
基于孪生空间的单目图像目标位姿一体化标注方法
2023-11-24 05:25:58李聪亮孙士杰张朝阳刘泽东宋焕生
计算机研究与发展 2023年11期
李聪亮 孙士杰 张朝阳 刘泽东 雷 琪 宋焕生
(长安大学信息工程学院 西安 710064)
(congliangli@chd.edu.cn)
目标位姿估计就是估计目标基于相机坐标系的位置及姿态,通常情况下我们分别使用3 个参数来表示其位置及姿态,因此该类问题也被称为6DoF(six degree of freedom)估计的问题,它是计算机视觉[1]与计算机图形[2]研究领域中的重要问题和热点问题之一[3].精确的3 维位姿估计方法对于实现人机交互[4]、移动机器人[5]等应用具有十分重要的意义.移动机器人,尤其是无人车,为了更好地感知复杂环境并完成特征任务,周围目标的位姿获取[6]不可或缺.
根据设备的不同,位姿标注方法可被划分为3 类:基于RGB-D 相机[7]、基于雷达[8]和基于RGB 相机[9]的目标位姿标注方法.基于RGB-D 相机的位姿标注方法大多依赖散斑或ToF(time of flight)方式获取深度,导致其感知距离受限(≤10 m)且会受到自然光照条件的影响,不适合在室外使用[10];基于雷达的位姿标注方法通常需要结合相机,才能获取场景的颜色信息,设备造价较高;基于RGB 相机的位姿标注方法不仅适用范围灵活(有些长焦相机的拍摄范围通常在100~300 m,甚至更远1 km[11]左右),而且采用的设备成本低廉,但是该类方法较难消除透视投影造成的信息损失.当前6DoF 估计问题的研究多采用RGB-D 相机所采集的数据,为获取准确的位姿,大多依赖于场景空间较小的数据集,如LineMod[12],YCB Video[13]等.
为克服相机的透视投影所带来的信息损失,本文结合真实3 维模型库,提出了一种基于孪生空间的单目图像目标位姿一体化标注方法.该方法仅需借助于单幅RGB 图像与3 维模型,便可估计出RGB 图像中每个目标的位姿.相比于使用雷达、RGB-D 相机,本文方法仅使用成本低廉、广泛布设的单目RGB 相机,数据获取更容易,可以进一步提升6DoF估计研究成果的实用性.
1 相关工作
基于RGB-D 相机、基于雷达和基于RGB 相机的位姿标注这3 种方法因可观测距离、观测精度等因素的差异,各有不同应用.
通过RGB-D 相机来捕获目标深度信息,进而融合深度信息与图像纹理信息,对目标6DoF 进行还原,从而获取目标的6DoF.该种方法在BOP(benchmark for 6D object pose estimation)挑战赛中应用广泛,如:在LM(LineMod)[12],YCB-Video[13],LM-O(Linemod-Occluded)[14],RU-APC(Rutgers APC)[15],T-LESS[16],YCB-V HB(HomebrewedDB)[17]等数据集中的应用.同时,由于目前主流的位姿估计数据集大多是通过RGB-D 相机构建而来的,也导致当前该领域的方法大多数基于RGB-D 相机.然而由于RGB-D 相机所存在的固有劣势,其拍摄范围在10 m 以内,虽然可以满足流水线机械臂抓取[13]等空间范围较小的应用,但是无法应用于无人驾驶、航天在轨机械臂、增强现实等场景空间范围较大的领域.
基于雷达的6DoF 标注的研究起步较晚,目前多使用无人驾驶数据集KITTI[18]中的3 维目标检测衍生出来的数据集.Slinko 等人[19]利用KITTI 数据集获取深度信息,对交通目标的6DoF 进行估计,相比于其他方法,该方法的应用场景进一步扩大,但是其精度相比于基于RGB-D 相机的方法略差.此外,由于雷达的价位较高[20],一定程度上限制了其大规模的应用.
基于单目RGB 相机的目标位姿标注方法主要分为基于单目RGB 视频或连续帧和基于单目RGB 图像的目标位姿标注方法.
基于单目RGB 视频或连续帧的目标位姿标注方法是通过视场中目标整体运动过程来克服相机透视投影的信息损失,并通过时间维度信息来弥补空间信息.其中赵丽科等人[21]通过单目序列图像得到运动目标轮廓集合,并构建不同位姿运动目标的模拟图像,通过模型图像轮廓与真实图像轮廓构建距离代价函数,进而解算运动目标位姿.袁媛等人[22]通过对目标运动过程中的编码特征点进行正交迭代解算算法完成目标物体位姿测量.An 等人[23]通过SFM(structure from motion)的方法对目标进行3 维建模,进而获取目标的形态.该方法应用较为简单,然而需要连续的相机拍摄过程,并且运算过程较为复杂,较难大规模适用于目标位姿标注过程.
基于单目RGB 图像的目标位姿标注方法是当前位姿标注研究的难点之一.目前仅存在基于RGB 图像的目标姿态标注方法[22]和目标深度估计方法.Zhao 等人[24]通过深度学习的方式对单目图像中目标深度进行估计,得到目标深度.Xiang 等人[25]利用目标检测网络和图像投影的逆过程,实现了目标姿态标注,并提出了Objectnet3D 的目标姿态数据集.然而文献[22-25]所提的方法虽然分别实现了目标真实空间深度和姿态的获取,但其获取过程复杂,且无法一体化获取目标位姿,因此当前急需一种目标位姿一体化标注方法.
为满足当前6DoF 估计领域的拍摄范围需求和大规模应用的可能性,本文设计了一种通过单目RGB图像和目标真实3 维模型估计位姿的方法,以一体化获取单目RGB 图像中目标的真实位姿.
2 本文方法
本文利用单目相机拍摄的RGB 图像与目标的3维模型,在已知相机焦距f的条件下使用相机的小孔成像原理,通过改变目标模型在3 维空间中的位置,使其与RGB 图像中对应目标重叠,以求解目标6DoF,这种求解目标的6DoF 的方法,本文称为基于孪生空间的单目图像目标位姿一体化标注方法.
2.1 图像的一次投影过程
图1 为本文方法的原理示意图,一次投影图为真实世界中相机拍摄过程,二次投影图为本文孪生空间中虚拟相机拍摄过程.为方便后续分析,设相机焦距为f,相机拍摄图像的宽和高分别为width和height,可得水平视场角和垂直视场角分别为

Fig.1 Schematic diagram of our method principle图1 本文方法的原理示意图
图1 中涉及到4 个坐标系,分别为相机坐标系(XcYcZc坐标)、图像像素坐标系(UV坐标)、世界坐标系(XwYwZw坐标)和目标物体坐标系(XoYoZo坐标).为便于分析,设定世界坐标系坐标轴Xw,Yw与相机坐标系坐标轴Xc,Yc平行且方向相同,Zw,Zc位于同一直线且方向相反,其中Zc轴为相机光轴;设世界坐标系原点Ow与相机坐标系原点Oc距离为d;目标物体坐标系原点位于目标中心点,Zo轴垂直向上,且与Xo轴和Yo轴成右手坐标系.需要注意的是,二次投影过程中的平面I1即为一次投影过程中的图像平面I1.为方便计算,设定相机水平视场角投射到世界坐标系XwOwYw平面时,其距离为dwidth=1 m,则垂直视场角投射到世界坐标系XwOwYw平面时,其距离为dheight=则此时世界坐标系原点Ow与相机坐标系原点Oc的距离为
将式(1)和dwidth=1 m带入式(3)得到
假设图像坐标系上目标位置存在某点p=(u,v,1),该点在相机坐标系、世界坐标系、目标物体坐标系的对应点分别为pc=(xc,yc,zc,1),pw=(xw,yw,zw,1),po=(xo,yo,zo,1).
由相机焦距为f,不考虑相机畸变,则相机坐标系到图像像素坐标系的转化关系为
其中cx和cy为图像中心点坐标,α 为尺度因子.
考虑到相机和目标的基准坐标系均为世界坐标系,因此目标物体坐标系到图像坐标系的变换则转换为物体坐标系经由世界坐标系、相机坐标系,最终转换到图像坐标系.由于世界坐标系仅是为方便表述而引入的中间变量,其位置对整体转换过程没有影响,因此可固定世界坐标系的位置.
为方便讨论,在坐标系转换过程中,先考虑位移,后考虑旋转.假定目标在世界坐标系中的位置为则由目标物体坐标系到相机坐标系的位移向量为
假定目标物体坐标系分别绕世界坐标系X,Y,Z轴的旋转角度分别为rX,rY,rZ,则目标物体坐标系到世界坐标系的旋转矩阵为
可得
由式(5)(6)(8)可得,目标物体坐标系到图像像素坐标系的转化关系为
由式(6)(8)可知,矩阵R含有9 个未知量,矩阵T含有3 个未知量,同时式(9)中自身包含1 个未知量α,因此式(9)中共有13 个未知数.假定已知2 维图像和3 维空间某个点的对应关系,代入式(9)可得到3个方程组,即: 一个3 维空间中的点与2 维图像中的对应点可提供3 个方程,因此若想求得唯一转换关系,则至少需要5 个不共面的对应点.考虑到固定大小的3 维物体目标与图像中已知的投影有无数个对应点,因此通过固定大小的非对称3 维物体目标在固定焦距和视场角的相机视角下,若图像中投影固定,则有唯一位姿.
2.2 孪生3 维空间的目标二次投影过程
由2.1 节可知,若固定大小的非对称3 维目标在固定焦距和视场角相机中的投影图像与空间目标存在至少5 个不共面的对应特征点,则可依据式(9)求得13 个未知数,且解唯一,本文称该投影过程唯一.对于对称目标,需特殊处理策略,本文不作讨论.
考虑到在真实空间中较难在同场景、同位姿情况下重构出目标一次投影,因此,本文通过重构同焦距、同视场的孪生相机及目标来构建孪生空间.通过在孪生空间中放置虚拟相机和一次投影图,并将与目标一致的3 维模型也放置其中.其中,3 维模型的投影过程称为“二次投影”,虚拟相机成像图为二次投影图,通过平移旋转,使得3 维模型在虚拟相机成像的目标与图像目标吻合,则此时3 维模型的位姿便可等价于该目标的位姿.具体有3 个步骤.
步骤1.孪生空间生成.本文选择使用VTK[26]工具进行初始孪生空间生成,同时在世界坐标系(0,0,d)的位置放置相机,相机焦距为f,水平视场角和垂直视场角分别为 αwidth和 αheight,相机方向即为相机光轴方向,与世界坐标系Z轴反向.
步骤2.视场范围内放置一次投影图像.考虑到场景信息不足,无法在空间中孪生目标周围环境,同时为方便比较一次投影图像中的目标与二次投影图像中的目标,以孪生空间世界坐标系的Ow点为图像中心,U轴与Xw轴平行,V轴与Yw轴平行,在XwOwYw平面内放置一次投影图,如图1 所示.
步骤3.模型二次投影.在孪生空间相机的视场范围内添加目标模型,并将模型在孪生空间中进行平移和旋转.此时,观察孪生空间相机拍摄结果,当目标模型二次投影结果与图像中真实空间目标一次投影结果完全相同时,通过VTK 工具得到目标3 维位姿.
3 实验结果及分析
考虑到6DoF 标注领域目前暂无基于单目RGB图像的目标位姿标注方法,无法进行同领域对比实验,因此为证明本文方法的有效性,本文与基于RGBD 和基于雷达的方法标注的精度进行对比,以证明本文方法的正确性和有效性.
3.1 实验环境及参数
为验证本文孪生3 维空间的目标二次投影方法在6DoF 获取的有效性,基于本文方法,使用Python3.8,VTK9.0 和PyQt5.15 制作标注软件——LabelImg3D①https://github.com/CongliangLi/LabelImg3D,并在Windows 系统上进行精度测试.
在测试时,需要已知当前场景相机的焦距或单个视场角以及真实物体的3 维模型,同时考虑VTK加载问题,模型为obj 文件.
3.2 数据集介绍
P-LM 是一个由LineMod 数据集整理后得到的数据集,共包含15 个类别,每个类别均包含深度图、掩码图和RGB 图像,每幅图像的内参矩阵已知,且每个类别均给出ply 模型及模型大小.KITTI 数据集是一个包含市区、乡村和高速公路等场景采集的真实图像数据,本文选择与其3 维目标检测数据进行精度对比,其训练集共包含7 481 张图像,其标签由car,van,truck,pedestrian,pedestrian(sitting),cyclist,tram,misc组成.
使用LabelImg3D 对P-LM 和 KITTI 这2 个数据集的图像进行标注,标注结果如图2 和图3 所示.为方便进行精度测试,本文分别从P-LM 和KITTI 数据集中选择每个类别中的200 张进行标注并测试.同时考虑到KITTI 数据集中并没有给出真实物体的3 维模型,因此根据KITTI 给出的目标长、宽、高及类别制作5 个类别的平均模型进行标注.

Fig.2 Schematic diagram of the labeling results of the indoor dataset图2 室内数据集标注结果示意图
3.3 评价指标分析
6DoF 估计主要有6 个参数,即x,y,z,rX,rY,rZ.考虑到,若位移误差仅使用一阶范数,则未充分体现出与相机的距离对误差产生的影响,因此本文提出6 个自由度的精度进行指标评价,参考高斯距离,使用 ℓX,ℓY,ℓZ来描述基于X,Y,Z方向上的精度,并使用来描述在RX,RY,RZ方向上的精度.其定义为:其中xg和为X方向上的位移和旋转的真值,xl和为X方向上的位移和旋转的标注结果.
3.4 实验对比与结果分析
为了进一步说明本文方法的有效性和精确性,将其与P-LM 数据集和KITTI 数据集进行对比实验.
3.4.1 基于P-LM 数据集的实验
将从P-LM 数据集中按照类别随机抽取的图片进行标注,结果如图4 所示,并将其与其原始标签对比,结果如表1 所示.由表1 可知,使用本文方法标注的结果,虽然因物体类型的不同精度有所变化,但是其位移精度均在0.95 以上,旋转精度均在0.90 以上,其精度基本满足实际获取需求.

Table 1 Comparative Experiment of P-LM Dataset表1 P-LM 数据集的对比实验

Fig.4 Example diagram of LabelImg3D labeling P-LM图4 LabelImg3D 标注P-LM 的实例图
3.4.2 基于KITTI 数据集的实验
将从KITTI 数据集中抽取的图片按照类别进行标注,结果如图5 和图6 所示,并与其原始标签进行对比,结果如表2 所示.由表2 可知,位移精度对比中Tram 类型位移精度较差,旋转精度对比中Pedestrian类型精度较差,其余位移精度均可达0.95 以上,旋转精度可达0.85 以上.
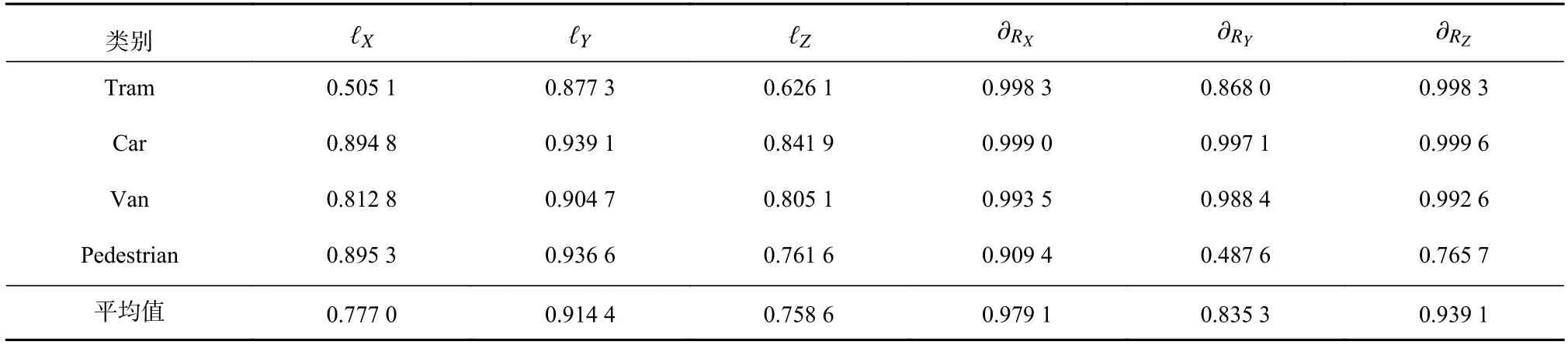
Table 2 Comparative Experiment of KITTI Dataset表2 KITTI 数据集的对比实验

Fig.5 Example diagram of LabelImg3D labeling KITTI图5 LabelImg3D 标注KITTI 的实例图
对Tram 类型进行对比分析,对比过程如图7 所示.由图7 可知,由于标注过程中使用的模型为平均模型,而对于Tram 而言其长度相差较大,这就导致在使用平均模型时无法使用模型本身的特征点对原图中Tram 的特征点进行准确表述,尤其是当存在一些极端长度时,会出现标注误差较大的问题.

Fig.7 Comparative results of Tram图7 Tram 对比结果图
对Pedestrian 类型进行对比分析,对比过程如图8所示.由图8 可知,由于人体在运动过程中的动态特性无法使用一个固定状态的模型去描述,这导致旋转标注结果与真值相差较大,因此在使用时仅可用于刚体3 维姿态的描述.

Fig.8 Comparative results of Pedestrian图8 Pedestrian 对比结果图
4 结语
本文提出了基于孪生空间的单目图像目标位姿一体化标注方法,此方法仅利用单目RGB 图像,结合与刚体目标一致的3 维模型,重构出与图像一致的孪生空间,并对3 维模型进行二次投影,最终得到目标的3 维位姿.实验表明,本文方法可在已知相机焦距的基础上利用图像和3 维模型,即可一体化获取精度接近RGB-D 相机和雷达采集的结果.
需要注意的是,本文方法存在一定的局限性:一方面该方法受限于3 维模型与真实物体的一致性,若存在较大的尺寸差异,需构建出多个不同尺寸的3 维模型;另一方面,该方法无法处理非刚体目标.未来,我们的主要工作将侧重于在非刚体约束下的目标位姿及形态高参估计.
作者贡献声明:李聪亮负责论文选题、论文实验、代码验证与测试、论文撰写;孙士杰负责论文选题、方法构思与设计、论文修改;张朝阳负责理论支撑、方法理论完善、文稿修改及论文定稿;刘泽东负责资料查询、代码实验测试及数据标注;雷琪负责资料解释、论文实验、代码实现与测试;宋焕生负责资料解释、文稿修改及论文定稿.李聪亮和孙士杰为共同第一作者.
猜你喜欢
中国光学(2021年6期)2021-11-25 07:48:32
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
中国医疗设备(2019年1期)2019-01-15 12:10:54
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
激光与红外(2015年10期)2015-03-23 06:07:18
机械工程师(2015年10期)2015-02-02 01:13:47
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:51
