
融合注意力机制的门控图神经网络文本分类算法∗
2023-11-21 06:17马明旭苏凡军佟国香
计算机与数字工程 2023年8期
马明旭 苏凡军 佟国香
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
文本分类是自然语言处理中的一个经典问题,目的是为句子、段落或文档等文本单位分配标签或标记,已被应用于许多现实场景,例如垃圾邮件检测、情感分析和新闻分类等。
基于规则和传统机器学习的文本分类算法,离不开繁琐的人工分析和特征工程,特殊领域的文本分类需要强大的专业知识,限制了庞大训练数据的使用,时间长且代价昂贵[1]。
随着深度学习的发展,神经网络在文本分类任务中广泛应用,提出了许多基于卷积神经网络(Convolutional Neural Network,CNN)或循环神经网络(Recurrent Neural Network,RNN)的方法[2~5],但是许多方法很大程度上忽略了远距离和非连续语义在内的信息[6]。
最近几年,图神经网络(Graph Neural Network,GNN)[7~9]成为研究热点,缓解了上述方法的局限性,研究者们提出了许多算法[10~14]。Yao[10]在GCN[7]的基础上提出了Text-GCN,首先将语料库转化为含有文本和单词的大型异构图,预先定义节点之间的关系,利用GCN 聚合节点的邻域单词特征更新文本和单词表示,将文本分类任务转换为空间中的节点分类任务。Rahul[11]分解Text-GCN 文本和单词的嵌入操作,根据网络层不同类型的输入输出,提出了分别编码文本和单词特征的同构层和异构层,并融合不同层的输出提出了用于文本分类的Hete-GCN 模型。Xin[12]将标签转换为节点加入异构图,利用GCN 将标签信息融入文本特征,促进模型学习更准确的文本嵌入。Huang[13]考虑为每个文本构造文本图,共享语料库中的单词表示和单词关系,提出了将节点和邻域特征加权求和更新节点表示的消息传递机制。Zhao[14]通过Bi-LSTM 建模单词特征,并利用GCN 从预先定义的句法依存树中提取句法和单词依赖信息,获取文本表示。但是构建文本-单词异构图的方法[10~12]忽略了文本和单词的细粒度交互[15],并且预先定义节点间的关系忽略了单词之间的细粒度交互问题,即忽略了噪声信息[16]和邻域节点的贡献程度[9]。
为了解决上述问题,本文提出了一个改进的门控图神经网络算法。门控图神经网络(Gated Graph Neural Network,GGNN)[8]是一种基于门控循环单元(Gated Recurrent Unit,GRU)[17]的图神经网络,在门控机制的作用下,更好地融合节点特征和邻域特征更新节点表示,可以提取文本内远距离和非连续的语义信息。Zhang[14]考虑文本-单词的细粒度交互,预先定义每个文本的图数据,并利用门控图神经网络聚合单词节点邻域信息更新单词表示,最后融合所有单词特征得到文本表示并进行分类。GGNN 用于文本分类方面的文献较少,目前这个方面的研究仍处于进展中。
本文提出了一种融合注意力机制的门控图神经网络文本分类算法(GGNN-AM)。算法分为三部分:数据处理层、文本嵌入层和分类层。数据处理层处理文本得到初始图数据,文本嵌入层得到图级别的文本表示,分类层提取文本特征并预测文本类别。
所提算法主要的创新如下:
1)针对单词-单词的交互关系,考虑到单词邻域的噪声信息[15]和每个邻域节点的贡献程度[9],在文本嵌入层引入注意力机制[18],在聚合邻域信息时为邻域节点动态分配重要性系数,使网络能够自动识别并提取重要特征,过滤噪声信息。
2)为了增强文本-单词的细粒度交互,在分类层将卷积核作为特征编码器,对每个单词和多个单词组合的局部信息编码,提取重要特征和一般特征表示文本,增强文本表示的表征能力。
在三个英文开放数据集上与多个文本分类算法相比,GGNN-AM算法取得了更好的分类结果。
2 GGNN-AM算法
GGNN-AM 算法分为三部分:数据处理层、文本嵌入层和分类层。
2.1 数据处理层
数据处理层处理文本并得到初始图数据。文本为T={w1,w2,…,wn},其中wi∊T为单词,n为文本T的长度。构造文本T的初始图数据G={V,E},其中单词节点集V={h1,h2,…,hm},hi∊Rd为第i个单词节点的初始表示,d为单词表示的嵌入维度,m≤n表示文本T中唯一单词的个数,E为边集。参考文献[9]的工作,边集E通过一个大小为z的滑动窗口和点互信息(Point-wise Mutual Information,PMI)确定。不同的是,PMI值仅用于判断单词之间是否存在边,忽略PMI值很小的边,并将其余边的权值初始化为1,后续通过注意力机制自动分配。滑动窗口中单词hi和hk的边定义为
其中,PMI 值大于0 表示单词之间有较高的语义关联,等于或小于0 表示很小或没有语义关联。对于单词hi和hk的PMI值计算定义为
其中,#W(hi,hk)表示同时出现单词hi和hk滑动窗口的个数,#W(hi)为出现单词hi的窗口个数,#W为滑动窗口的总个数。
如图1所示为利用大小为3的滑动窗口和点互信息构造的文本“the file is a verbal duel two gifted performers”的图数据,其中,节点为单词,边上的权值表示PMI值,虚线表示过滤的边。

图1 文本图数据示例
2.2 文本嵌入层
文本嵌入层处理文本图数据,获取图级别的文本表示。本层使用注意力机制自动分配单词之间的权重,使网络自动识别并提取单词节点的邻域重要特征;通过门控机制融合节点特征和邻域重要特征,更新单词节点嵌入,获取图级别的文本表示。
2.2.1 注意力机制
注意力机制为单词邻域节点分配重要性分数,并据此加权聚合邻域信息。如图2 所示为单词的邻域,表示第i个单词在t时刻的表示,即拥有t阶邻域信息的单词特征,表示第i个单词的初始表示。通过式(5)计算在t时刻对的注意力分数,并据此加权聚合邻域重要信息,计算过程为

图2 节点和邻域
其中,Wa为参数矩阵,∊R表示注意力分数,∊Ni为的邻域节点,C(·)为点积操作,为利用注意力机制聚合的邻域重要信息,f(·)为Re-LU激活函数。
2.2.2 特征融合
参考文献[8]的工作,利用门控循环单元融合节点和邻域特征。如图3 所示为门控循环单元,其中rt为重置门,用于控制信息遗忘的程度;zt为更新门,控制信息保留的程度;为t时刻的邻域信息为记忆信息,为融合t+1 阶邻域信息的单词节点特征。对于单词节点的处理过程为

图3 门控循环单元
其中,σ(·)是sigmoid 函数,W,U和b是可训练的权值和偏差。特征融合后,得到融合邻域信息的图级别文本表示
2.3 分类层
分类层将卷积核作为特征编码器,编码图级别文本嵌入,提取重要特征和平均特征表征文本,预测文本类别。首先,利用多尺寸卷积核分别对单个单词和多个单词的局部信息编码,得到特征。对于大小为s的卷积核,计算过程为
其中,W∊Rs×hd是卷积核,s∊Ns为卷积核的尺寸,hd为图级别文本嵌入的维度,Hi:i+s-1表示单词i到i+s-1 组成的特征矩阵,b为偏置项,f(·)为ReLU激活函数。经过s尺寸卷积核编码后的特征为
考虑到Cs中重要特征和所有特征的作用,利用池化层提取重要特征和平均特征。拼接所有卷积核得到的特征得到最终文本表示,并利用softmax预测文本类别,计算过程为
其中,s,S1,Sn∊Ns为卷积核的尺寸,⊕为拼接操作,WF和bF是可训练的参数,F是最终文本表示,ypred是模型预测的文本类别。目标函数使用交叉熵损失函数,并加入L2 正则化防止过拟合,目标函数为
其中,第一部分为交叉熵损失函数,ytrue为真实的文本类别,第二部分为正则化项,λ为系数。
3 实验
3.1 数据集
数据集采用公开的MR、R8 和Ohsumed 英文数据集,对三个数据集处理并进行统计,得到数据集的统计信息,如表1。
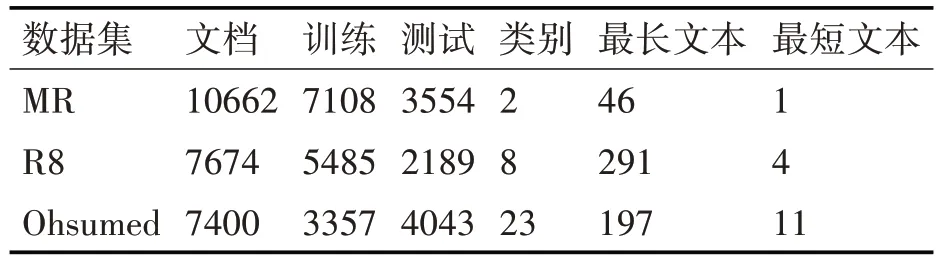
表1 数据集的统计信息
MR:电影评论的情感数据集,每个评论只有一个句子,分类涉及正负两类,共10662个文本。
R8:Reuters-21578 新闻数据集的子集,共7674个文本,涉及8个类别的分类。
Ohsumed:医药信息数据集,共7400 个文本,分类涉及23个类别。
3.2 参数和评测方法
实验采用glove[19]词向量glove.6B.200d 表示初始单词特征,维度为200,未登录词(Out Of Vocabulary,OOV)使用在[-0.01,0.01]范围内随机生成的向量表示。数据集按9∶1 分为训练集和验证集,学习率设置为0.001,正则化系数设置为0.0001,Dropout 参数为0.5,采用Adam[20]优化网络,其余参数根据数据集而定。实验选用分类评价性能指标Accuracy描述算法的性能,公式为
其中,PTrue为预测正确的样本数,Psamples为总样本数。
3.3 结果与分析
如表2 所示为GGNN-AM 与各算法在三个英文数据集上的分类准确度结果。Text-CNN[2]在卷积核的作用下更关注文本的局部特征,对比Text-GCN[9],前者在MR 短文本数据集上利用卷积核捕捉到了对分类重要的特征,并且可以获取局部单词的序列语义信息,提升了模型的分类准确率,但是在Ohsumed 和R8 长文本数据集上不如Text-GCN 预测准确,是因为CNN 对不连续词及长距离依赖关系的信息的提取存在限制[8]。Text-GCN 在MR 数据上表现不好,是因为MR 文本较短,图中边的数量较少,限制了信息在图中的传递,并且忽略了文本与单词的细粒度交互问题。Label-text[12]将标签信息融入了图数据,促进了模型学习对分类更重要的特征信息,增强了文本分类的能力,在R8 和Ohsumed 数据上均有提升。SC-DGCN[14]通过Bi-LSTM 提取文本的序列特征,并利用GCN 结合从预先定义的句子依存结构中提取句法信息,在MR 数据上提升较大。Huang[13]为每个文本建立图数据,模型更加关注单个文本图内信息的交互,在R8和Ohsumed数据上均有提升。
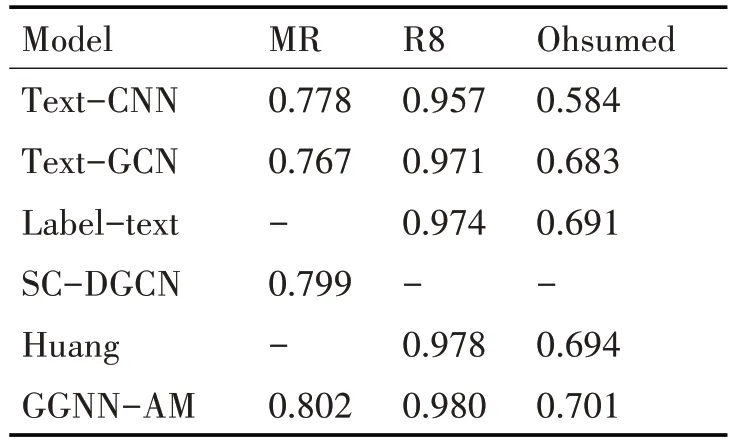
表2 实验结果
从表中可以看出,GGNN-AM 算法在MR、R8和Ohsumed 数据上取得了最好的结果。这是因为GGNN-AM 在注意力机制的作用下,关注不同状态下单词之间的交互关系,学习并提取到了邻域的重要信息,得到更准确、更相关的非连续语义特征。结合多尺寸卷积层的作用,突出了对分类有重要作用的重要单词和局部特征,得到更准确的文本表示,增强了文本-单词的细粒度交互,提升了分类的准确度。
3.4 部分参数对实验结果的影响
本小节实验结果均为模型运行3 次后取平均值。
1)注意力机制对预测结果的影响
去除GGNN-AM 中的注意力机制得到GGNN-NOAM,并使用PMI 值预先定义文本图数据。分别在MR 和R8 数据上进行实验,结果如表3所示。含有注意力机制的模型在两个数据集上取得了更好的结果,证明了在注意力机制的作用下,模型识别并提取了单词邻域的重要信息,从而提升了模型预测的准确度。

表3 对比实验
2)滑动窗口大小对实验结果的影响
如图4 所示,随着滑动窗口增大,模型预测准确率上升。由于滑动窗口的增大增加了单词的邻域范围,增加了边的数量,信息在图中的流动更加广泛,提升了实验结果的准确度。但是增大到5时,MR和R8的实验结果均出现了下降。推测是因为随着滑动窗口的增大,长距离单词之间关系较小,单词特征引入了无关信息,造成了结果的下降。

图4 不同窗口大小下的实验准确度
3)文本嵌入层数对实验结果的影响
如图5 所示,随着文本嵌入层的层数增加,模型预测准确度逐渐上升,MR和R8数据的预测结果分别在3层和2层时取得最好结果。但随着层数的上升,准确度下降,推测是因为单词节点通过网络获取到图数据中高阶长远距离的无关信息,降低了单词的表示质量,对实验结果造成了影响。
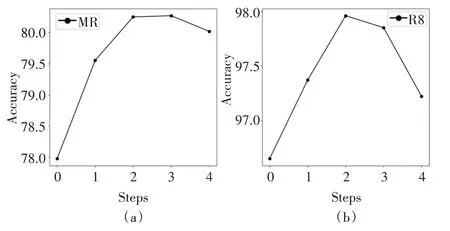
图5 不同时间步下的实验准确度
4 结语
本文提出了一种融合注意力机制的门控图神经网络文本分类算法GGNN-AM。构造每个文本图数据,将注意力机制与门控图神经网络融合,动态的分配单词之间权重,注重单词之间的细粒度交互,让模型自动识别并提取出邻域的重要信息。最后使用多尺寸卷积核对单词和局部特征编码,提取出重要的特征信息,增强文本与单词的细粒度交互,得到更准确的分类结果。在3 个数据集上的实验结果证明了GGNN-AM的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
吉林大学学报(理学版)(2020年3期)2020-05-29
电子制作(2019年11期)2019-07-04
自动化学报(2018年7期)2018-08-20
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
周口师范学院学报(2016年5期)2016-10-17
电视技术(2014年19期)2014-03-11
