
基于改进YOLOv4-Tiny的交通车辆实时目标检测
2023-11-13 01:37:42杨志军昌新萌丁洪伟
无线电工程 2023年11期
杨志军,昌新萌,丁洪伟
(1.云南大学 信息学院,云南 昆明 650500;2.云南师范大学 教育部民族教育信息化重点实验室,云南 昆明 650500;3.云南省教育厅 教学仪器装备中心,云南 昆明 650223)
0 引言
交通车辆检测是智能驾驶领域的核心技术之一,可为自动驾驶整体系统提供有效的数据保障。因此,设计强实时性与准确性的交通车辆目标检测算法具有重要的现实意义。
近年来,基于深度学习的交通车辆目标检测算法受到越来越多的关注。2012年,Krizhevsky等[1]将CNN用于图像领域,推动了深度学习在图像领域的应用。目前,基于深度学习的目标检测算法主要分为双阶段目标检测算法和单阶段目标检测算法[2]。在双阶段目标检测算法中,具有代表性的是R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]和SPP-Net[6]等,双阶段目标检测算法首先生成感兴趣区域,然后对感兴趣区域进行分类和定位,具有较高的检测精度,但实时性较差,无法满足自动驾驶对车辆检测速度的要求。单阶段目标检测算法主要有SSD[7]、RetinaNet[8]、EfficientDet[9]和YOLO[10]等,单阶段的目标检测算法不再提取候选区域,直接将待检对象输入网络,在输出网络中得到待检对象的目标边界框和类别信息,处理速度快,能够满足车辆检测的实时性要求。严开忠等[10]通过对YOLOv3的改进,提升了目标检测的速度,但精度下降;Bochkovskiy等[11]提出了YOLOv4,在检测速度和检测精度上有明显提升;2020年6月,Bochkovskiy提出了YOLOv4-Tiny算法模型,模型检测精度虽有下降,但检测速度大幅提升。
为了满足自动驾驶中对交通车辆检测实时性的需求,本文提出了一种改进的YOLOv4-Tiny交通车辆实时检测模型。该模型以YOLOv4-Tiny模型为基础,对YOLOv4-Tiny算法中的特征金字塔网络(Feature Pyramid Network,FPN)、空间金字塔池化(Spatial Pyramid Pooling,SPP)层等进行改进,同时引入注意力机制。实验表明,提出的模型在提升准确率的同时保证了实时性,且降低了模型的大小。
1 YOLOv4-Tiny模型概述
YOLOv4-Tiny是一种基于YOLOv4的轻量化目标检测模型,相较于YOLOv4,检测精度略有下降,但检测速度提升明显,参数量仅为YOLOv4的1/10,降低了对硬件的要求,使其可以适用于可移动设备和嵌入式系统等。
1.1 YOLOv4-Tiny网络结构
YOLOv4-Tiny由输入、主干、网络和预测四部分组成。输入部分负责图片的输入;主干部分使用CSPDarkNet53-Tiny网络替代YOLOv4中的CSPDarkNet53网络,负责特征提取;网络部分包含CBL(Conv2D_BN_LeakyReLU)等负责上下采样;预测部分获取由网络部分提取的特征图。
残差模块跨阶段部分连接(Cross Stage Partial Connection,CSP)由CSPNet构成,CBL模块主要由卷积处理层Conv、归一化处理层BN以及激活函数层LeakyReLU组成。以输入图像的尺寸(416,416,3)为例,输入图像在主干部分采用不同尺度的CSP层进行下采样,获得3个不同尺度的特征图;再经过网络层处理,将深层特征提取后进行上采样(Upsample)与浅层特征进行拼接(Concat),得到不同尺度的特征图,增加了特征图的感受野;最后,预测部分对输入的不同维度特征进行解码,解码的格式为:3×(5+class),其中3表示先验框数量,5表示预测边界框信息,class表示分类总数,得到目标检测结果。YOLOv4-Tiny网络结构如图1所示。

图1 YOLOv4-Tiny网络结构Fig.1 YOLOv4-Tiny network structure
1.2 SPP
He等[6]在2015年提出SPP结构,将空间金字塔匹配集成到CNN中,并采用最大池化层代替bag-of-words层。Bochkovskiy等[11]介绍了SPP是一组特殊模块的概念,可用于增强网络的感受野。使用SPP结构可以有效避免由图像区域裁剪和缩放操作导致的图像失真等问题,且解决了CNN对图像相关特征重复提取的问题,极大地提高了产生候选框的速度,降低了计算成本。其结构如图2所示,计算方式如下:
式中:w为输入尺寸,n为输出尺寸,k为池化窗口尺寸,s为步长,p为边距,「⎤和⎣」分别为向上取整和向下取整。
图2中,k表示池化核的大小,s表示步长。SPP将特征层分别通过一个池化核大小为5×5、9×9和13×13的最大池化层,然后在通道方向进行拼接以进一步融合,在一定程度上解决了目标多尺度问题。

图2 SPP结构Fig.2 SPP structure
在YOLO网络中,SPP可以处理宽高比和尺寸不同的输入图像,提升图像尺度不变性的同时降低过拟合,并且训练图像尺寸的多样化有利于训练过程的收敛。通过SPP模块实现局部特征与全局特征的融合,丰富特征图的表达能力,对于复杂的多目标检测有较大的精度提升。
1.3 FPN
2017年Lin等[12]提出特征金字塔结构,FPN解决了目标检测中的多尺度问题,通过简单的网络连接变换,在基本不增加原有模型计算量的情况下,大幅提升了小目标检测的性能,其网络结构如图3所示。

图3 FPN结构模型Fig.3 Structure model of FPN
图3中,Conv2d表示卷积,s表示步长。每一个特征图经过1×1卷积层的处理,对不同特征图的通道数进行调整,以保证融合时通道数相同;对高层特征进行2倍上采样,保证与下一层特征图的尺寸大小相同;经上述处理后,上一层与下一层特征图的形状完全相同,可进行相加操作。
以ResNet50作为主干为例,对于每个残差模块激活后的特征输出,可以将其表示为:
Ni=fi(Ci-1)=fi{fi-1[…f1(K)]},
(3)
式中:i={2,3,4,5}表示特征层数,K和f分别表示输入的图形和相应的卷积操作。

Mi=w(Ni,Ni+1)=f3×3{f1×1[Ni]+f1×1[p(Ni+1)]},
(4)
式中:p表示深层特征上采样操作,w表示相邻特征的融合操作,3×3和1×1表示卷积核的尺寸。
2 YOLOv4-Tiny算法的改进
2.1 CSPResNet模块改进
YOLOv4-Tiny使用3个CSPResNet模块提取模型中间部分的特征,将梯度变化集成到特征图中,降低了目标检测任务对计算成本的依赖。但YOLOv4-Tiny中部分卷积层使用了512个卷积核,导致模型参数较多,降低了模型的检测速度,不利于交通车辆的实时检测。
为了降低模型的计算量,将YOLOv4-Tiny中CSPResNet模块卷积核的数量减半,并将CSPResNet模块两端的卷积核大小改为1×1,极大地减少了模型的计算量和大小,但会导致精度的损失。为了尽可能地降低参数量并提高模型的精度,在CSPResNet模块中使用空洞卷积(Dilated Convolution),在不损失特征图尺寸的情况下增大了感受野。CSPResNet结构如图4所示。

(a)原CSPResNet结构

(b)修改后CSPResNet结构

(c)本文CSPResNet结构
2.2 SPP的改进
YOLOv3重新设计了SPP为SPP-YOLO[12],使用SPP-YOLO后,YOLOv3在MS COCO数据集上的AP50提高了2.7%,而只额外增加了0.5%的计算量。YOLOv4同样使用SPP-YOLO模块,模型性能超越YOLOv3,达到SOTA级别的物体检测表现。为了减少参数量,Scaled-YOLOv4[13]采用CSP-SPP跨阶段执行下采样卷积操作。
以上改进的SPP结构虽然可以提高目标检测模型的性能,但这些结构是为具有大量参数的大规模目标检测模型而设计,不适合交通车辆的实时目标检测。为了减少模型的计算量,使模型能够部署在资源有限的交通车辆设备上,本文重新设计了CSP-SPP并提出CSP-SPPx,其结构如图5所示。
图5中,route表示特征矩阵按维度、元素相加,k表示池化核的大小。CSP-SPPx删除了一个1×1卷积层和一个3×3卷积层,与CSP-SPP相比,模型参数量大幅减少,与CSP-SPP以route方式融合3个不同尺度的最大池化层的输出特征不同的是,CSP-SPPx以捷径分支方式融合3个不同尺度的最大池化层的输出特征,因此,CSP-SPPx输出特征的通道数是CSP-SPP的1/3,有效减少了模型的计算量,有利于将模型部署在资源有限的交通车辆设备上。

(a)CSP-SPP

(b)CSP-SPPx
2.3 特征金字塔的改进
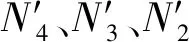
为了减少模型的推理时间,YOLOv4-Tiny仅采用自下而上的结构,无法将重要的深层特征和浅层特征进行融合。交通车辆在行驶过程中,存在遮挡及路况复杂等情况,若不能实时且准确地对相关物体进行检测,交通车辆在自动驾驶时将带来极大的安全隐患。本文对YOLOv4-Tiny网络结构的FPN进行改进,设计TFPN结构,在参数量和计算量较少的情况下显著提升模型的性能,其整体结构如图6所示。

图6 TFPN整体结构Fig.6 Overall structure of TFPN
自下而上的路径是TFPN的前馈计算网络层,将其表示为{c1,c2,c3}。为了聚合特征的空间信息并关注更细节的特征,同时使用最大池化(MaxPool)和平均池化(AvgPool),通过MaxPool和AvgPool聚合特征图的空间信息,生成2个不同的空间特征Fm1和Fα1,将特征融合后输入到卷积层,进一步减少模型的参数,最后输入到下一个MaxPool和AvgPool,以此得到更细化的特征。丰富的特征信息,使交通车辆能够做出更加准确的判断,避免事故的发生。
图6中,route表示特征矩阵按维度、元素相加。在FPN中,最高层的特征自上而下传递,与低层特征融合,利用深层特征的语义信息增强低层的特征映射,减少由特征通道造成的信息丢失,但此结构并不适合实时的交通车辆检测。基于FPN的这些特征,提出的TFPN结构采用了池化特征增强的方法,其中,池化特征增强的具体结构如图7所示,其计算可以表示为:
Fout=σ(FConv1×1(Fα2)+FConv1×1(Fm2))。
(5)
池化特征增强模块使用2个大小为1×1的卷积层和池化层,包括一个MaxPool和一个AvgPool。利用MaxPool操作和AvgPool操作,使输入特征图生成2种不同的语义信息,为了保证维度一致,在AvgPool操作后进行上采样操作,之后将2种类型的语义信息传递到同一个卷积核大小为1×1的网络中以产生更深层次的语义特征。通过池化特征增强模块,模型获取了更丰富的特征信息,能够更好地识别被遮挡的车辆信息,提高了交通车辆实时检测的准确性。

图7 池化特征增强PFA结构Fig.7 PFA structure improved by pooling feature
2.4 注意力机制
减少YOLOv4-Tiny的参数量虽然降低了计算量,但也减弱了模型的特征提取能力,降低了交通车辆实时检测的性能。注意力机制自从被提出后,在深度学习领域得到了快速发展,如SE-Net[15]、CBAM[16]、ECA-Net[17]、EPSANet[18]和GCNET[19]等。为了使模型能够更好地关注通道和空间特征,在模型中添加通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)[20]。Woo等[16]提出的CBAM模块结合了CAM和SAM,其性能较仅使用CAM或SAM有明显提升。为了使模型能够更好地关注交通车辆的特征,对CBAM模块进行改进,并提出新的RCBAM模块,其结构如图8所示。
图8 RCBAM模块Fig.8 RCBAM module
输入I∈RC×H×W,CBAM的特征图I先通过一维通道CAM,BC∈RC×1×1,之后通过二维的SAM,BS∈RC×H×W,CBAM的操作表示如下:
O=I⊗BC(I)⊗BS(I⊗BC(I)),
(6)
式中:O是输出特征,⊗表示逐个元素相乘。

(7)

图9 CAMFig.9 CAM
SAM是CAM的细化,其结构如图10所示。SAM使模型对特征的关键区域更加关注,本文SAM首先将CAM的输出输入到MaxPool层和AvgPool层,获取特征图的通道信息,为了保持特征图的维度一致,在SAM中添加上采样层,之后,通过卷积层对特征进行处理和卷积,最后在通道中进行合并,生成一个有效的二维空间特征区域,SAM的计算过程如下:
(8)
式中:σ表示sigmoid函数,F3×3表示3×3的卷积操作。
改进后的YOLOv4-Tiny网络结构如图11所示。图11中,route表示特征矩阵按维度、元素相加。

图10 SAMFig.10 SAM
3 实验结果
3.1 实验环境
本实验的环境配置如表1所示,对比实验的硬件配置与该实验的配置相同。
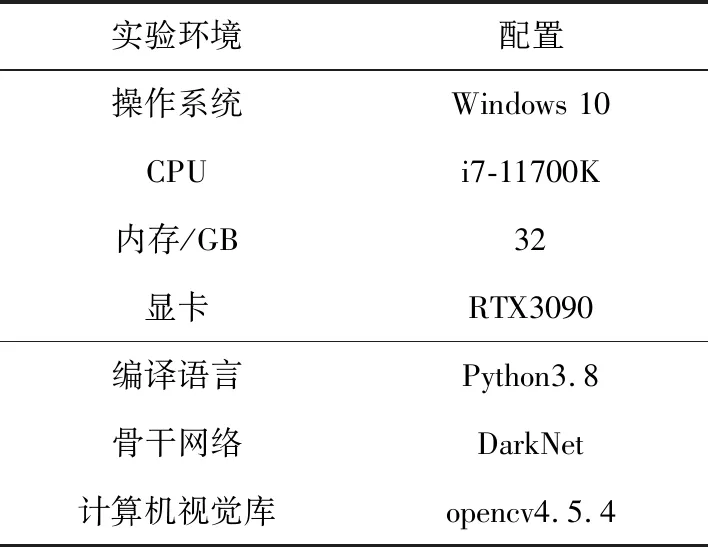
表1 实验环境配置Tab.1 Experimental environment configuration
本实验车辆图像来自kaggle的交通车辆目标检测数据集和网络收集标注,共1 600张,其中70%为训练集,30%为验证集,以上数据均采用LabeIimg标注。
模型的默认输入图像大小为416 pixel× 416 pixel,初始阶段的batch size设置为32,初始学习率设置为0.001 4,共迭代3 000次。
3.2 YOLOv4-Tiny算法改进前后对比
将本文改进的YOLOv4-Tiny算法与原YOLOv4-Tiny算法进行对比,以平均精度均值(mean Average Precision,mAP)、FPS、Model size作为评价指标,其对比结果如表2所示,输入图像尺寸统一为416 pixel×416 pixel。mAP可用来评价模型中每一类别的好坏,Recall用来评估模型是否漏检,计算公式如下:
式中:p表示准确率,r表示召回率,以准确率和召回率分别作为纵轴和横轴,对pr曲线与坐标轴围成的区域积分,得到平均准确率 (Average Precision,AP),再对AP取平均得到mAP;TP为真正例,FN为假反例。
由表2可知,原YOLOv4-Tiny算法的精度较低、处理速度较慢且模型较大,与原YOLOv4-Tiny算法相比,本文改进的YOLOv4-Tiny算法的mAP值提高了4.67%,图片处理速度也有一定提升,模型大小仅为原模型大小的47.26%。从模型整体性能而言,本文改进的YOLOv4-Tiny算法更优。

表2 原YOLOv4-Tiny算法与本文改进YOLOv4-Tiny 算法对比结果
3.3 与其他算法的对比
为验证可行性,将本文改进的YOLOv4-Tiny算法与Faster R-CNN、YOLOv3-Tiny、YOLOv4-MobileNet v3[16]、YOLOv5s和YOLOv4进行对比,以mAP、FPS和Model size作为评价指标,实验结果如表3所示。

表3 本文改进的YOLOv4-Tiny算法与其他算法的对比结果Tab.3 Improved YOLOv4-Tiny algorithm compared with other algorithms
由表3可以看出,本文改进的YOLOv4-Tiny算法在FPS和Model size指标上有明显优势,相比YOLOv4,YOLOv4-Tiny在特征提取阶段未采用Mish激活函数,删除部分卷积结构,在特征加强层仅采用一个特征金字塔等,从而大大加快检测速度并降低模型的大小,但由于提取的特征信息不够丰富,导致其检测精度低于YOLOv4。本文对YOLOv4-Tiny进行改进后,FPS是YOLOv4的2倍多,Model size仅为YOLOv4的1/23,满足车辆检测对精度和实时性的要求。
Faster R-CNN是双阶段目标检测算法,先生成感兴趣区域,然后对感兴趣区域进行分类和定位,其图像处理速度远低于单阶段目标检测算法且模型较大。与上一代YOLOv3-Tiny算法相比,虽然都采用DarkNet作为骨干网络,但YOLOv3-Tiny在训练过程中仅使用了上采样,而未使用下采样,是导致其mAP较低的原因之一。YOLOv4-MobileNet v3采用MobileNet v3作为主干网络,其mAP值较YOLOv3-Tiny有较大提升,但其模型大小呈倍数增加,图像处理速度下降。YOLOv4同样采用DarkNet作为主干网络,虽然取得了较高的mAP值,但其训练复杂度高且模型大,不适合部署于空间有限的轻量级设备。YOLOv5s在维持精度和FPS的同时,降低了模型的大小,综合mAP、FPS、模型大小来看,本文改进的YOLOv4-Tiny算法有较好的性能。
与主流的轻量级检测算法YOLOv3-Tiny、YOLOv4-MobileNet v3、YOLOv5s相比,本文改进的YOLOv4-Tiny算法的mAP均有提升,且模型大小及处理速度均是最优的,同时满足了车辆检测对精度和实时性的要求,但模型大小仍有改进空间。
3.4 消融实验
为验证本文改进的YOLOv4-Tiny算法的有效性,进行了消融实验。输入图像尺寸为416 pixel×416 pixel,骨干网络为DarkNet,每次试验只改变一个变量,实验结果如表4所示。

表4 本文改进的YOLOv4-Tiny算法消融实验结果Tab.4 Ablation experiment results of improved YOLOv4-Tiny algorithm
由表4可以看出,在YOLOv4-Tiny中使用CSPResNet和CSP-SPPx后,虽然模型的mAP提升较小,但通过剪枝操作后,模型的参数数量下降,模型大小减小及处理速度明显提升。采用TFPN模块后,模型的大小增加,在增加少量计算量的情况下,改进后的模型精度有较大的提升而不影响模型的实时性。引入注意力机制后,模型的大小增加且FPS略有下降,这可能是改进后的算法增加了模型的运算复杂度,导致了模型大小的增加和处理速度的下降。
通过消融实验,证明了本文对YOLOv4-Tiny算法的改进是有效的,能够满足车辆检测对精度和实时性的要求。
4 结束语
在YOLOv4-Tiny的基础上,通过对CSPResNet、SPP和FPN的改进,同时引入新的注意力机制,减少了YOLOv4-Tiny的参数量,提升了计算速度,并提高了准确率。本文提出的TFPN结构和CSP-SPPx结构只需少量计算即可提高模型的性能,适用于轻量级目标检测网络,与原YOLOv4-Tiny相比,本文模型的精度和处理速度均有较大提升,能够满足车辆检测对精度和实时性的需求。与其他轻量级目标检测算法相比,提出的改进YOLOv4-Tiny算法性能最优,证明了本文改进方法的有效性和可行性。最后通过消融实验验证了本文改进方法的科学性。
提出的改进YOLOv4-Tiny算法在性能上有了较大的提升,但车辆行驶过程中存在遮挡及复杂路况,模型仍存在误检和漏检的情况,后续将优化网络结构以提高对此种情况的检测。模型训练需要大量标注好的样本,对样本的大量标注耗时耗力,之后将利用半监督学习的方式,使用较少的已标注样本,达到较好的训练效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年11期)2018-08-04 03:25:38
小太阳画报(2018年3期)2018-05-14 17:19:26
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
阅读与作文(小学低年级版)(2016年12期)2016-12-22 19:35:04
少年博览·小学低年级(2016年9期)2016-11-24 06:21:37
测绘科学与工程(2016年5期)2016-04-17 06:51:15
汽车文摘(2015年11期)2015-12-02 03:02:53
电子设计工程(2015年3期)2015-02-27 12:03:45
