
基于智能电网设备运维检修阶段的多源BIM数据存储方法研究
2023-11-17 09:10:12张苏齐立忠武宏波荣经国
电测与仪表 2023年11期
张苏,齐立忠,武宏波,荣经国
(国网经济技术研究院有限公司,北京102209)
0 引 言
伴随建筑信息模型(building infor mation modeling,BIM)技术日益成熟,电力领域、公路领域等众多领域逐渐引入了BIM技术。BIM是一个从规划、设计、施工到管理各阶段统一协调的过程。BIM技术是电力建设信息化发展的重要方向,令电力系统发展更加数字化与智能化[1]。BIM数据存储方法是BIM技术的重要组成,可实现BIM海量内存资源的高效利用。利用高效的数据存储技术[2-4],检索海量BIM多源数据,实现BIM数据的可靠传输。BIM数据具有结构复杂、种类繁多、数据过于分散以及数据量大的特点[5-7]。研究具有高稳定性的BIM数据存储技术,便于BIM技术在电力领域更加良好的应用。
伴随配电网的信息化发展,电力系统设备数量以及设备运行数据量直线上升,电网设备运维检修的工作量急剧上升[8-10],提升了电力系统运维检修工作人员的工作难度。BIM技术具有智能化、直观可视化的特点,为电网设备运维检修领域提供重要的理论支持[11],探讨BIM技术在电力领域的应用性极为重要。电网设备运维检修阶段网络数据的存储是至关重要的。一旦重要数据丢失或损坏,将对电网设备造成难以弥补的损失[12-13],造成设备运行过程中出现事故,令电力企业出现严重的人员伤亡以及经济损失。因此需要设计可靠的数据存储方法,确保网络数据的安全。利用BIM技术提升电网设备的管理水平,是电力领域信息化管理的重要组成。
目前已有众多研究学者针对电力领域的数据存储方法进行研究。文献[14]将分布式压缩感知方法应用于电能质量数据存储中,通过对配电网电能质量数据压缩,提升配电网电能质量数据的存储性能;文献[15]对电力数据存储系统参数调优进行研究,调优后的电力数据存储系统提升了电力数据的存储性能。文献[16]在数据源中筛选提取高度重复性质的数据,擦除冗余数据,达到降低数量级压缩数据源的目的,提高数据存储性能;文献[17]通过压缩和保存结构化网格的方法,减小结构化网格文件的大小。当网格被解压缩时,使用超限插值算法从压缩数据中恢复所有网格顶点坐标,实现网格压缩,便于存储数据。
以上方法虽然可以实现电力系统中,电能质量数据以及电力数据的存储,但是无法应用于具有较高动态性的电网设备运维检修阶段。电网设备运维检修阶段的BIM数据具有多源的特点,动态性较高,研究电网设备运维检修BIM数据存储时,需要充分考虑数据的动态性以及多源性。
在电网设备检修时,智能电网设备运维检修阶段的多源BIM数据,有助于辅助相关人员进行检修决策,而大多数存储方法无法应用于具有较高动态性的电网设备运维检修阶段,论文基于面向电网设备运维检修阶段的多源BIM数据存储方法,将BIM技术应用于电网设备运维检修阶段,针对电网设备运维检修阶段包含的海量多源数据,利用高效的多源BIM数据存储方法,提升BIM多源数据的应用可靠性。
1 多源BIM数据存储方法设计
1.1 电网设备运维检修多源BIM数据整合
1.1.1 多源数据整合流程
电网设备运维检修多源数据采集是构建电网设备BIM模型的数据基础。电网设备运维检修阶段包含海量的多源异构数据,海量多源异构数据的整合具有重要意义。利用MySQL数据库以及SQL查询语言,实现海量电网设备运维检修阶段多源异构数据的整合。MySQL数据库是关系型数据库,适用于多源异构数据的整合中,SQL查询语言是针对MySQL数据库设计的,应用于电网设备运维检修多维数据信息交互的重要语言。由于电网设备运维检修数据具有多源异构的特点,需要利用数据接口适配器,针对电力系统中各运维检修相关系统建立数据接口,利用接口将运维检修数据传送至数据抽取引擎中,数据抽取引擎利用ETL技术抽取所采集数据,完成抽取后形成运维检修的临时数据,传送至数据转换引擎,数据转换引擎将众多数据转换为构建BIM模型所需的多源BIM数据。采集电网设备运维检修多源数据,对所采集的多源数据整合的结构图如图1所示。
构建电网设备运维检修多源数据整合的统一数据库时,需要依据统一数据库规定,对多源BIM数据中的不同类型数据,依据存储规则直接存储数据。对于多源数据中的故障工单等非结构化数据[18],需要对原始数据进行解析,对解析后的数据进行抽取,重新存储抽取后的数据。结构化数据和非结构化数据的对比如表1所示。

表1 数据类型对比
1.1.2 基于MySQL数据库的多源数据关联存储
对多源BIM数据进行格式统一化处理后,需要依据实际需求,对应用于构建电网设备BIM模型中分散存储的数据,依据多源数据间关系[19],实现关联存储。关系型数据库MySQL可以充分考虑多源BIM数据间的关联关系。利用关系型数据库MySQL组织电网设备运维检修的多源数据,将用户所需的电网设备运维检修数据利用事实表和维度表表示。事实表和维度表分别体现MySQL数据库中,全部数据实体以及数据维度[20]。利用维度表存储数据实体的关联关系,构建完整的电网设备运维检修信息记录。MySQL数据库的组织方式如表2所示。
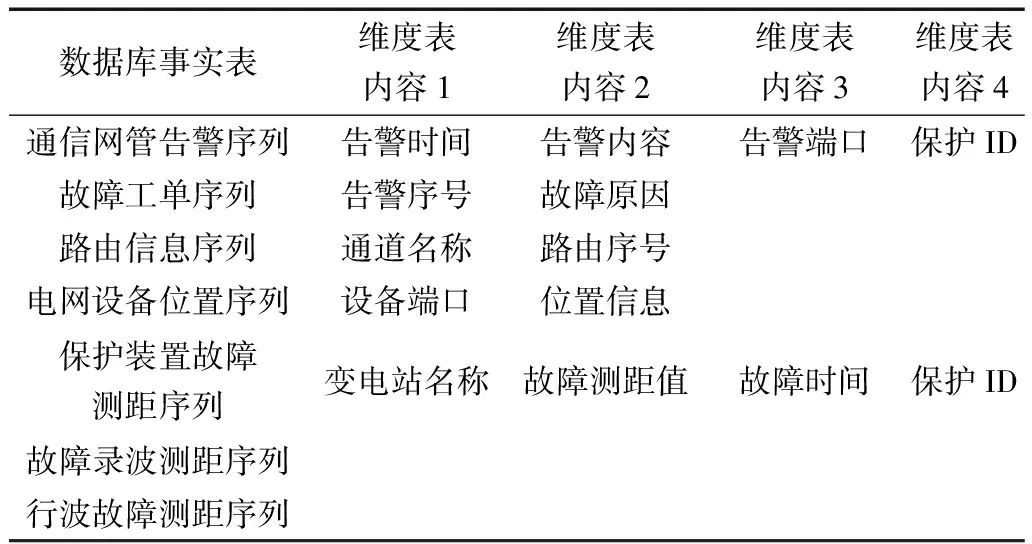
表2 MySQL数据库组织方式
通过以上过程统一电网运维检修多源BIM数据格式,将电网设备运维检修多源BIM数据整合至MySQL数据库内,为电网运维检修多源BIM数据存储提供基础。
1.2 构建多源BIM数据模型
利用电网设备运维检修多源数据整合结果,构建面向运维检修阶段的电网设备BIM模型。电力系统设备管理的重点是信息管理,利用BIM技术构建电网设备运维检修阶段的电网设备BIM模型时,需要对MySQL数据库中包含的电网设备信息进行分类、定义与赋值[21],满足BIM技术构建电网设备运维检修阶段BIM模型的需求。
根据电网设备信息的分类、定义和赋值,对其制定合适的编码,是电网设备BIM模型信息管理的重要前提。通过设备编码便于量化提取电网设备运维检修相关的标准信息[22]。对于不同的电网设备需要赋予不同编号,便于区分不同电网设备。
构建电网设备运维检修BIM模型的电网设备编码规则如图2所示。
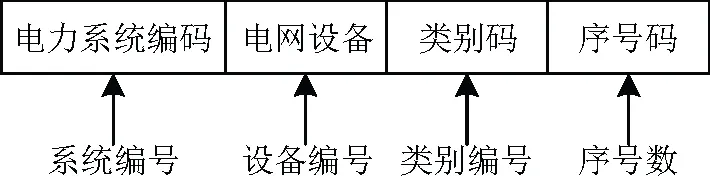
图2 电网设备编码规则
通过电网设备编码规则,令所构建的面向运维检修阶段的电网设备BIM模型更加标准化,为多源BIM数据存储提供良好的数据基础。所构建的电网设备运检维修的电网设备BIM模型中需要包含电网设备的完备信息[23],电网设备运检维修时,通过BIM模型的设备标识信息中,包含的设备名称、设备维修时间、设备检修次数等信息,明确设备运维检修状况。
构建电网设备BIM模型是电网设备运维检修阶段的重要部分。对于没有BIM模型的电网设备,应该构建电网设备BIM模型,在所构建电网设备BIM模型中,添加设备运维检修的相关信息。电网设备已经具备BIM模型时,需要检查所构建BIM模型是否为三维模型,其中包含的信息是否可以体现设备运维检修状况,包含信息不足时,需要及时补充与完善。完成电网设备BIM模型构建后,需要将所构建电网设备BIM模型导出至MySQL数据库中,存储至数据库内。存储过程中按照表2的MySQL数据库组织方式,导出电网设备BIM模型明细表,清晰的观测各个设备的运行状态,告警时间、告警信息等内容。MySQL数据库包含电网设备信息库与待检设备库两种,运维检修人员可在不同的数据库中分别更改相关BIM模型数据。运维检修人员可以在需要时,通过数据库查看电网设备运维检修信息[24]。设备达到运维检修需求时,将设备信息传送至待检信息库中,通知现场操作人员对电网设备进行检修。将电力设备BIM模型中的电网设备信息导入MySQL数据库中,或者直接在MySQL数据库中添加电网设备信息以及图片,依据电网设备的不同编码信息,完成BIM模型的搜索查询功能,便于电网设备运维检修人员快速查询电网设备信息,修改电网设备状态属性等需求。BIM模型具有数据导出功能,利用数据导出功能,实现数据打印与导出等众多功能。
1.3 云边协同技术的多源BIM数据存储方法设计
云边协同技术是边缘计算在云计算数据中心之外汇聚节点的延伸,由边缘向云反馈信息,云向边缘发布指令等,实现共存协同式的调度、命令、搜集、处理、计算、更新等工作。
云边协同的面向电网运维检修阶段的多源BIM数据存储结构图如图3所示。
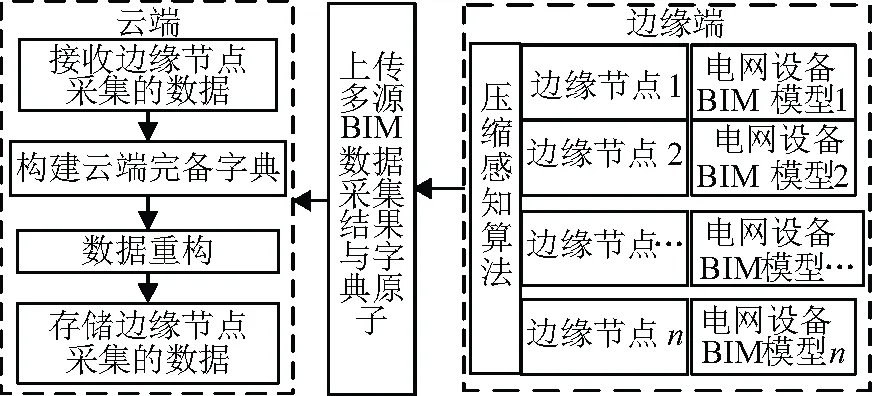
图3 云边协同的多源BIM数据存储
图3中,云端负责处理和存储非实时性、复杂度高、全局性的多源BIM数据;边缘端支持小型实时本地数据业务,在计算和存储上不会产生较高的设备成本,经济性高。
在云边协同中,遵循任务分配原则和数据处理原则,利用边缘计算技术的边缘节点采集所构建电网设备BIM模型的信息,获取电网设备运维检修的多源BIM数据,并对其进行重构处理。重构处理过程中形成重构数据与稀疏字典原子,利用远程云端,上传至云端。同时云端将调整后的预测结果和调度安排下放至边缘端中的各边缘节点,边缘节点相应调整自身调度计划,并将最终的信息回传至云端,完成云边协同。
通过云端对电网设备运检维修BIM数据进行压缩存储,同时构建完备稀疏字典。具体实现过程如下:
用n表示边缘节点采集电网设备运维检修BIM数据的长度,边缘节点上传电网设备运维检修BIM数据的字典原子数量为δ,存在压缩感知表达式如下:
(1)
式中S表示分布式压缩感知运算;Ym×s与Xn×s分别表示边缘节点的采集值以及原始多源BIM数据;Bτ×n表示边缘节点采集的电网设备运维检修数据上传至云端的字典原子;δ与m分别表示上传云端字典原子数量以及测量矩阵长度;γm×n表示稀疏矩阵;Φn×n表示多源BIM数据的测量矩阵。
云端整合各边缘节点上传的字典原子,构建完备的字典Bk×n,k表示完备字典的总原子数量。多源BIM数据存储需要调取电网设备的运维检修数据时,需要确定电网设备边缘节点对应的稀疏表示系数φn×s,φn×s表达式如下:
φn×s=O(Ym×s,Bk×n,γm×n)
(2)
式中O同步正交匹配追踪运算。
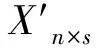
(3)
通过建立多源BIM数据存储云端的完备字典,各边缘节点仅通过电网设备BIM模型运维检修数据的上传,实现多源BIM数据的压缩存储。
构建面向电网运维检修阶段的多源BIM数据存储的完备字典过程如下:
1)计算采集多源BIM数据的边缘节点上传的字典原子bi与云端初始稀疏字典Bk×n中原子的相关度ri,k表达式如下:
(4)
当ri,k值低于所设置固定阈值时,表明云端中的字典Bk×n与边缘节点上传至云端的字典原子bi具有较低的相关性,此时在云端的稀疏字典中加入该字典原子;

(5)
通过式(5)对所构建的稀疏字典进行正则化处理,降低边缘节点上传的各字典原子间的相关性;
3)归一化处理构建的完备字典,更新边缘节点上传的字典原子表达式如下:
(6)
4)将分布式压缩感知算法与完备稀疏字典结合,从边缘节点上传的多源BIM数据中,恢复原始数据,获取各边缘节点对应的稀疏系数φj。将边缘节点采集的电网设备多源BIM数据存储至云端数据库中,实现多源BIM数据的压缩存储,为电网设备运维检修实际应用提供数据,供电网设备运行检修时的BIM数据读取。
2 实例分析
为了验证所研究基于面向电网设备运维检修阶段的多源BIM数据存储方法,对多源BIM数据的存储性能,选取某电力企业的IEEE 33配电网[25]作为研究对象。选取具有多软件交互性和建模灵活性高的软件作为构建电网设备BIM模型的BIM软件,构建应用于配网设备运维检修的变压器、发电机等35个电网设备的BIM模型,如图4所示。

图4 BIM模型
统计采用本文方法利用BIM软件打开电网设备模型的读取时间,统计结果如图5所示。其中,电网设备模型中包含继电保护告警数据、保护装置故障测距数据、故障录波装置测距信息等,共计12 GB。考虑到不同类型的数据大小、格式及维度不同,为了保证读取时间计量的准确性,对电网设备模型数据进行压缩感知重构,促使不同类型的数据格式统一。同时,将重构后的数据按维度分为3、5、7三种,分析本文方法打开重构后电网设备模型数据的读取时间。
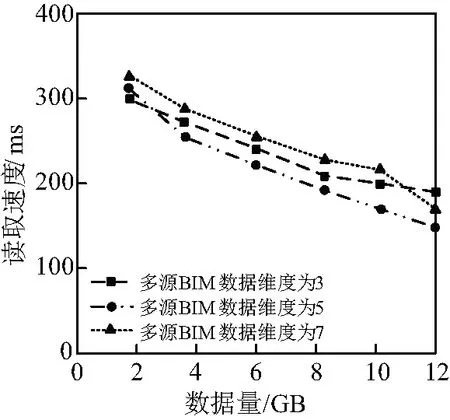
图5 电网设备BIM模型读取时间
通过图5仿真结果可以看出,采用本文方法读取电网设备BIM模型,伴随电网设备BIM模型数据量的增加,读取时间有所降低。不同电网设备BIM模型数据量时,本文方法均可以保证低于400 MB/ms的读取时间。图5仿真结果验证本文方法可以有效降低电网设备BIM模型的读取时间。
多源BIM数据维数较大,使用本文方法对其进行压缩时,需要消耗极大内存,数据维度越大,压缩复杂程度也越高。本文模型在不同多源BIM数据集维数下计算机内存占用率与CPU占用率情况见表3。
由表3可知,随着多源BIM数据维数的增加,计算机的内存占用率和CPU占用率随着增大,当多源BIM数据维数增加至20 000维时,计算机的保护系统自动报错并停止压缩,此时CPU占用率与内存占用率均超过95%,计算机无法再继续工作。
本文方法对多源BIM数据进行压缩重构,选取分布式压缩感知算法作为数据压缩存储的算法。以一次多源BIM数据采集为例,所采集原始多源BIM数据的大小为354.25×106kbit,采用本文方法结合云计算技术与边缘计算技术,压缩感知算法的稀疏字典原子大小为50.845 kbit。BIM模型单次存储深度为20 000个采样点,即2 Mpts。采用本文方法对多源BIM数据进行压缩采集与存储的时间为854 ms。采用压缩感知方法对多源BIM数据进行压缩存储时,所采用稀疏字典原子构建完备字典,利用所构建的完备字典,云端即可实现数据的压缩存储。面向电网运维检修的配网设备多源BIM数据中,某变压器电流数据与电压数据在压缩存储过程中的重构结果如图6所示。
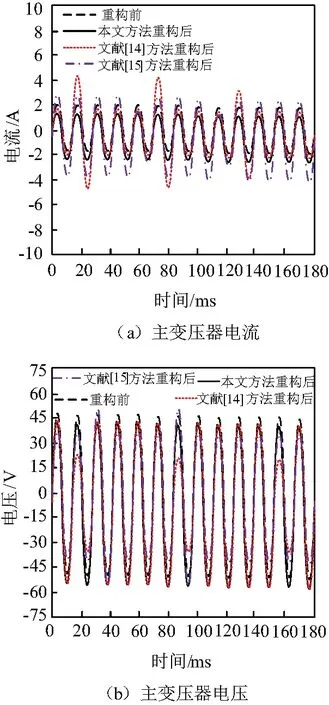
图6 多源BIM数据重构结果
通过图6仿真结果可以看出,重构前电压变化范围为-45 V~45 V,电流为-2 A~2 A,且电压和电流的波形具有规律性,波动范围较稳定。采用文献[14]方法和文献[15]方法重构后配网设备主变压器电压、电流波动过程中出现了突变,与重构前信号变化结果有较大差距,且波形变化趋势出现了一定的不同。采用本文方法重构后配网设备主变压器电压波动范围为-48 V~44 V,电流为-2.2 A~1.8 A,与重构前信号变化结果有较小差距,但波形变化趋势一致和范围基本保持不变,产生一定量误差的原因可能是主变压器运行过程中的外部干扰导致,但是整体来看,本文方法重构后的主变压器电压电流误差较小,还原度较高误差较小,对最终的数据存储影响较小。说明采用本文方法重构后多源数据发生的改变较小,可以实现多源BIM数据的良好重构。通过重构前后主变压器电压和电流的对比结果,本文方法可以利用高效的多源BIM数据重构结果,实现数据的高效存储,避免数据存储过程中存在数据丢失等情况。
为了进一步测试本文方法对多源BIM数据的存储性能,根据式(5)归一化处理结果构建的多源BIM数据的完备字典,结合式(6)更新边缘节点上传的字典原子(即电网设备位置序列、故障工单序列等数据),将其上传至云端服务器。对比多源BIM数据上传内容与读取内容,对比结果如表4所示。

表4 多源BIM数据存储性能测试
通过表4仿真结果可以看出,电网设备序号为5时,上传的设备位置序列为528165,故障工单序列为1584416,采用本文方法读取时,读取的设备位置序列为528165,故障工单序列为1584416,与上传数据一致;电网设备序号为28时,上传的设备位置序列为564854,故障工单序列为3815611,采用本文方法读取时,读取的设备位置序列为564854,故障工单序列为3815611,与上传数据一致。因此根据表3可知,采用本文方法存储面向电网设备运维检修的多源BIM数据,上传内容与读取内容均一致,验证了本文方法可以实现多源BIM数据的完整存储。
综上所述,本文方法可以提升BIM模型的读取效率的同时,还可以实现多源BIM数据的完整存储,为电网设备运维检修应用提供了良好的数据基础。通过高效的运维检修管理效率,提升配电网运行可靠性。
3 结束语
本文针对智能电网设备运维检修阶段的多源BIM数据,结合云计算方法与边缘计算方法,提出了一种多源BIM数据存储方法。测试结果表明,本文方法多源BIM数据读取时间低于400 ms;重构后配网设备主变压器电压波动范围为-48 V~44 V,电流为-2.2 A~1.8 A,波形变化趋势一致和范围基本一致;读取设备数据与上传数据一致。该方法应用于智能电网设备运维检修阶段后,利用边缘节点采集多源BIM数据信息,并通过压缩、重构多源BIM数据后上传至云端服务器,在MySQL数据库完成存储。相关工作人员可以从MySQL数据库中调取整合后的运维检修多源数据,为电网设备运维检修提供数据参考。该方法应用后,有利于实现电网设备运维检修阶段的高效管理,为电网设备运维检修阶段的信息共享提供有力的数据支撑。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
中国交通信息化(2022年7期)2022-10-27 06:35:24
中国惯性技术学报(2020年2期)2020-07-24 08:41:10
中国交通信息化(2019年5期)2019-08-30 03:49:14
能源(2018年8期)2018-09-21 07:57:24
能源(2017年11期)2017-12-13 08:12:25
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
现代工业经济和信息化(2016年8期)2016-05-17 05:37:41
