
HSKDLR:同类自知识蒸馏的轻量化唇语识别方法
2023-11-16 00:51马金林刘宇灏马自萍巩元文朱艳彬
计算机与生活 2023年11期
马金林,刘宇灏,马自萍,巩元文,朱艳彬
1.北方民族大学 计算机科学与工程学院,银川 750021
2.图像图形智能信息处理国家民委重点实验室,银川 750021
3.北方民族大学 数学与信息科学学院,银川 750021
唇语识别(lip reading,LR),是一种在没有声音时通过分析唇部图像序列,依靠口型特征向量和特定语音之间的对应关系,判断语言内容的技术[1],是人工智能的新方向。唇语识别涉及模式识别[2-3]、计算机视觉[4]、图像处理和自然语言处理等技术,多应用于信息安全[5-6]、语音识别[7-8]、驾驶辅助[9]等领域。
早期的唇语识别大多基于隐马尔可夫模型(hidden Markov model,HMM)[10]、离散余弦变换(discrete cosine transform,DCT)[11]等传统特征提取方法提取唇部图像的浅层特征(纹理特征、形状特征、颜色特征、拓扑特征),这些方法能够解决一定数据规模下识别精度不高的问题,但需要具备丰富唇读知识的研究者设计特征提取方法。此外,传统方法还存在泛化性不高的缺点[12]。
随着深度学习技术的快速发展,涌现了多种唇语识别方法和唇语识别数据集[13]。Stafylakis等人[14]使用深度残差网络(residual neural network,ResNet)[15]作为前端网络设计唇语识别模型,取得了很好的识别效果。LipNet[16]使用3D-CNN 提取由双向门控循环单元(bidirectional gate recurrent unit,BiGRU)分类的时空特征,在文献[17]的工作中,两个3D-ResNets 以双流的方式(一个用于图像流,另一个用于光流)用更大的网络为代价学习更强大的时空特征。Zhang等人[18]将口腔区域以外的面部区域结合起来解决孤立单词的识别问题,并添加互信息约束[19],以产生更多的鉴别信息。Martinez 等人[20]使用一个多尺度的时间卷积网络(temporal convolutional network,TCN)取代循环神经网络(recurrent neural network,RNN)的后端,在LRW 数据集上获得85.3%的识别准确率。为了提高唇语识别的准确率,深度学习方法不断加深网络,然而随着网络模型的复杂度增加,其参数量和计算量快速增加,导致识别模型对设备性能的要求与日俱增。现有的唇语识别模型无法解决提高模型准确率与降低模型计算量之间的矛盾,限制了唇语识别模型在移动终端和边缘设备上的应用。
知识蒸馏(knowledge distillation,KD)用复杂的教师网络训练简单的学生网络使学生网络获得接近教师网络的性能,并用训练后的学生网络作为最终模型,实现模型轻量化的同时获得一定的网络性能,多被应用于分类[21]、分割[22]、检测[23]等机器学习任务。
为解决上述问题,基于知识蒸馏的思想,本文提出一种同类自知识蒸馏的轻量化唇语识别模型(homogeneous self-knowledge distillation lip reading,HSKDLR),在提高识别准确率的同时,降低模型的参数量和计算量。
本文主要有以下贡献:
(1)提出S-SE注意力模块。在SE模块的基础上添加关注空间特征的注意力模块,同时提取唇部图像的空间特征和通道特征。
(2)提出i-Ghost Bottleneck。通过优化瓶颈结构的组合方式提高模型的识别准确率,降低模型计算量。
(3)提出同类自知识蒸馏的模型训练方法(homogeneous self-knowledge distillation,HSKD)。利用同类别不同样本的软标签实现无需教师网络的自知识蒸馏。
(4)基于i-Ghost Bottleneck 和HSKD,提出一种轻量化唇语识别模型HSKDLR。使用HSKD 训练基于i-Ghost Bottleneck(improved Ghost Bottleneck)设计的唇语识别模型,提高识别准确率,降低训练时间。
1 相关工作
1.1 注意力机制
注意力机制在图像分类和分割等多种计算机视觉任务中发挥了重要作用[24],然而注意力机制大多存在增加模型计算量的问题。常见的注意力机制多在空间或通道上关注图像特征。SENet(squeeze and excitation networks)[25]简单地压缩2D特征图,有效构建通道间的相互依赖关系;CBAM(convolutional block attention module)[26]通过引入空间信息编码,进一步提高模型性能;后续的工作多采用不同的空间注意机制或设计高级注意力模块的方法实现,如GENet(gather and excite network)[27]、GALA(global and local attention)[28]、AA(attention augmented)[29]和TA(triplet attention)[30]等模型。
SE(squeeze and excitation)模块[25]是一种常用的轻量级注意力模块,能够方便地添加到卷积结构中端到端地学习通道间的权重关系。SE 模块由挤压(squeeze)、激励(excitation)两部分组成,SE模块使用两个全连接层实现通道间的信息交流,通过获取通道间的信息权重提高模型的鲁棒性。SE模块的网络结构如图1所示。
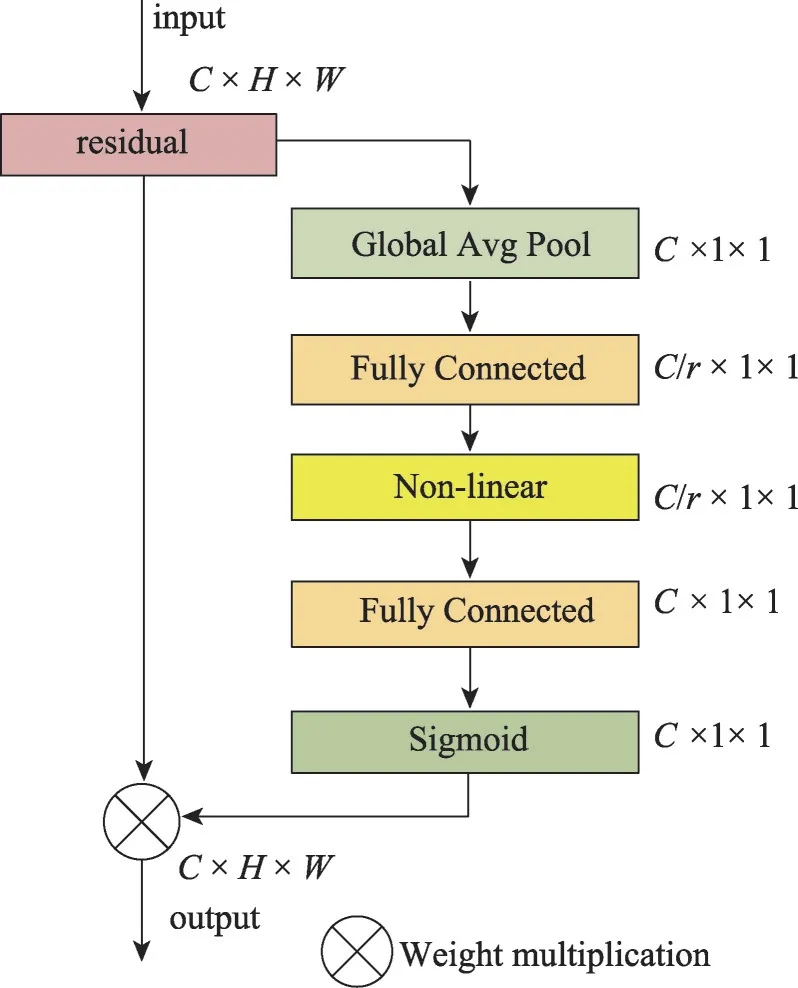
图1 SE模块的网络结构Fig.1 Architecture of SE module
1.2 Ghost模块
Ghost模块[31]使用一系列线性操作生成多个特征图,在不改变输出特征图尺寸的情况下,降低参数量和计算复杂度。图2显示了Ghost模块的原理。
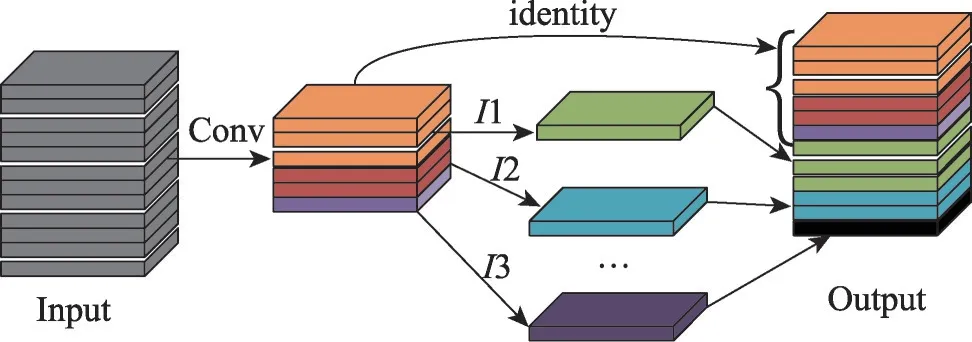
图2 Ghost模块原理Fig.2 Illustration of Ghost module
利用Ghost模块的优势,Han等人[31]提出Ghost瓶颈模块(Ghost bottlenecks)。借鉴ResNet[15]整合卷积层和捷径层的思路,Ghost瓶颈模块使用两个堆叠的Ghost 模块调整特征通道的维度:第一个Ghost 模块增加通道数,第二个Ghost 模块减少通道数。如图3所示,Ghost 模块有两种结构,当stride=2 时,两个Ghost模块之间加入步长为2的深度可分离卷积。在很多分类任务中,Ghost瓶颈模块有效降低了模型的参数量,提高了模型的精度。但是由于Ghost瓶颈模块的SE 注意力模块缺少捕获空间特征的能力,导致唇语识别的准确率不佳。
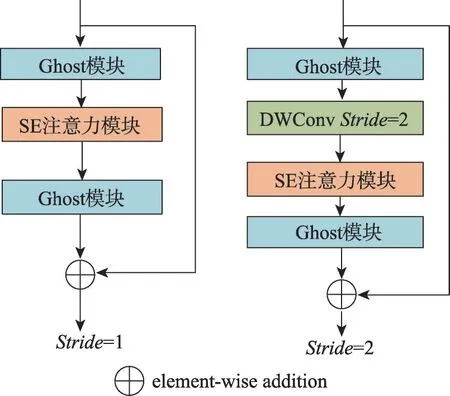
图3 Ghost瓶颈层结构Fig.3 Illustration of Ghost bottleneck
1.3 知识蒸馏
知识蒸馏(knowledge distillation,KD)[21]是Hinton等人提出的一种轻量化神经网络,与模型剪枝、量化等轻量化方法通过改变模型的网络结构来实现轻量化的方式不同,知识蒸馏利用大型网络(即教师网络)训练小型网络(即学生网络),使小型网络获得接近大型网络的性能。知识蒸馏更适用于结构整齐的小型网络,它通常会提高目标模型(学生网络)的性能。知识蒸馏的结构如图4所示。
自知识蒸馏(self-knowledge distillation,Self-KD)的教师网络和学生网络为同样的网络模型,避免了设计结构复杂的教师网络。一些自知识蒸馏的理论分析[32]和实验证明[33],自知识蒸馏在计算机视觉任务中是非常有效的。
2 同类自知识蒸馏的轻量化唇语识别模型
本文基于同类自知识蒸馏(HSKD)方法和Ghost瓶颈模块,提出一种轻量化唇语识别模型HSKDLR,实现端到端的唇语识别,其网络结构如图5所示。
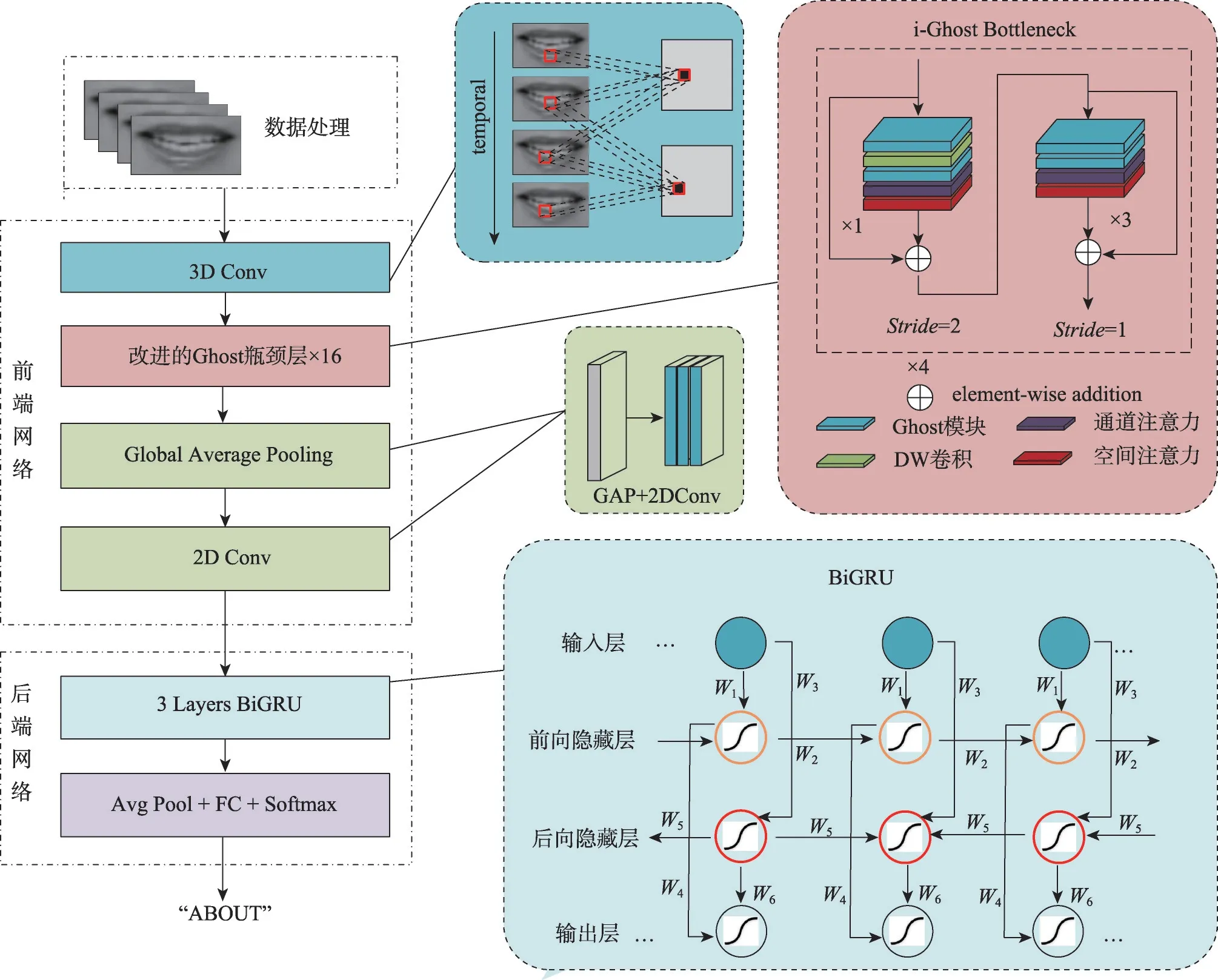
图5 唇语识别模型的网络结构Fig.5 Architecture of lip reading model
2.1 HSKDLR的网络结构
如图5 所示,HSKDLR 由前端网络和后端网络组成。
前端网络包括1个卷积核大小为5×7×7的3D卷积和16 个i-Ghost Bottlenecks。具体地:首先,将3D卷积作用于输入图像序列X,进行时空对齐,并用空间最大池化(max pooling)压缩空间特征;然后,使用16个i-Ghost Bottlenecks提取唇部的通道特征和空间特征,并进行全局平均池化(average pooling);最后,使用2D卷积将输出特征的维度对齐至512。
后端网络由3 个BiGRU 网络和线性层组成,以捕获序列的潜在关系并进行分类。如图5右下所示,BiGRU 包含两个独立的单向GRU(前向隐藏层和后向隐藏层),输入序列以正常顺序传入前向GRU,并以相反顺序传入后向GRU,两个GRU的输出将在每个时间步连接在一起。
HSKDLR模型的特点为:首先,使用S-SE注意力机制提高模型精度;其次,使用i-Ghost Bottlenecks提升模型准确率,并通过优化瓶颈结构的组合方式降低模型参数量;最后,使用同类自知识蒸馏方法提高模型的识别精度。
2.2 S-SE注意力机制
使用SE模块的唇语识别模型虽然可以小幅提升识别精度,但会增加模型计算量。研究表明[34],使用全连接层降维的方式破坏了通道与其权重的直接对应关系,丢失通道间的权重信息。为避免该问题,本文采用一维卷积代替两个全连接层,建模通道关系,如图6 所示。同时,由于SE 模块没有空间注意力机制,无法有效提取空间信息。本文参考CBAM[26]注意力结构,引入空间注意力机制,设计S-SE(spatial SE)注意力模块提取唇部图像的空间特征和通道特征。S-SE模块主要由通道注意力模块和空间注意力模块组成。

图6 S-SE注意力机制Fig.6 Illustration of S-SE
通道注意力模块的结构如图7所示。首先,将输入特征图F(C×H×W) 分别经过全局最大池化(global max pooling,GMP)和全局平均池化(global average pooling,GAP),得到两个C×1×1 的特征图;其次,将这两个特征图分别送入1×5 的一维卷积,将卷积后的输出特征相加;然后,经过sigmoid激活函数生成通道注意力特征;最后,将通道注意力特征和输入特征图F相乘,生成空间注意力模块的输入特征。同时使用GAP 和GMP 的原因是池化操作丢失的信息太多,GAP和GMP的并行连接方式比单一池化丢失的信息更少,效果更好。

图7 通道注意力模块的结构Fig.7 Architecture of channel attention model
空间注意力模块的结构如图8所示,通道注意力模块的输出作为空间注意力模块的输入特征图。首先,基于Channel 的GMP 和GAP 得到两个1×H×W的特征图;其次,将这两个特征图基于Channel 做Concat操作(通道拼接),并利用7×7的卷积操作降为1个Channel,即1×H×W;然后,经过sigmoid生成空间注意力特征;最后,将空间注意力特征和通道注意力特征相乘,得到最终特征。

图8 空间注意力模块的结构Fig.8 Architecture of spatial attention model
2.3 i-Ghost Bottlenecks
在深度神经网络中,丰富甚至是冗余的信息常常保证了对输入数据的全面理解。在许多分类任务中,多数网络模型选择过滤掉这些冗余信息来提高模型的识别精度。研究表明[31],冗余特征图可能是一个深度神经网络成功的一个重要特征。本文基于这一观点,使用Ghost模块利用冗余信息。
针对1.2 节所述问题,本文使用S-SE 模块代替SE 模块,提出一种i-Ghost Bottlenecks 模块,同时提取通道特征和空间特征,提高唇语识别模型的准确率和鲁棒性,i-Ghost Bottlenecks的结构如图9所示。
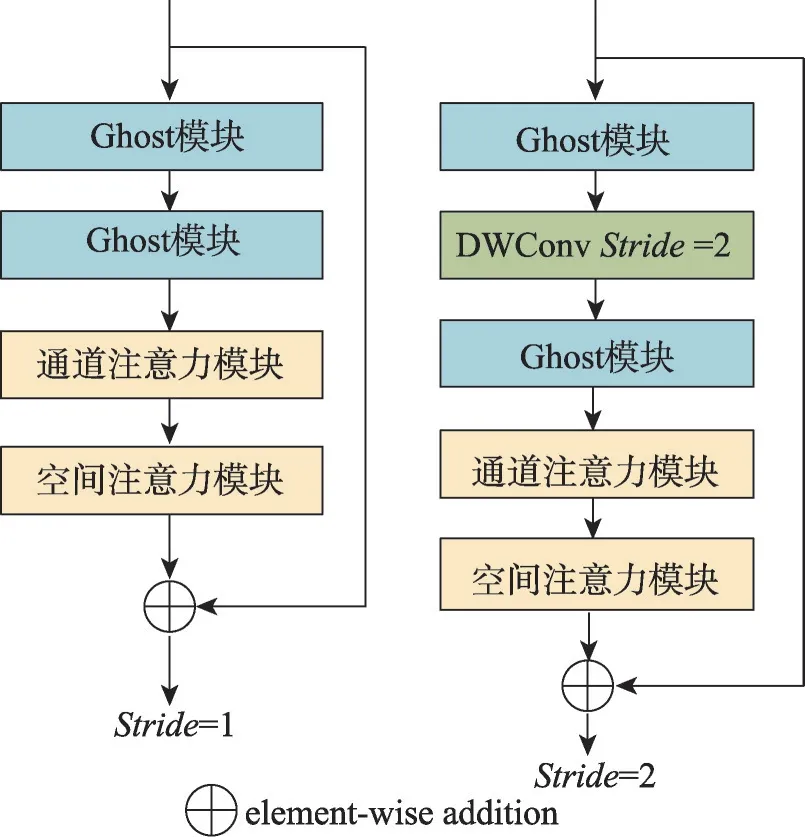
图9 i-Ghost Bottleneck的结构Fig.9 Illustration of i-Ghost Bottleneck
2.4 同类自知识蒸馏
Yuan 等人[35]的研究指出:知识蒸馏可以看作一种特殊的标签平滑正则化(label smoothing regularization,LSR)[36],两者具有相似的功能。随着温度的升高,知识蒸馏中教师软目标的概率分布更接近于标签平滑的均匀分布,但使用知识蒸馏时必须预先训练一个教师模型,这增加了模型的训练成本。利用自知识蒸馏思想,本文设计了同类自知识蒸馏(HSKD),该方法具有标签平滑特性,无需提前训练教师模型。
同类自知识蒸馏匹配并蒸馏唇语数据集中同一词语标签的不同样本之间的预测,对于同一词语标签的不同样本,同类自知识蒸馏会迫使神经网络产生类似的预测,而传统的交叉熵损失则不考虑预测分布的一致性。此外,与现有的大多数知识蒸馏模型相比,该方法无需预先训练教师网络,不增加额外计算量,具有防止模型产生过度自信(over-confident)预测的特点,表1比较了同类自知识蒸馏与其他知识蒸馏。

表1 同类自知识蒸馏与其他知识蒸馏方法的比较Table 1 Comparison of HSKD with other knowledge distillation methods
图10 为同类自知识蒸馏过程示意图,它由软标签生成(第一步)和模型训练(第二步)两个过程组成,使用软标签生成的类别预测结果辅助模型训练。软标签生成和模型训练的输入为同一标签的不同样本,f为同类自知识蒸馏的分项损失函数(如式(2)所示)。

图10 同类自知识蒸馏过程示意图Fig.10 Illustration of homogeneous self-knowledge distillation
给定输入x∈X,y∈Y的真值标签(ground-truth label),其预测分布为:
式中,fi是神经网络的logit(逻辑回归),神经网络的对数由θ参数化,T为蒸馏温度(T>0)。同类自知识蒸馏匹配同类不同样本的预测分布,利用模型自身提取暗知识。
本文使用正则化损失,对同类样本执行一致的预测分布,形式上将具有相同类别标签y的两个不同样本x和x′作为模型的输入图像,损失函数定义如下:
其中,KL表示KL 散度(Kullback-Leibler),不同于经典知识蒸馏方法(KD[21])匹配来自两个网络对单个样本的预测,损失函数ξ匹配同一个网络对不同样本的预测,即实现一种自知识蒸馏。同类自知识蒸馏的损失函数定义如下:
其中,ξCE是标准交叉熵(cross entropy,CE)损失,λ是同类自知识蒸馏损失函数的权重。借鉴原始KD方法[21],本文将温度T的平方乘以损失函数ξ。
为了避免过度自信的预测,同类自知识蒸馏使用其他样本的预测结果作为软标签。经过在唇语识别模型上的反复实验,同类自知识蒸馏不仅减少了识别模型的过度自信预测,而且还增强了与真值相关类的预测值,使唇语识别模型的精度得以提升。
3 实验
3.1 数据集
本实验采用LRW数据集[37],LRW由BBC的新闻和脱口秀节目的视频片段(1.16 s)组成,这些片段包含了超过1 000 个扬声器、头部姿态和照明变化。LRW 数据集拥有500 个单词,每个目标单词有1 000个片段的训练集,50个片段的验证集和评估集,总持续时间173 h。
3.2 数据预处理
本文使用dlib检测并跟踪LRW视频的68个面部关键点[38],首先将唇部裁剪成尺寸为96×96 的图像,其次将其随机裁剪为88×88的尺寸,然后将灰度化后的图像按0.5的概率水平翻转,最后将归一化后的图像输入HSKDLR。
为了减少过拟合(overfitting),本文使用mixup[39]进行数据增强。在此过程中,选择A:(xA,yA)和B:(xB,yB)两个样本通过加权线性插值生成新样本C:(x′,y′),即
其中,xi表示训练样本,yi表示训练样本i∈{A,B}的分类标签,β是服从参数均为α的Beta 分布的随机抽样值Beta(α,α)。表2为α对模型性能的影响,根据实验结果,本文将α的值设定为0.2。
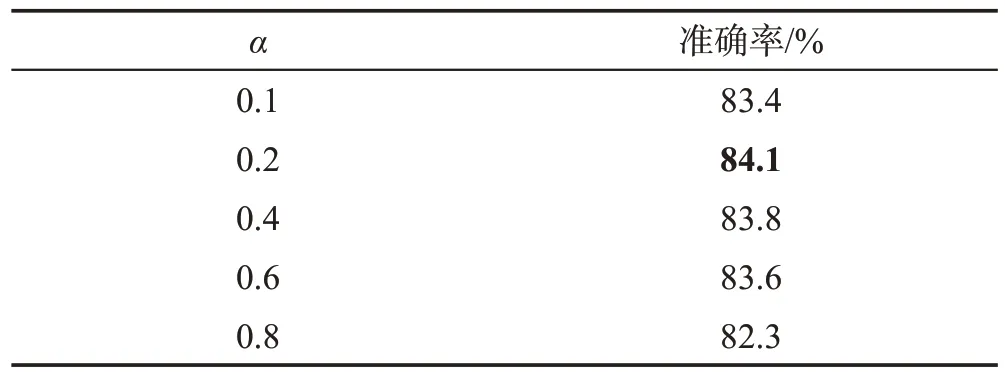
表2 α 对模型性能的影响Table 2 Influence of α on model performance
3.3 实验环境
模型的搭建、训练和测试均基于Pytorch,使用Tesla V100显卡。唇语识别模型总训练批次为96,采用余弦学习率,其计算公式为:
式中,t为批次数,T为总批次。初始学习率η的值为0.000 3,batchsize 为32,权重衰减率为0.000 1,使用Adam优化策略。
4 实验结果和分析
4.1 瓶颈模块的堆叠方式与数量
i-Ghost Bottlenecks 的堆叠方式和数量直接影响模型的识别性能,为了探究这一问题,实验考察瓶颈模块的堆叠方式和数量对识别性能的影响,实验结果如表3所示。

表3 瓶颈模块的堆叠方式和数量对识别性能的影响Table 3 Influence of stacking mode and the number of bottleneck modules on recognition performance
如表3 所示,堆叠方式用(x,y)×z的形式表示,x表示图9中stride=2 时的瓶颈结构的数量,y表示图9 中stride=1 时的瓶颈结构的数量,z表示以该结构进行堆叠的个数。由实验结果可以看出:(1,3)的堆叠方式要明显优于(1,1)的堆叠方式;骨干网络的总层数不易过少,虽然(1,3)×3与(1,1)×6的总层数少于(1,3)×4,计算量和参数量降低了,但也大幅降低了模型的识别精度;(1,3)×5与(1,3)×4达到的准确率几乎一致,本文最终采用堆叠次数更少的(1,3)×4方式,在减少骨干网络的复杂度的同时并未降低模型的识别准确率。
4.2 不同前端的性能对比
在将网络的第一个卷积保持为3D 卷积的情况下,本实验考察不同前端网络下的模型识别性能,这些前端网络分别为MobileNet V2[40]、ShuffleNet V2[41]、Ghost Bottleneck、SE-ResNet18 和i-Ghost Bottleneck,模型的后端网络统一使用BGRU(bidirectional gated recurrent unit)。模型构成和实验结果如表4所示。
由表4 可得,i-Ghost Bottleneck 构成的模型具有比MobileNet V2 和ShuffleNet V2 构成的模型更高的性能。与SE-ResNet18 构成的模型相比,i-Ghost Bottleneck的识别精度下降了0.8个百分点,但参数量降低了13,浮点数计算量降低了34。与Ghost 瓶颈模块构成的模型相比,i-Ghost Bottleneck构成的模型在降低浮点数计算量和参数量的情况下,提升了识别准确率。图11显示了不同的识别模型的识别准确率曲线,由图可见,本文方法的收敛速度和识别准确率明显高于其他方法。

图11 不同前端构成模型的识别准确率曲线Fig.11 Recognition accuracy curves of different front-end models
综合以上结果,本文提出的i-Ghost Bottleneck作为骨干网络构成的唇语识别模型取得了较好的识别性能。
4.3 不同后端的性能对比
本实验所有模型的前端网络为3D-Conv+i-Ghost Bottleneck,后端网络分别使用BLSTM(bidirectional long short-term memory)、TCN(temporal convolutional network)、MS-TCN(multi-stage temporal convolutional network)和BGRU(bidirectional gated recurrent unit),实验结果如表5所示。由表5可以看出,后端网络使用BLSTM和TCN构成模型的识别效果并不理想;后端网络使用MS-TCN时的参数量与浮点数计算量最低,但是模型精度下降了2.9 个百分点。综合准确率、参数量和浮点数计算量,本文采用BGRU作为后端网络。

表5 不同后端构成的唇语识别模型的性能对比Table 5 Performance comparison of lip reading models composed of different backends
4.4 不同知识蒸馏方法下的模型准确率对比
为了弥补轻量化唇语识别网络的精度损失,本文采用自知识蒸馏的方法提高模型的识别精度,为考察不同知识蒸馏方法的性能表现,本实验对比普通蒸馏、自知识蒸馏、同类自知识蒸馏方法的识别性能(基于2.4 节所述,此处也对比标签平滑正则化方法)。普通知识蒸馏方法的教师网络为3D-Conv+SEResNet18+BGRU,学生网络为3D-Conv+i-Ghost Bottleneck;自知识蒸馏方法的教师网络与学生网络均为3D-Conv+i-Ghost Bottleneck;同类自知识蒸馏方法的模型(无教师网络)为3D-Conv+i-Ghost Bottleneck;标签平滑是一种代替蒸馏的正则化方法。实验结果如表6所示。
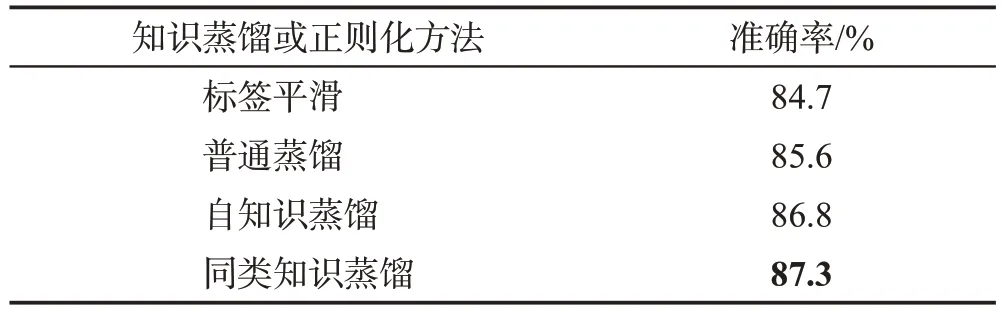
表6 不同知识蒸馏方法的模型性能Table 6 Performance of different knowledge distillation methods
由表6可见,各种知识蒸馏方法均比标签平滑方法得到的识别效果好,推测原因可能是标签平滑在训练时,使用的“人造”软标签通过人为设定固定参数实现,这使模型的泛化能力有限。普通蒸馏的教师网络的精度要高于自知识蒸馏的教师网络(如表4所示),但表6 中的自知识蒸馏方法的唇语识别效果更好,这说明使用结构复杂的高精度教师网络训练的模型不一定取得更好的识别效果。同类自知识蒸馏可以获得高于标签平滑和其他蒸馏方法的识别准确率,图12 显示了不同知识蒸馏方法的识别准确率曲线。由图12和表6可见,同类自知识蒸馏方法的识别准确率明显高于其他知识蒸馏方法和正则化方法。

图12 不同知识蒸馏方法的识别准确率曲线Fig.12 Recognition accuracy curves of different knowledge distillation methods
如图12 所示,同样采用软标签的自知识蒸馏方法明显优于采用“人造”软标签的标签平滑方法。可见,同类自知识蒸馏的软标签更有效。
4.5 同类自知识蒸馏应用于不同识别模型的性能对比
本实验考察同类自知识蒸馏方法在唇语识别任务中的可行性与在唇语识别模型上的通用性,对比四种经典模型[14,18,20,42]应用同类自知识蒸馏方法后的识别效果。表7 为同类自知识蒸馏应用于其他唇语识别模型的性能对比表,图13 显示了四个模型分别使用自知识蒸馏、同类自知识蒸馏后的识别准确率曲线。

表7 同类自知识蒸馏应用于其他模型的性能对比Table 7 Performance comparison of HSKD applied to other models
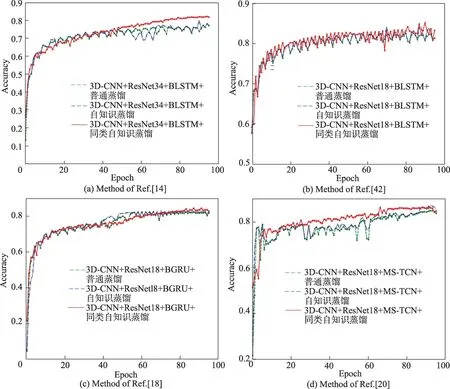
图13 同类自知识蒸馏应用于不同模型的准确率曲线Fig.13 Accuracy curves of different models which are applied with HSKD
由表7可以看出,应用同类自知识蒸馏方法的模型识别率普遍得到提高,这证明同类自知识蒸馏可广泛应用于现有唇语识别模型,并可提高其识别率。
实验也表明:应用了同类自知识蒸馏方法后的识别模型的准确率不与原识别模型的准确率成比例地提高,如表7 中,3D-Conv+ResNet18+BLSTM 和3D-Conv+ResNet18+BGRU的准确率分别为82.3%和82.7%,但应用同类自知识蒸馏方法后,它们的准确率为85.2%和84.8%,应用前后的识别准确率变化较大。
值得注意的是,应用同类自知识蒸馏方法的Martinez[20]模型所提升的精度与自知识蒸馏相当,但从图13(d)可以看出,使用了同类自知识蒸馏的模型在大多数时候的准确率均高于使用自知识蒸馏的模型。
由图13 可知,同类自知识蒸馏方法在不同模型上都能取得较高准确率;相对于普通蒸馏和自知识蒸馏方法,同类自知识蒸馏方法的收敛速度较快,并且较早出现准确率下降趋势。
4.6 与SOTA模型的性能对比
本实验比较同类自知识蒸馏模型HSKDLR和其他主流唇语识别模型的性能,实验结果如表8 所示。由表8可见,并不是结构复杂的唇语识别模型能获得更好的识别性能,如Stafylakis[42]和Petridis[43]在后端均为BLSTM的情况下,前端网络为3D-Conv+ResNet18的性能优于3D-Conv+ResNet34。同时,对于Zhang[18]和Zhao[19],在前端网络相同的情况下,后端网络为BGRU的模型性能要优于后端为BLSTM的模型。
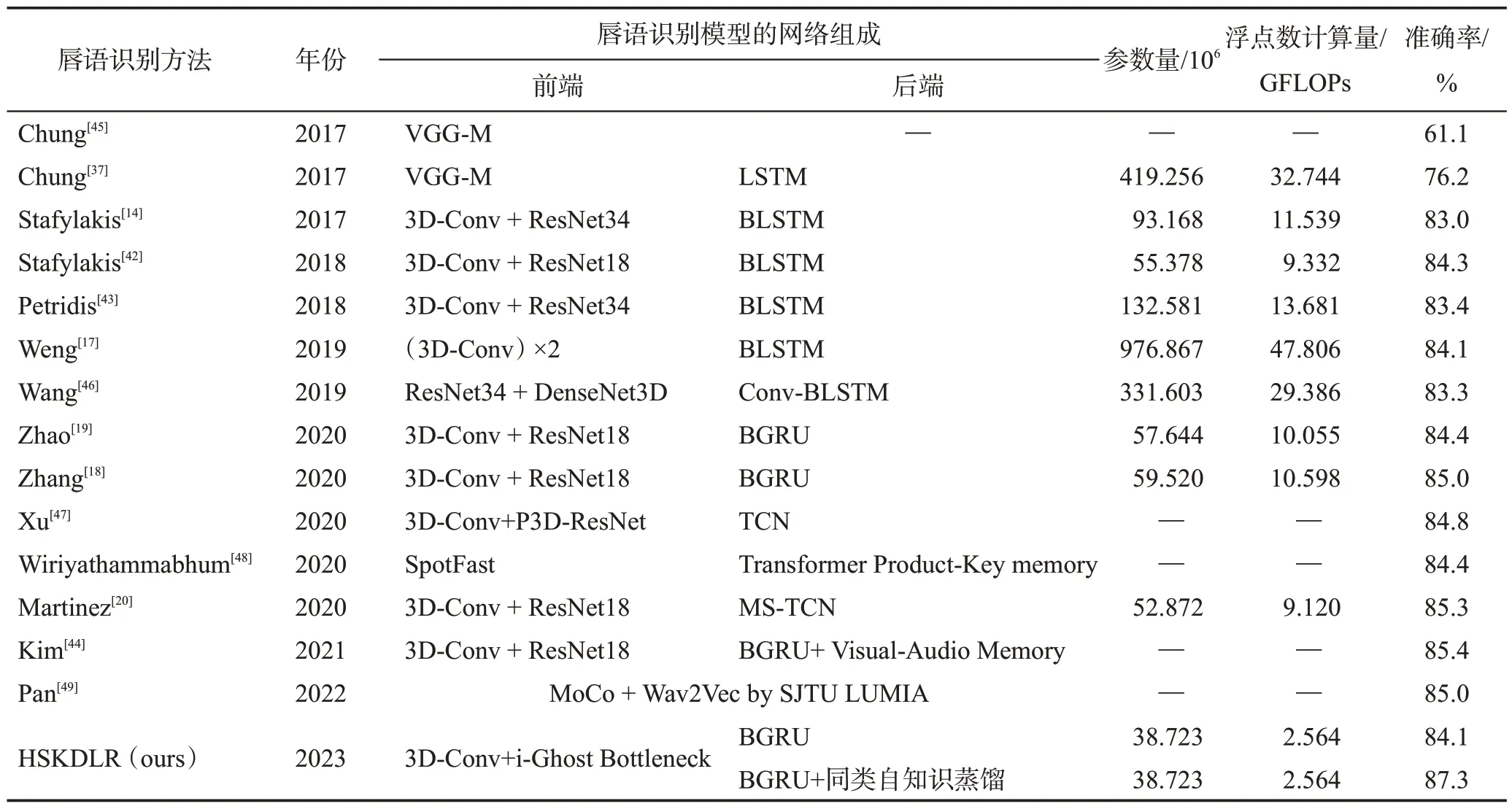
表8 HSKDLR和其他唇语识别方法的性能对比Table 8 Performance comparison between HSKDLR and other lip reading methods
HSKDLR的识别精度达到87.3%,超过所有非轻量结构的识别模型,并且模型的参数量和浮点数计算量远小于对比方法。HSKDLR的识别准确率比最高的Kim[44]方法还高1.9 个百分点;准确率比次高的Martinez[20]方法高2 个百分点,参数量和浮点数运算量却仅为它的73%和28%。
4.7 识别结果可视化
本实验可视化地展示HSKDLR 识别模型与Stafylakis[42]、Zhang[18]、Martinez[20]模型的识别结果。针对LRW 测试集中识别难度较高的5 个单词(right,spend,police,attack,fight)实验,对比识别结果,如图14所示。由表7和图14可见,Zhang模型的识别精度高于Stafylakis,但对识别难度较高的单词的识别错误较多。Stafylakis 模型出现了比较大的识别错误,它将“police”识别为唇形差异比较大的“place”,而其他方法识别为唇形差异不大的“policy”,这也表明Stafylakis模型可能缺少一定的稳定性。就这些较高难度单词识别的正确率来说,Martinez模型和HSKDLR均有较好的识别效果,但从两个模型的识别错误来看,它们所提取和关注的唇部特征有一定的区别和侧重点。值得注意的是,所有模型在识别“fight”单词时均将其错误地识别为了“fighting”,推测其原因可能是这两个单词间的细微特征未被准确捕获,或者是数据集的制作不够严谨。

图14 对5个识别难度较高单词的识别结果对比Fig.14 Comparison of recognition results of 5 words with high recognition difficulty
5 结论
本文针对唇语识别模型的识别率较低和计算量较大的问题,基于Ghost瓶颈结构和同类自知识蒸馏方法提出一种轻量化唇语识别模型和训练方法。在SE 中加入空间注意力模块,关注空间特征;用i-Ghost Bottlenecks作为骨干网络设计新的唇语识别模型HSKDLR;使用同类自知识蒸馏方法训练HSKDLR。由于同类自知识蒸馏方法不需要教师网络,省去了教师网络的训练过程,节约了训练成本。在LRW 数据集上的实验结果显示,本文模型达到87.3%的识别准确率,浮点数运算量低至2.564 GFLOPs,参数量低至3.872 3×107。实验结果表明,HSKDLR 的准确率可以媲美甚至超过现有的非轻量化模型,并且降低了浮点数计算量和参数,实现了模型轻量化的同时提高识别精度的目的。
猜你喜欢
幼儿画刊(2023年7期)2023-07-17
小雪花·成长指南(2022年1期)2022-04-09
童话世界(2019年32期)2019-11-26
作文通讯·高中版(2019年11期)2019-09-10
文学港(2019年5期)2019-05-24
下一代英才(酷炫少年)(2018年12期)2018-12-29
中国信息化周报(2018年3期)2018-01-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
儿童故事画报(2015年7期)2016-01-27
