
基于XLNet的业务流程下一活动预测方法
2023-11-14 06:06:36夏灿铭邢玛丽何胜煌
计算机集成制造系统 2023年10期
夏灿铭,邢玛丽+,何胜煌
(1.广东工业大学 自动化学院,广东 广州 510006;2.上海交通大学 自动化系,上海 200030;3.上海交通大学 宁波人工智能研究院,宁波 200052)
0 引言
伴随着数字化转型,流程执行数据(也称事件日志)的数量以海量规模增长。流程挖掘方法通过分析流程日志来发现、监控和改进业务流程[1],预测性业务流程监控(Predictive Business Process Monitoring, PBPM)已经成为流程挖掘的一个关键领域,其通过预测下一个可能的活动、持续时间和剩余完成时间[2-3]等任务来进行更有效的资源管理和提高运营效率。传统的预测研究主要基于业务流程模型,如流程树[4]、随机Petri网络[5]、变迁系统[6]等,而近年众多学者开始关注机器学习和深度学习技术在业务流程中的应用,如下一活动预测任务[7-8]。研究表明,在下一活动预测任务中,机器学习[9]和深度学习方法的预测效果在大多数情况下优于基于业务流程模型的方法。虽然如此,下一活动预测的效果还有待进一步提升[10]。
下一活动预测任务主要通过提取历史流程实例的前缀序列来构建数据,因此数据由不同长度的实例前缀构成。不同长度的流程实例之间存在一定差异[11],例如对于一个刚开始执行不久的流程实例和一个即将执行结束的流程实例,两者包含的上下文信息会有差异,而上下文信息可能会影响流程实例运行的方向[12]。因此,需要改进基于深度学习预测的方法,以更好地获取事件序列内部的关系。目前,基于深度学习的下一活动预测还需要解决一些问题,例如长—短期记忆[13](Long-Short Term Memory, LSTM)缺乏长距离和短距离依赖的显式建模,基于LSTM预测方法的性能会随事件序列的长度成比例下降[14];卷积神经网络[15](Convolutional Neural Networks, CNN)将事件的时间属性和活动属性转换为空间图像结构,然而所构建的图像具有信息稀疏性(缺失的信息采用补0的方式),且不能充分利用上下文信息。
针对上述问题,本文提出一种基于XLNet的业务流程下一活动预测方法。XLNet[16]是谷歌大脑提出的一种新的预训练模型,即语义理解的广义自回归预训练,该模型的核心思想是以排列组合的方式重构输入序列,同时兼顾原始的自回归(Auto Regression,AR)[17]和自编码(Auto Encoder,AE)[18]语言模型的优点(在模型输入阶段采用AR从左至右的形式输入数据,在模型中采用注意力掩码方法实现AE)实现了双向预测。虽然目前已有许多新的基于XLNet的工作,例如文献[19]提出基于XLNet的情感分析模型,但是基于XLNet的方法尚未应用于业务流程管理领域。本文方法以XLNet预训练模型为前提,构建了一个用于在业务流程中预测下一活动的网络框架,该框架具备长程记忆和充分利用事件序列的上下文信息的优点,提高了预测的准确率。最后,通过在4个真实事件日志上测试所设计框架的业务流程预测准确率,证明所提体系结构在预测下一个活动的任务方面优于现有方法。
1 相关工作
PBPM是流程挖掘中一个有前途的领域,具有广泛的商业应用。最初的研究重点是从持续时间和成功完成的角度检查业务过程的结果,典型模型有滑动窗口[20]、集成学习[21]等。另外,经典的机器学习方法,如随机森林和支持向量机,也被证明适用于事件序列的预测任务[22]。
随着深度学习的发展,数据驱动方法的应用逐渐广泛。早期,EVERMANN等[23]探索了深层序列建模的成功应用,将深度学习中的循环神经网络(Recurrent Neural Networks,RNN)引入业务流程预测,采用浅层LSTM模型和嵌入技术处理分类变量预测下一个活动;TAX等[7]采用一种具有一个热向量编码的类似LSTM模型架构预测下一活动等任务,效果均优于带注释的变迁系统和两层LSTM单一预测任务;CAMARGO等[24]利用LSTM组合支持分类和数字特征,解决了相同的过程监控问题。然而,LSTM模型建模的序列长度有限且计算费时,其预测效果有待进一步提升。
LSTM因其建模的特点而被广泛应用于序列预测任务,在很少的研究中也探讨了深层神经网络和分析技术的其他架构变体。KHAN等[25]引入基于记忆增强型的神经网络作为解决复杂流程过程的推荐工具;PASQUADIBISCEGLIE等[15]提出基于CNN的预测方法,利用事件序列的活动属性和对应的时间信息构建一个二维图像,将图像输入CNN网络,最终输出活动标签的预测值,从而完成下一活动的预测任务,与LSTM相比,CNN提升训练速度的同时,在一定程度上提高了准确率;MAURO等[26]将CNN的初始架构改编为序列数据,以解决下一个活动预测问题;PAUWELS等[14]提出一种贝叶斯技术来预测下一个事件;BOHMER等[27]提出将局部和全局技术相结合,使用序列预测规则预测下一个事件;WEINZIERL等[10]介绍了更多有关PBPM的深度神经网络架构工作,并对这些架构的下一个活动预测效果进行比较。
本文方法引入具有长程记忆、融合双向信息预测等特点的XLNet模型,克服以往方法中无法捕获输入序列的长距离依赖、只能利用上文信息预测下文信息的缺点,提高了预测准确率。
2 业务流程下一活动预测的基本概念
(1)活动域 活动即业务流程中事件发生的操作,活动域A是n个不同活动的集合,活动域中的活动都有可能出现在事件中。
(2)事件 事件εi是业务流程的主体,其属性包括A中的活动ai和活动发生的时间戳ti等。
(3)轨迹 轨迹σ={ε1,ε2,…,εl}(ti≤tj,1≤i≤j≤l)是由l个按照时间先后顺序发生的不同事件的有限序列,是业务流程实例的执行流程。
(4)事件日志 事件日志L由一系列轨迹组成,表示为L={σ1,σ2,…,σ|L|}。
(5)轨迹前缀 轨迹前缀是从轨迹的开头开始的轨迹子序列,用σk表示轨迹σ中的前k个事件,即σ={ε1,ε2,…,εk}(1≤k≤|σ|)。
3 业务流程下一活动预测方法
图1所示为业务流程下一活动预测的整体框架。首先,将事件日志进行预处理,提取每个轨迹的轨迹前缀,形成一系列长度相同的活动序列和对应的标签;然后,将活动序列输入XLNet,XLNet模型有12层的base版和24层的mid版,本文使用base版,活动序列在XLNet内部经历输入、Embedding、位置编码、Transformer-XL[15]模块等过程后形成一组特征向量;最后,将XLNet输出的特征向量输入设计好的神经网络,对特征向量进行处理并输出预测结果。
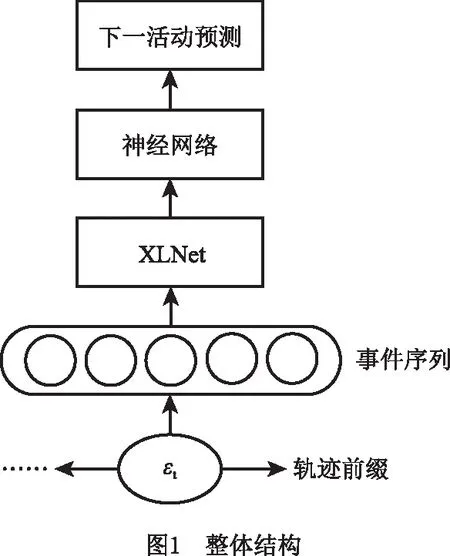
3.1 事件日志预处理
表1所示为一个描述事件日志片段的示例。活动域包括6个不同的活动,即Register request,Examine thoroughly,Check ticket,Decide,Reject request,Examine causally,每个事件均链接到特定的轨迹,对应活动域的活动及其相应的时间戳。
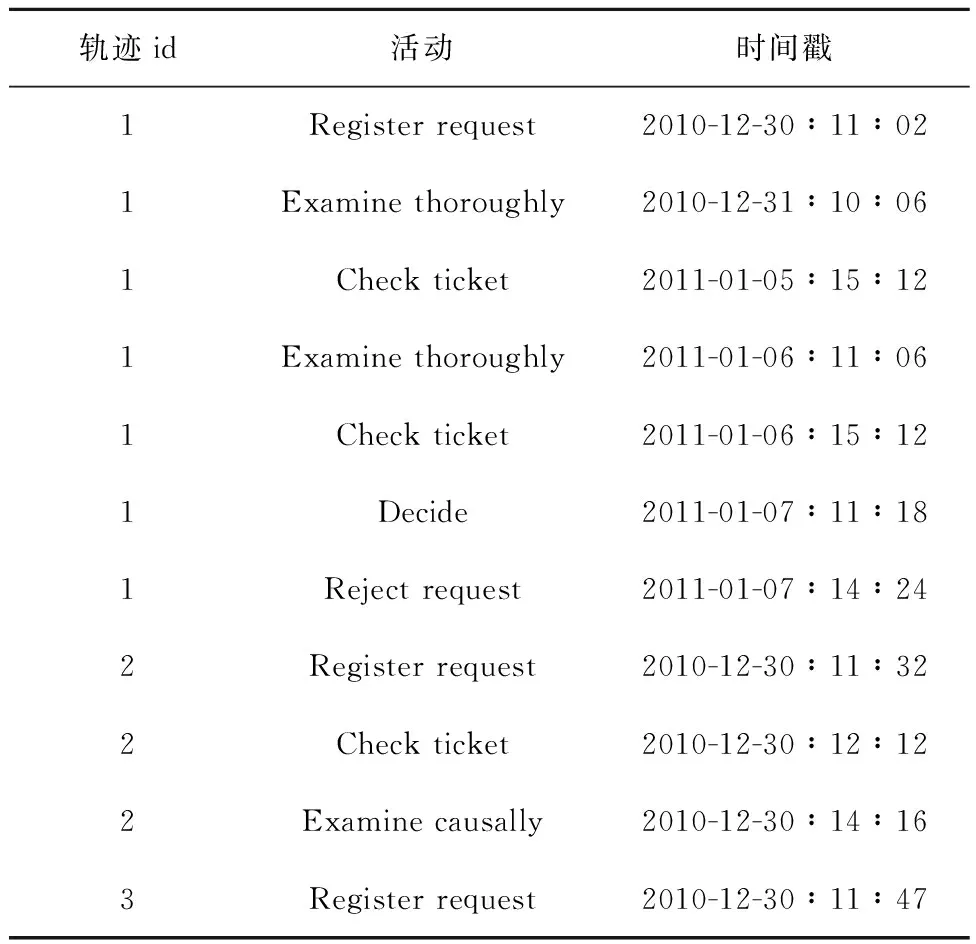
表1 示例事件日志片段
以表1的事件日志为例,事件日志预处理步骤如下:
(1)根据活动数量对活动(原先为英文字符)进行编码,例如表1的活动域中有6个活动,对应活动的编码分别为1,2,3,4,5,6。对于不同长度的前缀序列,采用补0的方式使序列长度相同,均为最大轨迹长度,这里假设最大轨迹长度为轨迹1的长度7。
(2)根据每个轨迹生成前缀序列。如表1所示,轨迹1生成的前缀序列为[0,0,0,0,0,0,1],[0,0,0,0,0,2,1],[0,0,0,0,3,2,1],[0,0,0,2,3,2,1],[0,0,3,2,3,2,1],[0,4,3,2,3,2,1],其对应的预测标签分别为活动2,3,2,3,4,5,可见在创建数据时,删除了同一轨迹的最长序列[5,4,3,2,3,2,1],因为它没有下一活动作为标签。除此之外,仅具有单个事件大小的轨迹3也被删除。对每个轨迹采用以上方法,从而获得数据集和对应的标签。
(3)将活动序列进行Embedding编码操作,生成每个活动对应的多维向量表示,然后进一步输入XLNet预训练模型。注意,在XLNet内部中前期已经包含了对序列的Embedding编码操作。
(4)对标签进行one-hot编码。其中标签是离散的活动值,为了更分明地表示标签特征,使特征之间的距离计算更加合理,采用one-hot编码机制对标签进行编码,例如将标签1编码为[1,0,0,0,0,0],将标签3编码为[0,0,1,0,0,0],以此类推。
3.2 XLNet模型
3.2.1 自回归语言模型
在XLNet中采用的AR模型具有计算效率高、建模概率密度明确的优点,常用的AR模型包括LSTM和RNN等。假设给定长度为T的活动序列a={a1,a2,…,aT},AR模型的目标函数表示为
(1)
式中at为假设需要预测的活动类别,a 3.2.2 随机排列语言模型 XLNet采用随机PLM,PLM由两个步骤组成: (1)全排列采样 例如,按时间排序的活动序列1→2→3→4,经过PLM全排列得到1→2→4→3,4→3→2→1等顺序。如果预测目标是活动2,则对于1→2→4→3,活动2排在第2位,则利用活动1的信息进行预测;对于4→3→2→1,可利用活动4和活动3的信息来预测活动2。由此可见,PLM能够在预测过程中获取上下文信息。 如果序列中位于首位的活动是预测目标,则该序列对模型的训练无益,需要删除该序列。XLNet用式(2)对全排列之后的序列数据进行优化,去除不合适的序列。 (2) 式中:z为从ZT采样的序列;ZT为长度为T的序列全排列集合;azt为序列z中t时刻(位置)的活动值;Ez~ZT表示对采样结果求期望以减小其复杂度。 (2)注意力掩码 注意力掩码(attention mask)即用矩阵遮掩输入序列的某一部分,不让其在预测过程中发挥作用,然而从模型外部看,序列顺序与输入时保持一致。图2所示为XLNet掩蔽机制实现方式的示例,图中假设原始输入的活动序列为[1,2,3,4],随机生成的活动序列为[3,2,4,1],从外部看,输入XLNet的活动序列仍然为[1,2,3,4],则掩码矩阵的原理为:在掩码矩阵中,黑色表示不遮掩(预测时能参考的信息),白色表示遮掩,当预测活动3时,因为其在首位无参考信息,所以掩码矩阵第3行无阴影,然后根据活动3的内容预测活动2,则掩码矩阵第2行的位置活动3有阴影,以此类推。 3.2.3 双流自注意力机制 XLNet的全排列打乱了原来输入的活动序列顺序,因此位置信息在预测时非常重要。XLNet采用双流自注意力机制添加位置信息,双流自注意力机制分为Query Stream和Content Stream: (1)Query Stream 每个预测目标活动对应的序列只包含了该目标的位置信息,注意这里的位置信息是目标在原始活动序列中的位置信息,不是重新排列的位置信息。 (2)Content Stream 每个预测目标活动对应的Content Stream包含了该目标的内容信息。 3.2.4 Transformer-XL Transformer-XL在继承原先Transformer[28]的基础上引入循环机制和相对位置编码的概念,使当前segment在建模时能够利用Transformer-XL论文中的segment信息实现长期依赖性,克服了原先长期依赖性能差、绝对位置编码无法表征序列中活动信息多义性的缺点。图5所示为两个序列之间引入循环机制的信息传递示例图,其中一个圈表示活动序列中每个活动对应的信息向量,灰线表示前一段序列保留的记忆。可见在XLNet模型中,可以利用前一活动序列[a2,a3,a4]保留的信息来实现活动信息传递的长期性。 绝对位置编码只考虑序列的绝对位置信息,不考虑相对位置信息,当两个活动序列中存在共同的活动信息时,该活动序列表示的信息可能相同,从而导致所构建的序列信息不够丰富。绝对位置编码公式为 (3) 式中:Exi,Exj分别表示活动i,j的内容向量;Ui,Uj分别表示活动i,j的位置向量,且Ui=Uj;W为权重矩阵。可见,在不同活动序列中,位置相同的同一个活动的位置编码均相同,模型无法获取相对位置的信息。引入相对编码机制后,式(3)变为 (4) 由此可见,引入相对位置编码使模型在学习过程中能够持续考虑位置关系的影响,能够捕捉不同输入序列包含的不同位置信息,从而获得更加准确的序列向量表示。 将XLNet模型输出的特征向量输入设计好的神经网络结构,以得到下一活动的预测结果。图6所示为自行设计的网络结构,其中:Conv1D层为一维卷积层,用来提取序列特征;Relu层为激活函数,其将非线性特性引入模型,使学习的参数具有意义;Global Pooling层用于降低全连接层的参数数目,防止过拟合;Dropout层用于提高网络的泛化能力,以降低过拟合;Dense层即全连接层,用于增加网络参数,提高网络的稳健性能,并最终输出预测维度。在Dropout层之间的两个全连接层Dense_1和Dense_2中,用直线修正单元函数作为激活函数,而在输出的全连接层Dense_3中,用多分类的归一化指数函数作为激活函数,来输出分类结果。另外,本文用分类交叉熵损失函数(categorical cross-entropy loss)作为损失函数,以调整训练过程中的权重参数。不同事件日志数据集会根据长度和活动种类的关系选择合适的网络参数进行训练,例如: (1)对于最长轨迹长度较长(大于100)的事件日志,参数设置如下: 1)Conv1D_1 卷积核个数为64,卷积核大小为2。 2)Conv1D_2 卷积核个数为128,卷积核大小为1。 3)Dense_1 输出维度为128。 4)Dense_2 输出维度为64。 (2)对于活动种类较多,而最长轨迹长度较短的事件日志,参数设置如下: 1)Conv1D_1 卷积核个数为32,卷积核大小为2。 2)Conv1D_2 卷积核个数为64,卷积核大小为1。 3)Dense_1 输出维度为128。 4)Dense_2 输出维度为64。 Dropout的概率为0.1,Dense_3的输出维度为预测的活动种类。可见,对于活动种类较多且最长轨迹长度较短的事件日志,可减少卷积核的个数,这是为了降低计算量,同时防止因过度提取特征而丢失一些重要特征。值得一提的是,以上网络参数可根据不同数据集灵活调整,以达到更好的预测准确率。 本实验使用BPIC_2012_W[28],BPIC_2012_CW[28],BPIC_2013[29],Helpdesk[30]4个公开事件日志数据集,它们均可在4TU Center for Research Data(https://data.4tu.nl/categories/)下载。这4个数据集来自不同领域,关于数据集的轨迹数量、活动数量等关键信息如表2所示。 本实验在Windows10系统中用代码编辑器Pycharm编写代码,使用的语言为Python 3.6,用Tensorflow中的Keras深度学习库搭建网络结构并进行训练测试。本实验采用第3章的方法从事件日志的数据集中提取可用于训练和测试的数据,并将整个数据集按照比例拆分为训练集(60%)、验证集(20%)、测试集(20%),加入验证集的目的是提高模型的鲁棒性。应该注意的是,验证集是在每次训练迭代结束后用于测试当前训练模型的指标,如损失和准确率。在网络训练过程中,学习率为0.001,迭代次数可设置为100,XLNet的记忆长度设置为最长轨迹长度,XLNet的batch_size根据最长轨迹长度而定。在实验中,如果数据集的最长轨迹长度超过100(如BPIC_2013),则XLNet的batch_size为128,否则为256。 本实验将准确率作为评价指标。准确率表示所有分类中被正确分类的样本比例,例如对于一个分类模型,样本包括m1个A类和n1个B类,模型正确识别了A类中的m2个样本,B类中的n2个样本,则准确率可表示为 acc=(m2+n2)/(m1+n1)。 (5) 在工程代码上,使用深度学习框架Keras的内置评价函数evaluate计算准确率。 实验将本文方法与经典的基于深度学习的方法进行对比,所选的基准如下: (1)TAX等[7]提出的基于LSTM深度神经网络的方法。 (2)CAMARGO等[24]利用LSTM的组合进行分类的方法。 (3)EVERMANN等[23]使用浅层LSTM模型和处理分类变量的嵌入技术预测下一次事件的方法。 (4)MAURO等[26]将CNN的初始架构改编为序列数据的方法。 本文方法与基准方法在各个数据集上的准确率[31]如表3所示,可见本文方法的平均准确率优于其他方法。值得注意的是,虽然本文删除了最长的轨迹和仅具有单个事件大小的轨迹,但是具有更好的泛化性和准确性,即使数据只有一个事件前缀、包含重复活动或者有过长的轨迹长度,该模型均能得到很好的学习效果。通过统计BPIC13数据集的轨迹长度发现,与其他数据集相比,轨迹长度相对较长(至少为该数据集中最大轨迹长度的1/5)的轨迹数量占比很少。在实验中,XLNet的记忆长度参数设置为最长轨迹长度,以使模型对长序列的信息捕捉能力更好,然而对于短序列较多的数据,可能导致精度降低。 表3 基准方法效果对比 由于数据预处理和用于学习的额外输入特征不同,直接与文献中的方法进行比较不公平。例如,文献[26]利用额外的事件属性,属性包括事件标签预测的时间戳等;类似地,文献[7]在Helpdesk和BPI2012数据集上进行了过多的预处理,包括根据事件的数量和持续时间消除轨迹,进而在一个理想的数据集上得到一个预测模型,不能反映现实生活中的复杂事件日志。然而,本文的技术是灵活的,通过改变XLNet的模型配置或者神经网络的结构和参数可以进一步提高准确率。 本文基于深度学习技术开展业务流程实例下一活动预测研究,提出一种基于XLNet的业务流程下一活动预测方法。相比流行的深度学习方法,该方法利用XLNet作为预训练模型,将其输出的特征输入自行设计的网络结构,经过训练得到下一活动的预测模型。该方法具有充分利用上下文信息的优点,并能更好地捕捉序列之间信息的长期关系。最后在4个真实的事件日志数据上开展实验研究,证明本文方法能够较大提升预测准确率,而且平均准确率优于现有的一些下一活动预测的基线方法。作为一种深度学习方法,本文方法的预测效果虽然较好,但是可解释性较差,因此提升可解释性是后续工作的重要内容。除此之外,后续也将继续研究本文方法在其他业务流程任务的应用,如剩余时间预测等任务。
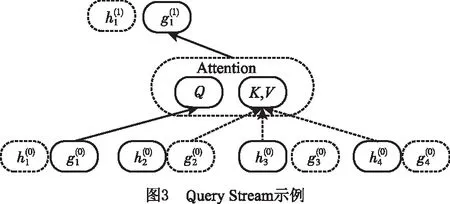
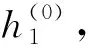




3.3 神经网络结构
4 实验结果
4.1 实验数据
4.2 实验设置
4.3 评价指标
4.4 对比实验

5 结束语
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
加油站服务指南(2021年4期)2021-07-21 02:29:24
心声歌刊(2020年4期)2020-09-07 06:37:14
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
电子测试(2018年23期)2018-12-29 11:11:28
现代营销(创富信息版)(2018年10期)2018-10-12 03:01:32
现代装饰(2018年5期)2018-05-26 09:09:39
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
中国三峡(2017年2期)2017-06-09 08:15:29
