
基于LSTM-SNP 的命名实体识别
2023-11-22 17:37:58陈晓亮陈龙齐
西华大学学报(自然科学版) 2023年5期
邓 琴,陈晓亮,陈龙齐
(西华大学计算机与软件工程学院,四川 成都 610039)
脉冲神经P 系统(SNPs)是从生物信息学的神经元之间的脉冲通信机制中抽象出来的一类分布式并行计算模型[1]。1 个脉冲神经P 系统,通常由4 个基本元素构成:结构、数据、规则集和对规则的控制方法[2]。结构细分为膜结构和数据结构2 部分。膜结构由有向图进行刻画,其中图的节点和边分别表示神经元和神经元间的突触。数据结构形式化为脉冲多重集。1 个神经元的内部机制包含脉冲和规则。系统中的数据一般是由神经元的脉冲统计个数来描述。规则是脉冲神经P 系统完成信号传递的核心[3]。SNP 系统的规则分为2 个类别:脉冲规则和遗忘规则[4]。前者又叫作点火规则,表示消耗脉冲且同时产生新脉冲,后者仅消耗而不会产生新脉冲。
与传统SNP 系统的区别在于,非线性脉冲神经P 系统(NSNPs)[5]通过预定义的神经元状态非线性函数实现脉冲的消耗和产生。因此,NSNP 系统适用于捕获复杂系统中的非线性特征。长短记忆神经网络(LSTMs)[6]属于循环神经网络(RNNs)的变体。1 个LSTM 模型包含1 个隐藏状态和3个门结构(遗忘门、输入门和输出门),共同实现神经元信息传递的调节。受到NSNP 系统脉冲和遗忘规则的启发,Liu 等 [7]基于LSTM 模型提出了新的循环神经网络模型,即LSTM-SNP 模型。该模型只由一个非线性脉冲神经元组成,具有非线性脉冲机制(非线性脉冲消耗和产生)和非线性门函数(重置、消耗和生成)。
循环模式可以较好地解决序列分析问题,例如,时间序列的预测。然而LSTM-SNP 作为传统序列分析模型LSTM 的最新变体,在处理典型自然语言处理序列分析问题,如命名实体识别(NER)的性能表现未见相关研究。本文将序列分析模型LSTM-SNP 用于解决命名实体识别任务,通过添加不同的深度学习组件,模型的性能得到显著的提升,同时,设计了多组对比实验,比较LSTM-SNP模型、传统的LSTM 和双向长短记忆网络(BiLSTM)的性能。
1 相关工作
本文旨在研究LSTM-SNP 模型在命名实体识别任务上的适应性问题,以评估模型在自然语言处理底层任务中的性能和潜力。命名实体识别任务是指在不规则文本中识别具有代表性的特定实体。其主要研究策略、方法根据时间的先后顺序分为:基于规则、基于机器学习和基于深度学习。
1)基于规则的命名实体处理,以语法为基础。Etzioni 等[8]和Wang 等[9]分别提出了基于地名词典和基于词汇句法模式引用规则的2 种经典方法。这类方法具有设计简单、复杂性低等优点,但识别效果严重依赖领域专家对语料库的标注[10]。此外,在处理大规模数据集时基于规则的模型性能具有局限性。
2)机器学习已经成为研究命名实体识别的主流技术。该任务在机器学习领域被定义为多分类序列标注问题。主要技术包括最大熵(MaxEnt)、支持向量机(SVMs)、隐藏马尔可夫模型(HMMs)、条件随机场(CRFs)等。Makino 等[11]基于语音和单词形式构建了系列人工特征,继而用HMM 提取特征,将其合并,并使用SVM 计算实体识别结果。Krishnan 等[12]利用2 个CRFs 来提取实体识别中的局部特征,并输出由逻辑前向CRF 提取的特征信息。这些模型克服了基于规则的缺陷,然而,由于无法捕获更多的上下文信息,当面对句子过长的场景会导致模型性能的降低。
3)近期一些文献强调了神经网络方法在解决NER 问题中的作用,包括长短期记忆神经网络(LSTMs)、卷积神经网络(CNNs)及其变体。神经网络方法避免了手动特征提取。Luo 等[13]提出了一个基于注意力的具有CRF 层的双向长短期记忆神经网络(Att-BiLSTM-CRF),继而训练一个高准确度的模型来识别已命名的实体。Li 等[14]建立的BiLSTM-CNN 模型表明,CNN 作为模型组件可以显著提高实体识别的精度。Li 等[15]提出了一种新的替代方法W2NER,它将NER 建模为词—词关系分类。此外,Bert、LSTM 和多重二维扩展卷积(DConv)的有机组合可以较优地处理NER 问题。
2 LSTM-SNP 模型实验设计
本章对文中提到的命名实体任务进行形式化表述。设L={L1,···,Lt,···,Ln}为一个有标签的实例文本训练集,θ={θ1,···,θt,···,θm}为一组类别标签,如位置、组织、其他等。实例Lt中的词语,记为tk,都被分配了一个标签 ε ∈θ。如果实例的词语是已命名实体的元素,则它的标签是该实体的类别。NER 模型的基本处理步骤为:首先,通过在模型的嵌入层中使用独热编码技术,将具有n个单词的句子X表示为向量序列X={x1,···,xt,···,xn};其次,将嵌入操作后的向量输入到LSTM、BiLSTM 或LSTM-SNP 中,以生成区分实体的预测标签;最后,使用相关的评价指标来评估模型的有效性。
2.1 LSTM-SNP 模型结构
RNN 技术在自然语言处理(NLP)研究中得到了广泛的应用。但是,随着模型层数的叠加,RNN网络容易发生梯度消失和梯度爆炸的问题。长短期记忆神经网络(LSTMs)[6]作为RNN 的变体,设计了3 个门控机制来调整细胞状态,如图1 所示。LSTM 单元在时间步t的遗忘门、输入门、输出门通常分别形式化为函数ft,it,ot。其输入的向量用xt表示。Ct表示单元在时间步骤t的状态。
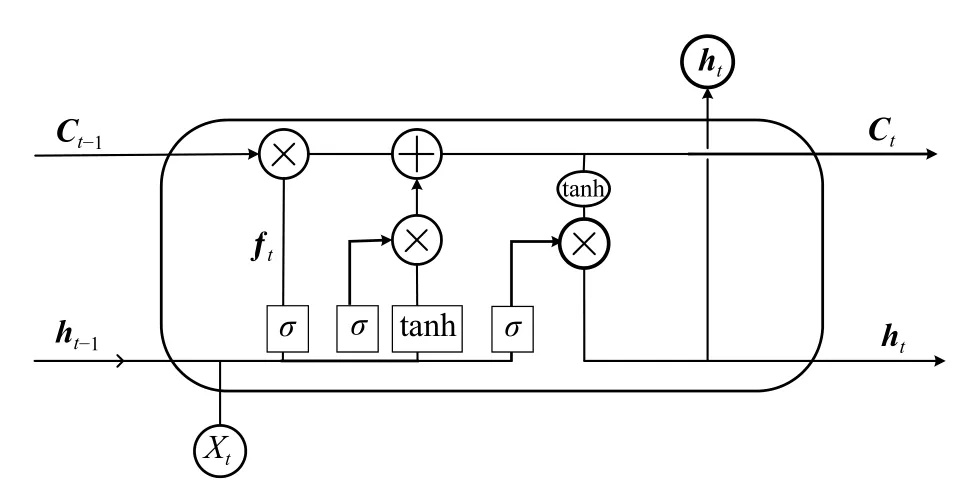
图1 LSTM 模型细胞结构图Fig.1 Cell structure diagram of LSTM model
由于使用了sigmoid 型函数,LSTM 能够有效地选择放弃和保留的信息。3 个门控单元的连接与控制的计算公式为:
Liu 等[7]认为,LSTM-SNP 是在LSTM 基础上用不同的非线性门函数、状态方程和基于膜计算规则的输入输出进行的模型重构。图2 表示了新型门机制:复位门rt、消耗门ct和生成门ot。复位门根据当前的输入、上一时刻的状态和偏置,决定前一状态的复位程度。
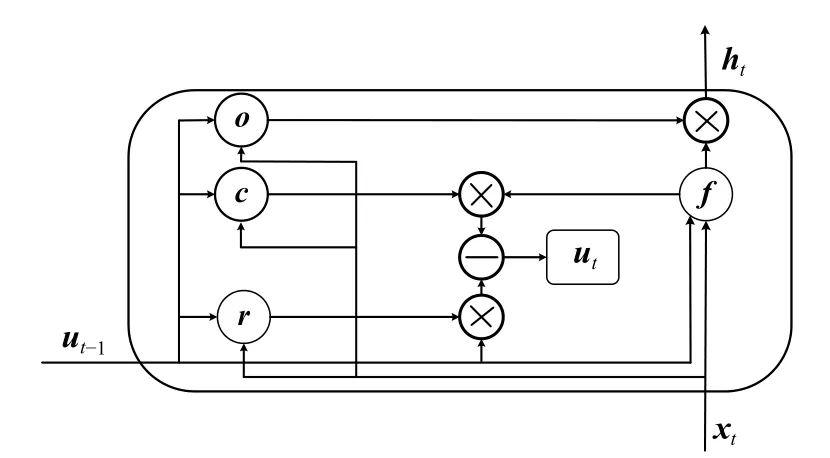
图2 LSTM-SNP 模型细胞结构图Fig.2 Cell structure diagram of LSTM-SNP model
生成门根据当前输入、上一时刻的状态和偏置来指定输出多少个生成的脉冲。xt表示输入句子的向量。总体而言,3 个门控装置之间的连接与控制取决于公式(2)。
神经元 σ产生峰值,为
根据3 个非线性门和产生的脉冲信号,计算神经元 σ在t时刻的状态和输出为:
其中,ht表示LSTM-SNP 层的输出,即NLP 任务的上下文隐层向量。图1、图2 以及LSTM 和LSTMSNP 的相关公式均在神经元细胞的水平上进行描述。当数百个神经元连接起来执行计算时,一个真正的仿生神经网络就形成了。
2.2 LSTM-SNP-CRF 模型
Lafferty 等[16]在2001 年提出条件随机场(CRFs)。CRF 是统计关系学习的重要框架,具有较强的描述、逻辑推理,以及对不确定性的处理能力。作为典型的判别模型经常被构造为NER 或其他NLP学习模型的增强组件。本节阐述LSTM-SNP 和CRF组件的兼容性,目的在于研究CRF 组件能否在NER任务中提高LSTM-SNP 的识别准确性。
本文选择LSTM 和BiLSTM 这2 个模型作为LSTM-SNP 模型的参照实验组,通过实体识别精度来评估3 个模型对CRF 层的性能提高敏感性。模型的处理流程为首先将文本经过词嵌入转换为特征向量,然后分别送入LSTM-SNP、LSTM、BiLSTM这3 个模型获取词语之间的关系特征,最后将其输入到CRF 处理层,获得标签的分值,最大分值对应的标签即为模型认定的标签。模型整体处理流程如图3 所示。LSTM-SNP 层的功能与LSTM 层和BiLSTM 层的功能相同。这3 层都是用来提取句子的特征。LSTM-SNP 层将依次被LSTM 或Bi-LSTM 层取代,用于CRF 敏感性比较。这些模型使用了BIO(begin,inside,outside)标签方案。

图3 LSTM-SNP-CRF 模型、LSTM-CRF 模型、BiLSTM-CRF 模型的结构Fig.3 Structure of the LSTM-SNP-CRF model,the LSTM-CRF model,and the BiLSTM-CRF model
2.3 GloVe-CNN-LSTM-SNP 模型
本节提出带有GloVe[17]和卷积神经网络(CNN)[18]的LSTM-SNP 的整体体系架构,如图4 所示。LSTMSNP、LSTM-SNP-CRF 这2 种模型中的嵌入表示仅采用了独热编码连接层。这种嵌入方法会造成编码稀疏、维度大、词间相似性反应能力弱等问题。因此,LSTM-SNP 在命名实体识别任务的有效性有待进一步的实验证明。区别于传统LSTM-SNP,本文采用了更高效的特征提取方法,具体分为基于词级别的特征提取和字符级别的特征提取。词级别的特征通过词嵌入方法GloVe 以及手动定义词大小写特征的方法分别获取语言特征和词大小写信息。基于字符级别的特征提取是通过卷积神经网络CNN 以获得词更加细粒度的特征表示。CNN模型提取单词的字符级特征的过程如图5 所示。模型将GloVe 向量、CNN 向量和单词大小写信息向量通过拼接操作相结合,并通过LSTM-SNP 层进行处理。同时,为了验证LSTM-SNP 模型在实际应用中的优越性,本文将LSTM-SNP 层分别替换为LSTM 层和BiLSTM 层用于性能比对。下面将基于词级别和字符级别介绍各项特征提取技术。
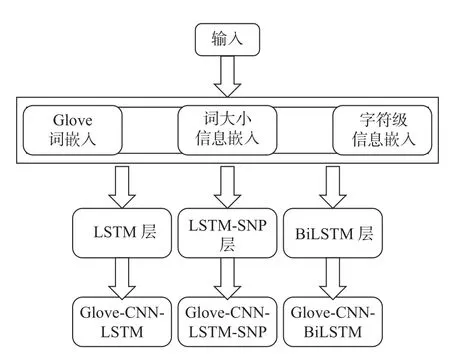
图4 GloVe-CNN-LSTM-SNP 模型、GloVe-CNN-LSTM 模型、GloVe-CNN-BiLSTM 模型的结构Fig.4 Structure of the GloVe-CNN-LSTM-SNP model,the GloVe-CNN-LSTM model,and the GloVe-CNNBiLSTM model

图5 CNN 模型提取单词的字符级特征的过程Fig.5 The process of extracting character level features of words from CNN model
2.3.1 基于词级别的语义特征提取
近年来,一些工具,如word2vec 和GloVe,已被广泛应用于命名实体识别(NER)。GloVe 是一种用于获取词的向量表示的无监督学习算法。简而言之,GloVe 允许获取文本语料库,并将该语料库中的每个单词直观地转换为高维空间位置。这意味着相似的词将被放在一起,而这一技术也是词嵌入技术的重要组成部分。本文受到Chiu 等[18]的启发,提出了一种基于预训练的字符嵌入方法,将来自维基百科和网络文本的60 亿个单词作为训练资料,设计了一组基于GloVe embeddings3[17]的对比实验。
2.3.2 基于词级别的大小写信息特征提取
因为在使用GloVe 词嵌入方法时会丢失大量的字母大写信息,所以本文借鉴Collobert[18]的方法获取词嵌入过程缺少的信息。该方法使用一个单独的查找表来添加大写选项:全为大写、初始大写、初始小写、大小写混合、其他。
本文的GloVe-CNN-LSTM-SNP 模型应用了Collobert 等[18]的方法以在单词嵌入期间获得词语大小写信息,同时将该查找表选项扩展。选项包括:所有字母全小写、所有字母全大写、仅首字母大写、全为数字、多部分为数字、少部分数字(包含数字)、其他、填充标记这8 个选项。将此选项表命名为查找表C 中,用于做基于词级别的单词大小写信息嵌入。
2.3.3 基于字符级别的特征提取
CNNs[18]是当前深度学习技术中最具有代表性的一种神经网络结构,近年来受到了众多学科的广泛关注。实验设置通过采用CNN 技术,从英文文本资料中提取指定实体的字符级特征。
英语中的单词通常由细粒度的字母构成,CNN技术被用于处理这些字母。这些字母包含了诸如前缀/后缀等隐藏特征。对于不同类型的字符,实验设置了不同的随机字符向量,以区分字符和字符类型(字母、数字、标点符号、特殊字符等)。例如,大写字母‘A’和小写字母‘a’对应于2 组不同的字符向量集。图5 展示了CNN 从一个单词中提取字符级特征的过程。
结合词级别和字符级别的特征表示,并将2 种级别的特征表示向量进行拼接,得到完整的单词嵌入表示。该词嵌入表示包括了词的语言相关特征、词语的字符特征、词的大小写信息。图6 展示了在GloVe 和LSTM-SNP 基础上加入CNN 模块后的整体模型,即完整的GloVe-CNN-LSTM-SNP模型。LSTM-SNP 层的功能与LSTM 层和BiLSTM层的功能相同。这3 层都是用来提取句子的特征。LSTM-SNP 层将依次被LSTM 或BiLSTM 层取代,用于比较3 种模型对于CNN 的敏感程度。

图6 GloVe-CNN-LSTM-SNP 模型的架构Fig.6 Architecture of GloVe-CNN-LSTM-SNP model
3 实验分析
3.1 数据集
本研究优先采用2 个经典的命名实体识别数据集CoNLL-2003 和OntoNotes5.0,对基于CRF、基于GloVe 和基于CNN 的LSTM-SNP 模型性能进行评估。所有的数据集都可以在网站公开获得。CoNLL-2003 数据集可以通过文献[19]网站下载。OntoNotes5.0 数据集可以通过文献[20]网站下载。关于数据集的训练测试和验证集的句子数量划分如表1 所示。
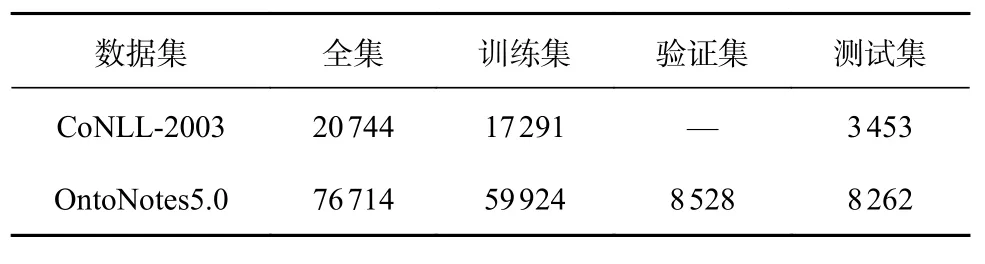
表1 语料库句子统计Tab.1 Corpus sentence statistics
3.2 评估标准
根据前期工作[21],为正确评估LSTM-SNP 在命名实体识别任务中使用CRF、CNN 和GloVe 时模型的有效性,本文选择了NLP 领域的通用评估度量系统,即精度(P)、召回率(R)和准确率(Acc)。测试样本被分为实际的实体类别和预测的实体类别。实验结果分为4 类,如表2 所示。预测的实体代表由模型得出的实体标签,实际的实体代表人工标注的真实标签。

表2 混淆矩阵Tab.2 Confusion matrixs
本文采用的精度(P)、召回率(R)和准确率(Acc)定义为:
式中:TP(true positive)表示模型正确地将一个实体标记为正类,即模型正确地将一个实体标记为实体,并且这个实体与真实标签一致;FN(false negative)表示模型错误地将一个实体标记为负类,即模型没有将一个实体标记为实体,或者将实体标记为了错误类型;FP(false positive)表示模型错误地将一个非实体标记为正类,即模型将一个非实体错误地标记为了实体;TN(true negative)表示模型正确地将一个非实体标记为负类,即模型正确地将一个非实体标记为非实体。
命名实体识别任务涉及多种分类。因此,微平均F1(F1macro)值也被用作性能评估指标,定义为:
式中:P1,P2,···,Pn分别代表第1 种实体类别,第2 种实体类别以及第n种实体类别的精度值;R1,R2,···,Rn分别代表第1 种实体类别,第2 种实体类别以及第n种实体类别的召回率。
3.3 参数配置
根据LSTM-SNP、LSTM 和BiLSTM 的模型结构,首先在实验中实现了这3 种模型。当对比实验依次添加CNN 和GloVe 作为嵌入模型时,模型的内部参数保持不变。
LSTM-SNP 模型除了需要学习的权重矩阵和偏差向量外,还有一些通过实验确定的先验参数,包括迭代计数(iterations)、Dropout 率和神经元数量(neurons)。
图7 展示了LSTM-SNP 在CoNLL-2003 数据集上经过不同迭代次数和提前停止次数训练时的性能差异,包括15-4、15-5、15-6、15-10、20-5、20-10 和100-50。由图可知,当迭代次数和提前次数为15-5 时,LSTM-SNP 在CoNLL-2003 数据集上取得了72.5%的F1macro值。因此不同迭代次数和提前次数采用15-5。

图7 基于数据集CoNLL-2003 上的不同的迭代次数与提前停止次数对LSTM-SNP 模型 F1macro分数的影响Fig.7 Influence of iterations and early-stops on F1macro based on LSTM-SNP model and dataset CoNLL-2003
本文还考察了不同的Dropout 率对LSTM-SNP模型F1macro分数的影响,即当迭代次数与提前停止次数定为15-5 时,Dropout 率分别为0%、5%、10%、25%、50%和75%。图8 所示的对比实验结果表明,当Dropout 率为50%时,F1macro值为72.8%,适合于模型训练。

图8 基于数据集CoNLL-2003 上的不同Dropout 率对LSTM-SNP 模型F 1macro分数的影响Fig.8 Influence of Dropout rates on F1macro based on LSTMSNP model and dataset CoNLL-2003
当迭代次数和提前停止次数为15-5、Dropout率为50%时,设置不同的神经元个数(32、64、128、256 和512)进行实验。如图9 所示的当前结果发现,神经元数量设为256 有利于模型训练。
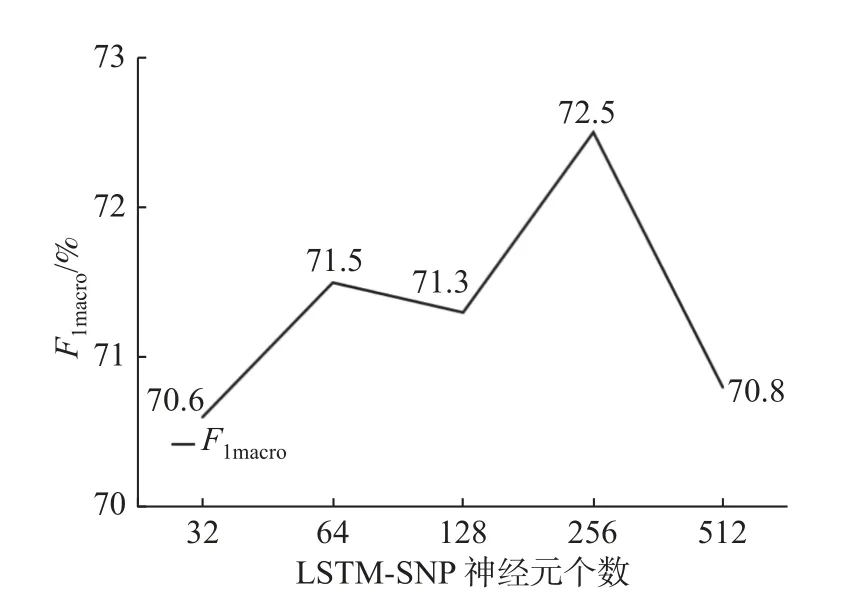
图9 基于数据集CoNLL-2003 上的不同的神经元个数率对LSTM-SNP 模型F 1macro分数的影响Fig.9 Influence of neurons on F1macro based on LSTM-SNP model and dataset CoNLL-2003
3.4 对比实验结果分析
本研究的最初目标是确定LSTM-SNP 模型对CRF、GloVe 词嵌入和CNN 等传统深度学习组件的适应性。在保持相同的超参数基础上,如表3 所示,本文将A、B、C、D 4 组模型在2 个数据集上进行实验,获得以实体为单位的识别结果。模型得分情况如表4 所示。其中:LSTM-SNP 在2 个数据集上的表现与LSTM 相似;所有模型在数据集CoNLL-2003 的F1macro平均得分比数据集Onto-Notes5.0 高出10 分左右。一个重要的原因是数据集CoNLL-2003 和OntoNotes5.0 中存在着不同的实体类别数量。前者分4 类,后者分18 类。这说明,LSTM-SNP 模型以及这类循环神经网络模型在对少量实体进行分类是具有更好的识别效果。本文从2 个不同的视角对实验结果进行分析。

表3 对比实验设置Tab.3 Contrast experiment settings

表4 LSTM-SNP、LSTM、BiLSTM 在数据集CoNLL-2003 和OntoNotes5.0 的性能结果Tab.4 Performance results of LSTM-SNP,LSTM,and BiLSTM in the dataset CoNLL-2003 and OntoNotes5.0
3.4.1 基于A、B、C、D 组的实验分析
A 组的LSTM-SNP 模型在数据集CoNLL-2003中的F1macro分数为73.35%,在数据集OntoNotes-5.0 中为39.30%。BiLSTM 的F1macro得分在2 个数据集下都是最高的。一个未预料到的发现是,LSTM-SNP 模型和LSTM 模型在NER 任务上的F1macro分数方面没有显著差异。整体而言,在处理4 种实体类型问题时,3 种模型的表现均优于18 种实体类型的模型。
B 组添加CRF 后,LSTM、BiLSTM 和LSTMSNP 3 种模型的性能均得到改善。在数据集Co-NLL-2003 和OntoNotes5.0 中,LSTM-SNP 模型在2 个数据集的F1macro得分分别为76.16%和59.95%。添加了CRF 的BiLSTM 在2 个数据集中性能仍然是最好的。值得一提的是,LSTM-SNP-CRF 在数据集OntoNotes5.0 拥有更明显的性能改进。与A 组相比,F1macro约提高了20%。
C 组的得分体现了GloVe 词嵌入对模型的贡献。实验结果显示,在使用GloVe 词嵌入时,3 个模型的学习效果均比A 组和B 组更优。在2 个数据集上,模型GloVe-LSTM-SNP 的F1macro分别比A 组的LSTM-SNP 高4%和34.47%。但是,从2 个数据集的F1macro来看,GloVe-LSTM-SNP的得分在2 个数据集上最低,分别为77.34%和73.77%。
D 组与C 组相比,3 个模型均无显著差异。与C 组3 个没有添加CNN 组件的模型相比,D 组的每个模型性能有轻微的提高。在数据集OntoNotes-5.0 中,GloVe-CNN-GloVe 相比A 组的F1macro提高35.82%。显然,D 组的3 个模型在2 个数据集上都取得了最高得分。
3.4.2 3 种模型的消融实验分析
将CRF 添加到LSTM-SNP、LSTM、BiLSTM 3 个模型时,各模型在数据集CoNLL-2003 上的F1macro分别提高了2.81%、4.05%和0.12%。3 个模型在数据集OntoNotes5.0 上的F1macro分别提高20.65%、20.45%和20.5%。实验结果表明,LSTM和LSTM-SNP 模型的性能提升程度在数据集CoNLL-2003 上比BiLSTM 模型更大,在数据集OntoNotes5.0 上提升程度相似。
需要指出的是,数据集CoNLL-2003 的数据量相对于数据集OntoNotes5.0 来说较小。数据集Co-NLL-2003 大约是数据集OntoNotes5.0 的3.5 倍。因此,模型LSTM-SNP、LSTM 与BiLSTM 相比,LSTM-SNP 和LSTM 对数据集的质量和数量更为敏感。
在LSTM-SNP、LSTM、BiLSTM 这3 个模型中添加GloVe 词嵌入,当处理数据集CoNLL-2003时,F1macro值相比于A 组分别增加了3.99%、9.06%和8.43%。将GloVe 词嵌入应用到LSTM-SNP、LSTM 和BiLSTM 模型中,在CoNLL-2003 数据集上与A 组比较,F1macro值分别提高了3.99%、9.06%和8.43%。此外,在OntoNotes5.0 数据集下,与原始模型A 组相比,分别提高了34.47%、38.65%和24.02%。实验结果表明:F1macro改善非常显著,GloVe 词嵌入对模型的性能有很大的改善。
然而,随着数据集数量的增加,BiLSTM 模型的F1macro得分提高幅度不如其他2 个模型。这一现象在某种程度上证明了BiLSTM 受数据量影响相对较小,而其他2 种模型受数据量影响较大。对于LSTM-SNP 模型,通过添加预处理方法,如词嵌入,该模型能够表现得更好。
在LSTM-SNP、LSTM、BiLSTM 中同时加入CNN 和GloVe 进行处理时,在CoNLL-2003 数据集下,3 个模型的性能均比A 组的基线模型提高了4.77%、9.20%和8.76%。在数据集OntoNotes5.0下,F1macro分别提高35.82%、39.24%和24.34%。这些数据共同证明了添加CNN 和词嵌入的有效性。类似地,LSTM-SNP 和LSTM 都有较大的增加,也说明了上述结论。此外,通过添加CNN从单词嵌入中学习字符级特征,3 个模型在2 个数据集上的性能提升很小。结果显示,基于文字嵌入的特征方法可以有效地改善LSTM-SNP 模型的性能,并具有较好的效果。
4 总结与展望
本文旨在评价LSTM-SNP 模型在序列问题(命名实体识别)应用中的有效性。同时,为了探索LSTM-SNP 模型是否具有在自然语言处理领域的研究潜力,本文在LSTM-SNP 模型以及其对比模型LSTM 和BiLSTM 中有序添加了一些深度学习组件,包括CRF、单词嵌入等,以对比组件对不同模型的性能提升幅度,从而为LSTN-SNP 模型的未来研究提供可靠数据参考。
实验表明,传统LSTM-SNP 模型在命名实体任务中的性能与LSTM 模型基本相似,但与BiLSTM 的良好性能仍存在一定的差距。此外,实验发现,LSTM-SNP 模型受数据集领域知识的影响较大。在LSTM-SNP 模型中加入CRF、词嵌入和CNN,该模型的性能有了显著的提高。加入词嵌入、CNN 等特征预处理模块可以极大地改善模型的总体性能。总体而言,LSTM-SNP 模型在命名实体识别任务中具有潜力,并且有比较大的改进空间。
未来的工作将考虑使用LSTM-SNP 模型提取实体局部特征。本文仅考虑了实体上下文特征,其粒度不够细腻。因此,将注意机制引入到LSTM-SNP模型中,利用注意机制来提取局部特征[22],从而实现对命名实体识别有较大影响权重特征的重点关注。同时,考虑实现多层或双向的LSTM-SNP 模型,以提高模型提取特征的能力。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
自然杂志(2021年6期)2021-12-23 08:24:46
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
中国外汇(2019年18期)2019-11-25 01:41:54
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
现代装饰(2018年5期)2018-05-26 09:09:01
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
