
基于轻量化神经网络的葡萄叶部病害检测装置研制
2023-11-14 11:30:18许文燕
江苏农业科学 2023年19期
许文燕
(1.广州南洋理工职业学院智能工程学院,广东广州 510925; 2.华南理工大学机械与汽车工程学院,广东广州 510641)
目前,随着果园葡萄种植模式不断复杂化、精细化,葡萄树生长过程中所遇到的病虫害情况也越来越复杂。如何快速、准确地检测葡萄叶部病害并采取相关防治措施及时止损[1-3],对于提高葡萄的品质与产量至关重要。随着计算机视觉技术的不断发展,果园病虫害检测技术也取得了长足进步。常见的果园病虫害检测方法主要分为传统机器视觉方法与深度学习方法两大类。传统机器视觉方法一般需要人工提取病虫害颜色、纹理、轮廓等特征[4-7],并对这些特征进行稀疏编码后采用特征分类器进行分类[8-9]。此类方法往往存在识别种类少、识别精度低等问题[10],因此难以大规模推广应用。如王利伟等利用数字图像处理提取15个葡萄病害区域形状、纹理、颜色等特征输入到支持向量机进行葡萄叶部病害的识别,识别准确率可达90%以上[6]。郑建华等综合利用RGB颜色矩、HSV颜色直方图特征、GLCM纹理特征、HOG特征共4种特征集训练SVM获得了93.41%的识别准确率[7]。张梓婷等提出了一种基于k-means++聚类与图像分块的农作物叶片病害异常检测方法,对马铃薯、玉米、苹果叶片检测精度可达 89%以上[11]。传统机器视觉方法识别精度非常依赖特征工程,对于相似病虫害往往难以识别[12]。
然而,深度学习技术却能够自动提取相似病虫害深度特征进行识别,识别准确率高、泛化能力强,近年来被广泛应用在果园病虫害识别领域[13]。如樊湘鹏等基于迁移学习和改进VGG16模型检测葡萄叶部病害,并将其部署在手机APP上,平均识别精度达95.67%[14]。何欣等提出了一种基于多尺度残差神经网络的葡萄叶片病害识别方法,使用Mask R-CNN提取葡萄叶片部位,并加入多尺度卷积等多种策略提升网络特征提取能力,最终输入到Multi-Scale ResNet中进行识别,准确率可达90.83%[15]。刘阗宇等提出了一种多角度建议区域的Faster-RCNN准确定位图像中葡萄叶片病害部位并进行识别的方法,并在真实场景下进行检测识别效果较好[16]。乔虹等利用Faster R-CNN算法对葡萄叶片病害进行动态检测,检测准确率达到了90.9%[17]。上述研究采用各自模型取得较好研究效果的同时,也存在模型网络结构复杂、参数量庞大、运算量要求高等缺点[18-21]。因此,目前迫切需要对它们进行优化改进,以满足在内存、算力资源受限的嵌入式设备上运用的要求[22]。
针对SqueezeNet网络结构中Fire模块数量过多、卷积核尺寸过大而导致模型运行效率低的问题[23-27],进行优化改进以提高其在嵌入式设备上的运行效率,然后将改进网络作为葡萄病害识别模型,拟研制一种便携式果园葡萄病害快速识别与检测装置,以期为果园病虫害信息快速获取与智能化管理提供技术与装备支持。
1 材料与方法
1.1 研究路线
基于改进SqueezeNet的葡萄叶部病害识别与检测技术路线如图1所示。该路线包括数据获取、数据预处理、数据集制作、模型设计、模型训练以及在移动设备上进行模型部署。一般来讲,采集的图像数据中或多或少都会存在部分缺失、分布不均衡、分布异常、混有无关紧要的数据等问题[28],通常都需要对其进行数据预处理,即剔除无效数据、标准化、数据增强以及数据标注等操作,以满足模型训练要求。然后,将预处理过的数据按照一定比例随机划分数据集。在识别模型选取方面,以SqueezeNet模型为基础进行轻量化改进并训练,将训练完成后的模型进行量化并导出部署在移动设备,最终完成深度学习模型在果园病虫害检测方面的落地应用。

1.2 试验数据
1.2.1 数据获取 从AI Challenger 2018农作物病害数据集中获取3 144张葡萄叶片样本。其中,健康叶片336张,病害叶片2 808张(表1)。考虑到葡萄健康叶片数量过少,另外,从广州市从化区(113.59°E,23.55°N)世外萄园中,利用飞萤8 SE相机(分辨率1 280像素×720像素)人工拍摄了366张真实环境下的葡萄健康叶片图像(图2),总计3 510张样本图像。在全部样本图像中,包含了健康、黑腐病、褐斑病以及轮斑病4种葡萄叶片。

表1 葡萄叶片样本数量
1.2.2 数据增强 考虑到各类病害样本数量分布不均,为防止模型产生过拟合问题,采用数据增强技术[29],对各类样本增加水平、垂直翻转、随机添加噪声等操作(图3),将图像样本由原来的3 510张增加到21 060张。因数据增强前后图像大小存在差异,使用MATLAB自编函数将其统一调整至224像素×224像素。

1.2.3 数据集制作 将数据增强后的样本按 8 ∶1 ∶1 的比例随机划分成训练集、验证集以及测试集(表2)。其中,验证集主要用于模型的交叉验证[28],测试集则用于评估最终模型的泛化能力[30]。
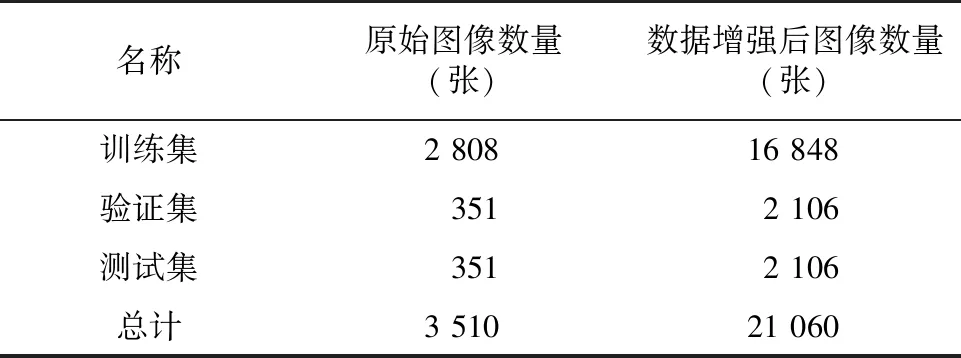
表2 各数据集样本数量

1.3 模型设计与改进
1.3.1 基础模型 近年来,随着深度学习技术的不断发展,卷积神经网络(convolutional neural networks,CNN)也由原来的8层AlexNet[18]增加到16层VGG-16[19],再到后来的22层的GoogLeNet[20]、101层的ResNet-101[31]以及201层的DenseNet-201[32]等。为了提高模型识别精度,科研人员往往采用更深的网络结构。但是这些臃肿而庞大的模型难以在算力资源受限的移动设备上运用[21-22]。为了使深度学习模型能够真正运用到嵌入式设备上,许多科研人员也做了大量的模型轻量化研究[20-21,23,29,33-34]。例如Iandola在2016年提出了一种轻量化的神经网络模型SqueezeNet[35],其结构见图4。SqueezeNet模型在识别精度与AlexNet相当的同时它的参数量仅仅是AlexNet的1/50。因此,本研究以经典的SqueezeNet模型为基础,对其做进一步改进优化,使得它能够在移动嵌入式设备上拥有更好的效率与精度。
由图4-a可知,该模型结构主要有8个Fire模块构成,还含有3个最大池化层(Max Pooling Layer)和1个全局平均池化层(Global Average Pooling Layer)。SqueezeNet模型的核心在于Fire模块,它包括Squeeze层和Expand层2个部分,其结构见图 4-b。通常将Fire模块定义为Fire(M,N,E1,E2),其中M、N分别代表Squeeze层的输入、输出通道数;E1、E2则分别代表Expand层中的1×1、3×3卷积核的数量。由图4-a可知,每经过一次最大池化操作,特征图的大小变为原来的1/4,因此最大池化可以减少模型计算量。Dropout层会随机失活一部分神经元,从而防止模型出现过拟合[36]。卷积层10(Conv10)采用1×1卷积核,输入通道数为512,输出通道数为1 000,输出特征图大小为13×13。卷积层10的输出经过全局平均池化层(Global Average Pooling Layer)后,将特征向量输入Softmax分类器,由Softmax分类器计算1 000种类别的概率,并将概率最大的类别作为模型最终识别结果[10]。

1.3.2 改进模型 原SqueezeNet模型是在大型数据集ImageNet上做过预训练,其分类数目是1 000类。本研究葡萄叶片样本为4类,需要在原SqueezeNet模型中将其改为4类。由于本研究识别种类较少,所以并不需要如此深的网络结构。这里参照文献[23]中的研究方法,在SqueezeNet模型基础上,先移除Fire5、Fire6、Fire7这3个模块。为了保证输入到Fire8的通道数与前面一致,需要把Fire8模块的参数修改为Fire(256,32,256,256),即将该模块中的输入通道数由512减少为256,同时把Squeeze层的输出通道由64减少为32。研究表明,利用1×1卷积替换3×3卷积,可大幅度降低模型计算量[37]。因为3×3卷积核有9个参数,每进行1次卷积需要做9次浮点乘法和1次浮点加法运算,而1×1卷积核仅有1个参数,只进行1次浮点乘法运算,所以1次1×1卷积的运算量约为3×3卷积运算的 1/9[38]。基于此原理,考虑将SqueezeNet模型中部分3×3卷积核用1×1卷积核替换。这样不仅减少了模型参数量,而且也显著地降低了模型运算量。具体做法是:(1)将Conv1的卷积核大小由 7×7 改为3×3,并将卷积核个数调整为64。(2)将Fire模块中的1×1和3×3卷积核数量由原来1 ∶1的比例调整为3 ∶1进行重新分配[23]。此外,由于每进行1次最大池化操作,特征图的大小会减少为原来的 1/4,然而特征图的大小又与深度学习架构的运算量有着密切关系。(3)对于Fire2、Fire3模块,如将其移到MaxPooling2之后,此时特征图的大小变为原来的1/4,计算量相应也会减少为原来的1/4。将上述改进后的SqueezeNet模型命名为T-SNet(即Tiny-SqueezeNet的缩写)与原模型以示区别,其具体结构见图5。

1.4 评价指标
本研究采用混淆矩阵评价改进模型性能优劣。其中,精准率、召回率以及准确率的基本定义如下。
精准率(Precision),又称查准率,是分类器预测的正样本中预测正确的比例。其取值范围在0~1之间,取值越大表示模型预测能力越强。
(1)
召回率(Recall),又称查全率,是分类器预测正确的正样本占所有正样本的比例。其取值范围在 0~1之间,取值越大表示模型预测能力越强。
(2)
准确率(Accuracy)则是分类器预测正确的样本占所有预测样本的比例。其取值范围在0~1之间,取值越大表示模型综合预测能力越强。
(3)
其中,FP表示样本为负,但预测为正的数量;FN表示样本为正,但预测为负的数量;TP表示样本为正,且预测也为正的数量;TN表示样本为负,且预测也为负的数量。
在正、负样本不均衡情况下,使用单一指标来评价模型具有一定的局限性[23]。因此,综合使用3种评价指标对改进模型进行全面而科学的评价[39]。
2 结果与讨论
2.1 模型训练
模型训练环境为MATLAB 2021b版本,其硬件配置为:Windows 10专业版64位操作系统,CPU为英特尔i7-10700,GPU为英伟达GTX 1660 Super 6 GB,主板为微星MAG B460M,内存为32 G。
2.1.1 超参数设置 在模型训练时,将训练超参数设置为:初始学习率(Initial Learning Rate)为0.001,学习率衰减因子(Learning Rate Drop Factor)为0.1,学习率衰减周期(Learning Rate Drop Period)为10轮/次,最大训练轮数(Max Epoch)为30轮,MinibatchSize为64,求解器为SGDM(Stochastic Gradient Descent with Momentum),验证频率(Validation Frequency)为每100次迭代验证1次,利用GPU加速运算,Dropout层随机失活神经元概率设置0.5,模型内部参数初始化采用经过ImageNet数据集训练过的SqueezeNet模型权重值。
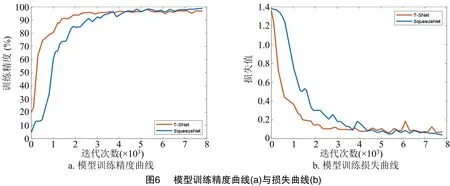
2.1.2 训练结果 在相同试验条件下,进行模型训练,得到原模型与改进模型的训练精度曲线与训练损失曲线(图6)。在相同试验条件下,原SqueezeNet模型与T-SNet模型训练曲线大体一致。但T-SNet模型由于参数量、运算量更少、网络结构更加轻量化,在训练时能够更快地收敛,经过约25 min训练,最终训练精度为99.32%,损失值为0.013 2。原SqueezeNet模型因网络深度较深,权重多且更新慢,因此导致其收敛速度慢。经过约40 min训练最终训练精度为99.65%,损失值为0.012 1。在大幅度降低T-SNet模型参数量与运算量的同时训练精度仅下降0.33%,表明T-SNet模型结构设计较为合理。
2.1.3 特征可视化 为论证改进模型的特征提取能力,利用t-SNE算法(t-distributed Stochastic Neighbor Embedding Algorithm)将模型所提取得深层特征进行可视化。所使用的t-SNE算法,又称 t-分布随机邻近嵌入算法,是一种用于非线性数据降维的机器学习算法[40]。该算法主要思想是将高维点嵌入低维点,重点关注数据点之间的相似性。高维空间中邻近点转化为邻近的嵌入低维点,而高维空间中远点转化为远处的嵌入低维点[41]。因此,可以将高维数据进行可视化,即从原始高维数据中找到同类簇[42]。t-SNE算法相关参数设置,Perplexity为30,迭代次数为500次,采用欧氏距离计算数据点之间的距离。原SqueezeNet模型与改进T-SNet模型从数据集中提取的分类特征如图7所示。
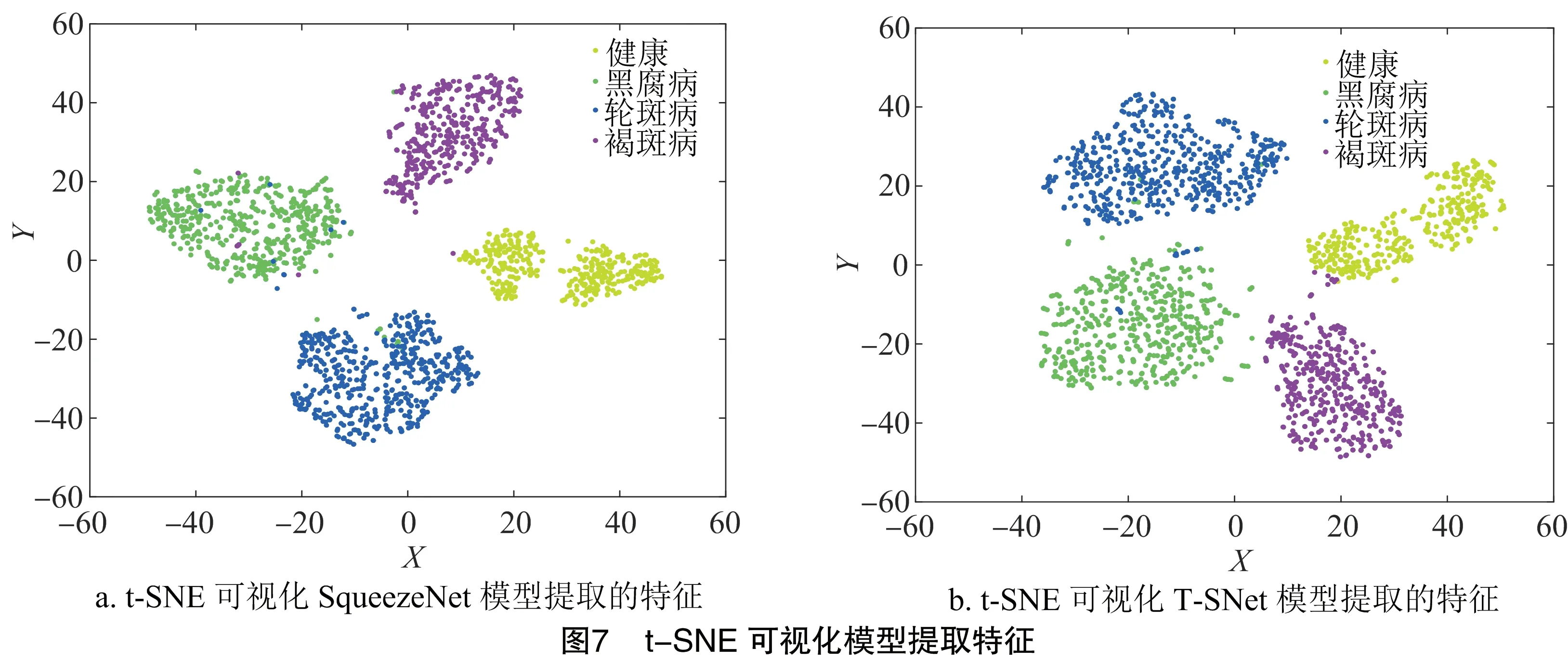
由图7可知,优化前后模型提取特征的能力旗鼓相当,都能准确地提取葡萄叶部健康、病害特征。结果表明改进后的模型特征提取能力较强,并没有出现明显的下降。因此,可将改进后的模型用于葡萄叶部病害的特征提取与识别。
2.1.4 模型性能测试 为验证改进模型的泛化能力,利用测试集数据来测试改进模型的识别性能。同时,为体现改进模型的优越性,选取经典的轻量化网络模型Xception、ShuffleNetv1、MobileNetv2以及原SqueezeNet作为对比分析,5种轻量化模型的参数信息及测试结果如表3所示。
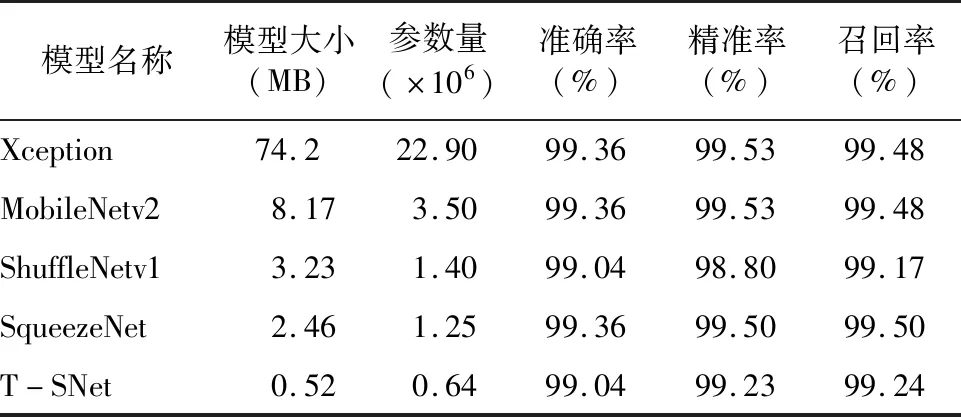
表3 模型各项性能参数与测试结果
由表3可知,5种模型识别性能均表现优异,其准确率都达到了99%以上。在4种原始模型当中,SqueezeNet模型不论是在模型参数方面,还是识别精度方面均表现最佳。T-SNet模型在原模型基础上,大幅度降低模型内存需求以及参数量的情况下,仍具有99%以上的识别精度,再次证明了所设计模型的合理性。T-SNet模型识别准确率、精准率以及召回率分别为99.04%、99.23%、99.24%,相比于SqueezeNet模型分别降低了0.32、0.27、0.26百分点。在模型性能参数方面,T-SNet模型内存需求、参数量分别为原模型的21.14%,51.20%。在识别精度相差不到0.5%的情况下,T-SNet 具有更小的模型内存以及参数量。因此,改进模型是明显优于原SqueezeNet模型的。
2.2 检测装置设计
2.2.1 硬件设计 为实现果园葡萄叶部病害的快速检测,设计了一款果园葡萄叶部病害快速识别与检测装置,其结构如图8所示。该系统包含了树莓派控制模块、加速计算模块、图像采集模块以及显示模块。

所设计移动设备实物如图9所示,树莓派4B处理器为BCN2711四核1.5 GHz Cortex-A72处理器,4 G运行内存,运行系统为Raspbian Buster;其他配置有USB 3.0接口、无线/有线通信模块等。外接设备主要有3.5寸触控显示屏,分辨率为480×320;摄像头为免驱USB摄像头,焦距F 6.0 mm,视频分辨率为640像素×480像素;通过USB 3.0接口连接USB加速棒,其型号为Intel Neural Compute Stick2,为树莓派识别运算提供神经网络推理加速。电源模块采用自带5 V/3 A输出能力的3 000 mA锂电池进行供电,可供该移动设备连续工作6 h以上。
2.2.2 软件设计 为实现果园葡萄叶部病害的快速与实时检测,将T-SNet模型部署在树莓派控制系统上进行应用。树莓派软件环境配置为Python3.7.3、OpenVINO库。该设备软件运行流程为设备开机、启动软件、系统初始化、打开摄像头、调用深度学习模型识别,显示识别结果等,具体流程见图10。

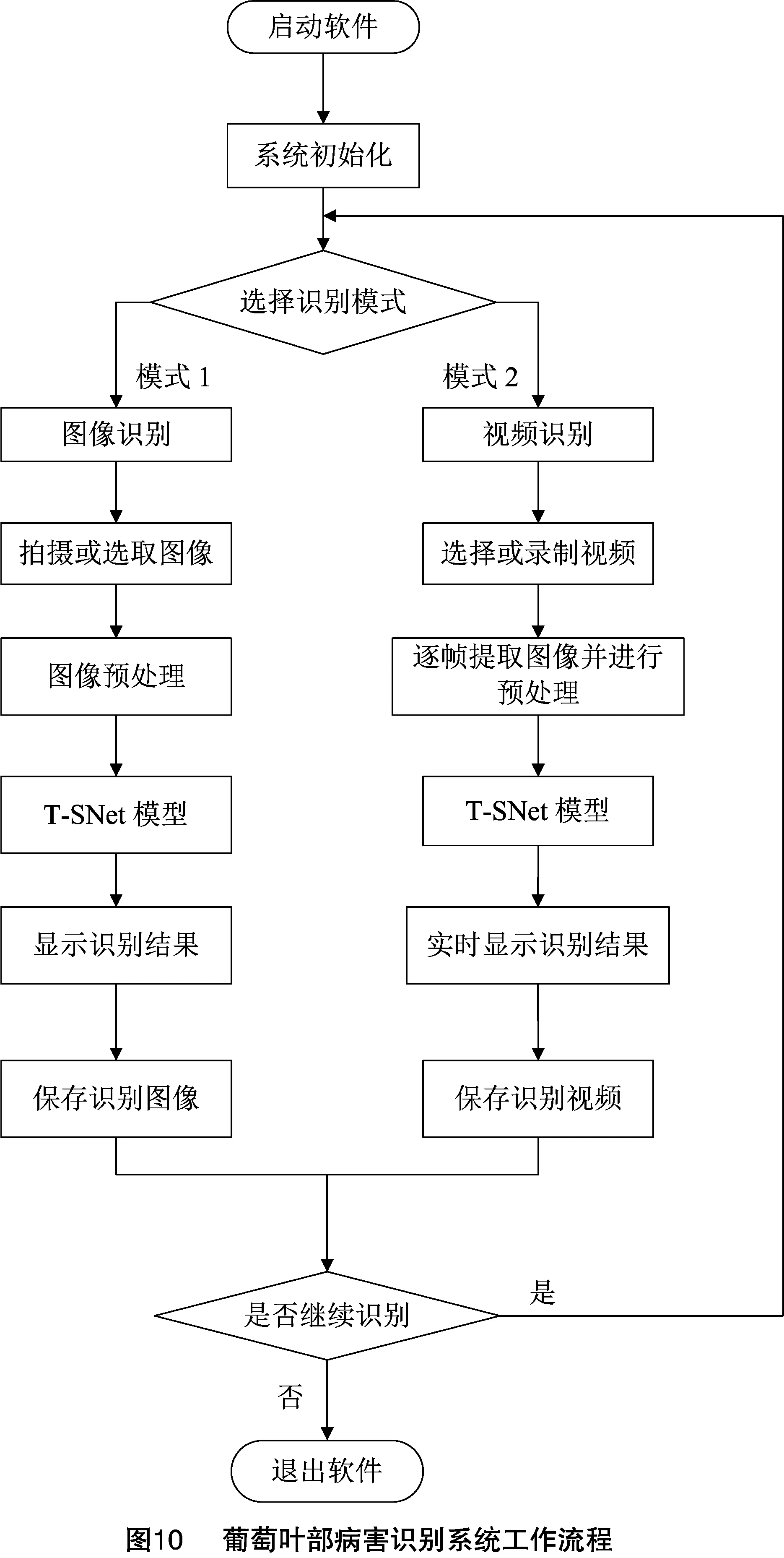
将T-SNet模型部署到树莓派之前,利用MATLAB软件中的exportONNXNetwork函数将T-SNet模型转化为ONNX文件格式,并利用OpenVINO中的DL WorkBench完成模型的量化、编译以及部署。其中,量化是指将模型内部权重值由单精度浮点型转为8位整型,进一步减少模型在移动设备上运行时的内存占用[43],但会有一定的精度损失。然后,利用生成的IR模型文件,即描述神经网络拓扑关系的.xml文件和储存模型权重和偏差数据的.bin文件。最后,将IR文件通过无线蓝牙模块传输到树莓派上进行部署应用。
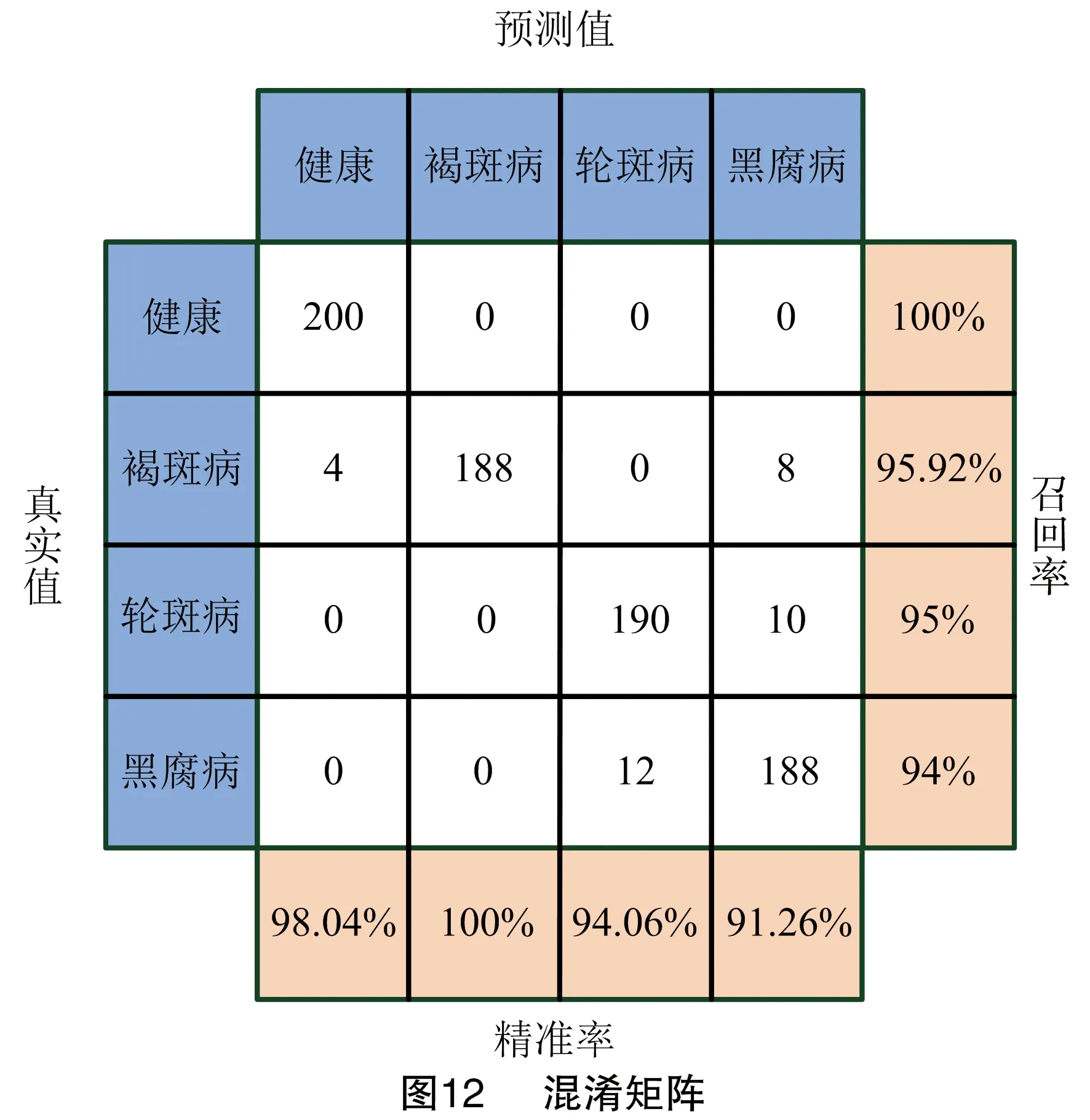
2.2.3 识别效果 为分析所设计葡萄叶部病害检测装置的性能,随机从测试集中选出4种葡萄健康与病害样本,每类选取200张图像进行测试(图11)。同时,将2022年5月23号、2022年6月30日、2022年7月8日这3个时间段分别录制的近 3 h 的葡萄健康叶片视频(在广州市从化区世外萄园中,使用飞萤8 SE相机录制)作为移动设备实时检测的验证视频,并利用混淆矩阵来展示移动设备识别各类葡萄样本的精度(图12)。

由图12可知,所设计移动设备检测葡萄叶部病害的准确率为95.75%,精准率为95.84%,召回率为96.23%。其中,200张健康葡萄叶片样本被全部准确识别;200张葡萄褐斑病叶片有188张被正确识别,4张被误识别为健康,8张被识别为黑腐病;而黑腐病与轮斑病由于患病早期病害特征较为相似,因此存在一定的相互误识别现象。
为测试所设计装置的检测效率,利用在真实果园环境下所拍摄葡萄健康样本视频来实时检测葡萄健康状况。由表4可知,在精度方面,原模型与改进模型平均识别精度均达了95%以上,其精度相差在1百分点以内。在检测速度方面,在未使用USB加速棒的情况下,改进模型检测速度在8~10帧/s,原模型在3~5帧/s,视频画面略显卡顿;在使用USB加速棒的情况下,改进模型平均处理速度明显提升可达86帧/s以上,而原模型平均检测速度仅为 38帧/s。在使用USB加速棒的情况下,模型识别精度略微提升但不显著。在实际应用中发现,若只是拍摄葡萄叶片病害图像进行检测,树莓派4B自身算力基本能够满足使用。因此,所设计移动便携式葡萄病害快速检测设备可满足果园葡萄病害快速检测与识别的应用要求。

表4 所设计葡萄叶部病害检测装置的检测效果
3 结论
针对果园葡萄病害叶部快速识别与检测问题,采集了葡萄健康、病害样本,制作了葡萄叶部病害数据集,并利用改进的轻量化卷积神经网络模型,开发了一套基于深度学习的葡萄叶部病害快速识别与检测装置,得到了如下结论:(1)基于MATLAB平台,将经典的SqueezeNet模型进行轻量化改进包括修改卷积核大小、数量以及Fire模块数量等;改进后,模型内存需求由2.46 MB减少为0.52 MB,模型参数量由125万降低到64万。(2)在相同试验条件下,训练模型并进行性能测试。在测试集上,改进模型识别准确率可达99.04%,仅比原模型下降了0.32百分点。利用t-SNE算法将原模型与改进模型提取的特征进行可视化,结果表明两者的特征提取能力无明显差异。(3)在真实果园环境下,所研制装置识别准确率能够达到95.75%,视频检测速度可达86帧/s以上,可满足果园葡萄病害快速识别与检测的需求。
猜你喜欢
农业工程学报(2022年6期)2022-06-27 02:01:24
中国烟草科学(2022年2期)2022-05-27 22:34:06
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
阅读(低年级)(2020年11期)2020-12-28 02:26:35
女报(2020年10期)2020-11-23 01:42:42
电子制作(2019年11期)2019-07-04 00:34:38
湖北农业科学(2018年18期)2018-12-11 09:53:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国糖料(2016年1期)2016-12-01 06:49:03
小青蛙报(2016年2期)2016-10-15 05:05:56
