
基于词典和表情符号的微博舆情情感分析研究
2023-11-13 07:10张丽李菊
电脑与电信 2023年7期
张丽 李菊
(南京理工大学紫金学院计算机学院,江苏 南京 210023)
1 引言
2023年3月2日,中国互联网络信息中心(CNNIC)第51次《中国互联网络发展状况统计报告》[1](以下简称《报告》)发布。《报告》显示,截至2022年12月,我国网民规模达10.67亿,较2021年12月增长3549万,互联网普及率达75.6%。互联网的开放性,使得公众可以在网络平台便捷地对社会各方面的热点事件发表意见和建议,因此形成了网络舆情。随着微博用户数量的快速增长,微博中携带了大量的网络舆情,其中蕴含了很多的情感信息。通过对这些文本中的情感信息进行挖掘,可以获得用户的情感倾向,从而实现情感分析[2]。通过情感分析,可以获得公众对于热点事件的态度和反应,有利于及时对微博舆论进行干预和引导,促进社会舆论的良性发展[3]。同时,微博舆情分析涉及数据发掘和信息检索等技术,具有广泛的研究价值和实际的应用意义,是近年来的研究热点[4]。
本文在爬取微博数据后,使用情感倾向点互信息算法(SO-PMI)选取新的情感词,对现有情感词典进行补充,并选取常用的表情符号构建了表情符号词典,最终基于构建的词典实现文本情感值的计算,并使用词云图展示关键词。
2 相关工作
微博舆情的情感分析过程包括微博语料的爬取、预处理和情感分析。其中,最关键的过程为采用合适的方法进行情感分析,目前常用的有基于情感词典的方法、基于机器学习的方法和基于深度学习的方法[3]。
微博文本篇幅较短,情感词之间的关联性较小,非常适合使用基于词典的方法进行研究。基于情感词典的分析方法实现较为简单,只需要将预处理后的文本与词典进行匹配,并采用一定方法计算情感得分。常用的情感词典包括中国知网情感词典HowNet、大连理工词典、台湾大学的NTUSD[5]和BosonNLP情感词典[6]。由于网络新词日新月异,在使用词典进行情感分析时,需要考虑情感词的扩充。在微博中,网民经常使用各种表情符号表达强烈的情绪,因此在情感分析中需要考虑表情符号对情感值的影响。习海旭等[6]通过相似度计算后,构建了领域情感扩充词典,实现了情感的可视化分析。吴胜杰等[7]通过统计信息识别新词,对新词进行情感分析,使用改进的PMI算法构建微博特定领域情感词典,并选择常用的表情符号构建表情符号词典,实现了微博文本的情感计算。管雨翔等[8]使用TF-IDF和TextRank两种方法提取种子词,然后采用SO-PMI算法构建领域情感词典,使用实验验证了构建词典的应用效果。林江豪等[9]使用TF-IDF算法选择种子表情符号,使用SO-PMI算法计算候选情感词与种子表情符号的贡献值,构建情感词典。李楠等[10]等通过归纳表情符号的动态特征,进行微博舆情分析。胡湘君[11]在微博综合计算过程中考虑了表情符号的作用,从而提高了模型的有效性。
本文对抓取后的数据进行清洗、分词和去停用词,通过TF-IDF算法获得种子情感词,再使用SO-PMI算法在预处理后文本中筛选情感新词,补充到情感词典中,通过计算词频选择常用的表情符号构建表情符号词典。通过情感极性值的计算和可视化方法,分析网络热点事件中人们的情感。
3 构建词典
BosonNLP词典是基于微博、论坛、新闻等数据来源构建,包括很多网络用语和非正式的简称,更适合于微博的情感分析。本文使用BosonNLP词典作为基础情感词典,使用TF-IDF筛选出文本中的种子情感词,再使用SO-PMI筛选出微博文本中的新情感词,加入到词典中,完成情感词典的扩充。本文还构建了表情符号词典和双重否定词词典,并使用中国知网的程度副词词典和否定词词典,完成情感极性的计算。
其中,微博情感词典的构建过程如图1所示。
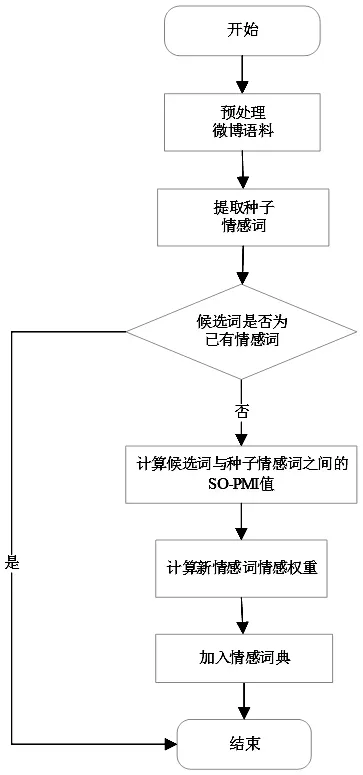
图1 微博情感词典构建流程图
3.1 微博语料的预处理
微博语料的预处理过程包括数据清洗、分词和去停用词[12]。其中数据清洗包括:
(1)删除“【话题名称】”“#话题名称#”、@微博昵称;
(2)删除网页链接、视频、图画,各种中英文符号;
(3)保留表情符号,用于表情符号词典的构建。
数据清洗结束后,就可以进行分词,本文选用结巴分词作为分词工具。微博文本中出现大量网络新词的情况,例如“打call”“带节奏”等,为确保分词的正确性,本文补充了搜狗拼音输入法的“网络流行新词”词库[13],使用jieba.load_userdict()导入自建词典。
完成分词后,使用“哈工大停用词典”删除停用词,将分词后的结果保存。
3.2 构建情感词典
3.2.1 使用TF-IDF算法选择种子情感词
TF-IDF的全称为Term Frequency–Inverse Document Frequency,是一种统计方法,用以评估一个词语在文本中的重要性程度[14]。其中TF表示词语在文本中出现的频率,IDF表示词语的逆向文件频率。计算公式为:
其中,nij表示词语i在文本dj中出现的次数,分母表示文本dj的总词数。
其中,|D|表示所有文本的总数目,| {j:ti∈dj}|表示出现该词语的所有文本数目,为了防止所有文档中都不含该词语时分母为0的情况,所以一般都要加1。
一个词语的TF-IDF计算公式为:
对于预处理后的微博文本,使用TF-IDF算法筛选出50对正向情感种子词和50对负向情感种子词,部分种子词如表1所示。

表1 情感种子词示例
3.2.2 使用SO-PMI算法筛选新情感词
点互信息算法PMI可以计算语料库中词语之间的相似度,其基本思想是词语之间共现的频率越高,说明相似性越高,反之,则越低。计算公式如下所示:
其中,P(w1,w2)表示两个词语w1和w2共同出现的概率,P(w1)和P(w2)分别表示词语w1和w2单独出现的概率。如果两个词语有很强的相关性,则共现概率大于单独出现的概率,此时计算出的PMI值大于0。
SO-PMI通过PMI算法计算词语的情感倾向,从而能够选出新的情感词。选定初始的正向情感种子词集Wpos和负向情感种子词集Wneg,计算词语wordi的情感极性公式如下所示:
计算结果大于0时,表示词语wordi为正向情感词;反之,表示wordi为负向情感词。
使用SO-PMI算法共筛选出了703个正向新情感词和1673个负向新情感词。根据SO-PMI值将情感词的情感强度取值分段处理,赋予值为:[1,2,3]和[-3,-2,-1]。部分新情感词如表2所示。
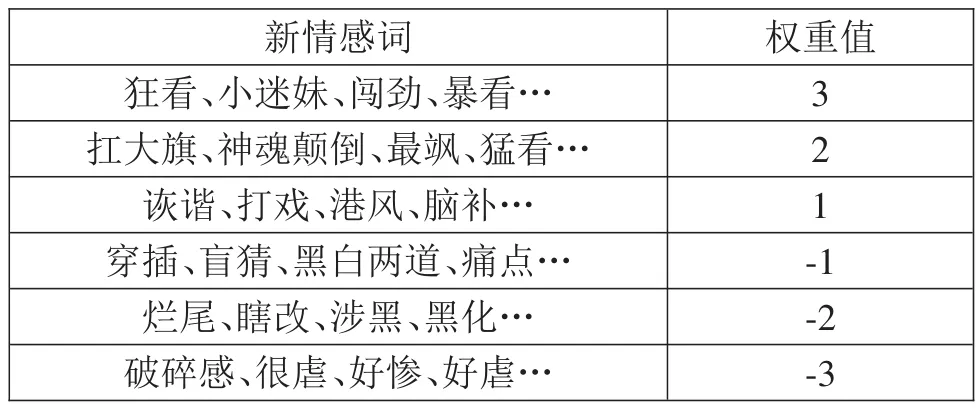
表2 新情感词和情感强度示例
3.3 构建表情符号词典
选择微博文本中频率较高的表情符号构建表情符号词典。对预处理后的微博文本,使用正则表达式过滤后只保留表情符号,共计551个表情符。对表情符号进行词频统计,筛选出词频数较高的前10%共计60个表情,组成表情符号词典。表情符号代表正向情感时,权重值设置为1;反之,权重值设置为-1。表情符号词典如表3所示。

表3 表情符号词典示例
3.4 构建否定词词典和双重否定词词典
否定词可以改变情感词的情感极性,而双重否定不会改变情感词的情感极性,但是会加强情感强度[7]。本文通过手动搜集,构建了否定词词典和双重否定词词典,其中否定词共73个,双重否定词16个,部分词如表4所示。

表4 否定词词典和双重否定词词典示例
3.5 构建程度副词词典
程度副词可以加强情感的表达强度,因此在情感分析时需要考虑情感词前面是否有程度副词。程度副词词典来源于知网词典库中的“中文程度级别词语”,共219个词语。这些词语的情感强度共有6级,在权重设置时根据不同的级别从高到低依次设置为3、2.5、2、1.5、1和0.8,词典示例如表5所示。

表5 程度副词词典示例
4 情感极性的计算
微博文本的情感极性结算过程为:
输入:分词后微博文本D
输出:文本的情感值s
(1)逐条遍历微博文本,提取其中的情感词、否定词、双重否定词、程度副词和表情符号列表。
(2)初始化ω=1,s=0。
(3)遍历微博文本Di中的全部词,
①如果当前词是情感词,判断该情感词与上一个情感词之间:
如果有否定词,则w=(-1)n×w,n为否定词的个数;
如果有双重否定词,则w=1×w;
如果有程度副词,则w=d×w,d为程度副词对应权重值。
②计算文本情感值s=s+w*v,其中v为情感词对应的权重值。
③如果当前词为表情符号,s=s+w*e,其中e为表情符号的权重值。
(4)返回s。
5 实验及结果分析
本文实验数据来自新浪微博,使用Python的Scrapy框架,爬取话题#狂飙#的微博文本,时间跨度为2023年1月14日到2023年2月6日,共计72965条记录。对爬取后的数据进行预处理后,基于构建的词典计算文本情感值,并进行可视化分析。
该剧在爱奇艺和中央电视台首播,播放周期为2023年1月14日至2023年2月2日,该话题下每日博文发布数量如图2所示。从图2可以看出,每天发布的微博数量是螺旋式递增的,在2月4日时达到顶峰,此时也是该剧播放结束后两天。此后每日发布微博数量逐渐减少。

图2 每日发布微博数量图
每日平均情感分、每日正向平均情感分和每日负向平均情感分如图3所示。从图中可以看出,每日平均情感分均为正值,每日负向平均情感分和每日情感平均分波动不大,每日正向情感平均分在1月31日达到顶峰后逐渐回落。
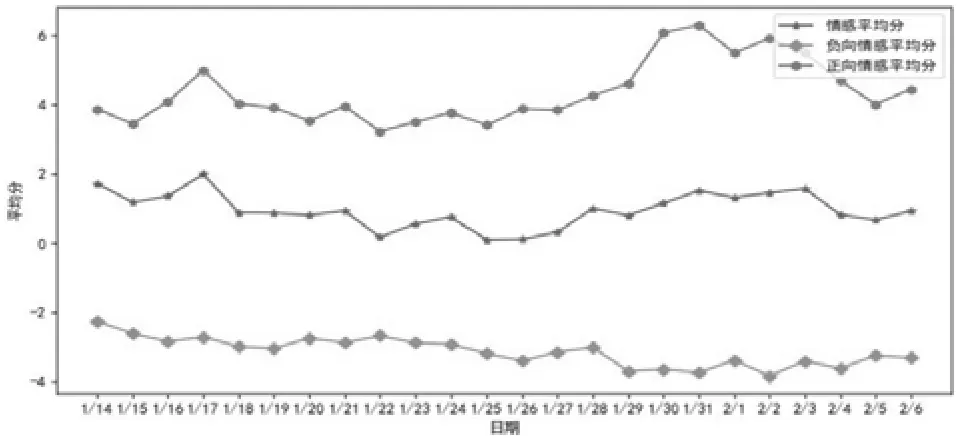
图3 平均情感得分图
每日正向博文和负向博文的点赞数、转发数和评论数如图4、图5、图6所示。从图中可以看出,正向博文的点赞数、转发数和评论数基本上都大于负向博文,尤其是1月21日正向博文的点赞数和评论数都远远高于负向博文,也高于其他日期。当日正好是除夕,网民会有更多的时间观看此剧,并对此剧进行评价。
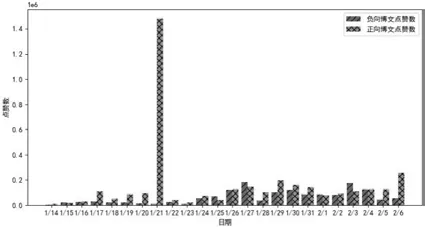
图4 每日正向博文和负向博文点赞数
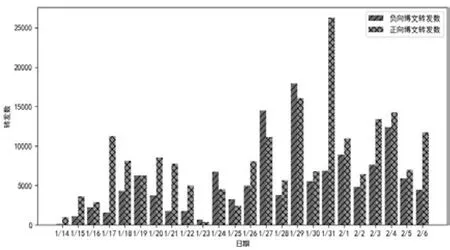
图5 每日正向博文和负向博文转发数

图6 每日正向博文和负向博文评论数
最后,使用词云图对文本中出现频率较高的关键词予以视觉化展示。在词云图中,词频越高的词语字体越大,如图7所示。通过图中我们可以看到,出现较高的关键词为剧名和剧中演员名字,说明网民在讨论时多次提到这些词语。其他频率较高的关键词集中在“真的”“好看”“好”等词语,说明网民对该剧的评价很高。

图7 关键词词云图
6 结语
本文使用爬虫爬取微博文本,在预处理后,使用SO-PMI算法在语料中筛选出情感新词,对BosonNLP词典进行了扩充,并选择频率较高的表情符号构建表情符号词典。使用构建的词典实现了情感分析,并使用可视化技术展现网民对热点事件的情感态度和情感值变化过程,展现了对博文中词频较高的词语。但是,分词的正确性会影响后续的情感极性计算,情感分析本身的主观性较强,会出现正话反说的场景,后续还需要继续研究情感词典的构建过程。
猜你喜欢
消费电子(2022年6期)2022-08-25
作文大王·低年级(2022年3期)2022-03-19
校园英语·月末(2021年13期)2021-03-15
疯狂英语·新阅版(2020年11期)2020-12-21
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小学生作文·小学低年级适用(2018年12期)2018-04-11
大作文(2016年7期)2016-05-14
校园英语·下旬(2016年2期)2016-03-18
Coco薇(2015年10期)2015-10-19
