
基于RoBERTa 和RCNN 的互联网文字消防接警辅助系统的设计与研究∗
2023-11-21 06:17张昊东
计算机与数字工程 2023年8期
张昊东 董 雷
(1.武汉邮电科学研究院 武汉 430000)(2.武汉理工光科股份有限公司 武汉 430000)
1 引言
随着中国城市化进程的加速,我国涌现出一系列超级大都会城市,人口的密集导致了城市火灾案件频发。另外,随着我国经济的迅猛发展,人民群众的家中也出现了各式各样的新式电器,且人均拥有量也不断提升,这也导致了城市火灾案件数量不断攀升,且难以防范。以上所述的现实环境都对我国新时代下各省市的消防系统建设提出了更高的要求。更智能、更迅速地成为各省市消防系统建设的共同导向[1]。在消防系统各子模块中,消防接警是最重要、最常用、最亟待提升的信息化模块[2]。现代消防接警信息来源已不只是来自于话务,更多的信息由于群众使用习惯、害怕担责等原因来自于互联网(微信公众号、微信小程序、支付宝小程序等)文字渠道。但在系统实践过程中,由于各地接警中心人力有限,且信息较短(单条20 字以下)、数量较多,以上提到的互联网文字报警信息往往没有被很好地利用[3]。
为此,我国企业、科研单位对其做了大量的研究,提出了许多不同的解决思路。但大都基于关键词标注、分级推送等传统思想,并没有深入到文本本身语义层次进行分析、处理[4]。
本文设计了一套互联网文字消防接警辅助系统,帮助接警员预筛有效消防报警信息,并通过语义分析对有效消防报警信息进行分类(火灾、抢险救援、反恐排爆、公务执勤四类),有效节省接警员反应时间,提高接警中心作业效率。经实验证明,本消防接警辅助系统的文本算法部分相较于工业领域常用算法和经典算法具有较高的识别率与性能。
2 基于RoBERTa 和RCNN 的改进短文本分类
2.1 RoBERTa模型
RoBERTa是一个预训练的语言表征模型[5],其基于2018 年10 月Google 发布的BERT[6]模型,从如下三个方面进行了改进。
1)增加中文语料,增强对中文文本的处理能力;
2)增大数据的训练量;
3)改进数据生成方法。
各类优化的结果体现在测试上,RoBERTa 较之与BERT 在互联网新闻情感分析、自然语言推断[7]、问题匹配语任务[8]、阅读理解[9]测试上均强于BERT,领先BERT模型1%~2%[10~12],如表1所示。

表1 RoBERTa与BERT能力对比表
2.2 RCNN模型
RCNN 模型是一种CNN 簇变种模型[13]。相较于传统的文本信息处理模型RNN,既关注了文本所隐含的时间信息,也利用了循环层的形式实现了卷积的效果,对文本信息进行了宏观上的提炼[14~15]。如图1 所示,利用left context 和right context 的信息与当前词链接,以循环层的形式形成了实质上的卷积。

图1 RCNN原理图
具体来说,其是借用双向RNN 的形式将当前上下文wi的左侧文本表示cl(wi)以及右侧文本表示cr(wi),与当前词向量wi链接,构成后序卷积层进行输入。举例子来说,我们以上图表示进行说明,South的词向量将会链接其左侧文本表示cl(w7)、右侧文本表示cr(w5),然后构成后序卷积层进行输入。链接形式如式(1)所示。
在链接完成后,链接信息会输入进一个卷积核大小为len*1(len 为词向量长度)的卷积层,该卷积层的激活函数在此规定为tanh,具体如式(2)所示。
在最后经过以上处理的文本语义信息,将通过池化层进行池化操作[16],并通过softmax 函数最终生成对应的概率分布。如式(3)所示。
2.3 基于RCNN的模型的改进
本文所使用的深度学习后端分类算法是基于RCNN 模型的基础上改进而来。主要改进内容如下。
1)调整激活函数为ReLU,有效缓解过拟合问题,提升神经网络稀疏性,加快模型反向传播速度。
2)改池化层均值池化为最大池化,降维数据,提取特征差异最大值。
3)在池化层处理之后,加入dropout 操作,以减轻神经元间的耦合现象,增强模型鲁棒性。以公式来体现,dropout 之前模型神经网络数学表示为式(4)。
在进行dropout 之后,该模型神经网络数学表示为式(5)。
4)调节隐层数量,以期达到更合理的模型抽象能力,更加适配短文本场景。
5)调节卷积核尺寸和数量,以期达到计算量和模型抽象能力的平衡。
2.4 本文算法
本文算法部分主要流程如下:
1)读取原始训练数据,划分数据集。
2)配置pad_size(每句话处理成的长度)、学习率、epoch数、类别数。
3)配置隐层层数、卷积核尺寸、卷积核数量。
4)将训练语料输入前置RoBERTa 模型中进行信息抽取。
5)对padding 部分进行mask,保持与句向量保持同样尺寸。
6)将句向量输入改进后的RCNN模型。
7)在模型收敛或达到指定batch后结束模型的训练。
3 互联网消防报警辅助系统的架构设计
3.1 总体设计
本系统总体设计包含三个部分:后端逻辑处理部分、模型数据迭代清洗入库部分以及深度学习短文本分类部分。其中后端逻辑处理部分负责请求接入及结果回送、定时消防报警信息推送以及深度学习模块调启。模型数据迭代清洗入库部分负责定时从给定已标注的业务数据库中抽取和清洗数据,注入已有训练及测试集,重新训练模型。深度学习短文本分类部分负责定义并训练模型,该部分为该系统的核心部分。各部分的关系如图2所示。

图2 总体设计中各模块之间的关系
3.2 后端逻辑处理部分详细设计
该部分向外分别提供请求接入及结果回送与定时消防报警信息推送两个功能支撑。监听给定端口,一旦有请求介入,该部分引擎将先把信息从以json形式表现的请求参数中的信息提取出来,做一部分信息过滤工作(实践证明现实网络接入数据有大量骂人语句等无用信息,该部分将对此类信息进行过滤),若信息通过过滤后,切换系统态调启python 进程,进行预测并返回预测结果。除了提供以上请求接入及结果回送功能以外,本部分还提供定时消防报警信息推送功能的支持。通过@Scheduled注解配置定时任务,每次定时任务开始时从指定热点数据库读取数据,若数据量不够则结束此次定时任务,等待下一次定时任务,若数据量足够,则切换系统态调启python 进程,对数据进行预测,并以json 数据格式为载体推送至远端服务器。具体处理流程如图3所示。
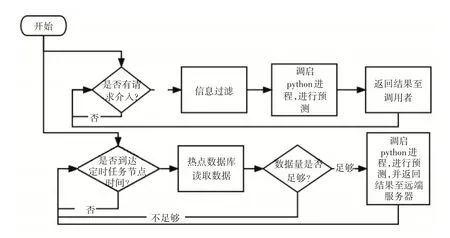
图3 后端逻辑处理部分详细设计
3.3 模型数据迭代清洗入库部分详细设计
该部分通过@Scheduled注解配置定时任务,从给定已标注的业务数据库中抽取和清洗数据,注入已有训练及测试集,重新训练模型。具体处理流程如图4所示。

图4 模型数据迭代清洗入库部分详细设计
4 实验结果与分析
对于后端逻辑处理部分与模型数据迭代清洗入库部分。作者使用调试、postman工具测试、日志追踪等形式进行了功能验证,功能完好,可以使用,典型测试场景如图5。
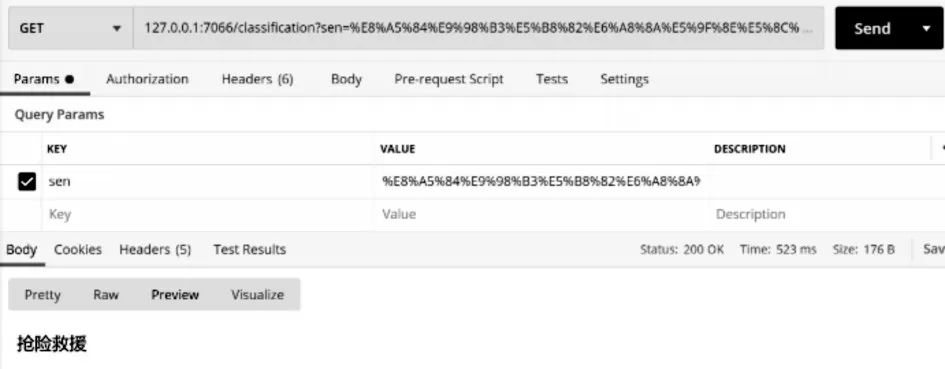
图5 测试典型场景
对于核心功能深度学习短文本分类部分,作者使用了上海立信会计金融学院所提供的防灾减灾数据集再加上作者自己在互联网上爬取、标注的数据以及业务数据,共同构建了该分类数据集。该数据集以中文为主,共计16800 条数据。在这16800条数据中,笔者利用sklearn工具以6∶1∶1的比例进行分割,选取12600 条数据用于训练,2100 条数据用于验证,2100条数据进行测试。
测试模型所依赖的语言为python 语言。实验各硬软件环境数据如表2所示。
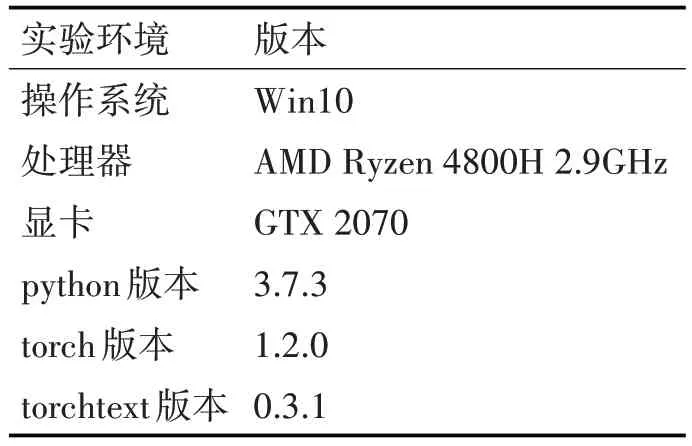
表2 实验硬软件环境
将本文所设计的短文本分类系统与工业界常用算法RoBERTa+BiLSTM,以及传统算法RNN 相比较。从模型预测能力、模型工作效率两个方向上对模型进行评价。以准确率(分类正确样本占总样本比例)、识别效率(模型处理10 个短文本所需时间)作为评价标准。实验结果如表3、图6所示。
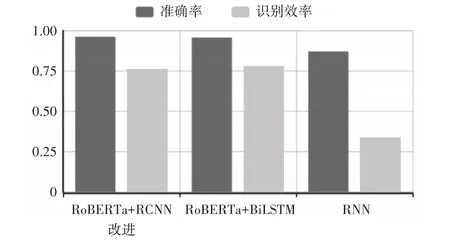
图6 实验结果条形图

表3 实验结果表
从以上图表可以看出,在准确率上,本文所提出的模型较工业界常用模型(RoBERTa+BiLSTM)有所提升,较经典RNN 模型有大幅提升,但在模型时间效率上不如经典RNN 模型,但与工业界常用模型在同一水平上。
5 结语
本文设计研究了一种基于RoBERTa 和RCNN的互联网文字消防接警辅助系统,提出了一套后端逻辑设计方案及深度学习短文本分类模型。经实验证明,后端逻辑设计方案切实可用,深度学习短文本分类方案较工业界常用方案及经典方案在准确率上进行了提升,并保证了不错的时间效率。在新时代、新形势下的人民消防工作下,该设计及系统具有相当的实战意义,有助于节约国家财务成本,有助于保障人民群众的生命健康权。
猜你喜欢
消防界(电子版)(2022年18期)2022-10-29
北京航空航天大学学报(2021年9期)2021-11-02
小天使·一年级语数英综合(2020年11期)2020-12-16
消防界(2019年2期)2019-09-10
电子制作(2019年11期)2019-07-04
时代英语·高二(2018年7期)2018-12-03
读者(2018年18期)2018-08-31
时代英语·高二(2018年3期)2018-06-06
北京航空航天大学学报(2018年1期)2018-04-20
电视技术(2014年19期)2014-03-11
