
基于全卷积神经网络的医学图像语义分割研究进展综述
2023-11-13 07:10:20赵芝鹤杨婷婷
电脑与电信 2023年7期
于 营 赵芝鹤 杨婷婷
(1.三亚学院信息与智能工程学院,海南 三亚 572000;2.三亚学院陈国良院士团队创新中心,海南 三亚 572000;3.空军军医大学第三附属医院颅颌面整形与美容外科,陕西 西安 710000)
1 引言
医学图像分割是计算机视觉技术在智慧医疗中的重要应用,用于识别和提取医学图像中的特定结构或区域。医学图像分割通过自动或半自动地对医学图像中的像素进行分类,将图像分割成不同的有意义的区域,从而能够识别出图像中的器官、组织或病灶,在诊断和治疗过程中起着举足轻重的作用。常用的医学成像技术包括磁共振成像(Magnetic Resonance Imaging,MRI),计算机断层扫描成像(Computed Tomography,CT),X光检查(X-ray),皮肤镜成像(Dermoscopy)等,图1为不同成像方式得到的医学图像。由于成像原理和组织本身特性的不同,并且成像容易受到场偏移效应、局部体积效应、组织运动和噪声的影响,医学图像分割存在许多挑战。

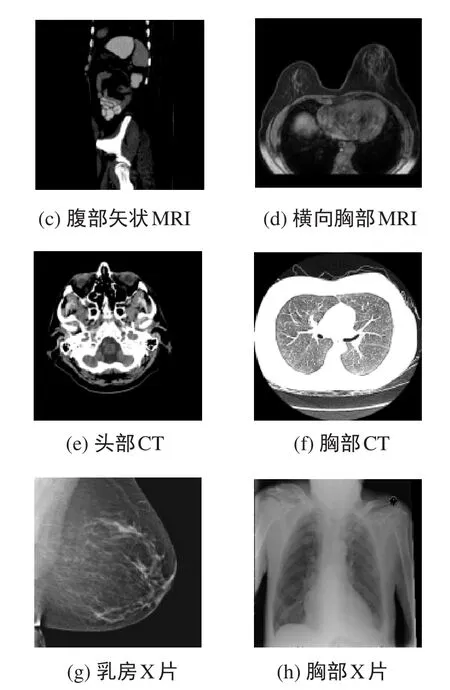
图1 不同成像方式的医学图像
器官分割和病灶分割是医学图像分割的两个主要应用。器官分割即识别器官的曲率或其内部ROI区域,以便定量地分析其状态,例如心脏分割和脑部分割;病灶分割的目的是通过精确地识别和定位病灶,为疾病的早期诊断、随访和治疗提供有效依据,如脑肿瘤分割等。针对医学图像中目标形状、位置和尺寸多变,部分组织结构成像差异小,以及部分组织边界模糊的难题,最新的解决方案通常为改进或优化已有的深度学习模型。在相关文献中,一些常用的CNN模型作为基础网络已经证明了其在医学图像分割上的有效性,如VGG[1]、ResNet[2]、U-Net[3]和Transformer[4]。另外,在相关数据较少的情况下可以使用迁移学习。
2 数据集
数据集是深度学习系统中最重要的部分之一。一个适当的数据集,首先应具有足够大的规模,样本均衡,具有细粒度标注,可以准确地表示系统的用例。数据采集往往需要专业的设备获取数据,并对这些数据进行选择和标注,这需要领域专业知识和大量时间。在研究中,通常使用现有的标准数据集,标准数据集对问题的领域有足够的代表性,方便在系统之间进行公平地比较。本节将介绍目前用于医学图像语义分割的最流行的大规模数据集,所有这些临床数据均为匿名并获得机构伦理批准。
2.1 BraTS
BraTS数据来自19家机构,使用不同的MRI扫描仪采集,是MICCAI脑肿瘤分割比赛指定的多模态3D颅脑MRI数据集,每个病例包含4种MRI模式,分别为T1、T1c、T2和FLAIR,标注为3个嵌套的肿瘤亚区,分别为WT(全瘤)、ET和TC(肿瘤核心)。训练集划分为低级别胶质瘤(Low-grade glioma,LGG)和高级别胶质瘤(high-grade glioma,HGG),每个病例是一个MR序列,包含155张图片,图片大小为240×240像素。
2.2 MM-WHS
MM-WHS(Heart Segmentation on Multi-Modality Whole Heart Segmentation Challenge)2017数据来自多个机构的120例多模态全心脏图像,包括60例心脏CT/CTA和60例覆盖整个心脏亚结构的3D心脏MRI。数据涵盖上腹部到主动脉弓的整个心脏区域,在轴向视图获取切片。其中,训练集包含20例CT和20例MRI图像,测试集包含40例CT和40例MRI图像。对于训练集,提供了7个全心脏子结构的手动标注,分别为:左心室血腔,标签值为500;左心室心肌,标签值为205;右心室血腔,标签值为600;左心房血腔,标签值为420;右心房血腔,标签值为550;升主动脉,标签值为820,肺动脉,标签值为850。由于视野的不同,升主动脉和肺动脉的范围在不同的扫描中会有所差别。
2.3 ACDC
ACDC(Automated Cardiac Diagnosis Challenge,自动心脏诊断挑战赛)的目标是,比较自动分割左心室心内膜和心外膜作为右心室心内膜在舒张末期和收缩末期情况下的性能,以及比较自动分类方法对正常、心力衰竭伴梗死、扩张型心肌病、肥厚型心肌病、右心室异常5类检查的分类性能。ACDC数据集是根据法国第戎大学医院(Hospital of Dijon)获得的真实临床检查创建的,数据来自150个病例,平均分为5个亚组(4个病理组与1个健康组),此外,病例数据还包含体重、身高以及舒张期和收缩期等附加信息。ACDC涵盖了几个定义明确的病理,有足够的病例,能够满足机器学习模型本地训练,也可以清楚地评估从MRI影像中获得的主要生理参数的变化,特别是舒张容积和射血分数。
2.4 CHAOS
CHAOS(Combined(CT-MR)Healthy Abdominal Organ Segmentation)挑战旨在从CT和MRI数据中分割腹部器官(如肝、肾和脾)。第一个任务为利用计算机断层扫描(CT)数据集对注射造影剂后门静脉期采集的肝脏图像进行分割,用于活体肝移植供者的预评估,采用的数据为包含40例不同患者的CT图像;第二个任务为从两种不同序列(T1-DUAL和T2-SPIR)获得的磁共振成像(MRI)数据集中分割腹部四个器官(即肝、脾、右肾和左肾),采用的数据包括来自两种不同MRI序列的120个DICOM数据集,其中,T1-DUAL序列有40个相位数据集,out序列有40个相位数据集,T2-SPIR序列有40个数据集,每一种序列均使用不同的射频脉冲和梯度组合扫描腹部。
2.5 ISIC
ISIC是常用的皮肤病或皮肤损伤数据集,包含恶性和良性的实例,每个实例均包含病变的图像,有关病变的元数据(包括分类和分割)以及相关患者的元数据。ISIC 2018和2019挑战赛的主要任务为对数千张皮肤镜图像的病灶分割、病灶归因检测和病灶分类。ISIC 2018包括2594张训练集图像(黑色素瘤占20.0%,痣占72.0%,脂油溢出性角化病占8.0%)、100张验证集图像和1000张测试集图像,用于特征提取和图像分割任务,以及10015张训练集图像和1512张测试图像用于分类任务,均为600×450像素。ISIC 2020对黑色素瘤分类,含2000多例患者进行33126次扫描的图像,以更好地支持皮肤科临床工作。
3 评价指标
分割效果常用Dice系数、豪斯多夫距离、Jaccard系数、灵敏性或特异性等指标来度量和评价[5]。
3.1 Dice系数
Dice系数(Dice Similarity Coefficient,DSC)是一种集合相似度度量,定义为预测区域A与标注区域B(ground truth)的重叠面积的两倍除以两幅图像的总像素数。公式如下:
3.2 豪斯多夫距离
豪斯多夫距离(Hausdorff Distance,HD)也称为最大对称表面距离(Maximum Symmetric Surface Distance,MSD),描述图像边缘点与最近的边缘点之间的最大距离。两个样本集合A和B的豪斯多夫距离定义为:
其中,h(A,B)是A到B的单向豪斯多夫距离,h(B,A)是B到A的单向豪斯多夫距离。
‖⋅‖是A和B之间的距离范式,如欧式距离、街区距离、棋盘距离等。双向豪斯多夫距离度量两个点集之间的最大不匹配程度,在语义分割任务中主要描述分割边界与实际标定边界的差异性。
3.3 Jaccard系数
Jaccard系数(Jaccard Index,or Jaccard Similarity Coefficient,JSC),又称交并比(Intersection over Union,IoU),在语义分割任务中表示预测掩码与真实标记像素的交叠率。平均交并比(mean-IoU,mIoU)是计算每个类别中IoU值的算术平均值,用于描述总体数据集的像素重叠情况。计算公式分别如下:
3.4 敏感性与特异性
敏感性(Sensitivity),即真阳性率(True Positive Rate,TPR),表示系统对阳性样本的敏感度。特异性(Specificity),即真阴性率(True Negative Rate,TNR),表示非目标元素(背景)被正确地识别出来的能力。
此外,在一些医学图像挑战赛中使用其他指标来度量预测结果与真实值之间的差异,如平均表面距离(Average Surface Distance,ASD)和体积距离(Volumetric Distance),它们是医学图像分割竞赛CHAOS(Combined Healthy Abdominal Organ Segmentation)中的指定的评估指标。
4 模型和关键技术
根据分割原理的不同,医学图像分割方法可以分为四代,如图2所示。
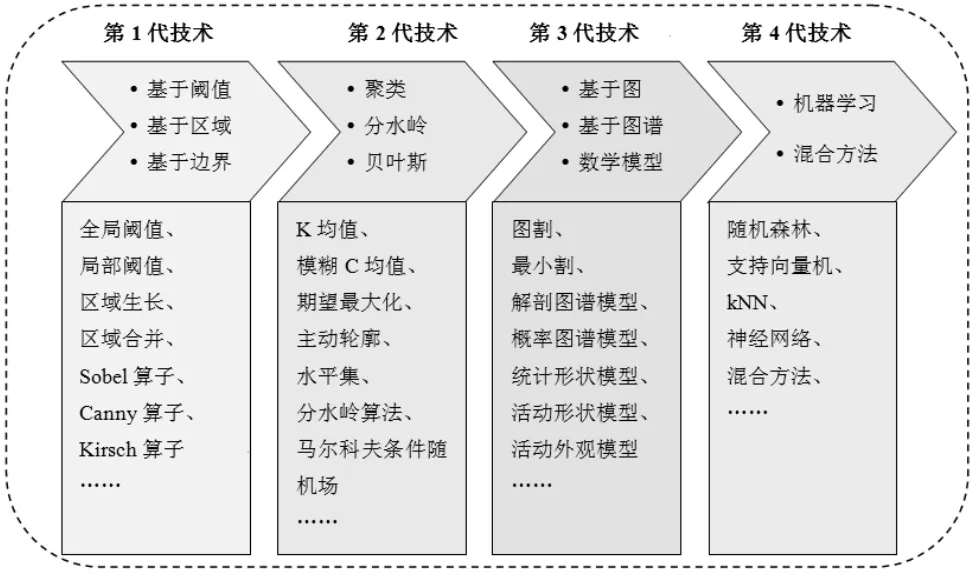
图2 图像分割方法分类
全卷积神经网络(Fully Convolutional Networks,FCN)[6]首次将深度学习方法用于图像分割,作为深度学习语义分割的开山之作,以端到端的工作方式,依据卷积运算的稀疏连接性、参数共享以及平移不变性实现了自动、快速的特征提取,成功应用于医学图像分割、病灶区域定位、细胞检测、异常检测等方面。
4.1 “编码——解码”架构
采用全卷积神经网络进行医学图像分割的主要思想是基于“编码——解码(Encoder-Decoder)”架构设计分割网络,如图3所示。
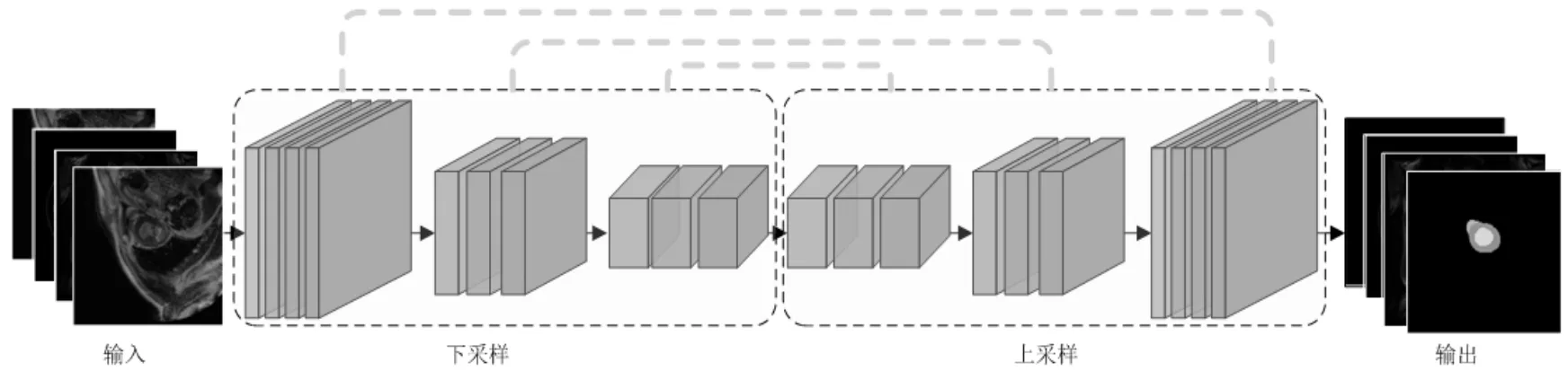
图3 “编码——解码”架构
“编码——解码”结构在U-Net[3]网络中提出,它在下采样过程中学习医学影像数据集中高级语义信息,然后对图像的每个像素进行分类预测。SegNet[7]采用最大池化索引(maxpooling indices)进行上采样,减少了端到端训练的参数量,在减少内存和提高计算效率的同时,改善了边界划分质量。全卷积神经网络不受图像大小限制,不需要对图像进行切块处理,可以单阶段地直接获得整个分割结果。
4.2 空洞卷积
空洞卷积(Atrous Convolution),也称膨胀卷积或扩张卷积(Dilated Convolution),简单来说就是在卷积核元素之间加入一些空格(零值)来扩大卷积核的感受野(Receptive Field)且不改变图像输出特征图的尺寸。
DeepLab v3+[8]是一种基于Encoder-Decoder结构的改进模型,采用了可分离卷积和空洞卷积来提高分割性能。可分离卷积可将传统的卷积操作分解为深度卷积和逐点卷积两个步骤,以减少参数数量和计算量。空洞卷积则可扩大感受野并保留图像的空间分辨率。这两种技术的结合使得Deep-Lab v3+能够在保持高分辨率的同时具有更大的感受野和更强的上下文信息。
4.3 注意力机制
注意力机制(Attention Mechanism)这一概念源于人的视觉机制。在观察目标时,人们通常有选择性地关注某些区域。在视觉任务中,对一张图像K使用注意力机制计算其中的重点关注区域,需要一个查询向量q,通过一个打分函数计算q和每个像素的值ki之间的相关性,得到一个分数。接下来对这些分数进行归一化处理,归一化后的结果即为q在每个ki上的注意力分布,根据这些注意力分布可以去有选择性地从图像中提取特征信息。
U-Net++[9]是一种基于U-Net架构的改进模型,通过引入嵌套的U-Net(Nested U-Net)结构和注意力门控(Attention Gates)来提高分割性能。具体来说,嵌套U-Net结构在编码器和解码器中分别增加了多个U-Net模块,使模型具有更强的多尺度信息处理能力。同时,注意力机制可用于自适应地选择重要的特征图以提高模型的精度和效率。
Attention U-Net[10]是一种基于U-Net架构的改进模型,通过引入注意力机制来提高胰腺分割性能。该模型在编码器和解码器的每个U-Net模块中都增加了一个注意力门控单元,以使模型能够自适应地选择关键的特征图。此外,该模型还采用了一种渐进的训练策略,以缓解数据不平衡和样本噪声的问题。
4.4 残差连接
残差连接(Residual Connections)是在ResNet[2]中提出的一种用于编码器内部的跳跃连接,可以有效地缓解深度神经网络随着深度增加而带来的退化问题。
MultiResUNet[11]是一种基于U-Net架构的改进模型,通过引入多分辨率分支以及残差连接来提高分割性能。该模型将输入图像分别缩放为不同的分辨率并在编码器和解码器中分别使用多个U-Net模块来处理不同分辨率的特征图。此外,残差连接可以加速梯度收敛效率,以提高模型的稳定性和收敛性。
4.5 迁移学习
从同一领域(甚至其他领域)中已验证的性能较好的模型中进行迁移学习(Transfer Learning),通过删除某些层或增加某些层,可以在训练样本不足的情况下获得更好的分类效果。Tajbakhsh等人[12]通过对放射学、心脏病学和消化病学中四个不同的医学成像应用,涉及来自三种不同成像模式(CT、超声、光学内镜)医学图像的分类、检测和分割,并研究了从头训练的深度CNN与以分层方式微调的预训练CNN的性能的差异性。被迁移的模型可以是在一般图像上预训练的网络,也可以是在医学图像上预训练的网络,对这些网络进行微调,以适应不同的目标分割或分类任务。在源网络和目标网络的任务比较相似时,迁移学习可以获得更好的性能。
表1中总结了近年来医学图像分割领域中使用全卷积神经网络及其变体的相关研究。
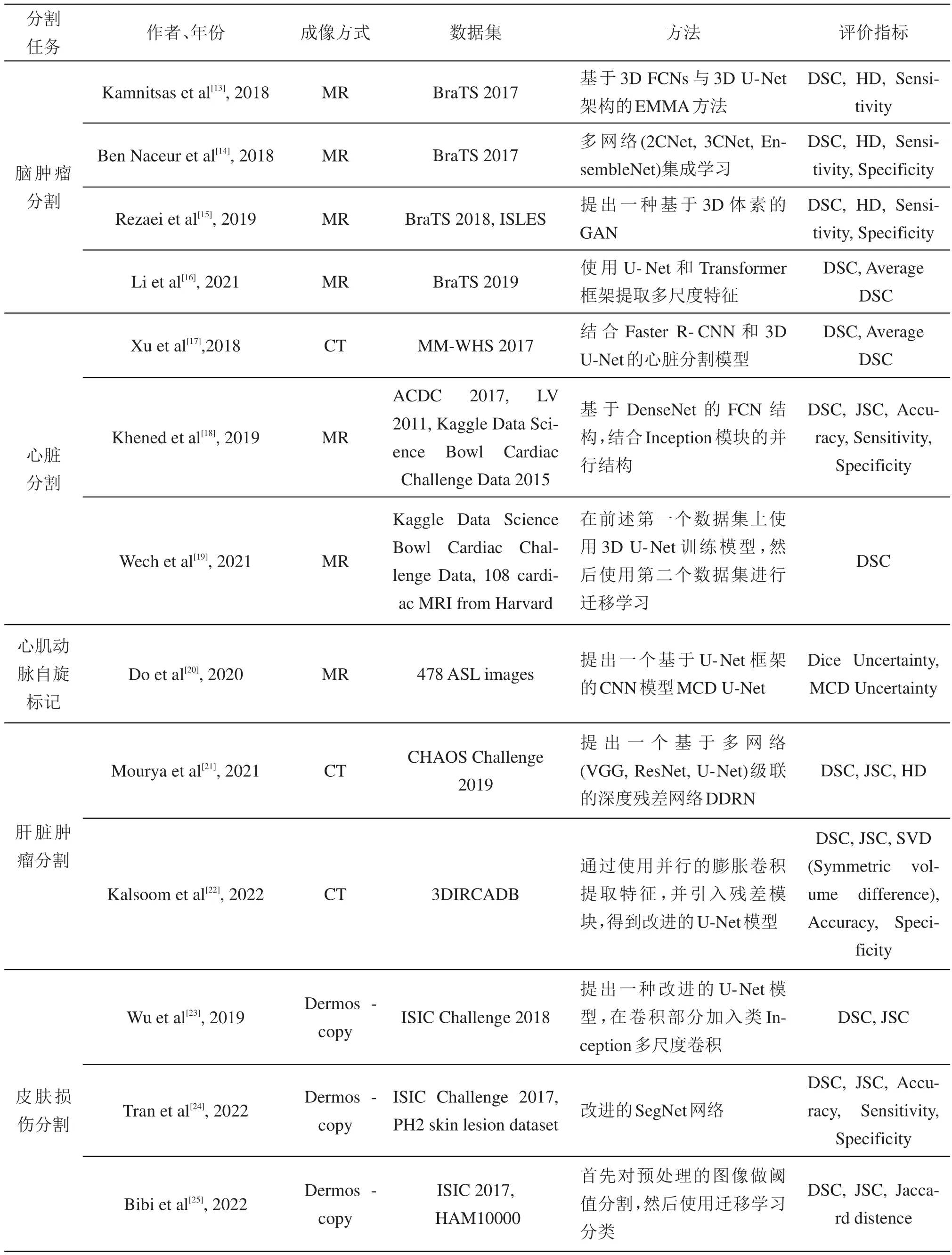
表1 医学图像分割研究总结与比较
5 存在的挑战
虽然医学图像分割这一领域已经取得了显著的进展,但仍然存在一些尚未解决的问题。
5.1 多模态图像融合
在许多应用中,需要将不同类型的医学图像(如CT、MRI、PET等)融合在一起进行分析,以获得更加准确、丰富的特征。融合这些图像的特征,在它们之间保持准确的空间对应关系仍然是一个挑战。
5.2 异质性和变异性
组织和病变可能具有显著的形态学和信号强度变异性,这使得基于图像特征的分割方法变得复杂。采用多时相数据融合的特征提取方法,可以有效地解决这个问题。但是,由于目前开源的多时相数据集较少,相关研究仍处于早期阶段。
5.3 数据标注准确性
目前医学图像的标注往往依赖于医学专家的认知和经验,这种方式不可避免地带来一些主观因素导致的误差。因此,使用深度学习算法辅助或替代医学专家做出诊断付诸实践的过程中还存在很多风险,现有的方法也远远无法胜任医学图像分割中存在的复杂情况。弱监督、无监督方法的不断完善和优化可以很好地弥补这个问题。
5.4 数据不足和数据不平衡
对于一些罕见疾病或特定场景,可能缺乏足够的带有标注的医学图像数据来训练高效的分割模型。此外,数据不平衡也可能导致模型在某些类别上的性能不佳。这个问题的解决方案之一是对样本进行加权,在训练时对前景对象应用更高的权重;或者利用Dice损失和Dice系数,实现对样本加权的自动修正。然而,在样本极端阶级不平衡的情况下,这些方法所带来的优化效果并不明显。图像分割中的数据不足和不平衡问题仍是一个有价值的研究课题。
5.5 三维图像处理
许多医学图像是三维的,处理这些大规模数据会带来计算和存储方面的挑战。不可否认,较长的推理时间以及高昂的计算成本是三维图像处理研究和应用的重大阻碍。使用排除策略剔除不太可能包含目标器官的区域,可以有效缩小搜索空间,从而实现更快的推理。
5.6 实时性和计算效率
在某些应用场景中,如手术导航和实时诊断,需要实时的图像分割。提高分割方法的计算效率仍然是一个关键问题。轻量化语义分割网络研究致力于减少模型参数,减少内存和训练时间,但模型参数和准确性之间的平衡需要更多的研究去验证。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
动漫星空(兴趣百科)(2020年12期)2020-12-12 05:31:42
作文小学中年级(2020年6期)2020-07-24 08:33:10
祝您健康(2020年4期)2020-05-20 15:04:20
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
新校长(2016年5期)2016-02-26 09:29:01
科学中国人(2015年13期)2015-02-28 09:13:00
电视技术(2014年19期)2014-03-11 15:38:20
