
基于BP-AdaBoost算法的复杂产品装配制造成熟度等级评估方法
2023-11-15 09:04徐美姣薛善良周国庆卢红根
中国机械工程 2023年20期
徐美姣 薛善良 张 惠 周国庆 卢红根
1.南京航空航天大学计算机科学与技术学院,南京,2111062.南京晨光集团有限责任公司,南京,210006
0 引言
航空航天工业领域,飞机、火箭、卫星等复杂产品的制造风险管理极其重要,如果复杂产品制造风险不能得到有效管理和监控,可能会出现制造成本增加、产品性能不佳、质量问题增多、安全性下降和产品交货滞后等现象。为了解决这类问题,美国国防部于2001年首先提出了制造成熟度(manufacturing readiness level, MRL)的概念,并随之将制造成熟度评价(manufacturing readiness assessment, MRA)应用于管控国防项目,为复杂产品制造风险管理提供了有效技术手段。在制造能力建设方面,我国航空航天企业已经有一定的基础,一些企业已具备较为先进的制造技术、制造工艺及制造设备,但是,在制造风险管理方面,仍然存在一些不足,往往不能在规定时间和目标成本内制造出质量稳定的产品。制造成熟度评价能够帮助企业及时发现产品生产过程中的问题,进而加强企业对国防工程的风险管控,有助于国防事业顺利发展。借鉴美国MRA在国防领域的应用经验,我国国防企业率先推广应用制造成熟度评价技术,并发布了GJB 8345—2015《装备制造成熟度等级划分及定义》和GJB 8346—2015《装备制造成熟度评价程序》等标准。但是,我国航空、航天、国防领域的复杂产品制造有自身特点,不能直接套用美国MRA的一整套方案。为此,我国政府和企业资助了针对航空航天领域产品制造特点的MRA应用技术研究。
国内外对成熟度的评价主要有德尔菲法、层次分析法等专家评价法。德尔菲法经组织专家开会得到评价结果,该方法的主观性太强,且花费时间过长。层次分析法在多层次的指标系统评价中得到了较多应用,通过专家评判指标权重和专家打分进行综合评估,存在主观性较强的问题,且当评价指标数量过多时,需要构建复杂的判断矩阵,求解矩阵结果时存在迭代次数较多、计算量大等问题。文献[1]应用模糊层次分析法对制造企业数字化成熟度进行评价,确定了制造企业数字化的风险因素。但由于制造企业数字化风险因素多且关系复杂,大量的评价数据仅依赖专家打分获得,存在随意性和主观性,且需要获得大量多维、科学、准确的原始数据。文献[2]构建了智能制造成熟度评价模型,为各区域制造企业的智能化转型提供了一种方法,该研究在构建模型期间运用层次分析法来求解评估指标权重,仍受专家主观性影响,且计算过程较复杂。
我国现有的研究工作大多是制造成熟度的相关理论以及在某些领域的初步应用方案,例如,文献[3]针对制造业的行业特点和相关理论构建智能制造能力成熟度评价指标体系,给出了智能制造能力成熟度评价数据预处理方法;文献[4]构建了航天器结构产品MRL等级与评价指标模型,利用模糊综合评判法评估航天器相关产品的MRL;文献[5]从制造相关的多个维度分析智能制造的内容,并建立了智能制造能力成熟度模型。这些评价方法都依靠专家确定评价指标权重及指标评分,主观性较强,且耗时长。据统计,本文所研究的某复杂产品的一个分系统的装配制造成熟度评价大约需要耗费半年时间之久,每次评价都完全依赖于现场所请专家经验进行权重评判和指标评分,而以往专家成功评价的实例数据难以利用,这些评价实例所蕴含的知识不能很好地传承。
反向传播(back-propagation, BP)神经网络[6]是人工智能中应用较为广泛的多指标变权动态求解方法,能够通过模仿人脑神经网络的学习方法处理多个指标的变权动态求解问题,且具有误差反向传播学习能力。通过层间权重的不断调整,使网络输出更接近理想输出,具有计算量小、简单易行、并行性强等优点,在降低产品制造成熟度评价主观性影响的同时提高客观参数量化评估的有效性和参考性,但存在着易陷入局部极小值、收敛速度慢、泛化能力弱等缺点。
AdaBoost算法[7]可以通过反复调整权值优化弱学习器以得到有效的预测。AdaBoost算法的核心思想是在初次训练结果的基础上,改变样本的分配权重并再次进行训练,得到多个弱学习器及每个弱学习器的权重,最后根据权重分布将多个弱学习器组合形成强学习器。AdaBoost具有精度高、训练误差以指数速率下降的优点。
本文针对某复杂产品装配制造风险管理需求,研究一种基于BP-AdaBoost的装配制造成熟度等级评估方法,充分利用以往专家评价实例数据,应用人工神经网络评估制造成熟度等级达成度,以克服现有专家评价存在的主观性和效率低的问题。
1 制造成熟度评价指标体系及量化
1.1 装配制造成熟度评价指标体系的构建
制造风险因素是复杂产品制造成熟度评价的重要依据。根据GJB8345—2015、GJB8346—2015等相关标准,制造风险主要包括工业基础与制造技术体系、设计、技术成熟度、工艺、物料、设备设施、制造人员、制造管理、质量管理和成本管理十个方面的风险因素,这些风险因素宏观上覆盖了复杂产品各组成部分和装配制造各阶段可能发生的所有问题。但是,复杂产品的装配制造工艺涉及的装配件和装配资源的种类繁多、数量庞大,所操作的装配空间通常极其狭窄紧凑,难以应用机器人等自动化装配工具,而装配质量要求却非常高。同时,该复杂产品的型号多、品种多、批次多,研制批产并举,制造模式多样,制造管理复杂,且存在着技术封锁等特殊制造风险,目前尚无一套适用的装配制造成熟度评级指标体系。
本文结合该复杂产品装配制造实际需求,针对单件、小批量生产所重点关注的是否装配出符合要求的部件、分系统和整机产品,综合考虑人、机、料、法、环、测等要素在某复杂产品装配制造过程中对产品质量、生产效率和成本的影响,考虑技术封锁潜在影响,分析各要素存在的装配制造风险,对制造十大风险要素逐一进行分解,从相互关联、相互耦合的诸多制造风险因素中出识别关键制造元素(crucial manufacturing element, CME),形成23个装配制造风险子要素。以这些风险子要素为评价对象,构建某复杂产品装配制造成熟度评价指标体系(图1)。其中,工艺建模与仿真(覆盖率)、物料可取性(满足度)、制造人员数量、过程质量管理(覆盖率)、厂家质量管理(等级)、成本分析(费用)等评级指标尤为重要。

图1 复杂产品装配制造成熟度评价指标体系
1.2 装配制造成熟度评价指标量化
图1所示的评价指标体系包括了23个二级指标,分别对应复杂产品装配制造风险各子要素。表1列出了各指标量及类型,其中,定量指标是采用数学方法收集和处理数据资料而作出定量结果的价值判断;定性指标是根据专家的知识、经验直接作出定性结论的价值判断。例如,制造人员数量是指具有特定装配制造能力的人员总数,该指标是具有望大特性的定量指标;成本分析表示装配制造费用,即装配过程中各种资源利用情况的货币表示,是衡量装配技术和管理水平的重要指标,是具有望小特性的定量指标。对定性指标的评价结论无法用数值表达,而定量指标的评价结果可能有不同量纲。本文依据各项指标的特征、值域范围以及对成熟度的影响等因素,对制造成熟度各指标进行了量化处理,分别应用模糊评价法和模糊数学隶属函数实现定性指标和定量指标的量化[8-9]。
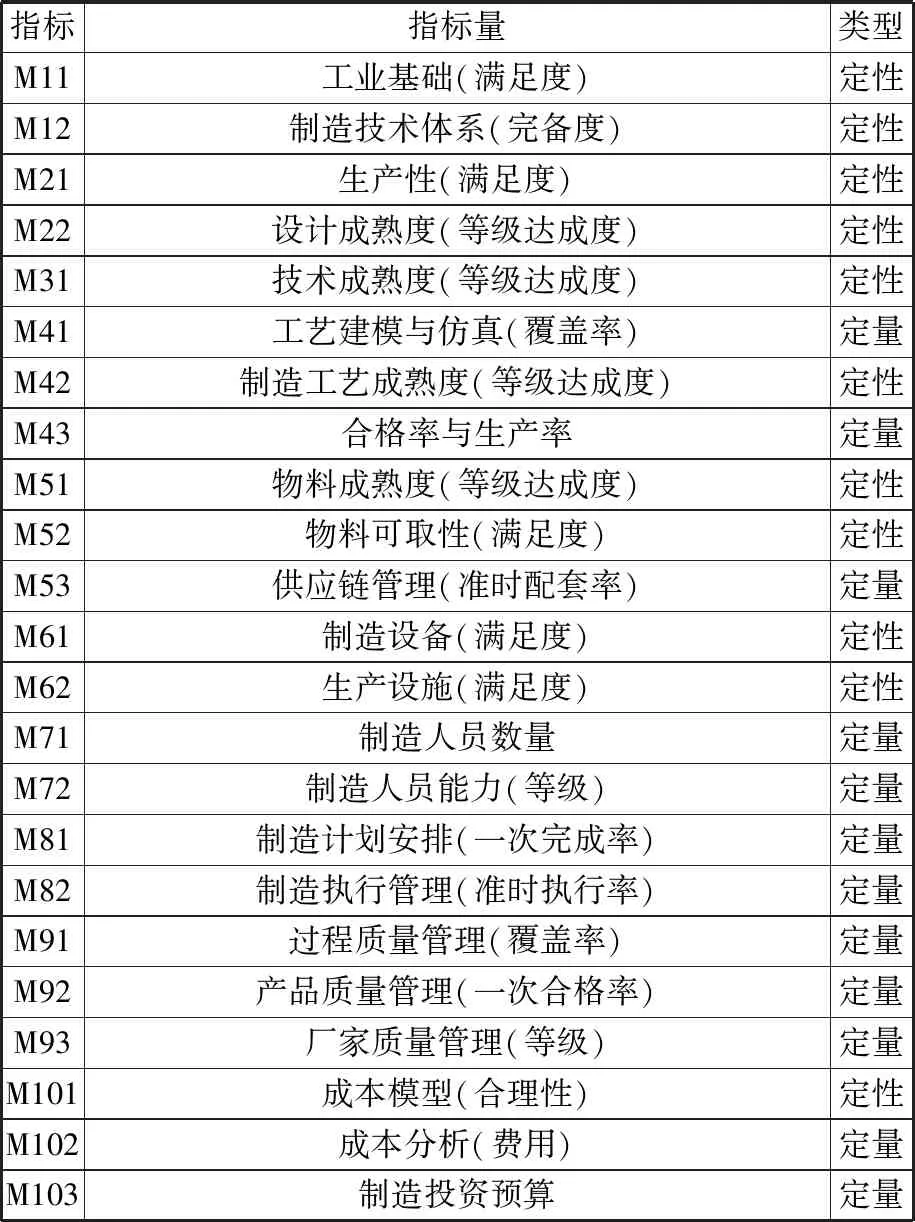
表1 装配制造成熟度评价指标量及类型
1.2.1定性指标量化方法
定性指标只通过语句表达要求满足程度,而不含任何数据。例如,设计生产性、物料可取性等评价指标以及成熟度等级达成性。本文参考文献[8]应用模糊评价法将定性指标的评价结果分为四个等级:完全不满足、基本满足、达到预期要求、达到完美要求。采用定量分级处理方法,以0、0.5、0.8、1分别表示定性指标评价集内各元素[10],构成表2所示的定性指标评价集。

表2 定性指标评价集
1.2.2定量指标量化方法
定量指标是具有数据要求的指标,指标的绝对量是尺寸、费用、件数、时间、比率等具有不同量纲的真实数据,需要依据指标的特征、值域范围以及对成熟度的影响等因素,根据指标相关的真实数据与设定数据间的关系进行归一化等处理,以适用于成熟度评估模型神经元激活函数输入。定量指标包括正指标、负指标和适度指标三种。量化定量指标,首先需要判断指标所属种类,然后根据指标的真实情况完成量化。本文采用模糊数学中的隶属函数,以指标a的边界值amin/amax和最适值amod为标准进行量纲一处理,将指标的初始值换算为量纲一的评价值,各类指标的量化方法如下。
(1)正指标量化。正指标是在一定范围内指标越大评价值越高的一类指标,具有望大特性,如准时配套率、合格率、生产率等。采用隶属函数进行正指标模糊量化:
(1)
式中,V(a)为该指标经过量纲一化之后得到的评价值;a为制造成熟度定量指标的原始数值;amax、amin、amod分别为指标在制造成熟度评价实施时采用的最大值、最小值和最适值。
(2)负指标量化。负指标是在一定范围内指标越小评价值越高的一类指标,具有望小特性,如装配成本、制造投资等。采用隶属函数进行负指标模糊量化:
(2)
(3)适度指标量化。适度指标是在一定范围内指标越接近最适目标值,其评价值越高的一类指标,具有望目特性,如装配件设计外廓尺寸、过渡配合装配间隙等。采用隶属函数进行适度指标模糊量化:
(3)
2 基于BP-AdaBoost的成熟度等级评估模型
2.1 基于BP的成熟度等级评估模型
神经网络由输入层、隐藏层和输出层组成[11],每层又含多个神经元,神经元个数在输入层和输出层与样本数据对应,而隐含层则要视实际情况而定。本文研究的装配制造成熟度等级评估神经网络的输入层由某复杂产品装配制造成熟度等级评价指标体系内23个二级指标评价值构成,输出层为成熟度等级值达成度,输入、输出神经元的个数分别为23个与1个。
BP神经网络隐含层层数和各隐含层节点数对BP神经网络模型的构建影响非常大。多隐层的网络结构对数据有更好的表示能力,但是隐含层层数过大可能会带来过拟合问题,同时也会增加模型的训练时间,造成无法收敛。与此同时,各隐含层节点数过少,可能会导致模型的学习能力下降,训练结果受影响;节点数过多,可能导致模型的训练时间增加,出现过拟合现象。
隐含层最大层数与输入层和输出层神经元个数以及样本个数有关:
(4)
式中,M为隐含层数;S、P分别为输入层和输出层神经元个数;R为样本个数。
实际应用中,隐含层多数为1~3层,根据样本数据的数量级及具体性能要求而定。
现阶段使用最多的隐含层节点数求解公式为
(5)
式中,α为调节常数,取值范围2~10。
在确定各隐含层节点数时,各隐含层节点个数必须小于R-1。若某隐含层节点个数大于等于训练样本个数R,可能会导致模型的训练时间增加,还可能使得建立的训练模型不能预测其他样本数据,失去模型的实用性。另外,样本数必须多于模型权数的2~10倍。
本文构建多层制造成熟度评价模型,对于多层网络,sigmoid函数的分类相较于线性函数容错性较好,划分更加精确、合理。装配制造成熟度评价指标的评分结果量化后控制在[0,1]内,制造成熟度等级达成度评估结果也在[0,1]内。sigmoid函数可处理且逼近非线性关系,因此制造成熟度等级评估模型选取sigmoid函数作为激活函数[12],如下所示:
(6)
本文比较分析了traingdm、traingd、trainrp和trainlm训练函数,其中trainrp和trainlm效果较好。进一步选取trainrp和trainlm训练函数分别构建某复杂产品装配制造成熟度等级评估模型,选用相同隐含层个数情况下,分别进行仿真实验,针对平均绝对百分比误差MAPE、平均绝对误差MAE、均方根误差RMSE和决定系数R2进行比较分析。实验结果表明trainlm作为训练函数的评估结果更贴近实际值,因此本文选用训练函数trainlm。
接着,设置训练参数,设置学习效率、动量因子、最大训练次数、目标误差分别为0.01、0.9、1000和0.001。设置双层隐含层的激活函数为tansig和logsig,正切S型函数tansig形式为
(7)
对数S型函数logsig形式为
f(x)=(1+e-βx)-1
(8)
式中,β为调节常数。
输出层的激活函数为purelin,线性函数purelin形式为
f(x)=kx+c
(9)
式中,k为线性函数的斜率;c为线性函数的截距。
2.2 基于AdaBoost的成熟度等级评估模型优化
BP神经网络评估制造成熟度等级误差较低,但存在易陷入局部极小值、收敛速度慢、泛化能力弱等缺点。为了获得预测效果更好评价模型,本文分别使用粒子群算法(PSO)和自适应增强(AdaBoost)算法对BP神经网络模型进行对比优化,结果表明,使用AdaBoost算法对BP神经网络模型进行优化能进一步提高收敛速度以及评估精度。
从国内外研究现状可知,基于AdaBoost算法优化后的BP神经网络建立的预测或评估模型预测精度高、误差小且稳定性高,因此,本文采用基于BP-AdaBoost的复杂产品装配制造成熟度等级评估方法。评估流程见图2,具体步骤如下。
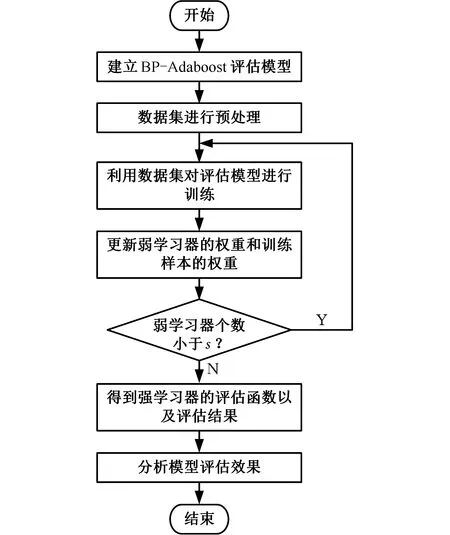
图2 基于BP-AdaBoost的制造成熟度评价流程
(1)初始化训练样本权重:
(10)
式中,Wi为训练样本的初始权重;m为训练样本个数。
(2)设置以BP神经网络为弱学习器的个数T,以及BP神经网络的激活函数、隐含层、目标误差、学习效率等;
(3)对弱学习器开始训练,得到训练样本的评估误差,比较评估误差与训练误差,调整训练样本的权值Di;
(4)训练第s个弱学习器,根据第s个弱学习器的评估误差计算该学习器的权重;
(5)根据第s个弱学习器的评估结果g(s),调整第s+1轮训练样本的权重;
(6)经过T轮循环,得到T组不同权重的函数f(gs,Ws),根据权重分布得到强学习器的预测函数F(x)。
3 评估模型的训练与对比分析
3.1 训练数据及训练方法
我国制造成熟度评价技术应用处于起步阶段,主要应用领域局限于航空航天工业和国防工业。现有的成熟度评价实例多为专家主观定性评价。为此,本文针对该复杂产品装配制造成熟度评价指标特点,结合已有的装配制造成熟度评价实例,参照装配制造成熟度评价指标体系和评价指标量化方法,对来自于评价专家打分的定性指标M11、M12、M21、M22、M31、M42、M51、M52和M101进行定量分级处理,对来自装配制造数据的定量指标M41、M43、M53、M71、M72、M81、M82、M91、M92、M93、M102和M103进行量化处理,制作该复杂产品的分系统装配制造成熟度评价数据集进行训练。该数据集有8200条数据,每条数据有23项指标,其中训练、校验和测试的样本数量比例分别为70%、15%和15%。利用数据集对构建好的T个BP神经网络弱学习器进行训练,设第s个弱学习器训练后的评估结果为gs(s),实际结果为Y,计算训练集上的最大误差Es:
Es=max(|gs(s)-Y|)
(11)
计算第i个样本在第s个训练集上的相对误差ei:
ei=|gs(xi)-Yi|/Es
(12)
式中,xi为第i个样本输入值;Yi为第i个样本实际结果。
计算每个训练集的回归误差率es:
es=es+Ds(i)ei
(13)
式中,Ds(i)为第i个训练样本的权值。
根据第s个弱学习器的评估误差es计算该弱学习器的权重:
(14)
由第s个弱学习器的评估结果gs(s),调整s+1轮训练样本的权重:
(15)
i=1,2,…,m
式中,Bs为归一化因子。
最后,利用平均绝对百分比误差(MAPE)、平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2)比较选择最优等级评估模型,用于确定制造成熟度等级。
3.2 对比测试结果与分析
为比较分析本文研究的基于BP-AdaBoost的制造成熟度等级评估方法的有效性和效率,本文对BP神经网络算法、粒子群算法改进后的BP神经网络及BP-AdaBoost算法进行对比实验。实验中,采用相同的数据集以及参数,结果如图3~图5所示,实验误差如表3所示。
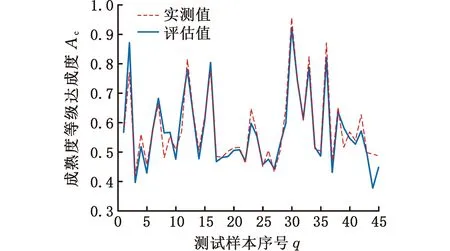
图3 BP的实验结果
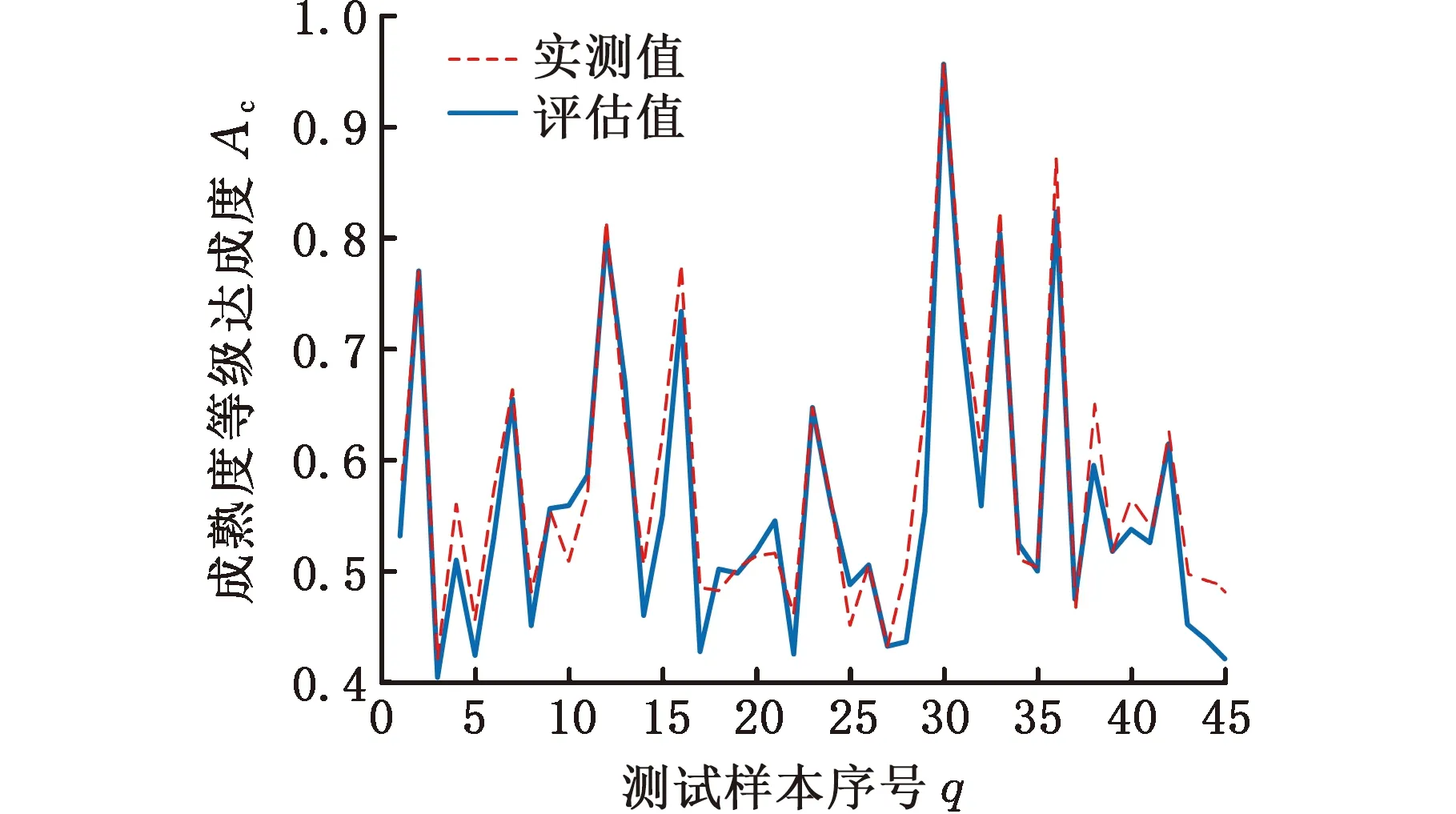
图4 PSO-BP的实验结果

图5 BP-AdaBoost的实验结果
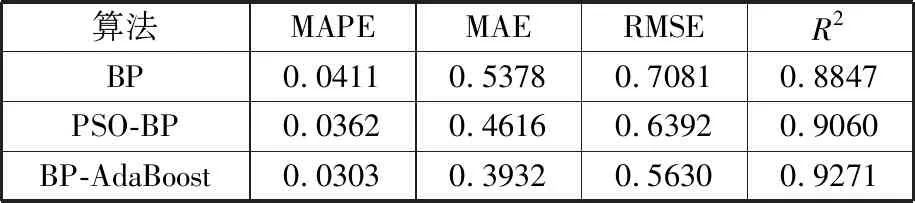
表3 BP、PSO-BP和BP-AdaBoost误差分析
对比可知,BP算法、PSO-BP算法、BP-AdaBoost算法的MAPE分别为4.11%、3.62%、3.03%。可以看出,BP-AdaBoost算法的仿真结果更贴近真实值,比BP算法和PSO-BP算法的评估效果更好。
综上,基于BP-AdaBoost的制造成熟度等级评估方法效果最优,因此将其应用于产品装配制造成熟度等级评价。
4 结论
本文分析了某复杂产品装配制造风险因素,建立了装配制造成熟等级评价指标体系,并给出了成熟度等级达成度量化方法。对比发现,采用BP-AdaBoost算法构建的装配制造成熟度评价模型实现了某复杂产品装配制造成熟度等级评估,提高了制造成熟度评价的精确度和效率,缩短了评价周期。
随着该复杂产品及同类型产品装配制造成熟评价技术的推广应用,将进一步应用所积累的评价实例数据对本文所研究的方法进行验证和优化,并在同类型产品装配制造风险管理中推广。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
航天工业管理(2020年9期)2020-12-28
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
航天工业管理(2020年1期)2020-04-20
电子制作(2019年19期)2019-11-23
种子(2018年9期)2018-10-15
学苑创造·B版(2018年12期)2018-03-04
重型机械(2016年1期)2016-03-01
