
改进YOLOv5s 和DeepSORT 的井下人员检测及跟踪算法
2023-11-23 01:28:22邵小强杨永德刘士博原泽文
煤炭科学技术 2023年10期
邵小强,李 鑫,杨 涛,杨永德,刘士博,原泽文
(西安科技大学 电气与控制工程学院,陕西 西安 710054)
0 引言
为了扎实推进智慧矿山的建设,提升企业整体的信息化、数字化水平,对井下监控系统与巡检机器人的检测及跟踪能力进行全面升级是十分必要的。国家煤矿安监局最新出台的《煤矿井下单班作业人数限员规定》将矿井按生产能力分为7 档,对于各档次矿井下单班作业人数及采掘工作面作业人数做出限制。于是对井下人员进行实时跟踪及统计是避免发生安全事故的有效手段。但井下工作环境存在着光照不均,煤尘干扰严重等问题,导致工作人员无法长时间有效对监控视频进行多场景监控[1],且定点监控覆盖面有限。因此,使用巡检机器人取代工作人员进行实时监控对于减轻职工工作强度,降低岗位安全风险,实现企业减人增效和建设智慧矿山有着积极的作用[2]。
当今目标检测算法分为2 大类:传统机器学习与深度神经网络。传统机器学习算法分为三部分:滑动窗口、特征提取、分类器[3]。此类算法针对性低、时间复杂度高、存在窗口冗余[4];并且手工设计的特征鲁棒性差、泛化能力弱[5],这导致传统机器学习算法逐渐被深度学习算法所取代[6]。李若熙等[7]通过YOLOv4[8]算法进行井下人员检测,在寻找目标中心点时引入聚类分析算法,提升了模型的特征提取能力。杨世超[9]通过Faster-RCNN[10]算法进行井下人员检测,将井下监控采集的图像输入到检测模型中提取特征,利用区域建议网络和感兴趣区域池化得到目标的特征图,最后通过全连接层得到目标的精确位置。董昕宇等[11]通过SSD[12]算法构建了一种井下人员检测模型,采用深度可分离卷积模块和倒置残差模块构建轻量化模型,提升了模型的检测速度。陈伟等[13]提出一种基于注意力机制的无监督矿井人员跟踪算法,结合相关滤波和孪生网络在跟踪任务的优势,构建轻量化目标跟踪模型。以上文献都是利用深度学习算法实现井下人员检测与跟踪,但是当出现目标遮挡时,检测效果均不佳;同时缺少对井下人员编码统计的能力;而且模型参数量较大,检测速率也有待提高[14]。
针对上述问题,基于YOLOv5s[15]和DeepSORT[16]模型进行改进,使用改进轻量化网络ShuffleNetV2[17]替代YOLOv5s 主干网络CSP-Darknet53[18],使得模型在保持精度的同时降低了计算量。同时在改进ShuffleNetV2 中添加Transformer[19]自注意力模块来强化模型深浅特征的全局提取能力。接着使用Bi-FPN[20]结构替换原Neck 结构,使多尺度特征能够有效融合。最后使用更深层卷积强化DeepSORT 的外观信息提取能力,有效的提取图像的全局特征和深层信息,减少了目标编码切换的次数。实验结果表明,改进后的模型有效解决了人员遮挡时检测效果不佳及编码频繁切换的问题。
1 YOLOv5s 模型
YOLOv5 是当前深度学习主流的One-Stage结构目标检测网络,共有4 个版本:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。考虑到井下巡检机器人的轻量化设计,本文采用深度最小,特征图宽度最小的网络Yolov5s。其分为输入端Input、主干网络Backbone、颈部网络Neck、输出端Head 四部分。输入端通过Mosaic 数据增强、自适应锚框计算、自适应图片缩放,使得模型适用于各种尺寸大小图像的输入的同时丰富了数据集,提升了网络的泛化能力。主干网络包含:焦点层(Focus),Focus 结构在之前的YOLO 系列[21-23,8]中没有引入,它直接对输入的图像进行切片操作,使得图片下采样操作时,在不发生信息丢失的情况下,让特征提取更充分[24];跨阶段局部网络层(Cross Stage Partial Network,CSP),CSP[25]结构是为了解决推理过程中计算量过大的问题;空间金字塔池化(Spatial Pyramid Pooling,SPP),SPP[26]结构能将任意大小的特征图转换成固定大小的特征向量。Neck 中采用的是FPN+PAN 结构,负责对特征进行多尺度融合。Head 输出端负责最终的预测输出,使用GIOU 损失函数作为位置回归损失函数,交叉熵损失函数作为类别损失函数,其作用是在不同尺度的特征图上预测不同大小的目标。
2 改进YOLOv5s 井下人员检测算法
提出的井下人员检测框架如图1 所示。首先将井下巡检机器人所采集的图像逐帧输入到改进YOLOv5s 中进行训练,从而获取到网络的训练权重,最后利用测试集图像对本文改进的目标检测算法进行验证。

图1 本文目标检测算法框架Fig.1 Detection framework of the proposed algorithm
2.1 主干网络的替换
由于YOLOv5s 具有较大的参数量,对于硬件成本要求较高,难以部署在小型的嵌入式设备或者移动端设备。因此使用轻量化网络ShuffleNetV2 代替原主干网络CSP-Darknet53,通过深度可分离卷积来代替传统卷积减小参数量的同时高效利用了特征通道与网络容量,使得网络仍保持较高的精度[27]。表1 展示了改进ShuffleNetV2 结构,本文将原结构中最大池化卷积层采用深度可分离卷积进行替换,实现了通道和区域的分离,增强了网络的特征提取能力同时也降低了参数量;使用全局池化层替换原结构中的全连接层进行特征融合,保留了前面卷积层提取到的空间信息,提升了网络的泛化能力。

表1 改进ShuffleNetV2 结构Table 1 Improve the structural ShuffleNetV2
2.2 Transformer 自注意力模块的融入
Transformer 整个网络结构由自注意力模块和前馈神经网络组成。Transformer 采用自注意力机制,将序列中的任意两个位置之间的距离缩小为一个定值,具有更好的并行性,符合现有的GPU 框架[28]。本文在改进ShuffleNetV2 中引入Transformer 自注意力模块,与原始网络相比,添加Transformer 模块可以提取到更加丰富的图像全局信息与潜在的特征信息,提升了模型的泛化能力。
本文融入的Transformer 块结构图如图2 所示,其主要由以下3 部分构成。

图2 Transformer 块结构Fig.2 Transformer block structure
高效自注意力层(Efficient Self-Attention)可以通过图像形状重塑,缩短远距离特征依赖间距,使网络更加全面地捕获图像特征信息[29]。自注意力公式如式(1)所示。
式中,(Wq,Wk,Wv)为权重矩阵,负责将X映射为语义更深的特征向量Q,K,V,而dk为特征向量长度。
高效自注意力层通过位置编码来确定图像的上下文信息,输出图像的分辨率是固定的,当测试集图像与训练集图像的分辨率不同时,会采用插值处理来保证图像尺度一致,但是这样会影响模型的准确率[30]。针对此问题,本文在高效自注意力层后连接混合前馈网络(Mix Feedforward Network,Mix-FFN)来弥补插值处理对泄露位置信息的影响。混合前馈网络计算公式如式(2)、式(3)所示:
式中,xin为上层输出;Norm 为归一化处理;MLP 为多层感知机;GELU 代表激活函数。
重叠块压缩层(Overlapping Block Compression,OBC)用于压缩图像尺寸和改变图像通道数,保留尺度稳定的特征,简化模型复杂度和降低冗余信息。
2.3 多尺度特征融合网络
原始YOLOv5s 的Neck 部分采用的是FPN+PAN 结构,FPN 是自顶向下,将高层的强语义特征向底层传递,增强了整个金字塔的语义信息,但是对定位信息没有传递。PAN 就是在FPN 的后面添加一个自底向上的路径,对FPN 进行补充,将底层的强定位信息传递上去。但是该结构的融合方式是将所有的结构图转换为相同大小后进行级联,没有将不同尺度之间的特征充分利用,使得最终的目标检测精度未达到最优。因此,本文采用一种更为高效的Bi-FPN 特征融合结构进行替代。其结构如图3 所示,相较于原始特征融合结构,BiFPN 能更有效的结合位于低层的定位信息与高层的语义信息,同时在通道叠加时将权重信息考虑进去,实现双向多尺度特征融合,通过不断调参确定不同分辨率的特征重要性,如式(4)所示。
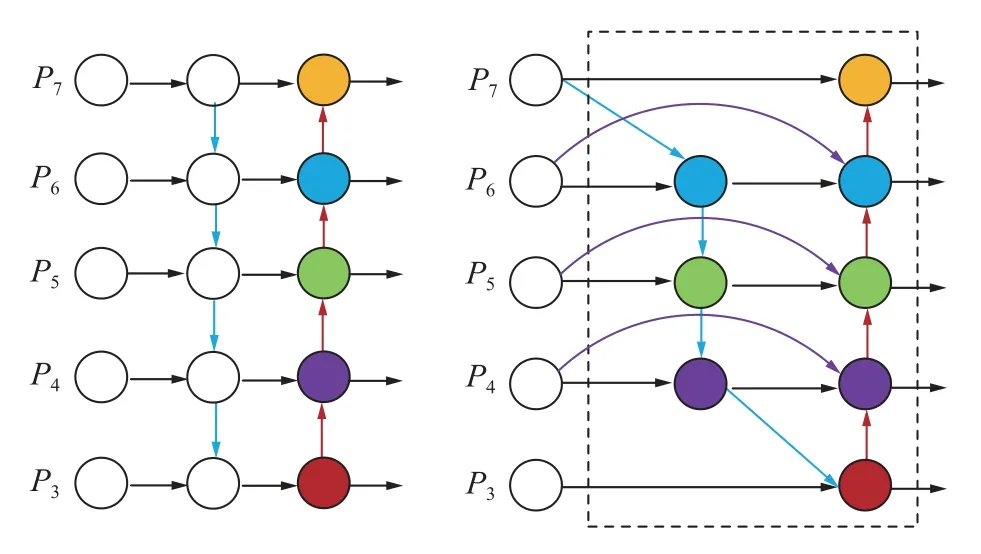
图3 BiFPN 结构Fig.3 BiFPN structure
式中,i为第i个权重;j为权重总个数;ln 为输入特征;Out 为输出特征;ωi为权重。
将主干网络中Transformer 模块提取出大小不同的特征图通过BiFPN 进行融合,可以更加有效地融合全局深浅层的信息与关键的局部信息,将第一次下采样得到的特征图与后面的特征图进行跨层连接,使得定位信息能够获取充分,提升了模型小目标的检测性能;在特征融合时删除对模型贡献较低的节点,在同尺度特征节点间增加跳跃连接,减少了计算量;最终在提高模型精度及泛化能力的同时降低了漏检率且几乎不增加运行成本。
3 DeepSORT 多目标跟踪算法及改进
使用本文提出的检测模型与改进DeepSORT 跟踪算法搭配实现对井下人员的跟踪,首先将监测图像输入到改进Yolov5s 目标检测网络,得到检测结果,然后通过改进DeepSORT 算法逐帧对人员进行匹配,得到他们的轨迹信息,最后输出跟踪图像。
3.1 DeepSORT 算法
DeepSORT 是针对多目标的跟踪算法,其核心是利用卡尔曼滤波和匈牙利匹配算法,将跟踪结果和检测结果之间的IOU (Intersection over Union,交并比)作为代价矩阵,实现对移动目标的跟踪。
为了跟踪检测模型找出的作业人员,DeepSORT使用8 维变量x 来描述作业人员的外观信息和在图像中的运动信息,如式(5)所示。
式中:(u,v)为 井下人员的中心坐标;γ为人员检测框的宽高比;q为 人员检测框的高;为 (u,v,γ,q)相应的速度信息。
DeepSORT 结合井下人员的运动信息与外观信息,使用匈牙利算法对预测框和跟踪框进行匹配,对于人员的运动信息,采用马氏距离描述卡尔曼滤波的预测结果和改进YOLOv5s 检测结果之间的关联程度,如式(6)所示。
式中:dj为 第j个检测框;yj为第i个检测框的状态向量;Si为i条轨迹之间的标准差矩阵。
当井下行人被障碍物长时间遮挡时,外观模型就会发挥作用,此时特征提取网络会对每个检测框计算出一个128维特征向量,限制条件为同时对检测到的每个人员构建一个确定轨迹的100 帧外观特征向量。通过式(7)计算出这两者间的最小余弦距离。
式中:rj为检测框对应的特征向量;rk为100 帧已成功关联的特征向量。
马氏距离在短时预测时提供可靠的目标位置信息,使用外观特征的最小余弦距离可使得遮挡目标重新出现后恢复目标 ID,为了使两种度量的优势互补,最终将两种距离进行线性加权作为最终度量,公式如式(8)所示。
式中:λ为权重系数,若ci,j落在指定阈值范围内,则认定实现正确关联。
3.2 DeepSORT 算法的改进
原始DeepSORT 的外观特征提取采用一个小型的堆叠残差块完成,包含两个卷积层和六个残差网络。该模型在大规模路面行人检测数据集上训练后,可以取得很好的效果,但是井下环境光照不均匀,烟尘干扰严重,导致对井下人员跟踪的效果不理想,于是本文采用高效特征提取架构OSA(one shot aggregation)来替代原DeepSORT 外观模型中的堆叠残差块以强化DeepSORT 的外观特征提取能力,有效的提取图像中的全局特征和深层信息,达到减少人员编码切换次数的作用,OSA 结构如图4 所示。
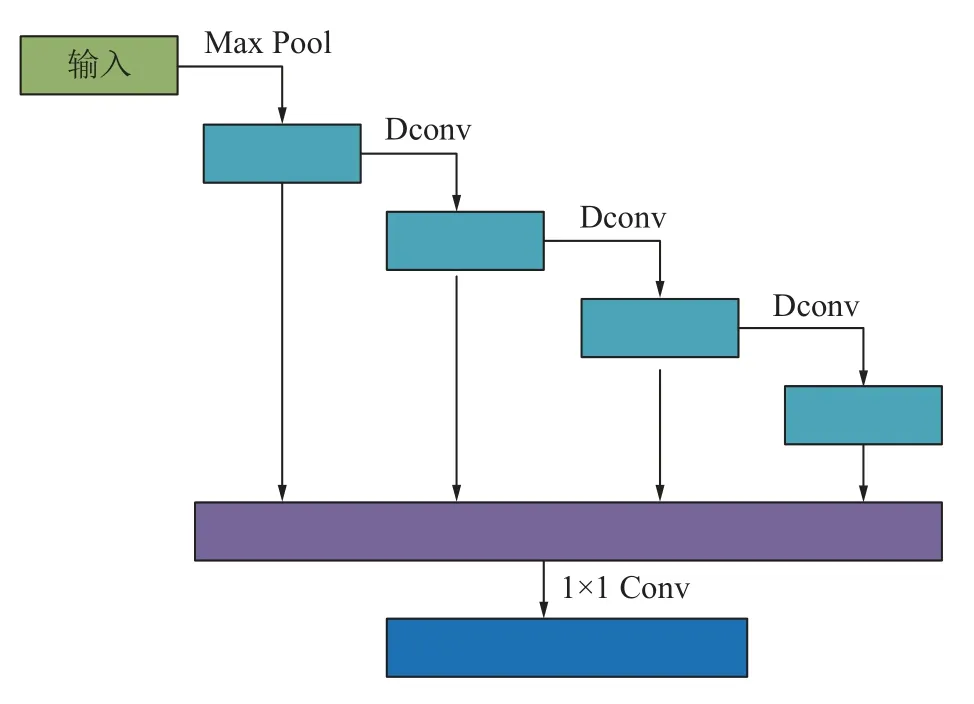
图4 OSA 结构Fig.4 OSA structure
在外观状态更新时,采用指数平均移动的方式替代特征集合对第t帧的第i个运动轨迹的外观状态进行更新。如式(9)所示。
4 试验与分析
4.1 试验准备
本文采用Caltech 行人数据集(Caltech Pedestrian Detection Benchmark)、INRIA 行人数据集(INRIA Person Dataset)及自建井下人员检测及跟踪数据集对所提检测及跟踪算法井下进行验证。
1) Caltech 行人数据集:此数据集为目前规模较大的行人数据集,使用车载摄像头录制不同天气状况下10 h 街景,拥有人员遮挡、目标尺度变化大、背景复杂等多种情形,标注超过25 万帧,35 万个矩形框,2 300 个行人。同时注明了不同矩形框之间的时间关系及人员遮挡情况。
2) INRIA 行人数据集:此数据集为目前常见的静态人员检测数据集,数据集中人员身处不同光线条件及地点。训练集拥有正样本1 000 张,负样本1 500张,包含3 000 个行人;测试集包含正样本350 张,负样本500 张,包含1 200 个行人,该数据集人员以站姿为主且高度均超100 个像素,图片主要来源于谷歌,故清晰度较高。
3)自建井下人员检测及跟踪数据集:采集井下巡检机器人与监控视频拍摄的10 万帧图像,筛选其中8 000 帧相似程度较低的图像构建数据集。首先使用ffmpeg 工具将图像按帧切为图片,其中涵盖井下各种环境:光照不均2 267 张、煤尘严重1 568 张、目标遮挡3 891 张、其余环境1 200 张。其次采用Python 编写的Labelimg 对图片中人员进行标注,自动将人员位置及尺寸生成xml 文件,最终转为适用于yolo 系列的txt 文件,包含每张图片中人员的中心位置(x,y)、高(h)、宽(w)三项信息。如图5 所示,该数据集包含上万个人工标记的检测框。由于本文算法应用于井下人员的检测及追踪,故数据集中仅含“person”一个类。将图片数量按照7∶2∶1 分为训练集、验证集和测试集。

图5 自建井下人员检测及跟踪数据集Fig.5 Self-built downhole personnel detection and tracking data sets
试验使用平台参数如下:

检测算法评价指标:使用模型参数量、检测时间、召回率Mr、准确率Mp、漏检率Mm,误检率Mf及mAP@0.5 作为检测算法的评价指标。
式中:Tp为被正确检测出的井下人员;FN为未被检测到的井下人员;FP为被误检的井下人员;TN为未被误检的井下人员;mAP 为不同召回率上正确率的平均值。
跟踪算法评价指标:
1)编码变换次数(ID switch,IDS),跟踪过程中人员编号变换及丢失的次数,数值越小说明跟踪效果越好。
2)多目标跟踪准确率(Multiple Object Tracking Accuracy),用于确定目标数及跟踪过程中误差累计情况,如式(15)所示。
式中:Mm为漏检率;Mf为误检率;IDS为编码转换次数;GTt为目标数量;n为图片数量;t为第t张图片。
3)多目标跟踪精度(Multiple Object Tracking Precision,PMOT),用于衡量目标位置的精确程度,如式(16)所示。
式中:dt,i为目标i与标注框间的平均度量距离;ct为t帧匹配成功的数目。
4)每秒检测帧数 (Frames Per Second,FPS)及模型参数量,体现模型运行的速率及成本。
4.2 目标检测试验结果与分析
将本文算法通过自建井下人员检测及跟踪数据集进行训练,输入图像大小为 608×608,迭代次数为300,批次大小为 16,初始学习率设置为 0.01,后 150轮的训练学习率降为 0.001。动量设置为0.937,衰减系数为0.005。训练损失变化如图6 所示。可以看出模型三类损失函数收敛较快且都收敛于较低值,表明改进算法具有良好的收敛能力与鲁棒性。

图6 损失函数曲线Fig.6 Loss function curve
为了验证本文改进检测算法的有效性以及轻量化主干网络选择的合理性,将本文算法与YOLOv5s模型和YOLOv5s-ShuffleNetV2 通过自建井下人员检测及跟踪数据集进行对比。
从图7 中可以看出,原始YOLOv5s 算法迭代到40 次时,准确率上升到0.86 左右,最终收敛在0.87 左右;YOLOv5s-ShuffleNetV2 在迭代到40 次时,准确率上升到0.84 左右,最终收敛在0.85 左右;而本文所提算法在迭代40 次时,准确率上升到0.91 左右,最终收敛在0.92 左右,较原始YOLOv5s 模型提升了5.1%。
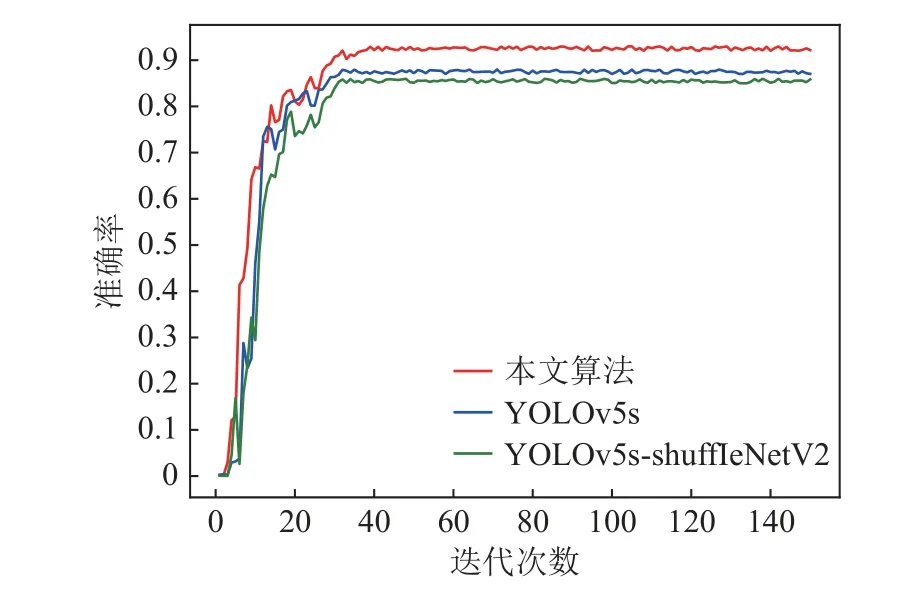
图7 准确率曲线Fig.7 Accuracy rate curve
从图8 中可以看出,原始YOLOv5s 算法在迭代到40 次时,mAP上升到0.85 左右,最终收敛在0.86左 右;YOLOv5s-ShuffleNetV2 在迭代到40 次时,mAP上升到0.85 左右,最终收敛在0.85 左右;而本文算法的迭代到40 次时,mAP上升到0.89 左右,mAP最终收敛在0.90 左右,较原始YOLOv5s 模型提升了5.2%。综上所述,本文选取的轻量化网络ShuffleNetV2 可以使得检测模型保持一定精度的同时降低计算量;轻量化主干的改进、注意力机制的引入以及多尺度的融合对于目标检测性能有着明显的提升,因此,本文检测算法对于井下复杂环境中的人员检测具有良好的精度。
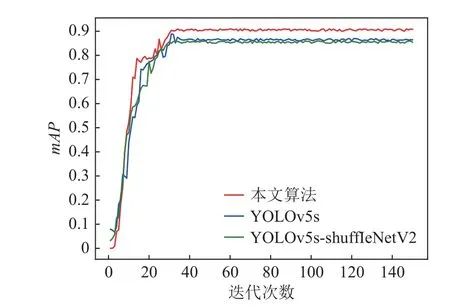
图8 mAP 曲线Fig.8 mAP curve
在YOLOv5s 算法的基础上进行了改进轻量化主干网络的替换ShuffleNetv2、Transformer 自注意力机制模块的融入、Neck 部分进行BiFPN 的替换。为了检验本文对检测阶段各改进点的有效性,以YOLOv5s 模型为基准,使用消融实验在相同环境下进行进行验证,各模型参数设置保持一致,具体消融试验结果见表2。

表2 消融试验结果Table 2 Ablation results
由表2 可以看出,原始YOLOv5s 的主干网络替换后,准确率下降了1.4%,速率提升了34%。在模型2 中添加Transformer 自注意力模块后,准确率提升了2.8%。在模型2 中使用BiFPN 替代原来的特征融合结构后,准确率提升了2.1%。在模型2 中同时添加Transformer 自注意力机制模块和BiFPN 模块,准确率提升了7.4%,平均漏检率下降了40%,召回率提升了8.4%,平均误检率下降了51%。综上所述,单独添加Transformer 自注意力模块和BiFPN 模块,井下人员检测性能提升有限,而两种模块组合添加时,井下人员检测性能获得了很大的提升。相比于原始算法,准确率提升了5.2%;参数量下降了41%;检测速率提升了21%,达到0.014 8 s/帧;为部署于巡检机器人奠定了基础。
为了验证文中检测算法具有良好的泛化能力,在2 个公开行人数据集Caltech 行人数据集、INRIA行人数据集上进行进一步验证,性能指标对比见表3。通过比较3 个不同数据集中的性能指标,可以看出文中算法不仅适用于井下人员检测,在目标尺度变化大、背景复杂、光照剧烈等多数场景中人员检测效果也均优于原始YOLOv5s,因此,具有良好的泛化性与鲁棒性。
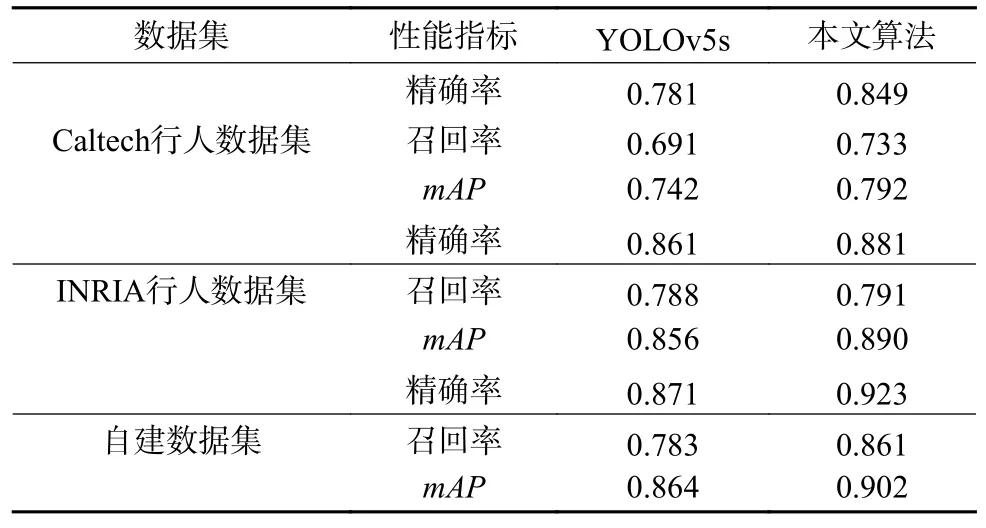
表3 多数据集性能指标对比Table 3 Comparison of performance indicators of multiple data sets
为了更加直观地体现文中检测算法的效果,选择 Faster-RCNN、YOLOv3、YOLOv4、YOLOv5s 4 种主流算法在自建数据集中选取光照不均、煤尘干扰、多目标移动、人员遮挡4 种场景进行验证,检测结果如图9 所示。

图9 主流目标检测结果对比Fig.9 Comparison of detection results of mainstream targets
从第一组试验中,可以观察到光照不均严重,Faster-RCNN、YOLOv3、YOLOv4、YOLOv5s 均出现误检的情况,而本文算法使用了BiFPN 结构使得多尺度特征能够有效融合,对于远处小目标检测能够起到了很好的识别作用。从第二组试验中,可以观察到粉尘干扰严重,除文中算法外,其余算法出现漏检、误检的情况,而文中算法由于融合了Transformer 自注意力模块强化了模型深浅特征的全局提取能力,提升了目标在复杂环境中的对比度,有效抑制了粉尘的干扰。从第三、四组试验得出,本文算法对于井下环境中多目标移动对象及遮挡人员的检测也具有良好的效果。综上所述,文中检测算法在井下各种复杂环境中检测效果良好,与主流目标检测算法相比更适用于井下人员的检测。
4.3 井下人员跟踪结果与精度分析
为了验证文中算法在井下人员多目标跟踪方面的表现,本文通过自建井下人员检测及跟踪数据集上进行验证,以YOLOv5s-DeepSort 为基准,使用原算法的参数设置,对检测与跟踪阶段进行消融试验来验证文中两阶段改进各自的有效性,结果见表4。

表4 多目标跟踪结果对比Table 4 Comparison of multi-target tracking results
由表4 得出,文中目标检测阶段的改进在有效提升井下人员的检测精度的同时提升了检测速度,而跟踪阶段的改进有效减少了人员编号的转换,可以在出现人员遮挡的情况下有效提升检测的精度。文中检测及跟踪算法最终达到89.17%的精度;速率达到67 帧;人员编码改变次数仅4 次,目标编号改变次数降低了66.7%;参数量缩减到原始跟踪算法的23%。可以很好的满足井下人员实时检测及跟踪的需求。
为了更加直观展示文中跟踪算法的效果,文中选用戴德KJXX12C 型防爆矿用巡检机器人进行验证,如图10a 所示,该装置搭载本安型“双光谱”摄像仪,最小照度达彩色0.002 lux,高粉尘环境下,可通过红外摄像仪辅助采集井下图像。采集与控制系统采用STM32ZET6 芯片,上位机检测及跟踪主控系统采用Windows 版工控机。图像信息会通过千兆无线通讯传输在远端上位机,将环境运行代码安装于上位机。图像信息经过本文算法处理,结果将存储并实时显示于主控界面,如图10b 所示,主控界面采用CS 架构,由C#语言编写。监测人员通过主控界面实时及历史数据对工作面作业人数是否合格进行判断。
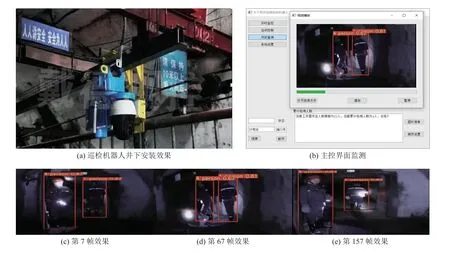
图10 巡检机器人多目标跟踪效果Fig.10 Inspection robot multi-target tracking effect
从图10c,图10d,图10e 中可以观察到,在井下光照不足的环境中,井下2 个作业人员相互遮挡并且持续行走一段距离后,巡检机器人能够进行稳定的检测跟踪并且其编号没有发生改变,实现有效计数,也能够证明我们改进的算法在复杂环境中出现井下人员遮挡时,也会在后续帧中匹配到被遮挡人员,对于遮挡情况具有良好的鲁棒性。
5 结论
1) 提出了一种改进YOLOv5s 和DeepSORT 的井下人员检测及跟踪算法。在YOLOv5s 模型的基础上,使用轻量化网络ShuffleNetV2 替换了原主干网络CSP-Darknet53,减少了模型的参数量。同时融入Transformer 自注意力模块,可以提取到更多潜在的特征信息。使用多尺度特征融合网络BiFPN 替换原Neck 结构,能更好的融合全局深浅层信息与关键的局部信息。跟踪阶段使用更深层卷积强化了DeepSORT 的外观信息提取能力。
2) 利用自建井下人员检测及跟踪数据集对本文算法进行验证。结果表明,本文井下人员检测算法的准确率达到了92%,检测速率达到0.0148 s/帧。多目标跟踪算法准确率提高到了89.17%,目标编号改变次数降低了66.7%,并且拥有良好的实时性。
3) 构建的改进YOLOv5s 和DeepSORT 的井下人员检测与跟踪算法能够实现在井下复杂环境中对人员的实时检测及跟踪,其参数量也缩减到原来的23%,不仅可以部署于煤矿监控系统,也可以部署在井下巡检机器人等小型嵌入式设备上,可以为井下人员的安全生产提供良好的保障。对于国家矿山安全监察局出台的《煤矿井下单班作业人数限员规定》早日实现智能化监测具有重要意义。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
作文小学中年级(2020年6期)2020-07-24 08:33:10
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
河南科技(2014年23期)2014-02-27 14:19:15
自然资源遥感(2014年3期)2014-02-27 11:56:38
