
基于改进YOLOv5s的茶叶嫩芽分级识别方法
2023-11-22 04:46胡和平吴明晖洪孔林张海峰
江西农业大学学报 2023年5期
胡和平,吴明晖,洪孔林,张海峰
(上海工程技术大学 机械与汽车工程学院,上海 201620)
【研究意义】中国茶园面积和茶叶产量都居世界第一,茶叶在中国乃至世界都是很受欢迎的饮品[1]。茶叶采摘是生产过程的重要环节,对茶叶品质影响较大。目前采摘茶叶嫩芽主要依靠人工和机械化采摘。人工采摘茶叶嫩芽成本高,且效率较低;机械化采摘效率有一定提高,但无法精准区分茶叶的老叶和嫩芽且无法保证茶叶嫩芽的完整性。随着社会的发展,人们对茶叶的品质有不同需求。为了解决上述问题,需要研究更加智能化的机器设备对茶叶嫩芽进行精准的实时品质分级识别,以完成对不同品质茶叶嫩芽的采摘,因此对茶叶嫩芽品质分级识别方法的研究具有重要意义。【前人研究进展】目前完成茶叶嫩芽识别主要是采用图像分割方法提取茶叶嫩芽的颜色或者形状特征,分割出茶叶嫩芽图像。如刘自强等[2]使用HSI 颜色空间模型提取茶叶嫩芽颜色特征,对转换颜色空间的茶叶图像二值化后,提取茶叶嫩芽形状特征;邵佩迪等[3]对茶叶图像进行滤波去噪等预处理后,将茶叶图像颜色通道互换对调,增加茶叶嫩芽对比度,提取颜色特征,分割识别出茶叶嫩芽;吴雪梅等[4]使用Ostu法K-means聚类法对茶叶嫩芽进行识别实验,结果表明基于Lab 颜色模型的K-means 聚类法识别效果较好。近年来,随着计算机视觉和图像处理技术的发展,使用深度学习网络算法进行目标检测的研究逐渐增多。许高建等[5]选用三种基础网络不同的Faster R-CNN 算法和SSD 算法分别对茶叶嫩芽图像数据集训练,结果表明采用 VGG-16网络作为主干网络的Faster R-CNN 算法识别准确率较高,但检测速度较慢。王子钰等[6]提取茶叶嫩芽颜色特征后使用SSD 目标检测算法训练,识别准确率有所提高,但小目标茶叶识别效果较差。孙肖肖等[7]改进了YOLO 算法的特征提取网络,对茶叶嫩芽的平均识别精度有很大提高。王梦妮等[8]通过改进YOLOv5s 模型的主干网络和颈部网络,对茶叶嫩芽进行多场景检测,置信度分数较高。张晓勐等[9]使用轻量化网络替换YOLOv4 主干网络,更换轻量化激活函数,改进后的模型各项性能指标表均优于对照模型。毛腾跃等[10]等使用ResNet-50特征网络改进CenterNet模型,改进后模型的识别效果比同类无预处理识别方法要好。【本研究切入点】综上,基于颜色和形状特征的传统图像分割算法研究较多,应用简单,但存在识别速度慢、难以实时识别、环境适应性差等缺点;二阶段的R-CNN 系列[11-12]目标检测算法检测精度虽高,但检测速度慢,远不能满足对茶叶嫩芽的实时识别检测需求;一阶段的YOLO[13]系列和SSD[14]目标检测算法适合多尺度目标检测,且兼具速度快、精度高等优点,满足茶叶嫩芽的实时检测需求。【拟解决的关键问题】针对茶园复杂环境下茶叶嫩芽识别准确率低、速度慢和鲁棒性差等目前茶叶嫩芽识别检测存在的问题,对YOLOv5s算法的网络结构改进,提高各等级茶叶嫩芽识别准确率,减少漏检和误检,为不同品质茶叶嫩芽的精准实时识别和茶叶嫩芽的自动化采摘提供技术支持。
1 材料与方法
1.1 茶叶嫩芽数据集制作
1.1.1 数据采集 选择在上海市金山区沪枫茶叶种植基地进行茶叶嫩芽的图像采集,茶叶品种主要为大红袍和龙井;图像采集设备为小米10S 和英特尔RealSense D435 双目深度相机,相机分辨率为5 792×4 344 和1 920×1 080 像素;图像采集于2023 年4 月中旬和5 月上旬进行,拍摄时间为08:00 至18:00;拍摄角度与竖直向上方向夹角为0~90°夹角,拍摄距离为10~50 cm,共拍摄茶叶图像600余张,以此构建实验所用数据集。为增加实验的可信度,拍摄时选择从多种不同的角度、距离、目标区域进行茶叶图像拍摄,如下图1所示。拍摄完成后,为减少处理设备内存和显存的消耗,加快图像的处理速度,对茶叶图像进行预处理。

图1 不同角度和距离拍摄茶叶嫩芽Fig.1 Tea shoots from different angles and distances
1.1.2 数据增强 由于茶叶嫩芽图像的采集具有时间限制,且基于深度学习的目标检测算法的参数和非线性操作过多,训练数据样本较少,易出现过拟合现象,导致训练效果不佳。因此需要对拍摄的茶叶图像进行数据增强处理,满足深度学习训练算法模型对大量图像数据的需求,提高目标检测算法训练模型的鲁棒性。数据增强主要包括镜像、旋转、添加噪声等操作,如下图2所示。

图2 茶叶嫩芽数据增强Fig.2 Enhancement of tea bud data
对拍摄的茶叶图像数据集进行初步人为挑选后,得到500 张样本数据,对样本数据进行数据增强处理后,茶叶图像数据集增加到4 000张。完成茶叶图像数据集扩增后,将其划分为训练集、验证集和测试集,3种数据集分配比例为8∶1∶1,分配数目分别为3 200、400、400。
1.1.3 数据标注 茶叶的等级划分标准比较多样,由茶叶的外部形状和色泽质量,可将茶叶分为多个不同的等级;由茶叶嫩芽和叶片的数目,可分为一芽一叶、一芽两叶、一芽三叶。结合大部分茶叶生产商的划分标准,本研究对茶叶品质分级的划分为:单芽(特级)、一芽一叶(一级)、一芽两叶(二级)和一芽三叶(三级)[15],茶叶嫩芽的品质分级标准如下图3所示。

图3 茶叶嫩芽分级示意图Fig.3 Schematic diagram of tea quality classification
茶叶嫩芽的分级标准确定后,需要对茶叶嫩芽图像进行手动标注,标注软件为LabelImg。确定标注文件的格式和对应保存路径后,由茶叶嫩芽的品质分级标准,使用矩形框对图像中的茶叶嫩芽标注不同等级。茶叶嫩芽的目标标注主要分为4类,如下表1所示,标注文件以 TXT文件的形式保存。

表1 各个等级茶叶嫩芽标注名称Tab.1 Labels of tea buds of different grades
1.2 YOLOv5目标检测算法
YOLO(You Only Look Once)属于一阶段目标检测算法,核心思想是将目标检测转换为回归问题,通过主干网络提取特征后,进行类别和位置预测,从而完成目标识别检测。与二阶段目标检测算法相比,一阶段的YOLO 算法在识别精度无明显下降的情况下,模型的运行速度有较大提高,且能够进行实时目标识别。
YOLO系列的YOLOv5算法是基于YOLOv4的改进算法,可同时识别检测多类别不同大小的目标,其中的YOLOv5s 网络模型较小,检测速度较快,因此本文选择将YOLOv5s 网络作为基础研究模型。YOLOv5s网络的组成结构为输入端、主干网络、中间层、输出端4部分。输入端(Input)部分对输入图片进行缩放和数据增强,并计算最佳锚框值;主干网络(Backbone)主要由Conv结构和C3结构组成,提取主要特征;中间层(Neck)采用FPN+PAN 的结构,连接 Backbone和 Prediction,用于提取更复杂的目标特征;输出端(Prediction)用于预测目标的类别和位置。YOLOv5s的网络结构图如下图4。
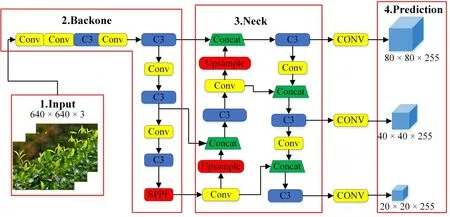
图4 YOLOv5s网络结构图Fig.4 YOLOv5s network structure
1.3 改进YOLOv5s目标检测算法
1.3.1 CBAM 注意力机制 CBAM 注意力机制(convolutional block attention module)是由通道和空间注意力机制组成,其总体结构如下图5所示。特征图输入通道注意力模块后,进行全局最大和平均池化,获得两张不同维度的特征图。这两张特征图通过两个全连接层分别下降和扩张通道数,之后进行通道维度堆叠,经sigmoid 激活函数处理后,将归一化的权重与输入特征图相乘,输出处理后的特征图。通道注意力模块输出的特征图进入空间注意力模块后,对输入特征图在通道维度下进行最大和平均池化,输出的特征图进行通道维度堆叠后,使用卷积层融合通道信息,卷积后的结果经过sigmoid 函数对特征图的空间权重归一化,并和输入特征图相乘,得到最终处理结果。
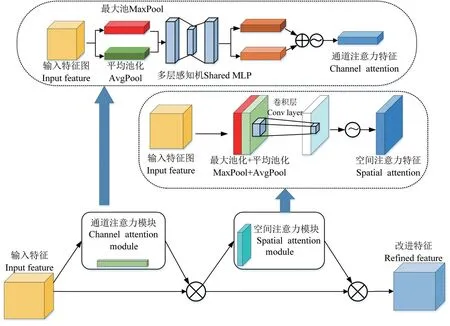
图5 CBAM注意力机制结构图Fig.5 Structure of CBAM’s attention mechanism
CBAM 注意力机制是一种即插即用的模块,可以直接嵌入到网络架构中,但插入不同的位置,会有不同的检测效果。为确定CBAM 注意力机制的最优嵌入位置,在YOLOv5 网络结构的每个尺寸的特征检测层前分别加入CBAM 注意力机制,并使用已有数据集进行相关实验。实验结果如表2 所示,YOLOv5-3 平均检测精度与召回率提高较多,表明CBAM 注意力机制嵌入到YOLOv5 算法的主干网络(Backbone)后部,算法的识别检测效果较好。

表2 CBAM 嵌入YOLOv5不同位置对比实验Tab.2 Comparison experiment of different positions of CBAM embedded in YOLOv5
1.3.2 微小目标检测层 目前的目标检测算法存在下采样率和感受野过大、语义与空间矛盾、缺乏特征融合等缺点,对于小目标物体的检测效果较差。YOLOv5s网络结构进行目标检测时,其三个不同尺度的特征检测层,能够对多尺度目标进行检测,但对微小物体的目标检测可能存在漏检或检测效果不佳等问题,因此需要添加一个微小物体的特征检测层,来提高小目标物体的识别检测效果。
为使微小目标有较好的识别检测效果,本研究在YOLOv5s 多特征融合结构增加微小目标特征检测层。微小目标特征检测层在主干网络中进行了两次采样操作,提取浅层特征,在颈部网络中两个P2 层特征与主干网络中的同尺度特征通过Concat形式融合特征,最后输出三方面的融合特征,分辨率为160×160像素。添加的微小目标特征检测层的结构图如下图6所示。

图6 微小目标特征检测层结构图Fig.6 Structure of micro target feature detection layer
1.3.3 改进YOLOv5s网络结构 对于茶叶嫩芽的分等级识别目标,不但要考虑茶叶嫩芽的语义特征,还需考虑茶叶嫩芽的空间位置,因此在YOLOv5s 算法主干网络最后的位置嵌入CBAM 注意力机制,加强YOLOv5s 算法的主要特征提取能力,自适应提取茶叶嫩芽的关键特征,降低非关键特征的干扰,同时可以节约参数和计算力。
在实际应用场景中,茶叶嫩芽的目标较小,YOLOv5s 网络提取的特征图经过多次卷积后,容易丢失小目标茶叶的特征信息,尤其是单芽茶叶,识别效果较差。针对上述缺点,本研究在YOLOv5s 网络结构中增加微小目标特征检测层,将浅层与深层特征图拼接融合后进行检测,以提高小目标茶叶的识别准确率,减少漏检和误检情况。
在YOLOv5s算法主干网络后嵌入CBAM 注意力机制的同时,增加微小目标特征检测层,对YOLOv5s算法进行改进,改进的YOLOv5s算法的网络结构如图7所示。

图7 改进后的YOLOv5s网络结构图Fig.7 Network structure of the improved YOLOV5s
1.4 YOLOv5s损失函数计算
损失函数表示模型预测值和真实值的偏离程度。对已经完成标注的数据集进行大量轮数的训练后,损失函数逐渐变小,最终稳定下来,此时的损失函数最小,可得到主干网络各项参数。在对数据集进行训练后,需要计算训练模型的损失值,损失值越小,模型的预测值和真实值越接近,模型的性能越稳定准确。
YOLOv5s共有三种损失函数:分类损失(Lcls),定位损失(Lbox),置信度损失(Lobj)。分类损失是计算标注框与其分类是否一致;定位损失是预测框与手动标注框之间的误差;置信度损失是计算网络的置信度。三种损失函数的加权和即是总损失函数,计算公式如下:
式(1)中,a、b、c 表示相应损失函数在总损失函数中的权重占比,其中置信度损失权重较大,定位损失和分类损失权重较小,本研究中a、b、c的取值分别为0.4、0.3、0.3。定位损失采用CIOU_Loss函数计算,分类损失和置信度损失使用二元交叉熵函数(BCEWith LogitsLoss)计算。
2 实验与分析
2.1 试验平台
本研究各个算法网络进行模型训练和测试的计算机处理器型号为Intel(R)Core(TM)i5-8300H,GPU型号为NVIDIA GeForce GTX1050Ti,运行内存为8 GB;软件运行系统为windows 10,深度学习框架为Pytorch1.7.1,开发环境为Python3.8.3,运算架构为Cuda11.0。
2.2 评价指标
在进行基于深度学习的茶叶嫩芽识别模型的训练过程中,对于训练模型的优劣,常用评价指标有精确率(precision)、平均精确率(average precision)、召回率(recall)、平均精确率均值(mean average precision)等。经分析,本文引入P、R、AP和MAP为茶叶嫩芽目标识别算法的评价指标。
式(2)和式(3)中:TP表示正样本正确框选为正样本的数量;FP为负样本错误的框选为正样本的数量;FN为正样本错误的框选为负样本的数量。公式(4)中AP是P-R曲线与坐标轴围成区域的面积,P表示预测正确率,R表示实际正确率。公式(5)中APi为第i类的平均准确率,N为类别数量。MAP表示所有类别茶叶嫩芽的识别精确度均值。
2.3 模型训练
本研究实验均在相同计算机软硬件条件下进行训练、验证和测试,安装好相关环境配置后,使用YOLOv5s 模型进行预训练,便于加速后续网络训练。进行预训练后,使用改进的YOLOv5s 算法在GPU上对已经构建好的茶叶图像数据集进行训练,设置训练轮数epoch 为500,单次输入图片数目batch_size为4,初始的学习率为0.001,输入图片分辨率为640×640。
训练结束后,对改进的YOLOv5s 算法下训练的模型可视化,可得到改进的YOLOv5s 算法在训练集和验证集下的损失值数据以及其他各项指标在验证集下的训练数据,训练结果如下图8和图9所示。随着训练轮数的增加,模型损失值逐渐减小,到450次左右时,损失曲线趋于收敛稳定。由模型训练数据和上文的损失值公式(1)可得改进的YOLOv5s 算法的训练集的总损失值为0.018 6,验证集的总损失值0.016。总损失值接近于0,证明训练的模型较稳定,可用于茶叶嫩芽的分等级识别,此时的训练权重best.pt可以作为茶叶嫩芽识别模型的权重。

图8 改进YOLOv5s算法损失曲线Fig.8 Improved YOLOv5s algorithm loss curve

图9 改进的YOLOv5s算法各项性能指标Fig.9 The performance indicators of the improved YOLOv5s algorithm
2.4 消融实验
为验证改进的YOLOv5s 算法对提高茶叶嫩芽识别效果的有效性,通过消融实验评估各个改进模块对茶叶嫩芽识别效果的影响。在相同计算机软硬件条件下,对相同的茶叶图像数据集,使用原YOLOv5s、YOLOv5s+CBAM、YOLOv5s+Microdetect、Improved YOLOv5s 4 种网络进行模型的训练和测试,实验结果如表3 所示。其中YOLOv5s-CBAM 表示YOLOv5s 主干网络后嵌入CBAM 注意力机制,YOLOv5s+Microdetect 表示YOLOv5s 算法增加微小目标检测层,Improved YOLOv5s 表示YOLOv5s 算法主干网络后嵌入CBAM 注意力机制的同时,增加微小目标特征检测层,是本研究提出的改进的YOLOv5s 算法。
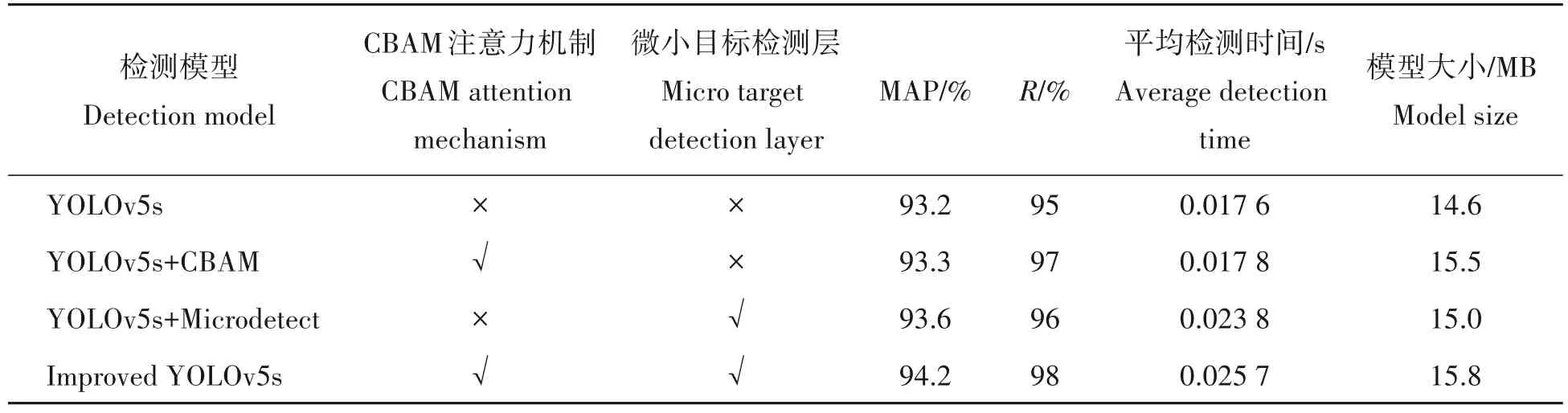
表3 不同策略消融实验对比Tab.3 Comparison of ablation experiments with different strategies
由表3 可知,在YOLOv5s网络结构中单独增加CBAM 注意力机制或者微小目标特征检测层时,模型的检测平均正确率、召回率、平均检测时间以及模型大小均有小幅度提高;Improved YOLOv5s 算法中同时添加这两个改进模块,相对于前两种算法,改进算法训练的模型的检测平均正确率、召回率提高较多;改进算法中引进了两个新的模块,提高了网络结构的复杂度和计算量,使得改进模型的检测速度和大小均有所提高,但对茶叶嫩芽的分级识别影响较小,仍然满足实时识别要求。消融实验证明,改进的 YOLOv5s 算法在主干网络后嵌入CBAM 注意力机制的同时,增加微小目标特征检测层,可以有效提高茶叶嫩芽识别效果。
2.5 对比实验及数据分析
为体现提出的改进的YOLOv5s 算法对提高茶叶嫩芽识别效果的优越性,使用Faster-RCNN、SSD、YOLOv3、YOLOv4、YOLOv5s 以及改进后的YOLOv5s 目标检测算法进行对比实验。6 种目标检测算法对已经制作的茶叶嫩叶图像数据集对进行训练,得到最优模型之后,在测试集上进行测试,各个目标检测算法对各个等级茶叶嫩芽的识别平均精确度(AP)如图10所示,各个目标检测算法对茶叶嫩芽识别的各项性能指标如表4所示。
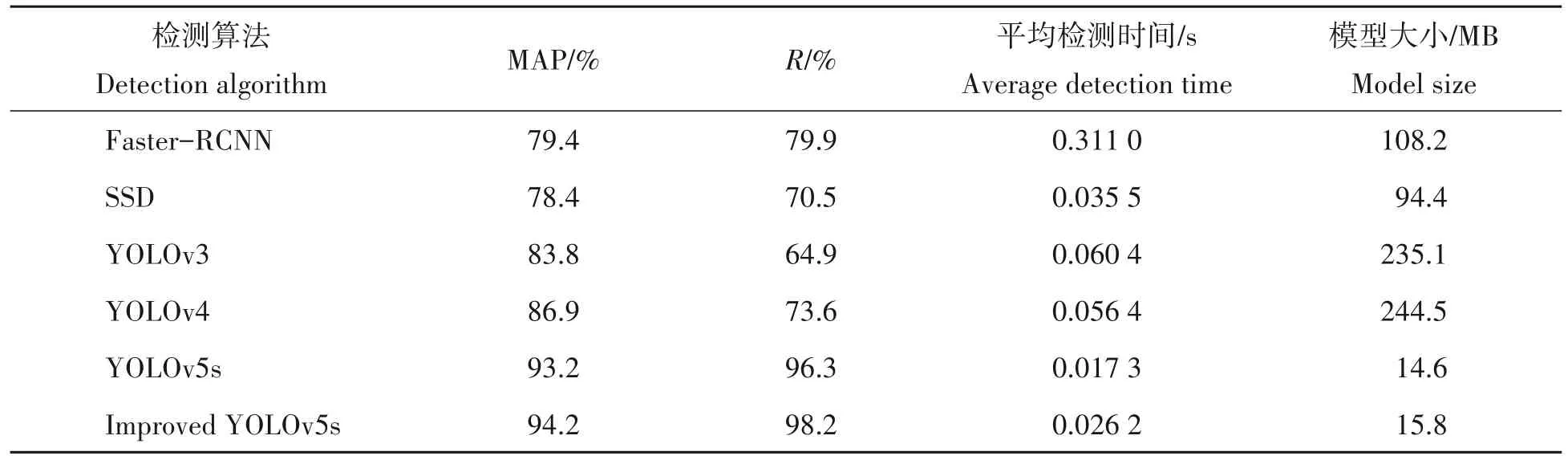
表4 不同检测算法实验结果对比Tab.4 Comparison of experimental results of different detection algorithms
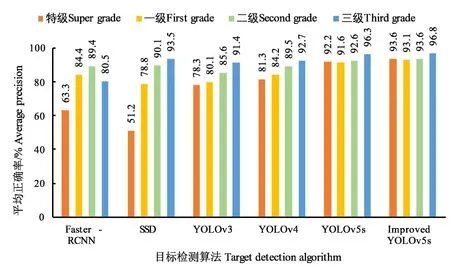
图10 6种算法对各等级茶叶嫩芽的识别平均精确度Fig.10 Average accuracy of the six algorithms in identifying tea buds of each grade
由上图10可知,对比实验使用的Faster-RCNN、SSD、YOLOv3和YOLOv4这4种主流目标检测算法对各个等级茶叶嫩芽识别的平均精确度均低于YOLOv5s算法和改进的YOLOv5s算法,其中对目标较小的特级和一级茶叶嫩芽识别平均精确度较低,Faster-RCNN 和SSD 算法对特级茶叶嫩芽识别AP 为63.3%和51.02%;对目标较大的二级和三级茶叶嫩芽识别平均精确度稍高。由图10可知,改进的YOLOv5目标检测算法对各个等级茶叶嫩芽识别的平均准确率较高,其中单芽(特级)的识别AP为93.6%,一芽一叶茶叶的识别AP为93.1%,一芽二叶茶叶的AP为93.6%,一芽三叶茶叶的识别AP为96.8%。改进的YOLOv5算法与原YOLOv5s 算法相比,特级、一级、二级、三级茶叶的识别AP 分别提高了1.4%、1.5%、1%、0.5%。因此,改进后的YOLOv5s算法对各等级茶叶嫩芽的识别精确度要优于原YOLOv5s算法和其余几种主流算法,尤其是对单芽和一芽一叶的识别AP提高较多。
由上表4 可知,Faster-RCNN、SSD、YOLOv3 和YOLOv4 这4 种主流目标检测算法对所有等级茶叶嫩芽的识别平均精度(MAP)和召回率(R)低于改进后的YOLOv5s 算法与原YOLOv5s 算法较多,且检测速度相对较慢,识别模型较大,不适合移动设备使用,不满足对茶叶嫩芽高精度分等级实时识别的要求。改进后的YOLOv5s 算法与原YOLOv5s 算法相比,对茶叶嫩芽的识别MAP 提高了1 个百分点,召回率提高了1.9个百分点,因对YOLOv5s网络的改进,提高了算法网络结构的复杂度和计算量,导致了算法检测速度和识别模型均有微小提高,但对茶叶嫩芽的分等级识别影响较小,满足对茶叶嫩芽高精度分等级实时识别的要求。
综上,改进的YOLOv5s算法对各个等级的茶叶嫩芽识别的平均精确率较高,尤其对尺寸较小的单芽和一芽一叶茶叶的识别AP 提高较多,平均检测时间较短,网络模型相对较小,适合在移动设备上使用。因此,改进的YOLOv5s算法综合检测性能较佳,能够满足对茶叶嫩芽进行高精度分等级实时识别检测的要求。
2.6 识别效果及效果分析
为验证改进算法的实际识别检测效果的提高,使用SSD、YOLOv5s 和改进的YOLOv5s 算法,从测试集中随机抽取0°角、45°角、近距离、远距离拍摄的茶叶嫩芽图像进行识别检测,识别结果如下图11所示。由识别检测结果可得Faster-RCNN、SSD、YOLOv3 和YOLOv4 这4 种主流目标检测算法对茶叶嫩芽的识别效果较差,漏检误检较多;YOLOv5s 算法存在少量漏检误检情况;改进的YOLOv5s 算法对各个等级的茶叶嫩芽均能准确识别,其中对尺寸较小的单芽和一芽一叶茶叶识别效果明显提高,漏检和误检大大减少,更适合完成对茶叶嫩芽的分等级识别工作。

图11 多种目标检测算法对茶叶嫩芽的分级识别效果Fig.11 Effect of multiple target detection algorithms on classification of tea buds
3 讨论
通过对实验数据和识别效果的分析,改进的YOLOv5s目标检测算法平均精确率较高,平均检测时间较短,对茶叶嫩芽的分等级识别效果较好。实验过程中部分茶叶嫩芽没有被识别,出现漏检情况,经分析,主要有以下3种原因:(1)拍摄距离和角度不同。不同的拍摄距离,图像中呈现出不同大小的茶叶嫩芽,尺寸过小的茶叶嫩芽会难以识别。拍摄角度不同,图像中茶叶嫩芽的姿态形状会有差别,假如有茶叶相互遮挡的情况,部分茶叶嫩芽无法被识别[16]。(2)采集图像的季节不同。根据季节划分,茶叶分为春茶和夏茶,其中春茶的绿色更浅,茶芽相对较小[17-18],因此不同季节茶叶嫩芽的形状和颜色可能影响识别效果。(3)拍摄时的光线强度不同。不同的光线强度不同,拍摄的茶叶嫩芽图像亮度会有不同,加上阴影等因素的干扰,会影响茶叶嫩芽识别的准确性[19-20]。
在后续的研究工作中,为进一步提高茶叶嫩芽分等级识别的准确率和鲁棒性,缩短对茶叶嫩芽的检测时间,可以获取更丰富的茶叶图像数据集,重点解决拍摄的距离、角度以及光线强度等因素对茶叶嫩叶分等级识别的影响。
4 结语
针对茶园复杂环境下茶叶嫩芽识别准确率低、速度慢和鲁棒性差的缺点及对不同品质茶叶的需求,提出了一种基于改进YOLOv5s的茶叶嫩芽品质分级识别方法。通过增加CBAM 注意力机制和微小目标检测层对YOLOv5s 算法进行改进,后对改进的模型进行训练和测试实验。结果表明,改进YOLOv5s 算法对多类别茶叶嫩芽的识别平均准确率达到94.2%,召回率达到98.2%,较原模型分别提高了1%和1.9%;平均检测时间为26.2 ms,模型大小为15.8 MB。与多种主流目标检测算法进行对比实验并对拍摄的茶叶嫩芽进行识别效果检测,对比结果表明,改进的YOLOv5s 算法对茶叶嫩芽的漏检和误检大大减少,识别效果较好。
综上,改进的YOLOv5s算法对各等级的茶叶嫩芽具有较高的检测精度和良好的鲁棒性,且检测速度快,模型小,适合嵌入式移动设备使用,可以满足对不同品质茶叶嫩芽的高精度实时识别检测的需求。在后续的研究工作中可以获取更丰富的茶叶嫩芽图像数据集,重点解决拍摄的距离、角度、光线强度以及茶叶嫩芽相互遮挡等因素对茶叶嫩叶分等级识别的影响,同时也需要优化算法的网络结构,减少网络冗余参数和计算量。
猜你喜欢
儿童时代·幸福宝宝(2022年10期)2022-11-23
茶叶通讯(2022年2期)2022-11-15
红蜻蜓·低年级(2021年2期)2021-07-20
小学生学习指导(高年级)(2021年6期)2021-06-19
创造(2020年5期)2020-09-10
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
快乐语文(2018年36期)2018-03-12
数学小灵通·3-4年级(2017年9期)2017-10-13
创新作文(小学版)(2017年23期)2017-04-04
