
深度学习驱动的电网无功-电压优化控制策略模型
2023-11-18 04:31李彦君刘友波冉金周刘俊勇
电测与仪表 2023年11期
李彦君,刘友波,冉金周,刘俊勇
(四川大学 电气工程学院,成都 610065)
0 引 言
随着电网技术的飞速发展下,对系统的电能质量、功率损耗优化要求也越来越高。在电力系统最优潮流模型中是以社会效益、稳定裕度最大化、有功功率损耗最小为目标,基于数学模型利用数学规划方式进行求解。
目前电力系统应用最为广泛的最优潮流算法为非线性规划法。非线性规划法主要包括梯度法、牛顿法、二次规划法、内点法等。梯度法原理简单,沿控制变量的负梯度方向进行寻优,在求解优化问题时对初值的要求不高,但在接近最优点的路径上搜索缓慢,出现锯齿,并且修正步长的选取直接影响算法性能。另外罚函数的罚因子数值的选择是否恰当对算法有很大的影响,若选择的参数不当则不能保证全局收敛,收敛速度也会降低。二次规划法很好的适应了网络优化问题中目标函数为二次函数、非线性的特点。但是二次规划法的计算时间随系统规模的增大明显延长,不能保证全局收敛。内点法目前在电力系统得到广泛应用,该法在可行域内从初始点出发沿着中心路径直接走向最优解,优化结果对初值依耐性较强,其中一种改进的方法路径跟踪法有效地避免了对初值选取的敏感性,同时具有鲁棒性强的特点,但是该法不适用于离散、连续混合变量的优化求解。随着现代电力系统规模日益扩大,离散变量在电力系统中屡见不鲜,系统优化的难度加大,对求解算法的要求也越来越高,如能快速、可靠地收敛于最优解等,故传统的数学方法在求解功率优化问题时有很大的局限性。近年来,一些基于人工智能的启发式搜索算法[1],如遗传算法、强化学习[2]、粒子群算法[3]等,具有全局收敛性,在电力系统优化问题中有着广泛的前景。
文献[4]选用收敛速度快、收敛可靠性比较高的牛顿-拉夫逊法进行潮流计算全网网损,并在此基础上对修正方程式的求解进行一些改进,进一步提高了计算速度。文献[5]提出了配合PQ分解法潮流计算的B′矩阵法和转置B′矩阵法有功网损微增率算法,并运用优化算法进行改进,提高了算法的计算速度和效率。然而解析法对网络拓扑结构、运行测量数据精度以及系统参数依赖层度较高,复杂的迭代求解在网损优化时存在鲁棒性不强的问题。在与大数据结合方面,近几年也颇受研究者们的推崇[6-10],文献[6]采用数据挖掘和场景模拟思想,提出了一种新颖的基于混合聚类分析的网损评估方法。该方法根充分考虑电力数据特点的基础上,分别选取划分聚类算法和层次聚类算法对其进行聚类分析,根据基于混合聚类结果生成电网的典型运行方式集,以用于网损评估。但是仍然存在电网网损数据样本聚合精度较低、计算精度不高的问题。文献[10]提出了一种基于改进遗传算法(IGA)的BP神经网络方法计算配电网的理论线损。该算法(GA)有效地克服了GA算法的搜索效率低、个体多样性差及早熟现象,提高了算法的收敛性能。但浅层的BP神经网络却有它明显的局限性,对于高维特征变量存在拟合效果较差,训练时间过长的缺陷。
随着新能源的发展与引入,由于能源的不稳定性对配网电压越限风险影响显著,无功优化显得十分重要。文献[11]针对含分布式电源(DG)的配电网无功优化的问题,通过加权高斯混合分布(WGMD)和Beta分布分别构建风电DG和光伏DG更准确的出力模型。采用改进的非支配排序遗传算法(NSGA-Ⅱ)对系统有功网损最小、节点电压总偏差最小为目标函数的无功优化模型进行求解。文献[12]针对光热-光伏系统无功控制问题,提出一种基于模型预测控制MPC (model predictive control)的多时间尺度无功优化控制策略。通过灵敏度电压预测模型,预测未来多个时刻电压运行状态并以未来多个时刻预测电压控制偏差最小为优化目标,建立日内滚动优化模型。
文献[13]依据配电网拓扑结构、支路参数和部分有监测装置节点的负荷数据,以多种类型分布式电源的出力为决策变量,采用罚函数方法处理约束条件,粒子群优化算法进行优化模型求解,但PSO算法却存在容易错过最优解,算法不收敛以及精度不高的问题。
为解决传统最优潮流计算电力系统网络损耗存在大量离散变量、函数变量关系、约束集时不能快速、有效地求解的问题,文中提出一种利用深度学习与遗传算法相结合的方式有效地避免了传统算法无法对离散、连续混合变量优化的缺陷。该法通过对可调设备的状态以及节点电压幅值准确评估预测系统网络损耗,优化控制具有全局收敛、收敛速度快的特点,功率损耗优化效果显著。
1 基于数据驱动的无功-电压控制模型
1.1 传统最优潮流模型
电力系统有功损耗优化在数学上是一个复杂的非线性规划问题,具有多约束条件、多变量、混合整数变量等特点。传统的数学规划方法收敛可靠,收敛速度快,但这些方法往往依赖于精确的数学模型,要求目标函数可微以及控制变量连续等,电力系统网络损耗的数学模型为:
(1)
其中,目标函数G是实现有功功率损耗最小,等式g表示系统的潮流平衡约束,v、δ、qG、PG、PD分别表示节点电压、节点电压功角、发电机无功、发电机有功以及负荷有功。不等式约束PGj表示发电机有功功率输出极限,不等式PDl表示有功需求约束,不等式δi表示节点之间的功角约束,不等式qGj表示发电机无功输出极限,不等式vi表示节点电压幅值约束。传统最优潮流是典型的非线性规划问题,要求控制变量连续可微,不适合目前存在大规模离散、0-1控制变量的电力系统快速、有效地优化求解,因此文中提出一种基于数据驱动的无功-电压控制模型以解决离散、连续混合变量的求解问题。
1.2 基于数据的驱动潮流优化模型
目前电力系统网络损耗调节的关键措施主要有以下两类:
1)改善网络中的功率分布;
2)合理组织电网的运行方式。
因此,系统中的无功补偿设备、变压器运行方式、发电机出力以及ZIP负荷状态都将影响系统的功率损耗。按理直接将这些相关变量作为输入,与系统网络损耗作为输出进行拟合效果会最佳,但是由于ZIP负荷的特征维数是PQ负荷特征维数的3倍,因此随着网络结构的复杂化、电网规模的扩大输入变量存在维数爆炸的问题,同时维数过多也会影响最终拟合的效果和深度学习的训练时间。
降维是行之有效地处理维数爆炸问题的方法,倘若直接暴力降维虽然减少了变量的特征维数,但是同时也降低了输入、输出变量间的相关性影响训练拟合的效果。在潮流计算中,各个节点有、无功率信息确定时,各个节点的电压也就确定了,因此节点电压具备各个节点功率信息的完整度,用节点电压信息替代节点功率信息既保存了输入、输出变量相关性完整度又大大降低了输入特征的维数。
文中研究场景是在电网设备确定不变的情况下,通过调节变压器变比、无功补偿设备状态以及节点电压幅值信息,运用深度神经网络强大的泛化能力准确快速地预测系统中网络损耗,并以此为调节方式,实现电力系统无功-电压控制,从而达到降损目的。
在系统设备确定的情况下,网损是同发电机机组出力以及负荷波动随时间的变化而变化,其数据驱动的无功-电压控制模型示意图如图1所示。
1.3 样本的生成
1.3.1 负荷模型的选择
为模拟更佳真实的工况,文中采用多项式综合负荷(ZIP)模型,该模型以权重形式包含恒阻抗、恒电流、恒功率3种负荷类型,通常表示为节点负荷功率与节点电压幅值的关系:
(2)
式中api+bpi+cpi=aqi+bqi+cqi=1;PLi、QLi、VLi分别为负载有功、无功、节点电压的标幺值;api、bpi、cpi和aqi、bqi、cqi分别表示节点i恒阻抗、恒电流、恒功率的有功、无功负荷的比重,多项式综合负荷(ZIP)模型生成的样本数据更贴切实际。
1.3.2 佳点集采样
考虑到深度学习的样本很多,为了提高拟合的效果以及解空间的搜素能力,文中采用佳点集方法进行样本生成。佳点集最初由华罗庚等[14]提出,其基本定义与构造为:设Gs是s维欧氏空间中的单位立方体,如果r∈Gs,则为:
(3)
偏差φ(n)满足:C(r,ε)是只与r和ε(ε是任意的正数)有关的常数,则称Pn(k)为佳点集,r为佳点,p是满足(p-3)/2≥s的最小素数,其中{a}表示取a的小数部分。这样生成的佳点集在多维的单位立方内,所以需要将离散变量映射到多维单位立方区间,每个离散变量对应的区间距离相同,形成等概率事件。
由佳点集理论可知,随机法生成的样本集在取相同5 000个数点的情况下,采用佳点集生成的样本空间更加均匀,而随机点集的样本空间相对稀疏,对比效果如图2、图3所示。因此,将输入样本空间上无功补偿设备、变压器运行方式、发电机出力情况以及负荷的佳点集映射到目标求解空间,可使样本更具有遍历性,提高了解空间的搜索能力,从而更好的达到全局寻优的目的。

图2 佳点集采样

图3 随机样本采样
在约束条件中变压器的变比、电容器的电容值属于离散变量,变量的空间模型描述如下:
(4)
式中ki表示第i个变压器的额定变比;rij是第i个变压器j挡的抽头;Ri表示抽头后新变比;Ci是第i个电容节点处j组电容值之和;Ci.min、Ci.max表示SVC的极值范围。
(5)
式中表示第i个节点发电机机组出力以及节点电压约束。
(6)
式中是ZIP模型第i个负荷节点的有功、无功的约束条件,Pzi、Pii、Ppi分别表示第i个负荷节点的恒阻抗、恒电流、恒功率的有功;qqi、qqi、qqi分别为第i个负荷节点的恒阻抗、恒电流、恒功率的无功。
文中通过不断改变系统的节点负荷与机组出力,同时对变压器变比、电容器、SVC进行佳点集采样,利用潮流计算找到对应的节点电压以及系统网损,生成输入特征、输出特征样本。
2 深度学习训练及遗传算法寻优
2.1 深度神经网络
深度神经网络理论上可以拟合任何函数,具有强大的非线性拟合能力[15],而电力系统是个典型的非线性系统,目前深度神经网络与电力系统相结合的运用已有很多,验证了深度神经网络在电力系统各方面优秀的学习能力。
深度神经网络(DNN)从不同层的位置划分,DNN神经网络层可以分为三类,输入层、隐含层和输出层如图4所示。

图4 神经网络结构图
图4中每一个圆圈都代表一个神经元。在DNN的结构里下层神经元和所有上层神经元都能够形成连接,层与层之间是全连接的,也就是说,第n层的任意一个神经元一定与第n+1层的任意一个神经元相连。层与层之间是一个线性关系,再通过一个激活函数σ(z)关联在一起的。
2.1.1 前向传播算法
使用上一层的输出计算下一层的输出,就是所谓的前向传播算法。就是利用若干个权重系数矩阵W,偏置向量b来和输入向量X进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直运算到输出层,得到输出结果为止。

(7)
2.1.2 反向传播算法
根据前向传播算法得到的预测结果很可能跟真实结果不一致,甚至相差甚远。
反向传播算法是起到一个反馈作用,通过与标签值比对,用一个合适的损失函数来度量训练样本的输出损失,然后对这个损失函数进行优化不断调整权重矩阵W、偏置向量b直至神经网络达到准确预测的能力。
DNN中常用均方差作为损失函数来度量损失,结合前向传播算法:
(8)
对第l层W、b的梯度进行求解:
(9)
当第l层的输出值al与标签值y相同时,即:al=y。
此时对应的权值矩阵W、偏置向量b即为所求,工程中一般当W、b的变化量小于一个足够小的阀值ε时,就会停止计算并更新每一层的权值和偏置项。
2.2 样本的DNN封装模型训练
样本深度学习本质是找到控制变量与目标变量的隐性映射关系。文中通过DNN对系统各节点变压器变比、电容器值、SVC值在随各节点的负荷、发电机出力变化即不同节点电压时与系统网损进行拟合。因此输入特征为:变压器变比(离散)、电容值(离散)、SVC值(连续)、节点电压;输出特征为:有功损耗,训练方式如图5所示。

图5 训练封装模型示意图
在某一特定时刻,发电机出力与节点负荷是不变的即节点电压值确定,此时变压器变比、电容器值、SVC值映射一个特定网损值。由于发电机出力、节点负荷随时间变化,因此不同时刻即使相同的变压器变比、电容器值、SVC值映射的网损值也与之前不同。
训练好的神经网络等于找到了输入、输出特征变量之间的映射关系,下一步就是优化求解的问题。
2.3 遗传算法寻优
优化求解的方式很多,由于文中控制变量较多,优化对搜索空间的要求很高,而遗传算法的操作对象是多个可行解而非单个,搜索轨道也有多条,因而具有良好的并行性和稳定的全局优化性能。它只需要利用目标函数的取值信息,而无需梯度等高阶信息,适用于大规模、非线性、不连续以及没有解析表达式的目标优化,具有很强的通用性。与前文深度神经网络相结合,将深度神经网络学习到的节点电压、设备状态与网损之间的映射关系嵌入遗传算法,遗传算法通过改变设备状态优化系统网损,寻优过程如图6所示。

图6 基于深度学习的遗传寻优
2.3.1 目标函数
网损的计算方式大致分为两类:一类是根据系统总网损等于全网各节点总净注入功率;另一类则是根据系统总网损等于系统中各支路功率损耗之和。文中就是采用网损等于全网各节点总净注入功率的方式计算:
(10)
式中g为网络中电源的个数;l为负荷节点的个数;PGi、PLj分别为第i个电源节点有功功率以及第j个负荷节点有功功率值。选取目标函数:
minf=PLOSS
(11)
式(11)中PLOSS为式(10)中PLOSS的计算方法。
2.3.2 改进遗传算法交叉、变异方式
文中由于优化的变量较多,遗传算法采用了精英预留的方式确保最优秀的基因能够遗传到后代,交叉是遗传算法获取优良个体的重要手段,因此交叉概率一般取值较大,文中交叉系数设置为0.9,交叉操作采用多变量同时交叉。在变异操作中,变异概率不宜取得过大,如果P> 0.5,遗传算法就可能退化为了随机搜索。为了避免高适应度染色体在早期迅速占领种群造成染色体之间基因过于近似导致“早熟”,对染色体实施灾变。变异率设置成动态变化,随着迭代次数的增加提高变异的概率,变异函数为:
Pmu=pstart+padd×et-Tmax
(12)
式中Pstart、Padd分别为起始变异概率、迭代增加变异概率;t、Tmax分别为当前迭代数、最大迭代数,通常变异率设置在0.1~0.2之间,同时动态补充新的种群个体,种群函数为:
(13)
式中nstart、nadd分别表示起始种群数、迭代增加种群数。变异方式采用单基因变异,这样打破原有基因的垄断优势的同时加快收敛速度。同时注意交叉、变异过程要满足边界条件。适应度函数采用动态非线性标定的方式:
(14)
式中ξ(t)为选择压力调节值,是个较小的数随迭代次数t的增加而减小,r∈[0.9,0.999]的常数;M为常数;ξ(t)确保了最差个体仍然具备繁殖能力;f为目标函数。
改进算法在确保种群广域搜索的同时保证局域搜索的收敛性。
2.3.3 改进GA算法全局收敛性证明
由于文中优化的封装模型具有目标单一、控制变量较多的特点,为证明改进算法的适用性以及全局收敛性能,用多元的Ackley函数进行测试,其中Ackley函数定义为:
(15)
式中c1=20,c2=0.2,c3=2π,e=2.712 82,这是一个多峰值函数,具有很多局部极小点和一个全局极小点,最小值为FAckley(0,…,0) = 0,下面通过IGA算法对Ackley函数最小值进行求解,迭代收敛过程如表1所示,其中Pstart、Padd分别为0.1、0.1。

表1 Ackley函数的IGA求解收敛过程
从表1可以看出,随着迭代次数的增加,Ackley函数逐步收敛于FAckley(0,…,0)=0,验证了改进GA算法在多元变量优化过程中良好的全局收敛性。
3 算例分析
本节基于控制装置、发电机出力及负荷的实际运行参数进行算例分析,验证所提模型优化的有效性并对相关参数进行了说明。
文中用IEEE 30节点的系统进行验证,具体做法是:在确保该系统潮流计算正常收敛的情况下,通过不断调节电力系统中电容器值、SVC值以及变压器变比的分接头,进行潮流计算,生成输入变量为:电容值、SVC值、变比,输出变量为网络损耗的样本。其中IEEE 30节点的系统有发电机5台,电容器、SVC装置各5台,变压器4台,线路37条,网络结构如图7所示。图7中方点表示PV节点,三角点表示平衡节点,圆点表示负荷节点。输入样本特征维度44维,样本除了14个控制变量外还包含发电机PV节点、ZIP负荷波动数据对应的30个节点电压值,输出样本有功损耗特征维度1维。

图7 IEEE 30节点示意图
3.1 深度学习训练效果
为验证样本输入特征与输出特征的相关性,文中通过MATLAB中nnstart拟合工具分别对未降维的随机点集样本输入特征维数167以及降维后输入特征维数44的佳点集样本、随机点集样本进行拟合,拟合效果如图8~图10所示。通过图8、图9可以看出输入特征变量与输出特征变量的相关性很高,R值都接近于1。图9是随机点集相同样本数在训练相同次数100次时的拟合效果,跟图8比较,佳点集样本的相关性更高。图10是使用潮流功率分布数据的特征样本,除控制特征外里面包含了所有节点的有功、无功特征信息,与图8、图9相比高纬度数据的拟合效果远不如选取节点电压信息替代降维后的拟合效果,输入、输出特征的相关系数R不到0.86。

图8 30节点佳点集拟合图
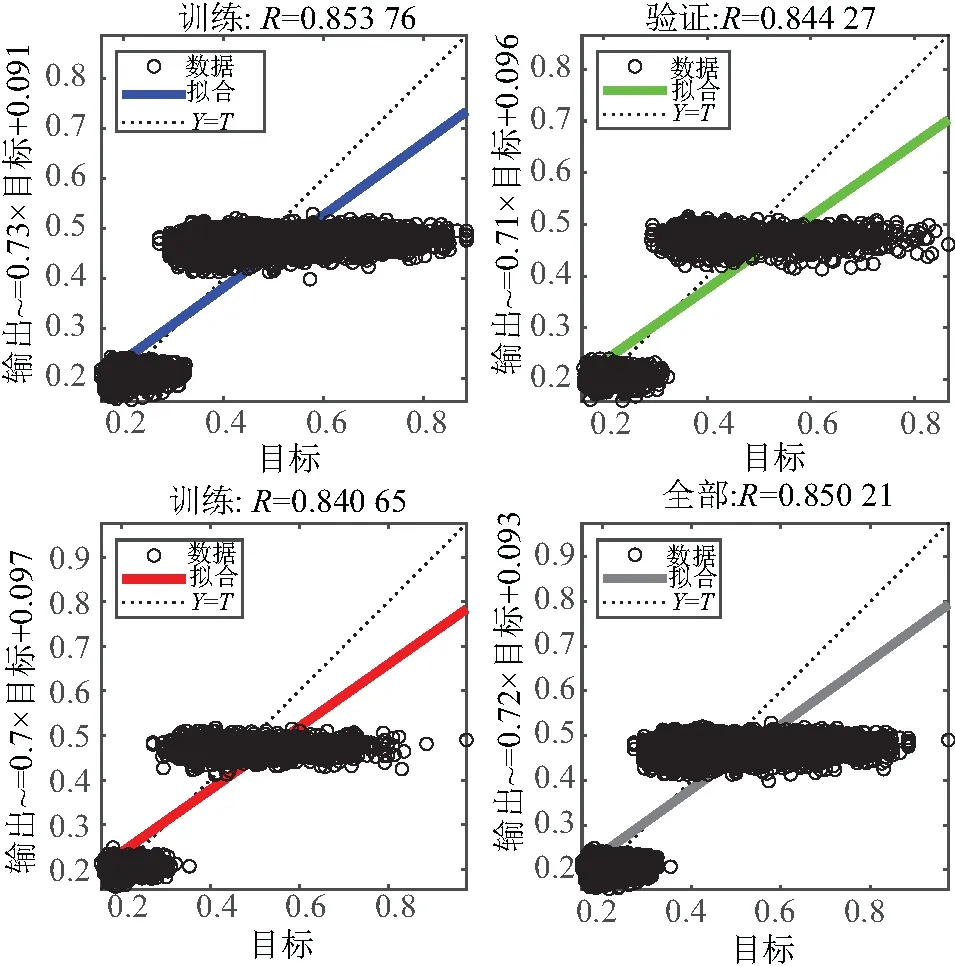
图10 30节点未降维随机点集拟合图
根据深度神经网络结构原理,文中通过MATLAB中Deep Learning Tool Box工具将20 000个样本分为90%训练集和10%测试集通过试验的方法,分别尝试含有2个、3个、4个隐含层神经网络的模型结构,再结合不同的隐藏层节点数组合,共进行上百次调参试验找出最好的训练效果参数,其中学习速率均设为0.001,动量设为0,由于训练数据量够大,为了提高效率,避免训练震荡而不收敛,批量大小设置为500,最大迭代次数设置为300。因篇幅有限,文中不一一列举试验过程,只将最佳网络结构及预测误差精度进行说明,结果如表2所示,神经网络各层都采用全连接,IEEE 30节点系统训练的网络有3个隐含层,各隐层神经元个数根据预测误差精度最高原则,通过实验均已在表2中列出。

表2 神经网络结构参数及误差精度表
表2预测误差精度RMSE的大小是样本10%的测试集随训练迭代次数变化,迭代过程如图11所示,从图11可以看出误差精度随训练迭代次数增加而降低,直到趋于平缓,佳点集样本测试集误差精度RMSE的迭代收敛速度略快于随机点集且训练300次后的误差RMSE为0.038 7,随机点集误差RMSE为0.042 5。图12、图13分别是佳点集样本和随机点集样本中测试集训练后的误差直方图。图13是佳点集测试样本与随机点集测试样本深度学习后预测值与真实值的对比曲线,其中虚线代表预测值,实线代表真实值,效果如图14所示。

图11 测试集RMSE迭代曲线

图12 佳点集测试样本误差直方图
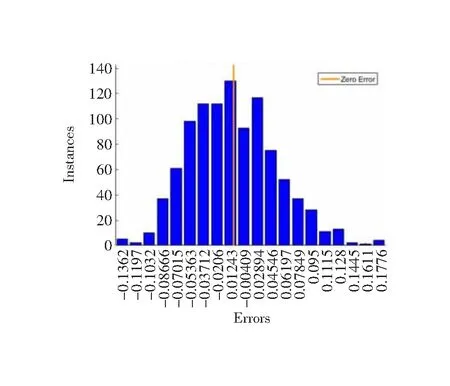
图13 随机点集测试样本误差直方图

图14 测试集样本预测曲线
3.2 遗传算法目标函数的优化
在未使用改进遗传算法策略时,对IEEE 30节点系统某一时间断面进行网损寻优,系统优化前网损初始值为0.198 3(p.u.),优化后网损值降到了0.197 7(p.u.)左右,根据系统单一断面网损实验数据优化结果可以得出,通过调节变比,无功补偿设备对网损优化的策略有效,且其中采用佳点集样本进行系统网损优化比采用随机点集样本优化具有更好的遍历性,效果见图15所示。

图15 佳点集、随机点集GA算法优化对比
另一方面,为了验证2.3.2节中改进遗传算法策略的有效性,对同一时间断面的系统用改进后方式进行优化,并与改进前算法的优化效果进行对比,如图16所示,图中可以看出改进后的算法策略虽然此刻并未体现出遍历性更好的优势,但展现出了更快的收敛速度,提前找到最优解。

图16 佳点集GA、IGA网损优化对比图
表3是根据图15、图16的总结,从表中可以看出通过佳点集样本训练的神经网络结合改进的遗传算法,对系统网损的优化遍历性更好、收敛速度更快。表4是图16中采用改进后算法优化前、后设备的调节控制方式,以及对应的网损情况。
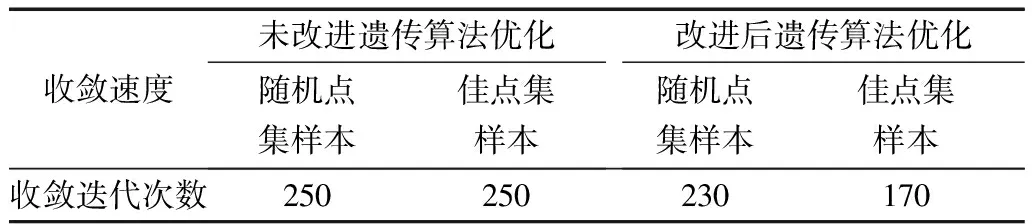
表3 改进前、后算法优化对比表
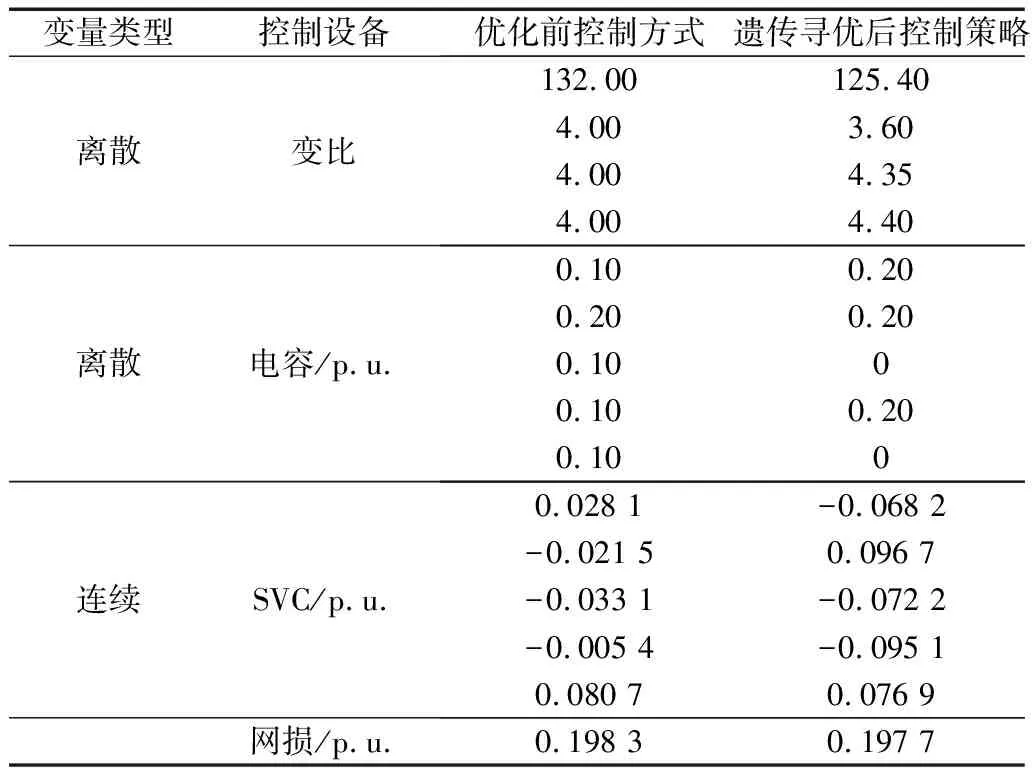
表4 改进算法寻优控制策略表
表5在不同时间断面通过对系统内部参数调节改变系统潮流分布,表中5个断面潮流分布各不相同,并对其使用改进遗传算法策略优化系统有功损耗的情况,从表5中可以看出佳点集样本训练的神经网络具有更好的全局优化能力,具体迭代优化效果如图17对应所示。
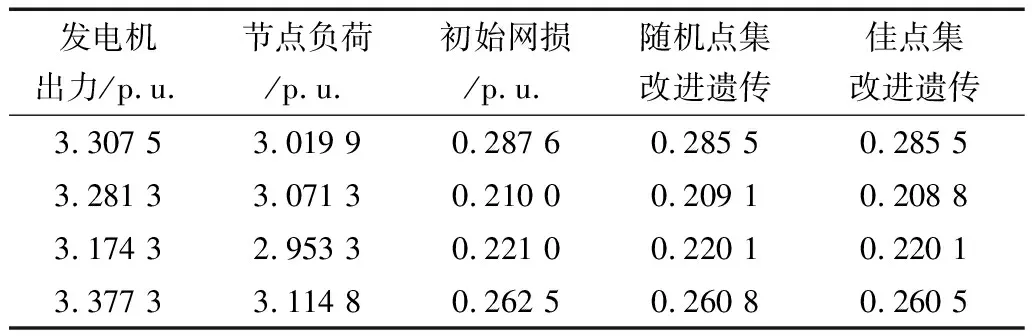
表5 IEEE 30节点网损(p.u.)优化表
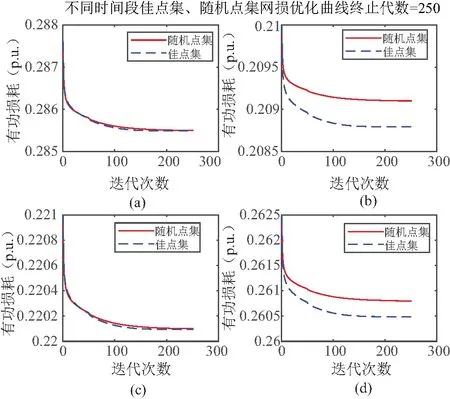
图17 改进算法佳点集、随机点集优化对比图
4 结束语
文中提出一种无功-电压优化系统潮流有功损耗的控制策略,并结合深度神经网络与智能算法有效地解决了传统数学规划对电力系统大量离散控制变量优化不能有效、快速求解的问题,通过降维的方式有效解决输入特征维数过大导致训练拟合效果差的问题,同时利用佳点集抽样的方式让训练样本更均匀提升神经网络训练效果,并对IEEE 30节点系统进行仿真计算,验证了无功-电压优化控制网损策略的有效性,从文中大量的实验数据和改进的方式还可得出以下结论:
1)采用佳点集抽样训练的神经网络比随机点集抽样训练的神经网络有更好的拟合效果和误差精度,同时在与智能算法相结合时有更好的优化能力;
2)改进遗传算法提升了传统遗传算法的广域搜索能力,能够提升搜索的迭代速度;
3)用节点电压数据替代系统功率分布数据,在有效降维的同时保证了关联信息的完整性,大大提升了训练拟合的效果和误差精度。
猜你喜欢
电子制作(2019年19期)2019-11-23
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
重型机械(2016年1期)2016-03-01
智能系统学报(2015年4期)2015-12-27
大连工业大学学报(2015年4期)2015-12-11
核科学与工程(2015年2期)2015-09-26
