
基于多策略改进的麻雀搜索算法
2023-11-14 13:16贺智明黄志成
计算机与现代化 2023年10期
卢 磊,贺智明,黄志成
(江西理工大学信息工程学院,江西 赣州 341000)
0 引 言
随着时代发展,工程类优化问题日趋复杂化,传统优化算法算力不足、效率低下等问题逐渐明显。为了摆脱传统优化算法的局限,研究者们开发了群智能优化方法来解决高度复杂的工程优化问题,如遗传算法(GA)[1]、蚁群优化(ACO)[2]、粒子群优化(PSO)[3]、人工蜂群(ABC)[4]和麻雀搜索算法等。这些算法简单易行,受到越来越多学者的青睐。其中麻雀搜索算法由Xue等人[5]于2020年提出,该算法通过模拟麻雀种群的捕食与反捕食机制来建立数学优化模型。由于其具有算法结构简单、参数少和搜索性能出色等特性,已被广泛应用于智能路径规划[6-8]、图像处理[9-11]、医学分析[12]和电气工程[13-15]等领域。然而,SSA 算法也存在一些不足,如在迭代末期种群多样性衰退,易陷入局部最优等问题。
针对SSA迭代末期种群多样性衰退、抗局部极值能力弱等问题,许多学者提出了可供参考的改进方案。Tang 等人[16]提出了一种基于对数螺旋策略和自适应步长策略(CLSSA)的麻雀搜索算法,该算法首先通过对数螺旋策略对搜索机制进行改进,增强了种群分布多样性和搜索空间多样性;然后引入自适应步长策略,增强了麻雀搜索算法的迭代末期开发与探索能力。仿真结果表明,CLSSA 在23 个基准测试函数的测试上比同类算法更加优秀。
马卫等人[17]提出了一种基于莱维飞行机制的扰动策略来解决SSA 易陷入局部最优的问题。该方案首先引入Sin 混沌映射来增加初始种群的丰富度,然后利用莱维飞行扰动机制增加空间搜索的多样性,最后利用14 个常用的典型高维测试函数进行模拟仿真。实验结果表明该方案不但能保持标准SSA 全局寻优能力,而且大幅度提高了算法在初期的收敛速度和末期的求解精度。
李丹丹等人[18]提出了一种结合多策略改进的麻雀搜索算法。首先在种群初始化阶段使用Tent映射替换标准麻雀初始化函数用来增加种群多样性;然后利用自适应交叉变异算子平衡全局与局部搜索资源,最后运用差分变异对迭代后种群进行扰动,避免后期种群单一。分析模拟仿真结果可知,经改进后的麻雀搜索算法较其他对比算法在寻优性能和收敛速度上更具优势。
段玉先等人[19]提出结合随机采样和纵横交叉策略来优化标准麻雀搜索算法。首先,对原算法初始化阶段使用随机采样法来增强种群丰富度,然后在运行阶段采用非线性惯性权重的策略来提高算法效率,最后使用纵横交叉策略来平衡算法全局与局部的搜索能力。模拟仿真数据表明,新算法弥补了原算法求解精度不足和收敛速度过慢的问题。
通过研究上述改进方法可知,麻雀搜索算法的改良主要集中在优化种群结构、避免局部最优、平衡全局与局部等方面。
为进一步升级算法性能,本文提出一种结合多策略改进麻雀搜索算法(MUSSA)。首先,将特殊透镜学习策略与Iterative 映射融合改进提出基于Iterative映射的混沌透镜学习机制(ILL),并使用ILL 对麻雀种群进行初始化,改善种群逻辑结构,丰富种群多样性;然后,使用遗忘递减策略减少使用ILL 策略个体数量,减少计算成本;最后,使用螺旋策略和参考系机制分别对发现者和追随者的搜索策略进行更新,增强麻雀种群全局探索及局部开发能力,提升算法的收敛速度与精确度,减少种群陷入局部极值的频率。
实验过程中将MUSSA 与标准SSA 以及另外3 个近年性能较为优秀的搜索算法,即哈里斯鹰优化算法(Harris Hawks Optimization algorithm,HHO)[20]、WOA[21]和AO[22]作为参评算法,以13 个基本测试函数对其进行测试并进行Friedman 检验。各种模拟仿真结果均显示,MUSSA 相比原算法和其他参评算法具有更优秀的性能。
1 标准麻雀搜索算法
SSA 是近些年较为优秀的进化算法之一,其核心机制为模拟麻雀觅食行为。麻雀觅食过程可以抽象为一种“发现者、追随者和观测者”的数学模型。其中有较高能量储备的麻雀通常被划分为发现者,而能量较少的个体划分为追随者,发现者与追随者可以互相转化。此外,在雀群中还会选择一定比例的个体成为观测者,为种群进行天敌检测和危险预警,若发现危险,这些个体就会飞去寻找新的位置。麻雀搜索算法就是通过公式模拟其种群3 种角色的位置更新来求解问题最优解。其中,发现者的位置更新规则为:
其中,t表示当前迭代轮次表示最大迭代次数,表示迭代到第t次时第i只麻雀的第j维的值。α∈[0,1];R2∈(0,1)表示报警值;ST∈[0.5,1)则表示安全阈值,通常设置为0.8;Q为服从正态分布的随机数,L表示1×D的矩阵,D表示当前问题的维度,其中每个元素的内部值为1。公式(1)中的位置更新规则可表述为:当警报值未超过安全阈值时,代表当前捕食区域不存在威胁。当警报值超过安全阈值时,代表捕食区域存在威胁,发现者需转移到安全区域觅食。
追随者位置更新规则为:
观测者位置更新规则为:
其中,表示当前全局最佳位置,β表示观测者位置更新的步长控制参数,是服从高斯分布的随机数,其值域为(-1,1)。fi是当前个体的适应度值,fg表示当前全局最优个体的适应度值,fw表示当前最差个体的适应度值。K∈[-1,1]是一个随机数;ε 是很小的常数,以避免分母为0。观测者位置更新规则可表述为:当麻雀个体处于不安全位置时,需采取反捕食策略,即通过变换位置来获取更高的适应度;当搜索单元处于种群中心位置时,将持续向同伴位置进行收敛以规避威胁。
2 基于多策略改进的麻雀搜索算法
通过研究标准麻雀搜索算法的3 类个体更新公式可以看出,其寻优方式可分为2种:
1)个体直接跳跃至当前最优解附近。
2)个体向原点靠近。
麻雀搜索单位采用该途径进行位置更新虽然获取了强大的开发能力,却忽略了向最优搜索单位收敛过程中对邻域空间的探索,降低了搜索空间的多样性,使其容易错过全局最优而陷入局部最优。针对上述问题,本文提出多种改进策略用于优化标准麻雀搜索算法。
2.1 遗忘递减的ILL策略
近年来,计算领域出现了一种名为反向学习策略(OBL)[23]的优秀技术,用于增强机器学习算法性能,其基本思想是在求解一个问题时,同时对其相反问题进行建模求解,以提高算法的鲁棒性和泛化能力。经过Tizhoosh等学者[23]的深入研究,发现使用反向学习策略能够显著增加智能算法找到全局最优解的可能性。
通过阅读文献[24],可知透镜学习公式在缩放因子取值为1 时可以化简为式(4)。该式的效果与反向学习策略类似,也能增加算法鲁棒性。
其中,x'j是xj对应的反向解;aj表示搜索空间上边界,bj表示搜索空间下边界。
由于透镜学习机制具有较强的鲁棒性,其生成的解有时会比当前最优解更差。为了进一步优化种群丰富度,并尝试克服该缺陷,本节借鉴文献[16]将混沌映射替换随机参数的实验思路,将Iterative 映射同特殊透镜学习机制结合,提出一种基于Iterative映射改进的透镜学习机制ILL。具体数学模型描述为:
其中,X'i表示种群中第i个搜索单位对应的混沌透镜学习机制生成的改良解,λi是对应的混沌值。
Iterative 映射数学模型如式(6)所示,Iterative 映射图如图1 所示,可以看出Iterative 映射具有良好的随机性和遍历性。

图1 Iterative映射图
其中,b∈(0,1),本文取值为b=0.7。
通过使用ILL 策略,算法的搜索单位初始位置分布会变得更加随机,从而改善种群质量,并增强算法全局开发能力,提升初期收敛速度。然而,随着迭代轮次的增加,对所有搜索单位使用ILL 策略可能会产生大量的无用搜索,导致算法的运算量增加,进而影响算法的效率,由此本节提出基于遗忘曲线的递减策略,随着迭代轮次的增加,逐步减少使用ILL 策略的个体数量,具体数学公式如式(7):
其中,P表示使用ILL 策略的种群数量,N为种群搜索单位总数,round(·)是四舍五入函数;e-t/s是记忆保持率;t表示当前迭代轮次;s表示遗忘速度,取值为200。
2.2 动态权重的螺旋与参考系策略
在每次迭代的初始阶段通常会看到单个发现者快速地收敛于全局最优解决方案,以此获得强大的开发能力。然而,以该种方式获取全局最优解往往忽略了对附近搜索空间的探索,导致在全局开拓阶段探索空间量严重不足,并倾向于陷入局部最优解。为了提高发现者模型在解空间搜索的充分度和在优化问题中的求解性能,本节在发现者模型中引入了2种改进方法。
第1 种改进方案参考文献[25],采用鲸鱼优化算法气泡网攻击中的螺旋搜索策略,以增强发现者的更新模型。然而,WOA 中使用的螺旋搜索策略具有固定不变的局限性,可能导致发现者的搜索方法缺乏多样性,抗局部极值能力弱,从而削弱算法的搜索能力。于是本节还参考众多研究者使用的惯性权重策略[26-29],在螺旋策略位置更新规则中写入非静态权重因子η,动态调整发现者位置更新的螺旋弧度。这种动态调整螺旋参数的模式扩展了发现者探索未知搜索区域的能力,同时仍保持了其强大的收敛速度。螺旋参数β模型如式(8)所示,其中,a是用于定义对数螺旋的常数,l是[-1,1]之间的常数。
第2 种改进方案参考文献[30],在发现者位置更新模型中集成参考系,即让发现者参考上一轮次的全局最优解来进行位置更新。通过此模式更新的发现者可以减少对无意义方位的探寻,从而提高算法中发现者模型的运行效率。为平衡该策略对算法全局和局部的影响,也在该策略中使用上文提及的惯性权重思想(在公式中引入非静态权重因子ω),其模型如式(9)。非静态权重因子在迭代初级阶段具有相对大的值,提高发现者模型使用参考系的频率,提高全局开发性能,而在迭代末期赋予较小的权重值,减少发现者模型使用参考系的频率,降低策略对算法的影响,从而更好进行局部开发。
相同的算法对于不同的问题不可能一直保持着优秀的寻优能力。为了提高改进后算法的寻优性能与泛用性,使用随机概率p来随机选择2 种策略。基于上述分析,发现者位置更新规则调整为式(10)。式中为当前发现者在对应轮次的最优位置,β为基于余弦函数的动态螺旋参数,α为随机数且值域在(0,2)之间,rand 是区间(0,1)内均匀分布的随机数,R3是一个(0,1)之间的随机数,t和M分别为种群当前迭代到的轮次和允许种群最多迭代到的轮次。
通过运行算法并进行分析发现,带权重因子的发现者在初期的迭代进化过程中会以从外而内的螺旋逐步开发解空间,从而获取更详细的空间探索,增加了获取高质量解的概率;而在迭代进化的末期,权重因子η逐渐减小,螺旋幅度也逐步减小,这样减少了发现者对相同空间的重复探索,从而增强了算法末期寻优效能。
分析追随者更新公式可知,其搜索单元收敛于当前最优解的方法为直接瞬移至当前最优解邻域或是快速向原点靠拢。与粒子群算法中粒子逐步向最优解靠近的方式不同,该方式缺乏局部搜索能力,这就导致以最优个体为中心寻优的追随者极易迷失方向,从而陷入局部极值。为了减少追随者迷失方向的概率并丰富追随者个体与个体之间的学习与参考,本节针对追随者个体寻优提出一种参考系机制,其原理如式(12)所示。与发现者模型参考当前全局最优个体不同,追随者参考的是相对位置位于其前一位的个体。此外,为了避免只有正方向扰动对算法的影响,引入参数μ进行改动,μ为Sign函数,表达式为(13):
在上述改动基础上,为了进一步提高改进后算法的寻优性能,与发现者模型一样,追随者也使用随机概率p来随机选择使用策略。基于此分析,追随者位置更新规则调整为式(14)。
综上所述,改进后的麻雀搜索算法流程如图2 所示。图中PD 为生产者的数量,SD 为感知到危险的麻雀数量。

图2 改进后的麻雀搜索算法的流程图
2.3 改进后的麻雀搜索算法收敛能力分析
全局开发和局部搜索能力等指标通常被研究者用来衡量算法性能的优劣。前者决定了算法前中期收敛到全局最优位置邻域的速度,而后者决定了算法收敛精度,即让算法求出的解向全局最优无限靠近。SSA 算法通过对种群对象的职责划分来决定全局与局部搜索比重,其中发现者的位置更新可以视作为全局开发,其收敛方式如图3 所示,而追随者与观测者的位置更新可以视为局部挖掘。在MUSSA 中沿用了原算法的种群对象职责划分,且在原算法上进行了改进。首先,使用ILL 策略对种群进行优化,提高产生优质解的概率,丰富种群多样性,增加算法在全局开发时的性能,并且对使用该策略的种群进行遗忘递减的数量控制,减少无用搜索成本,使其逐步适应整个算法求解流程,由此保障算法收敛速度。然后,使用动态权重的螺旋策略和参考系机制分别对发现者与追随者位置更新策略进行改进并使用随机概率来决定使用何种改进策略。对发现者来说,自适应权重螺旋策略的引入,在保留了原算法优越性的同时提高了全局搜索精度;对追随者而言,动态选择的参考系机制不但保障了其原有优势,还提升了局部拓展能力。由此可知,改进后的螺旋策略和参考系机制提高了麻雀个体对其所在位置邻域搜索的充分程度,能有效解决麻雀个体陷入局部最优的短板,保障了全局与局部的收敛精度。综上,本文提出的改进策略能够在保障原算法收敛速度优势的同时增强其综合寻优性能。
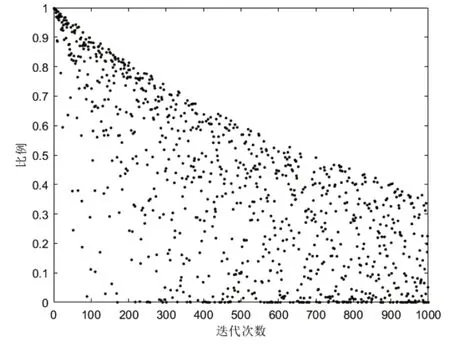
图3 发现者收敛函数散点图
2.4 时间复杂度分析
时间复杂度作为衡量算法计算量的重要手段之一,是智能算法必须考虑的重要因素。假设N为算法的总体数量级,M为最大迭代频数,D为待解决问题的维度,那么标准SSA 的时间复杂度可表述为O(N×M×D)。从宏观上分析,MUSSA 算法优化过程中并没有在整个算法外增加循环,由此相比原算法并没有增加时间复杂度。从微观角度分析,假设p为发现者在种群的比率,t1为改进后发现者位置更新损耗时间,t2为改进后追随者位置更新损耗时间,t3为使用ILL 策略更新最优解损耗时间。那么发现者部分的时间复杂度为O(M×N×p×t1×D),追随者部分的时间复杂度为O(M×N×(1-p)×t2×D),使用ILL 策略的时间复杂度为O(M×t3),总时间复杂度为O(M×(N×D(p(t1-t2)+t2))+t3),由于p、t1、t2、t3均为较小的数,所以可以近似认为MUSSA 的时间复杂度为O(N×M×D)。综上所述,尽管MUSSA 相比SSA 求解最优解花费的时间稍长,但是并没有增加时间复杂度。在权衡时间、性能和精度的情况下,使用MUSSA 通过牺牲少量时间获得更好的性能和更高的精度是值得的。
3 数值实验和结果分析
仿真实验基于Windows10(64 bit)操作系统,Intel CoreTM i5-9300H CPU@2.40 GHz、2.40 GHz 主频及16 GB 内存,使用MATLAB R2017B 编程开发。本文使用了在文献中常见的13 个基准测试函数进行模拟仿真,其中前7 个测试函数为单峰测试函数,有且只有一个理论最优解,主要用途为测试算法在局部开发时的性能;后6 个测试函数为多峰测试函数,存在多个局部极值,一般用来评价算法的全局探索性能和抗局部极值性能。13个基准测试函数如表1所示。

表1 测试函数
3.1 不同改进策略的有效性分析
本文采用2 个改进策略,分别是:1)采用遗忘递减的ILL 策略(SSA-A);2)采用动态权重的螺旋和参考系策略(SSA-B)。为了分析本文提出策略对标准麻雀搜索算法的影响,取种群大小为50,最大迭代轮次为1000,维度为30,对表1 中的F1 函数与F2 函数分别进行模拟仿真。从图4 可以看出,对于单策略改进的麻雀搜索算法SSA-A 和SSA-B,在收敛速度及精度上明显优于原算法;对于融合2 种改进策略的MUSSA,其性能不但优于标准SSA,而且优于2 个单策略改进的SSA。模拟仿真结果表明本文提出的2种改进方式可行且有效。

图4 不同策略收敛情况
3.2 MUSSA与其它先进算法比较实验
为了验证MUSSA 算法的改进效果,使用原始SSA、WOA、HHO 和AO 算法作为参评算法进行对比实验。同时,为尽量减少偶然因素的影响,每种参评算法均要单独运行32 次,然后取这32 次实验结果的平均值记录于表2、表3、表4 中作为该算法的性能指标,并根据仿真结果对参评算法优劣性进行评价。本次模拟仿真,参数设置如下:

表2 MUSSA与其他算法性能对比(Dim=30)

表3 MUSSA与其他算法性能对比(Dim=50)

表4 MUSSA与其他算法性能对比(Dim=100)
极限迭代轮次为300,麻雀种群搜索单元数量设置为50,预警值设置为0.8。为了确保参评算法性能,所有参评算法的参数根据原论文设置。鉴于本文使用的测试函数属于非固定维度函数,因此在维度为30、50和100的条件下分别对这13个函数进行求解。
根据对3 种不同维度的实验数据的分析,发现MUSSA 算法在大多数测试函数上的寻优性能较其他参评算法要优秀。此外,改良后的麻雀搜索算法性能不会因为测试函数维度的上升而产生较大波动。
具体而言,对于单峰测试函数F1~F7,MUSSA 算法在前6 个测试函数上总能找到比其他参评算法更好的最优值,且只在测试函数F7 上的表现分别在收敛精准度和收敛稳定性方面稍逊于AO 算法和HHO算法。
对于多峰测试函数F8~F13,只有HHO 算法在测试函数F8上的寻优能力能稳定优于MUSSA算法。在测试函数F9~F11上,除WOA 算法外的所有参评算法均能得到不错的优化效果,即稳定收敛到理论最优值且不因维度变化而发生变化。在函数F12和F13上,只有MUSSA算法找到的最优值更接近于理论最优值。
值得注意的是,无论使用何种测试函数,MUSSA算法的性能总能在绝大部分情况下优于原始SSA 算法且不因维度的变化而发生改变。这说明MUSSA 算法的开发能力要明显优于原始SSA算法。
综上所述,MUSSA算法相比于SSA算法以及其他参评算法具有更优秀的性能。本文所提出的改进策略较好地提升了种群丰富度,拓展了算法针对理论最优解所存在的域的发掘,从而提高了算法的寻优性能。
为了比较MUSSA 和SSA 针对不同测试函数的优化表现,根据维度为30 时的标准差数据,对各参评算法从小到大进行排序,并根据排序结果绘制了排名雷达图,如图5 所示。性能雷达图中的曲线所围成的多边形区域越广,表示该算法的标准差数据排序越靠后,其稳定性就越差。在本文中,使用黑色加粗实线表示MUSSA 算法,黑色虚线表示原始SSA 算法。从雷达图中不难发现,SSA 算法排名曲线所围区域远超MUSSA 算法,这说明MUSSA 算法在各测试函数上的整体性能优势较原始SSA更显著。

图5 维度30测试函数雷达图
为了评估改良后算法的收敛速度和收敛精度,本文给出MUSSA 算法和其他参评算法在解决不同维度测试函数时的平均收敛曲线,如图6 和图7 所示。从图中可以看出,无论是在30 维还是100 维情况下,MUSSA总能获得不错的优化效果。
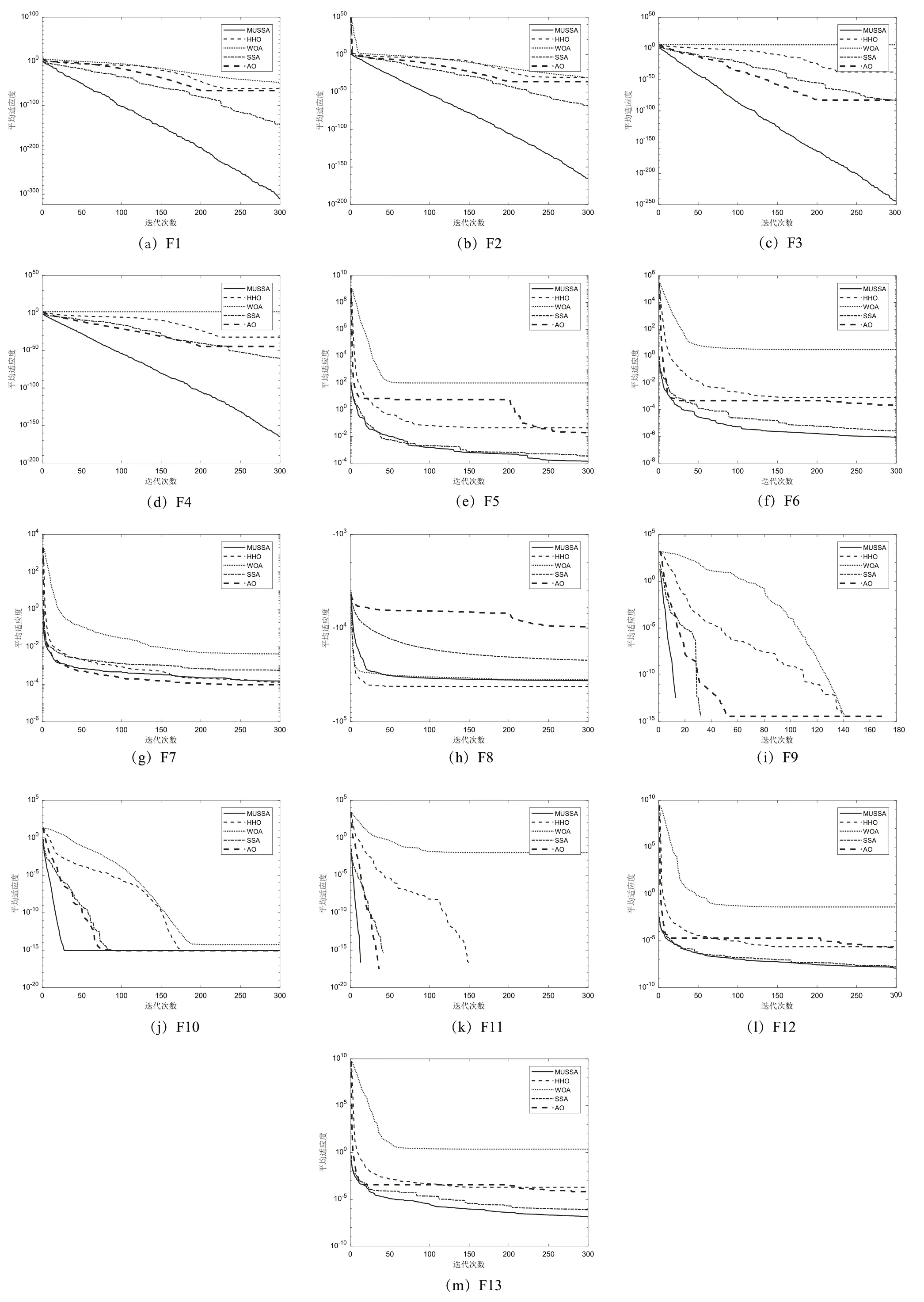
图7 MUSSA与其他优化算法收敛曲线图(Dim=100)
为了从统计学角度证明改良后算法的优越性,本文还采用Friedman 检验[31]对各参评算法进行了多维度校验。表5 为各算法的平均排名结果,数据保留3位小数。从表5中可以看出,MUSSA算法无论是在各维度的独立排名还是总排名均为第一。

表5 不同算法的Friedman检验
综合上述实验结果可以得出,MUSSA 算法相较其他参评算法在统计学角度具有更好的寻优性能。
4 结束语
本文首先将Iterative映射与透镜学习机制引入标准麻雀搜索算法中,通过改善种群结构,来丰富种群多样性,从而避免算法陷入局部最优,并使用遗忘递减策略,逐步减少使用混沌透镜学习策略的个体数量,削减计算成本;然后,将动态权重的螺旋搜索策略和参考系机制作用于发现者,优化全局搜索时的搜索范围,增强其对局部的开发能力;最后,将动态选择策略和基于螺旋的参考系机制作用于追随者,平衡全局与局部搜索不均的态势,并提高收敛速度。本文选取常用的13 个基准测试函数,从收敛性、稳定性和平衡性3 个角度进行模拟仿真,实验结果表明MUSSA 在各方面性能均优于其他参评算法。
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
法律方法(2018年2期)2018-07-13
物联网技术(2017年5期)2017-06-03
魅力中国(2017年6期)2017-05-13
中学生数理化·八年级物理人教版(2017年11期)2017-02-15
上海理工大学学报(2016年2期)2016-06-02
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
江苏高职教育(2014年2期)2014-07-16
