
基于通道注意力机制与金字塔池化的包裹破损检测算法
2023-11-13 01:37:34周耀威孔令军李慧刚郭乐婷杨文杰陈一品张栋濠
无线电工程 2023年11期
周耀威,孔令军*,李慧刚,郭乐婷,杨文杰,陈一品,张栋濠
(1.金陵科技学院 网络与通信工程学院,江苏 南京 211169;2.浙江舟山群岛新区旅游与健康职业学院 科研与社会服务处,浙江 舟山 316111)
0 引言
包裹破损检测技术是智慧物流体系中重点研究的方向之一,对物流运输效率和包裹运输质量有着至关重要的作用。尽管包裹破损检测已经取得了一些显著的成果,但要在实际的检测场景中精确且快速地检测出破损包裹仍然存在着许多不足:① 检测到小体积包裹时,破损特征更加不明显,很容易造成误识别的现象[1];② 随着物流行业的兴起,包裹数量呈指数级增长,从而使得检测需要消耗大量的时间,影响物流速度[2]。
目前包裹破损检测主要分为2类:基于人工设计特征提取的包裹破损检测和基于深度学习的包裹破损检测。传统的人工设计特征提取的检测方法是指通过人工设计的特征来进行计算机实时检测,将检测目标与该特征进行比对,从而反馈检测结果,有着较好的实时性。然而环境的变化和场景的不同会导致识别准确率相差甚远,具有很强的局限性。因此,随着深度学习技术的快速发展以及目标检测算法的不断创新,基于深度学习的包裹破损检测技术[3]由此兴起。
基于深度学习的特征提取是指通过卷积神经网络自主地学习图像的特征提取[4],目标检测的精度有了极大的提升。目前,通用的目标检测算法主要分为两大类:Two-stage算法和One-stage算法。前者先进行区域生成一个可能包含待检测物体的预选框(Region Proposal,RP),再通过卷积神经网络进行样本分类。此类算法虽然具有很高的精确度,但在面对一些小目标时,效果相差甚远,同时实时性也很差,因此适用于检测高精度的大目标,代表算法有R-CNN[5]、SPP-net[6]、Faster R-CNN[7]等。另一类算法是不用RP,直接在网络中提取特征来预测物体分类和位置。此类算法的实时性高,在检测堆积目标和小目标时精度较低,因此适用于实时目标检测。代表算法有YOLO[8]、SSD[9]、Retina-Net[10]等。
近几年,由于目标检测技术的盛行,越来越多的目标检测算法经过改良后有着非常不错的速度与精度提升[11]。文献[12]提出了在目标检测框架YOLOv5s的基础上引入基于通道的Transformer注意力机制以及SE注意力机制优化检测器,使得检测精度有了一定的提高。文献[13]提出了基于ResNet神经网络模型来构建包裹缺陷检测系统,随着网络的深度增加,能够提高准确率。文献[14]提出了通过修改Faster R-CNN算法中的损失函数,使用RepGT损失函数代替,使得包裹检测候选框更接近目标框,识别精度提高。文献[15]提出了一种改进的SSD目标检测算法,通过改进ResNet-50网络并引入了ECANet通道注意力机制,使得检测精度均值达到了99.8%。文献[16]提出了一种改进的CenterNet目标检测算法,使用HRNet替代算法中的Hourglass-104主干网络,通过降低参数量来提高模型的推理速度,引入注意力机制来提高检测精度。文献[17]提出了一种可部署于移动端的轻量级卷积神经网络算法YOLOv3_M,使用ISODATA动态聚类算法对BDD与KITTI混合数据集聚类分析找出更适合目标的Anchor Box,使用MobileNetv3-Large网络代替原始YOLOv3网络中的特征提取网络DarkNet53,该算法与开源框架YOLOv3相比在降低参数量的同时提高了检测速度与检测精度。
基于以上研究可以发现,轻量级网络模型除了有着较高的检测速度外,还需有着较高的检测精度[18],同时模型大小与参数量都必须控制在一定的范围内,进一步体现了对模型简化程度的追求,从而有利于边缘计算设备[19]部署。
为此,本文针对自然场景下包裹破损检测耗时过长的问题,提出了一种提高检测速度的轻量级包裹破损检测模型,算法在YOLOv5s的基础上进行改进。改进思路如下:① 使用ShuffleNetV2[20]作为轻量级主干网络来降低模型复杂度,从而提高模型检测速度;② 融合通道注意力机制SE[21]模块减少卷积神经网络对图像相关特征的重复提取,提高信息表征能力,从而提高轻量级优化后模型的检测精度;③ 利用快速空间金字塔池化(Space Pyramid Pool-Fast,SPPF)在不同尺度的特征图上进行特征提取,有效减少漏检与误检,进一步提高了模型对多尺度目标检测的精度。
1 算法框架设计
1.1 整体网络结构
本文使用ShuffleNetV2作为轻量级模型来构建YOLOv5s目标检测框架的主干网络,整个网络结构如图1所示。
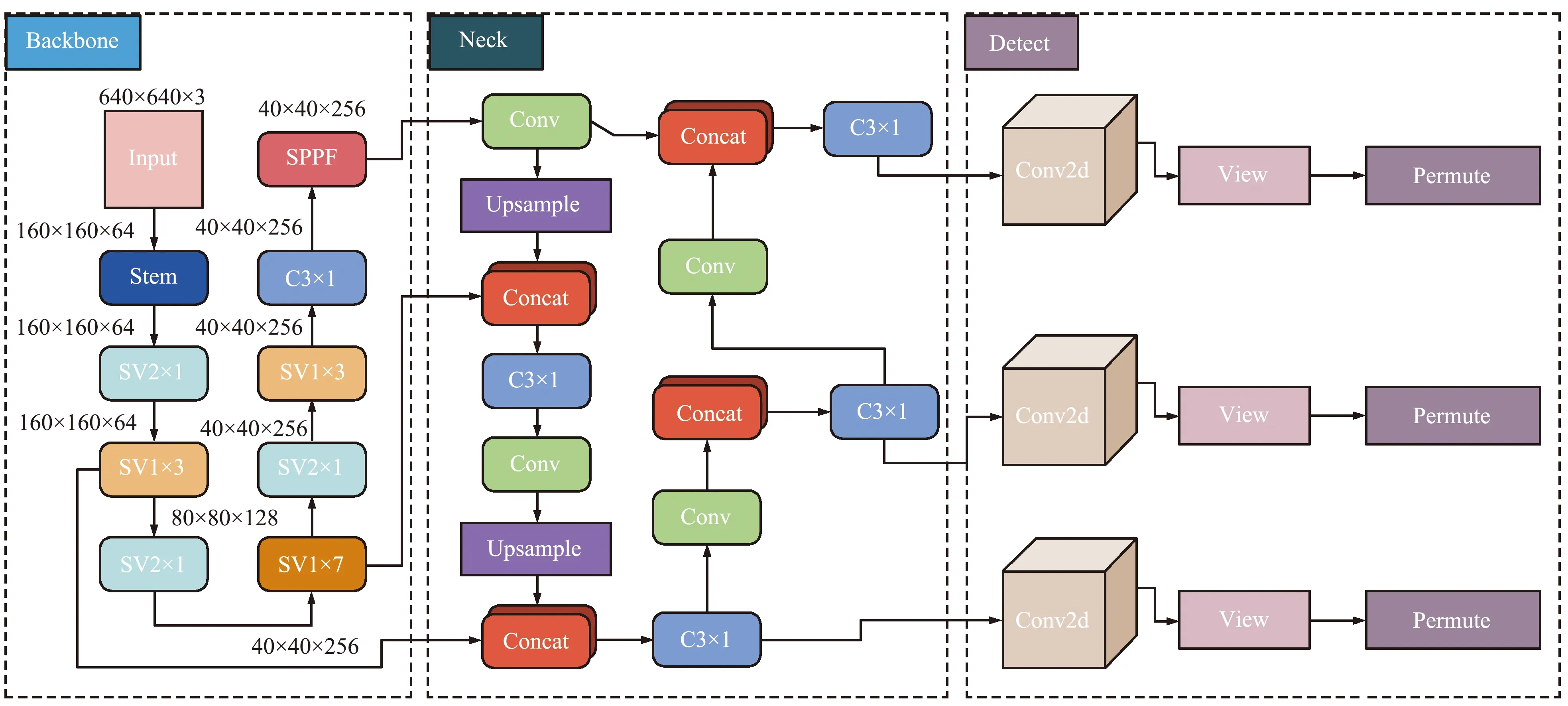
图1 整体网络框架Fig.1 Overall network framework
YOLOv5s-5.0版本的Stem模块是一个Focus切片操作,而YOLOv5s-6.0版本是一个6×6的Conv,本文在此基础上将其改成一个3×3的卷积来降低参数量。大小为640 pixel×640 pixel×3 pixel的RGB图像作为网络的输入,然后通过Stem模块将图像进行特征提取得到160×160×64的特征矩阵,接下来使用了重复堆叠的SV1基本模块与SV2下采样模块对特征矩阵进行了特征提取,分别得到了不同分辨率的特征矩阵。网络在最后一个SV1模块后添加了C3模块,由于此时的采样特征较小,为40×40,执行速度非常快,因此加入该模块基本没有影响模型性能,同时还解决了深度网络的梯度发散问题。为了解决目标多尺度问题从而能够在堆积包裹中更准确地预测,在主干网络轻量化的同时添加了YOLOv5s 6.0中的SPPF模块,结构如图2所示。
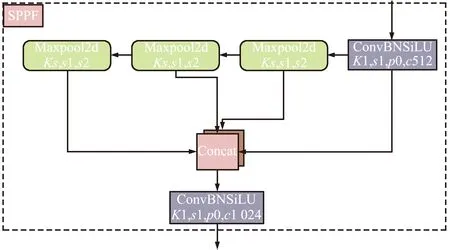
图2 空间金字塔池化模块Fig.2 Spatial pyramid pooling module
从图2可以看出,SPPF结构是将输入串行通过多个卷积核大小5×5的MaxPool层。卷积操作中池化层提取重要信息的操作,可以去除不重要的信息,减少计算开销。最大池化操作相当于核在图像上移动时,筛选出被核覆盖区域的最大值。目的是保留输入的特征,同时把数据量减少,对于整个网路来说,进行计算的参数就变少了,会训练得更快。该模块将任意大小的特征图固定为相同长度的特征向量,传输给全连接层。因为卷积层后面的全连接层的结构是固定的。但在现实中,输入图像尺寸总是不能满足输入要求的大小,然而通常的方法就是通过裁剪和拉伸,但这样做效果总是会有所欠缺,扭曲了原始的特征,如图3所示。

图3 裁剪和拉伸导致的图像失真Fig.3 Image distortion caused by clipping and stretching
SPPF模块通过将候选区的特征图划分为多个网格,然后对每个网格内都做了最大池化,这样依旧可以让后面的全连接层得到固定的输入。通过SPPF解决了深度网络固定输入层尺寸的限制,使得网络可以享受不限制输入尺寸带来的好处,如图4所示。
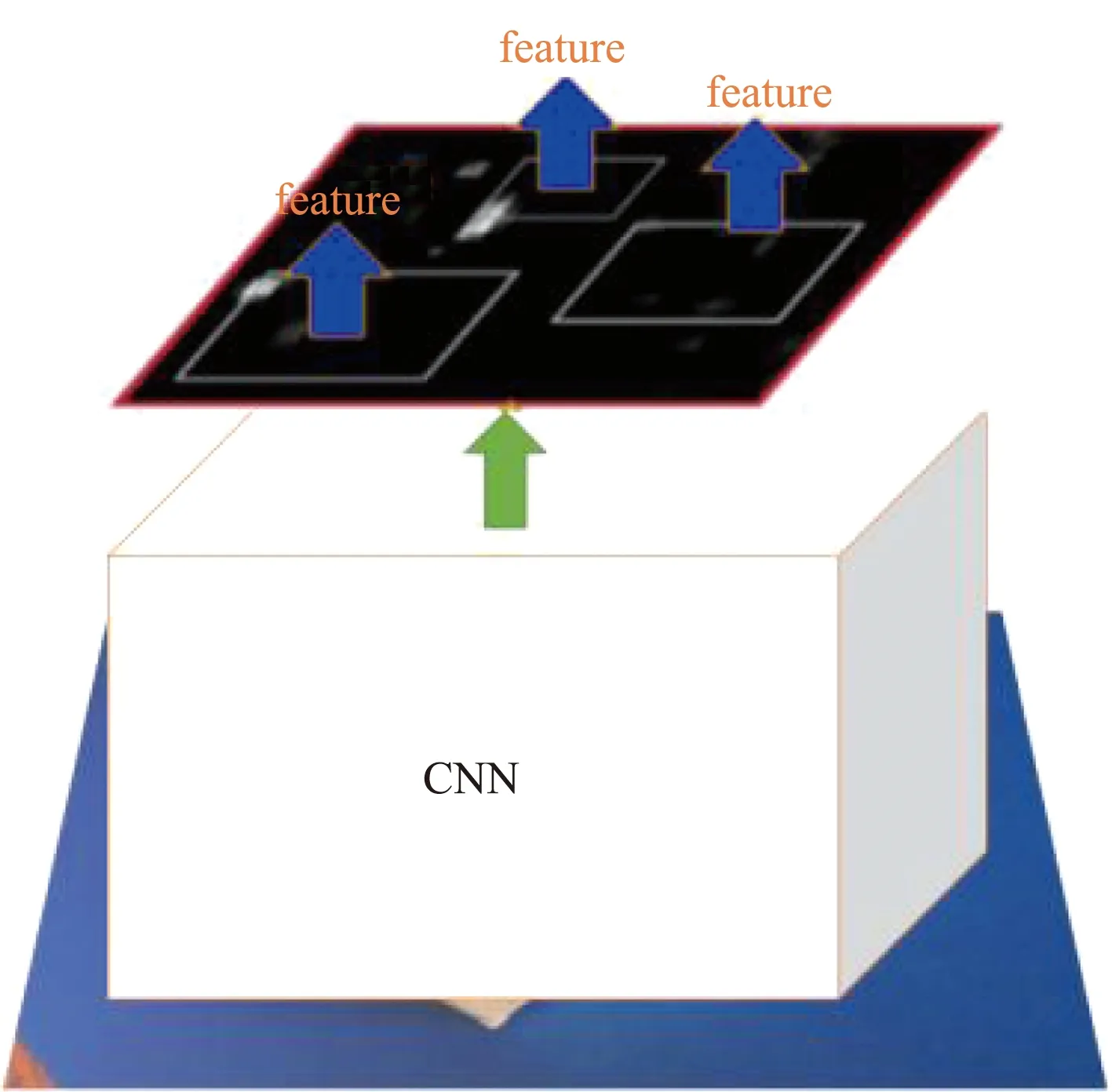
图4 SPPF模块特征提取Fig.4 SPPF module feature extraction
因此,对输入图像的不同纵横比和不同尺寸,SPPF同样可以处理,从而提高了图像的尺度不变性和模型泛化能力。
引入SPPF模块后,模型精度有了进一步的提升,实验结果将在3.3节给出。
1.2 轻量级主干网络
本节将详细介绍主干网络部分。作为轻量级的卷积神经网络,除了要提高模型的速度外,必须同时降低模型的参数量。为此本文的主干网络主要使用融合了SE注意力机制的ShuffleNetV2基本模块和下采样模块,详细结构如图5和图6所示。

图5 轻量级主干网基本模块Fig.5 Lightweight backbone basic module
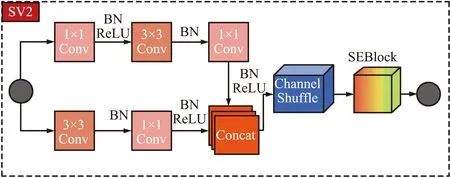
图6 轻量级主干网下采样模块Fig.6 Lightweight backbone down-sampling module
图像通道宽度均衡能够使内存成本(MAC)最小化。对承担大部分计算开销的逐点卷积进行分析,假设输入通道数C1和输出通道数C2通过网络各层时特征图的空间大小为h×w,那么1×1卷积核的计算量(FLOPs)如式(1)所示:
B=hwC1C2。
(1)
内存足够的情况下,其内存消耗如式(2)所示:
MAC=hw(C1+C2)+C1C2。
(2)
则由式(1)可以推导出C2的表达式如式(3)所示:
(3)
在满足式(3)的情况下内存消耗如式(4)所示:
(4)
从式(4)可以看出,当且仅当C1=C2时,MAC有最小值。因此为了得到最轻量化的模型,基本模块与下采样模块的输入输出通道都应该相等。
增加组卷积的同时将使内存访问成本增加,分析组卷积,计算量如式(5)所示:
(5)
式中:g为组数。
由式(2)可得此时的内存消耗,如式(6)所示:
(6)
假设固定输入hwC1和计算量B,则MAC又可以推导为式(7):
(7)
观察式(7)可以发现,若组数g增加,内存量MAC也会随之增大。
网络碎片化操作将会降低并行度,若采用Inception网络那样的“多路”结构,即一个网络块中有多个卷积或池化操作,很容易造成网络碎片化,从而运行速度变慢,并行度降低。元素级操作也是不可忽略的,如ReLU函数和Add操作,即使运算量较小,也会带来较大的内存损耗。
本文设计的轻量级主干网络结构如表1所示。
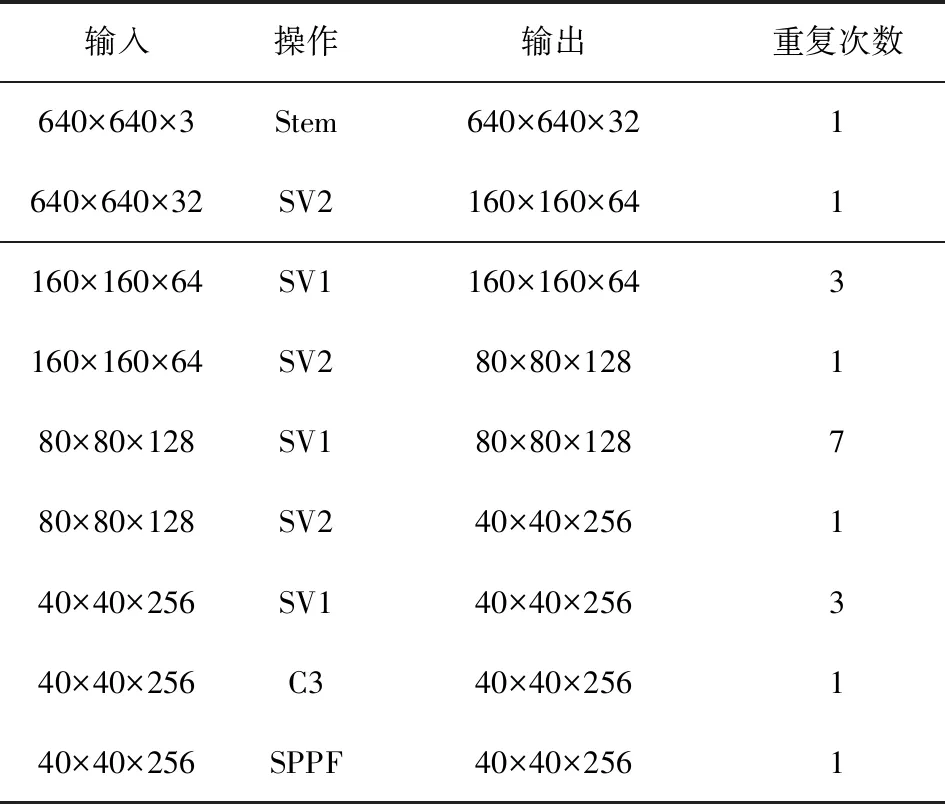
表1 轻量级主干网络Tab.1 Lightweight backbone network
由表1可以看出,本文设计的轻量级网络第一层是一个使用了3×3卷积的Stem模块,为了降低参数量,将通道层设计为32。中间使用的SV1为基本模块,SV2为下采样模块。虽然其中几个模块还有重复次数设置,但每个模块都有着较好的性能,计算量并没有过多的增加。
1.3 损失函数
本文所使用的损失函数Loss由分类损失Lc、定位损失Lb和置信度损失Lo组成,如式(8)所示。为了实现损失函数权重的平衡,引入了3个不同系数,其中系数α设置为1,系数γ设置为1,由于正样本定位直接影响到目标预测的准确率,系数β设置为4。
Loss=α×Lc+β×Lb+γ×Lo。
(8)
分类损失Lc和置信度损失Lo使用了二元交叉熵损失函数(BCE with Logits Loss),如式(9)所示:
(9)
式中:x表示训练过程中所预测的包裹核心区域,y表示标签值,a表示预测的概率值,n表示样本总量。
采用CIoU损失函数计算正样本的定位损失,在IoU的基础上引入长宽比因子,如式(10)和式(11)所示:
式中:A为真实框,B为预测框,d为预测框和真实框中心点的距离,c为最小外接矩形的对角线距离,v为长宽比的相似性因子,如式(12)所示。
(12)
式中:Wb、Hb为真实框的宽和高,Wp、Hp为预测框的宽和高。
2 数据集
由于开源包裹破损数据集较少,因此本文使用自建的包裹破损数据集,总共标注了2 104张图片,其中1 169张图片作为训练集,935张图片作为测试集,其中包括不同数据特征的包裹,如单个完整包裹、单个破损包裹以及多个堆积包裹。单个包裹样例如图7所示,第一行为单个破损包裹与完整包裹图片,第二行为经过神经网络模型推理后的包裹图片。
多个堆积包裹样例如图8所示,第一行为多个包裹堆积图片,第二行为经过神经网络模型推理后的堆积包裹图片。
数据集详细划分如表2所示。
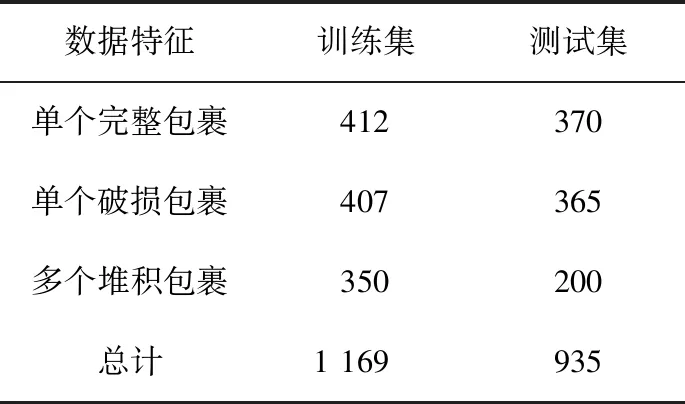
表2 数据集划分Tab.2 Dataset partitioning
3 实验结果与分析
3.1 实验平台部署
本文实验所使用的是PyTorch深度学习框架,在Ubuntu 20.04操作系统下进行。训练以及测试所使用的硬件设备如表3所示。

表3 硬件平台Tab.3 Hardware platform 单位:GB
本文在消融实验和对比实验中,在数据集上做了300个epoch的微调训练,其余参数配置将在3.2节做简要描述。
3.2 实验设计与参数设置
为了验证本文提出的包裹破损检测算法的有效性与真实性,选用了当前较为流行的轻量级主干网络模型进行对比试验。其中有将主干网络替换为MobileNetV3[22]的YOLOv5s_MV3,相较于MobileNetV1[23]和MobileNetV2[24],该版本加入了神经网络架构搜索和h-swish激活函数,并引入了SE通道注意力机制,在性能和速度上表现优异;还有将主干网络替换为GhostNet[25]的YOLOv5s_GN,该模型首先通过在卷积部分使用少量卷积核进行卷积操作减少计算量,接着使用3×3的卷积核进行逐通道卷积操作,进一步降低了模型的复杂度;以及将主干网络替换为ShuffleNetV2的YOLOv5s_SV2,与ShuffleNetV1[26]相比,该版本既没有密集的卷积,也没有太多的分组,实现了较高的模型容量和效率。
训练中的超参数设置如表4所示。

表4 超参数配置Tab.4 Hyperparameters configuration
为了丰富数据集的多样性,减少GPU运算时的显存消耗,本文使用的数据增强过程如下:
① 首先随机抽取4张图片。
② 分别对4张图片进行数据增广操作,如随机翻转、随机缩放和色域变化等,系数如表5所示。
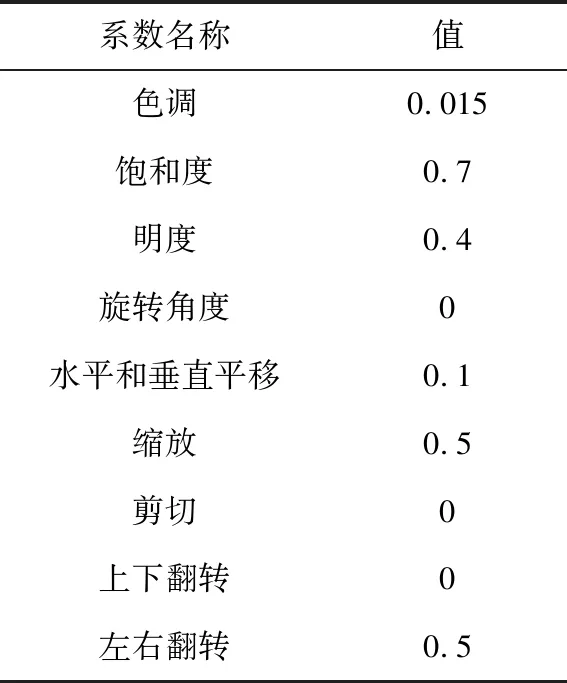
表5 数据增强系数Tab.5 Data augmentation coefficient
③ 进行图片的组合和选框的组合,完成4张图片的摆放之后,利用矩阵的方式将4张图片固定的区域截取,然后进行拼接,得到一张新的图片,如图9所示。
3.3 结果对比与分析
本文的实验结果使用了3种指标来评价模型:
① 针对神经网络模型的复杂度评价,以浮点运算次数(Floating point Operations,FLOPs)来衡量模型的复杂度,其数值越小表示模型的复杂度越低,更加轻量化。
② 针对神经网络模型的精度评价,以平均精度(mean Average Precision,mAP)来衡量模型的检测精度,其数值越高表示预测准确率越高。
③ 针对神经网络模型的速度评价,以每秒传输帧数(Frames Per Second,FPS)来衡量模型的识别速度,其数值越高表示预测速度越快。
不同算法的实验结果,如表6所示。

表6 不同算法的实验结果对比Tab.6 Comparison of experimental results of different algorithms
由表6可以得到以下结论:
① 对比开源框架,使用轻量级网络作为主干网络能够大大降低模型的计算量,模型速度也得到了提升,但精度有所下降。
② 表中FPS最高的YOLOv5s_SV2与开源框架相比,速度提升了近173%,但mAP却下降了26.7%。YOLOv5s_MV3模型与开源框架相比,速度提升了36.3%,同时mAP下降了10%。
③ YOLOv5s_GN框架则只是模型复杂度有所下降,精度指标mAP和速度指标FPS都没有提高,反而出现了下降。
④ 以上数据表明,YOLOv5s_SV2模型的速度最快,如果能够继续改进算法将mAP提高到80%以上,前景非常可观。
为此,本文进行了大量的消融实验来提高YOLOv5s_SV2的精度,实验数据如表7所示。

表7 轻量级主干网络消融实验对比Tab.7 Comparison of lightweight backbone network ablation experiments
表7第一行是表示本次实验对开源YOLOv5s算法的复现结果,以此作为基准线,可以得到以下结论:
① 融合了SE注意力机制的YOLOv5s_SV2框架在数据集上精度有所提升,提升了3.5%,效果并不是特别明显,速度下降了约8.3%。验证了通道注意力机制能够在轻量级网络中提高检测精度。
② 结合SPPF模块的YOLOv5s_SV2框架在数据集上精度有了较大的提升,提升了19.7%,速度下降了21.5%。验证了SPPF模块丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,因此对检测精度有很大的提升。
③ 同时融合SE注意力机制与结合SPPF模块可以在模型精度和性能之间做一个折中,相对于开源YOLOv5s算法,速度提升了约105.7%,模型复杂度下降了约84.2%,精度仅下降了2.8%,验证了本文所设计轻量级网络的有效性。
3.4 算法在不同类型包裹数据上的性能对比
使用YOLOv5s_SV2算法分别在单个包裹和多个堆积包裹以及单个完整包裹和单个破损包裹的数据集上单独进行对比实验,不同数据集的实验结果如表8所示。
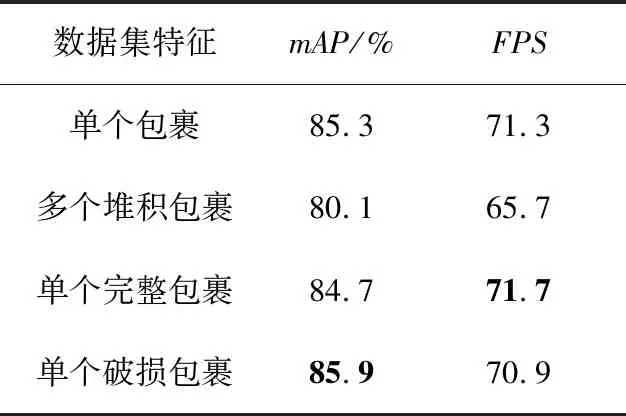
表8 本文算法在不同数据集上的性能对比Tab.8 Performance comparison of the proposed algorithm on different datasets
由表8可以得到以下结论:
① 对比单个包裹图片与多个堆积包裹图片的数据集,前者在本文算法上的检测精度较高,达到了85.3%,推理速度较快,达到了71.3帧/秒。由于多个堆积包裹图片的检测目标较多,数据集在算法上的检测精度和推理速度虽然略微有所下降,但仍有着较高的数据值,具有可靠性。
② 对比单个完整包裹图片与单个破损包裹图片的数据集,前者在算法上的推理速度更快,达到了71.7帧/秒,后者在算法上的检测精度更高,达到了85.9%,二者的实验结果数值相差并不大。
③ 根据对4种不同数据特征的包裹数据集进行实验,得到的结果均有着较高的检测精度与检测速度,验证了本文所提出的算法能够准确识别多种不同数据特征的包裹图片,兼顾了推理速度与检测精度,在实际包裹破损检测场景中,符合轻量化模型这一需求。
4 结束语
本文提出了一种新的自然场景包裹破损检测框架,并在模型主干网络部分融合了通道注意力机制,其中SPPF模块能将有效特征更精确地覆盖到目标区域,在突出目标特征的同时能抑制无关的背景噪声。在数据集上的实验结果表明,本文所提方法对多种不同破损程度的包裹图像检测精度可达 82.7%,模型泛化能力较好,且相比于目前先进的算法在FPS指标上有一定的提升,证明了方法的有效性。此外,为了促进对目标检测识别领域的研究,接下来将考虑把模型应用于其他检测场景下进行研究,从而给予更多科研人员以参考。
猜你喜欢
军事文摘(2024年2期)2024-01-10 01:58:34
广东教育·高中(2022年1期)2022-03-16 23:19:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
心肺血管病杂志(2020年3期)2021-01-14 00:42:12
心肺血管病杂志(2019年6期)2019-07-12 09:04:30
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
