满足电厂要求,且已上线使用。
1 PP-YOLOv2简介
PP-YOLOv2是百度于2021年4月提出基于PP-YOLO改进的神经网络结构,PP-YOLO是百度2020年8月基于YOLOv3改进的神经网络结构,使用百度开发的Paddle Paddle神经网络框架训练,因此命名为PP-YOLO。
PP-YOLO拥有45.2% mAP的正确率和72.9 FPS的帧率,优于当年较为流行的EfficientDet和YOLOv4的准确率和推理速度。PP-YOLO的主干网络将Dacknet-53替换成改进后的ResNet50-vd,并在最后将3×3卷积替换为Deformable Convolutional Networks(DCN),因此形成ResNet50-vd-dcn命名的Backbone。选择ResNet作为Backbone一方面因为其被大众广泛使用、优化程度更深、部署方便;另一方面是主干网络和数据增强是相互独立的关系。数据增强使用最基本的MixUP,并将训练的batch size从64增大至192,增大batch size可提高训练的稳定性和得到更好的训练结果。PP-YOLO并没有提出创新的技巧,只是组合使用了现有的技巧,使YOLOv3提高精度的同时不损失速度。
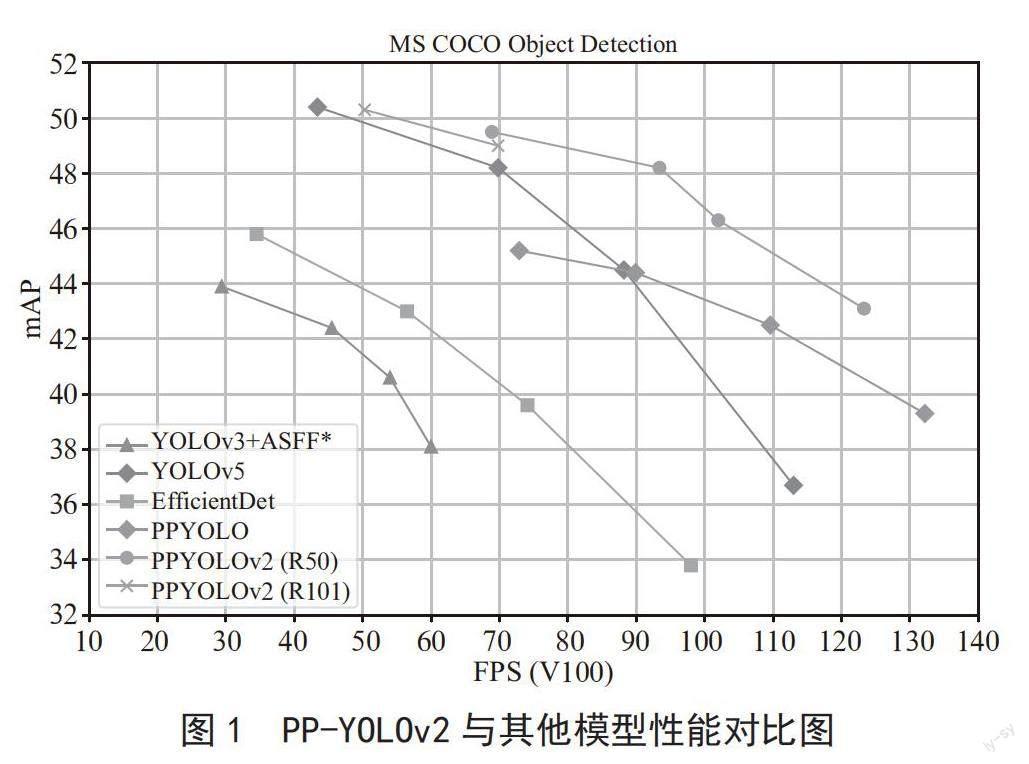
PP-YOLOv2是基于PP-YOLO的改进,通过多种有效改进方法的组合,使PP-YOLO在COCO2017 test-dev数据上的性能从45.9% mAP提升到49.5% mAP,故称模型为PP-YOLOv2。PP-YOLOv2的推理能力可达68.9 FPS@640×640的输入尺寸。采用百度飞浆的Paddle推理引擎+TensorRT+FP16+bs1,可进一步将PP-YOLOv2的推理速度提升至106.5 FPS。这样的性能超越了同等参数量的检测器YOLOv5l、YOLOv4-CSP等模型,如图1所示。此外,采用ResNet101-vd-dcn作为骨干网络的PP-YOLOv2可在COCO2017 test-dev数据集上获得50.3% mAP的性能[13]。
下文针对PP-YOLOv2相比PP-YOLO的主要改进进行描述:
1)预处理:首先采用Mixup训练[14](服从Beta(1.5,1.5)分布);然后以0.5概率逐个执行RandomColorDistortion、RandomExpand、RandCrop、RandomFlip方案;执行归一化mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225];最后输出尺寸从[320、352、384、416、448、480、512、544、576、608]中随机抽取进行多尺度训练。
2)基准模型:PP-YOLOv2的基准模型为YOLOv3改进版的PP-YOLO,进一步说明,它的骨干网络是ResNet50-vd,通过总计10个改进方案(包含SSLD、Deformable Conv、DropBlock、CoordConv、SPP等)改进了YOLOv3的性能,并且几乎不影响推理的效率。
3)训练机制:在COCO train 2017上,采用隨机梯度下降(SGD)训练网络500k次迭代,minibatch设置为96,分布在8张GPU上计算。在前4k次迭代中学习率线性地从0提升到0.005,然后在400k和450k处除以10。权值衰减设置为0.000 5,动量设置为0.9,与此同时,采用了梯度裁剪的方法稳定训练过程。
4)Mish激活函数:Mish激活函数[15]在YOLOv4和YOLOv5等探测器中被证明是有效的,它们在主干中采用Mish激活函数。由于PP-YOLOv2有一个非常强的预训练骨干模型(在ImageNet上达到82.4%的top-1精度),为保持骨干结构不变,我们仅将Mish用到了Neck部分。
5)更大的输入大小:增加输入尺寸可以增大目标被感知的面积,因此,小尺度的目标信息将比之前更好地保存,进而可提升模型的性能。然而,更大尺寸输入会占用更多内存,因此,需通过减少batch应用此技巧。具体来说,我们将单个GPU的batch从24减少到12,并将输入尺寸从608增加到768。输入尺寸均匀地从[320、352、384、416、448、480、512、544、576、608、640、672、704、736、768]中获取。
6)IoU感知分支:在PP-YOLO中,IoU感知损失是以软加权方式计算的,IoU损失定义为:
其中,t为锚点与其匹配的真实框之间的IoU,p为原始IoU分支的输出,σ (·)为sigmoid激活函数。值得注意的是:仅仅正样本的IoU损失进行了计算。通过替换损失函数,IoU损失表现更佳。
2 模型训练
论文所提及的安全帽识别目标检测模型训练基于百度开源的深度学习框架飞桨(PaddlePaddle)、目标检测框架PaddleDetection。训练的硬件条件和环境配置:Intel Core i7-9700处理器、16 GB运行内存、64位操作系统、GeForce RTX 2070 SUPER(GPU型号)、8 G显存、磁盘500 G、Python 3.8、PaddlePaddle 2.4.2。总共图片12 977张,其中训练图片9 084张、验证图片2 595张、测试图片1 298张。
参数设置:因训练集中包含了5 396张电厂数据,每张大小为1 920×1 280,在已有的GPU资源训练时间较长,因此设置一个较大的epoch记录训练过程的loss和mAP值,本实验设置epoch为500 000次。batch size设置为8(设置16显存不够),其余参数使用飞桨默认即可,可按照百度飞桨官方文档(https://github.com/PaddlePaddle/PaddleYOLO)准备训练。
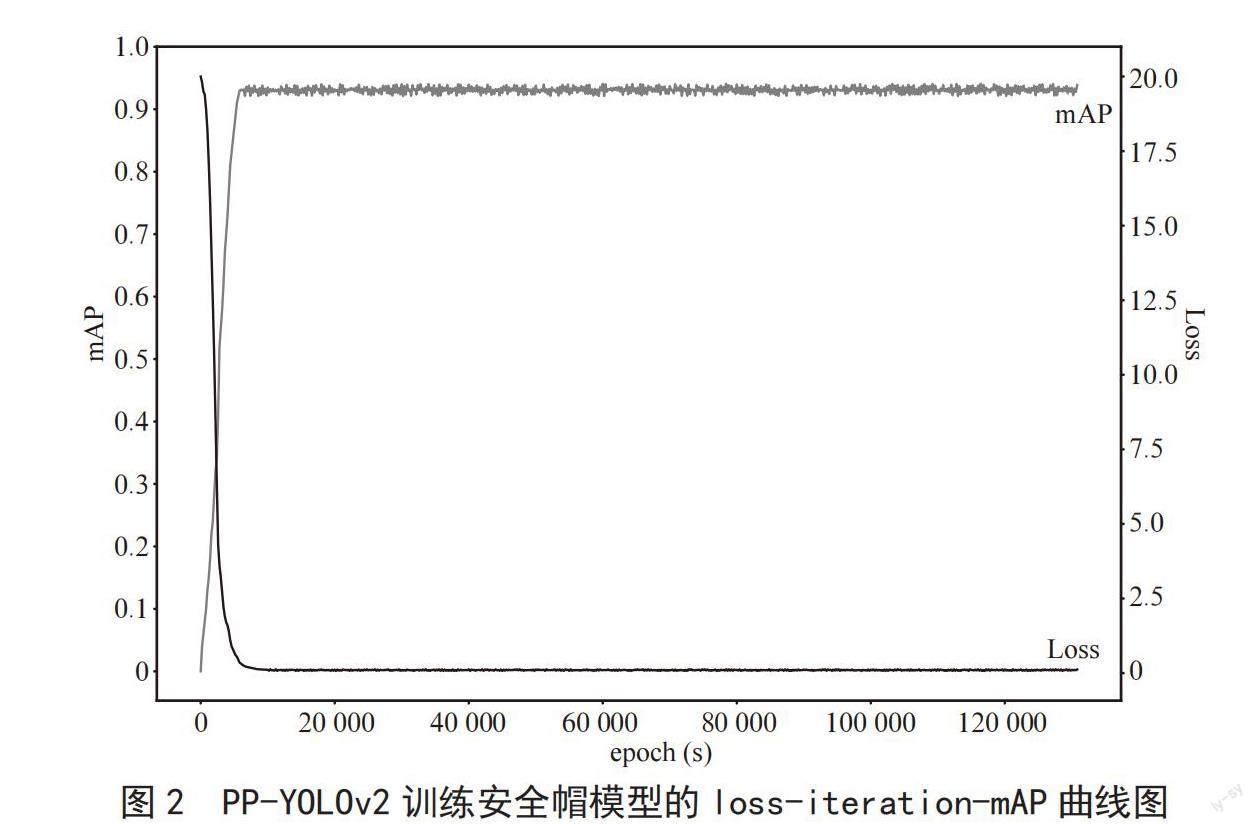
训练结果:在epoch大约为50 000次时,loss值开始动荡,mAP值也达到了94%的峰值,loss-iteration-mAP曲线如图2所示,最后在epoch为130 700时,我们终止了训练。
3 实验结果和分析
针对上一章节的训练结果,并不是目前学术界及工业界最好的mAP(IoU 0.5),但是它是本文作者所在团队部署到电厂检测效果最好的模型(注:并不是主流模型作者都进行了实验)。目前该算法已部署在电厂700余路高清摄像头,覆盖主要生产及保卫区域,基本实现重要设备及通道的视频覆盖。在厂区部署了3个5G宏基站和10个室分基站,做到5G信号全覆盖,满足偏远区域视频监控及移动监控的需求。
电厂场景安全帽检测结果如图3所示,安全帽的类别标签为“helmet”“helmet”字符后面显示的数值是置信度。图3中的a部分展现了电厂外景摄像图的正常监视范围,可以了解到电厂室外摄像头的景深较深,人在场景内的占比很小,安全帽则更小,在景深较深处的工人是否佩戴安全帽人眼也难分辨。图3的b~g是与a图同样像素点大小的图片中截取目标检测部分,方便读者看清楚。b~g截图时保留了目标在原图的大小显示,可知训练的模型要满足电厂室内和室外的场景需求,室内的工作人员在摄像图片中占比相对较大,安全帽也比较清晰,使用公共数据集训练的模型识别的正确率也相对较高,但是针对外景,人距离摄像头较远时,如图3的a示例展现的工作人员大小,漏报及错报的情况相当严重。
通过仅公共数据集训练的模型错检的案例如图4所示,导致这些场景错检的原因主要是标注数据时,仅标注了人头及佩戴安全帽的部分,且公共数据集的背景环境相对简单,电厂生产区域存在各种专业设备、钢管结构等复杂场景,这些通过公共数据集训练无法学习到的,即使更换数据集甚至增加数据集数据(注:本文作者所在团队因前期没有电厂数据已试过增加数据集和更换数据集的方法),仍存在设备误检且置信度高于0.5的结果。
针对电厂环境内使用深度学习算法实现安全帽佩戴检测的难点主要是数据收集,如图5所示。公开的安全帽数据集中安全帽在整幅图片占比如图5的a~c所示,相对于电厂场景图片的安全帽在整张图片中占比较大。电厂的实际情况如图5的d~f所示,可见表示安全帽的像素点很少,考虑到使用公共数据集训练的模型泛化能力不高的情况,本文作者所在团队决定采集一个月的电厂数据。通常,电厂场景内施工人员较少,95%以上的摄像头拍摄场景内大部分时间没有人出现,团队成员使用JAVA和Python编程语言编写一个针对每个场景若检测到人则将该帧图片保存的程序,人的检测使用了YOLOv7预训练模型,尽管存在部分误报的情况,但少了工作量。将上述程序部署在电厂服务器可实时计算摄像头场景是否有人,抓图时间间隔1分钟。
经过对收集到的数据进行清理,总共放入数据集中的电厂数据5 396张,使用百度的“飞浆EasyDL”软件进行数据标注,电厂数据和公共数据集数据总数是12 977张。标注框仅为脖子以上部分,如图6所示,紫色矩形框的标签为人头(head),蓝色矩形框的标签为安全帽(helmet)。用于训练的电厂数据中每个场景添加了两张无人的图片,由于收集一个月的数据,有些场景并没有抓到有人的图片,一方面原因一分钟抓一幀,人已不在摄像头所监控的范围内(一分钟走过了摄像头所监控的范围);另一方面是YOLOv7预训练模型正确率的问题。使用无人的图片训练有助于背景的学习。
将数据集重新标注之后,使用PP-YOLOv2进行训练,可取得如图7所示的约为94%mAP。将模型直接部署到电厂后,我们通过设置置信度0.5滤除设备误报的情况,同时,在用户界面配置算法时,开启了可由用户调整当个监控场景置信度的功能,可根据场景降低置信度,减少漏检的发生。此外,部署后偶尔会出现误报,比如光照条件较暗,易将安全帽识别成头,这种情况通常需要人的先验知识判断。
4 结 论
本文主要阐述了电厂内人员佩戴安全帽对安全作业的重要性,以及提出了智能化实时监测的必要性。本文花费大量的篇幅描述了为什么使用公共数据集训练的模型在电厂泛化性差,主要由于安全帽数据特征表征差异大。作者所在团队通过在电厂内服务器上部署抓图软件对电厂有人的图片进行采集,最终将5 376张电厂数据并入公共数据集,使用百度“飞浆EasyDL”重新标注所有的数据,基于百度飞浆PaddlePaddle训练PP-YOLOv2模型,最终得到mAP为94%的模型。
参考文献:
[1] LI H,LI X Y,LUO X C,et al. Investigation of the causality patterns of non-helmet use behavior of construction workers [J].Automation in Construction,2017,80:95-103.
[2] 朱明增.变电站现场佩戴安全帽智能监控预警系统研究 [J].中国新技术新产品,2015(24):178-179.
[3] DONG S,HE Q H,LI H,et al. Automated PPE Misuse Identification and Assessment for Safety Performance Enhancement [EB/OL].[2023-02-18].https://ascelibrary.org/doi/10.1061/9780784479377.024.
[4] KELM A,LAUSSAT L,MEINS-BECKER A,et al. Mobile passive Radio Frequency Identification (RFID) portal for automated and rapid control of Personal Protective Equipment (PPE) on construction sites [J].Automation in Construction,2013,36:38-52.
[5] BARRO-TORRES S,FERNANDEZ-CARAMES T M,PEREZ-LGLESIAS H J,et al. Real-Time Personal Protective Equipment Monitoring System [J].Computer Communications,2012,36(1):42-50.
[6] 李政谦,刘晖.基于深度学习的安全帽佩戴检测算法综述 [J].计算机应用与软件,2022,39(6):194-202.
[7] REN S Q,He K M,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J/OL].arXiv:1506.01497 [cs.CV].[2023-02-18].https://arxiv.org/abs/1506.01497.
[8] FU J T,CHEN Y Z,CHEN S W. Design and Implementation of Vision Based Safety Detection Algorithm for Personnel in Construction Site [EB/OL].[2023-02-18].https://www.semanticscholar.org/paper/Design-and-Implementation-of-Vision-Based-Safety-in-Fu-Chen/9e22ef48b825eac3f417437ff2cc43c3d85128a7.
[9] 王秋余.基于視频流的施工现场工人安全帽佩戴识别研究 [D].武汉:华中科技大学,2018.
[10] ZHAO Y,CHEN Q,CAO W G,et al. Deep Learning for Risk Detection and Trajectory Tracking at Construction Sites [J].IEEE Access,2019,7:30905-30912.
[11] 李小伟.轻量级深度学习目标检测算法研究及系统设计 [D].合肥:安徽大学,2019.
[12] CROITORU I,BOGOLIN S V,LEORDEANU M. Unsupervised Learning from Video to Detect Foreground Objects in Single Images [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:4345-4353.
[13] HUANG X,WANG X X,LV W Y,et al. PP-YOLOv2:A Practical Object Detector [J/OL].arXiv:2104.10419[cs.CV].[2023-02-18].https://arxiv.org/abs/2104.10419v1.
[14] ZHANG H Y,CISSE M,DAUPHIN Y,et al. mixup: Beyond Empirical Risk Minimization [J/OL].arXiv:1710.09412 [cs.LG].[2023-02-19].https://arxiv.org/abs/1710.09412.
[15] MISRA D. Mish:A Self Regularized Non-Monotonic Activation Function [J/OL].arXiv:1908.08681[cs.LG].[2023-02-19].https://arxiv.org/abs/1908.08681v2.
作者简介:辜诚炜(1993—),男,汉族,湖南长沙人,助理工程师,本科,主要研究方向:智能发电研究;谌志东(1978—),男,汉族,湖南益阳人,高级工程师,本科,主要研究方向:智慧电厂、数据通讯;罗仁强(1972—),男,汉族,湖南衡阳人,助理工程师,专科,主要研究方向:智慧电厂、自动化管理;周宏贵(1973—),男,汉族,湖南衡阳人,高级工程师,本科,主要研究方向:能源生产数字化化转型研究、生产技术与信息技术两化融化技术研究;郑春华(1982—),男,汉族,河南衡水人,工程师,本科,主要研究方向:智慧电厂与智能发电研究。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
