
基于语义的模糊关键词排序可搜索加密方案
2023-11-10 06:04黄保华赵统雷素梅林云杰
广西大学学报(自然科学版) 2023年5期
黄保华, 赵统, 雷素梅, 林云杰
(1.广西大学计算机与电子信息学院, 广西南宁530004;2.广西南宁市西乡塘区审计局, 广西南宁530001)
0 引言
在云计算环境中,大量的数据需要存储和共享,其中往往包含敏感信息。为了保护敏感信息,数据所有者需要在云端存储之前对数据进行加密,可搜索加密(searchable encryption,SE)是一种加密技术,能够在数据加密的同时保持数据的搜索和查询功能,该技术现已广泛应用于个人隐私数据分享和信息检索等场景。近些年,许多学者在该领域实现了多种方案,包括单关键词搜索[1-4]、多关键词搜索[5-11]、模糊关键词搜索[12]和连接关键词搜索[13]等方案。Song等[1]构造了第一个可实际运用的可搜索加密方案,该方案对文档中每个关键词都进行加密,需要检索的时候提交关键词陷门,服务器对密文文档中每个加密关键词进行顺序扫描,若陷门匹配到关键词,则将该文档返回。Goh[2]提出了可抵抗关键词语义攻击的安全索引,该方案基于布隆过滤器和伪随机函数,在进行搜索时可以直接进行索引匹配,但是检索效率取决于原始文档的大小。此后,Curtmola等[3]提出了一种关键词搜索方案,该方案在索引结构上采取倒排索引的方式,这种结构在检索文档的时候无需线性扫描,可直接根据关键词返回文档。Wang等[4]针对之前方案对数据文件相关性的忽视,通过利用现有的密码基元、保序对称加密给出一种排序关键词搜索方案,但该方案是在文档返回时对文档进行排序。Cao等[5]基于文献[14-15],提出一种隐私保护多关键词排名搜索方案。该方案选择坐标匹配以捕获数据文档与搜索查询的相关性,并进一步使用内积相似性来定量评估这种相似度。Xia等[6]结合向量空间模型和词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)模型,能够动态处理文档的删除和插入的同时实现多关键词排序查询,但方案无法抵御已知背景下的统计攻击。基于聚类技术,Zhu等[7]提出一种排序搜索方法,对搜索准确率有一定的提升。Dai等[8]提出了一种基于隐私保护的多关键词排序搜索方案,方案对高相关性关键词进行分组,并使用完整的二叉树结构对索引进行优化,并采用贪婪深度优先算法来提高搜索效率。Miao等[9]提出了一种基于机器学习的关键词排序搜索方案,该方案利用k均值聚类算法和平衡二叉树,在不牺牲准确性的情况下降低了搜索复杂性。庞晓琼等[10]提出一种基于区块链的支持验证与公平支付的多关键词排序检索方案,支持动态更新,并通过云服务器存储加密索引树和执行搜索操作。Wang等[11]提出一种基于二叉树的可验证对称可搜索加密方案,该方案满足了客户端对服务器返回结果的可验证性,并通过树索引平衡了存储和搜索的性能。
以上可搜索加密方案多基于关键词对文档进行评估,从而返回相应的检索结果。例如文献[5-6,10]都基于该领域常用的TF-IDF模型来实现对文档的排序可搜索加密,并通过安全内积计算的结果来评估关键词与文档的相关度。这类方案忽视了关键词中所蕴含的语义特征,也没有对关键词和文档的隐含语义特征进行结合,搜索结果与用户实际期望的内容存在一定的偏差,导致搜索返回的结果很难满足用户真正的需求。另外,这些模型在实现检索时以关键词字典中的词总数作为总维度,在文档集合到达一定量级后在构建索引和执行搜索时均产生巨大开销,即使采用树形的索引结构也会产生大量的输入、输出次数,从而降低搜索效率,因此需要采用更高效的索引结构来降低安全索引的规模。
考虑到传统可搜索加密方案存在的不足,也有部分学者开始从语义的层面上对文档进行分析并应用于可搜索加密领域中。语义是指语言或符号系统中词汇、短语、句子等表示的意义或含义,在可搜索加密技术中它代表方案中关键词之间的关系、文档中上下文的理解以及用户在执行搜索过程时所表达的真实意图。在基于语义的可搜索加密方案研究上,Xia等[16]基于同义词扩展提出多关键词可搜索加密方案,但方案需要构建语义关系库,会带来额外的开销。基于层次聚类,Chen等[17]提出了一种多语义可搜索加密方案,但该方案以文档为单位进行散列,其准确率和开销都存在问题。Fu等[18]提出了一种基于概念层次结构和加密数据集中概念之间语义关系的语义搜索方案,但在数据类型上存在局限性并且定义的标签规模过大。潜在狄利克雷分配(latent Dirichlet allocation, LDA)主题模型是一种得到广泛应用的主题模型,由Blei等[19]于2003年提出。该模型基于Dirichlet分布和Gibbs采样,能够计算出文档集中每篇文档的主题概率分布和每个主题的关键词概率分布,该模型作为一种语义模型在语义分析和文本挖掘中得到了广泛的应用。Dai等[20]使用语义模型分析潜在语义,实现了一种隐私持久性可搜索加密方案,但其索引规模仍较大。而后Dai等[21]结合LDA主题模型和查询似然模型又提出一种隐私保护的可搜索加密方案,利用主题信息进行关键词抽取,并通过似然模型来提高搜索的准确性。Xue等[22]在Dai的基础上使用短文本主题建模并在索引结构上采用两级安全索引,优化了索引结构规模。Zhou等[23]在基于LDA主题模型的基础上实现语义搜索的同时使用分裂层次聚类算法构建一种新型的树形索引,并提出一种深度优先的隐私保护多关键词搜索算法,提高了搜索效率。
尽管当前从语义层面上进行分析的可搜索加密方案[20-23]已经取得了一定的进展,但这些方案仅考虑了在一般情况下的应用,并没有考虑到用户在输入关键词时可能会出现拼写错误等情况。当用户的输入出现错误时很难返回预期的搜索结果,因此这些方案在模糊场景下的应用还存在着不足。总而言之,针对传统可搜索加密方案中存在的忽略语义与索引规模过大的问题,以及当前基于语义的可搜索加密方案对输入错误的低容忍性,本文中提出了一个基于语义的模糊关键词排序可搜索加密方案(latent dirichlet allocation fuzzy multi-keyword ranked searchable encryption, LDA-FMRSE),该方案采用 LDA 主题模型建模,并采用多级安全索引,通过倒排索引结构克服了其他索引结构存在的不足,在实现模糊搜索的同时能够高效地返回排序搜索结果,并在实现多关键词模糊搜索的同时无需预先定义词典,在搜索时仅需对主题进行一轮计算。经过实验测试表明,该方案能在保证一定准确率的情况下高效实现对关键词的模糊搜索。
1 预备知识
1.1 对偶编码函数
在可搜索加密方案中,安全索引和安全陷门以及搜索过程都以向量的形式进行运算,而关键词以字符的形式存在,因此需要将关键词采用某种方式向量化。
定义1给定字符串S=C1,C2,…,Cn,向量V∈{0}m, 其中n 布隆过滤器(Bloom filter)由Bloom[24]在1970年提出,用来测试一个元素是否在一个集合里。布隆过滤器是一个由m位组成的位数组,所有这些位最初都设置为0。给定一个集合S={a1,a2,…,an},布隆过滤器通过k个独立散列函数,将预插入元素进行散列后将布隆过滤器对应位置均设置为1,完成对预插入元素的插入过程。若要确认某元素是否存在于布隆过滤器中,只需要通过散列后查询其对应位置是否都为1,若其中任意对应位置为0,则该元素一定不存在于布隆过滤器中。否则该元素存在于布隆过滤器中或产生一个假阳性误报。m位Bloom过滤器的误报率ρ约为 (1) 局部性敏感哈希(locality sensitive hashing, LSH)主要运用于高维海量数据的快速近似查找,可以实现高维度的数据降维,将一个k维的向量降低至l维。给定一个距离度量d,LSH函数可以将相近的项散列至相同的散列值,其概率大于相距较远的项。 定义2如果任意两点s,t∈{0,1}k和h∈H满足: d(s,t)≤r1:Pr[h(s)=h(t)]≥p1, (2) d(s,t)≥r2:Pr[h(s)=h(t)]≤p2, (3) 则称哈希函数族H(r1,r2,p1,p2)是敏感的,其中d(s,t)是点s与点t之间的距离,因此当原始距离d(s,t)很小时,映射后的距离也小,则在字符输入错误不大的情况下即使出现输入错误也容易映射在邻近的位置,构成了实现模糊检索的前提。在本文的方案中使用p-stable的LSH家族[25]。p-stable LSH函数的形式为 (4) 式中:a是k维向量;v是向量;b、w分别为实数,且b∈[0,w],h(a,b)(v):{0,1}k→{0,1}l。 安全KNN技术(securek-nearest neighbor,SkNN)是密文检索中防止信息泄露的同时进行安全内积计算,达到保护隐私目的的一种加密算法。具体加密过程如下: 为了实现原向量的拆分,首先需要随机生成一个m维向量S,S∈{0,1}m。随后根据以下规则将m维的索引向量I和搜索向量Q进行拆分:若S[i]=1,则I[i]=I′[i]+I″[i],其中I′[i]和I″[i]分别为I[i]的一半再各加减一个随机数r;若S[i]=0,则I[i]=I′[i]=I″[i]。与之类似,Q也进行如上拆分得到Q′、Q″。再随机生成m维可逆矩阵M1、M2,将I和Q拆分所生成向量与M1、M2进行运算得到I和Q的加密拆分向量{M1TI′、M2TI″}和{M1-1Q′、M2-1Q″},对安全内积的计算式为 =I′Q′+I″Q″=IQ。 (5) TF-IDF模型是一种基于词袋的模型,通过关键词的词频(TF)和逆文档频率(IDF)表示文档之间相关度,即通过TF值T与IDF值I的乘积表示相关度的得分。T和I的计算公式为 (6) 式中:Nd,wi指关键词wi在文档d中的出现次数;Nd表示文档d中所包含词语的总数目;Nwi表示文档集合D中所包含关键词wi的文档个数;a表示文档集的数目。由TF-IDF的定义可知,它实际上是以文档间共现词的数量和共现词的重要程度来衡量文档之间的相关度,仅考虑了同一关键词在不同文档中的情况,而忽略了不同词语之间往往也存在着潜在语义特征,从而产生语义缺失的问题。 TF-IDF模型进行文档搜索时为每个文档构建一个m维的索引向量,其中m为文档集所包含的所有关键词的个数,若该文档包含某一关键词,则该文档索引向量中该关键词那一维的值即为该关键词的TF值,若不包含则将该维的值设置为0,搜索向量也做类似的处理,区别是搜索向量存储的是对应关键词的IDF值。搜索时基于每个文档对应的索引向量和搜索关键词对应的搜索向量进行安全内积计算获得其相关度得分,然后将相关度得分最大的前k个文档返回作为搜索结果。该方案以文档为单位构造索引,索引维度取决于关键词的数量,随着关键词数量的增多,索引的维度也在增多,从而产生巨大的索引空间开销。 本文中的方案系统模型如图1所示。方案中涉及3个实体:数据拥有者、数据使用者和云服务器。 图1 方案系统模型Fig.1 Scheme system model 数据拥有者是一个可信实体,因为它拥有并提供明文数据。该实体使用预加密文档集D作为输入进行主题建模,并生成对应的文档-主题矩阵和主题-关键词矩阵。接着该实体使用对偶编码函数将关键词向量化,并通过局部敏感哈希和布隆过滤器构建一级安全主题索引。该实体还使用文档-主题矩阵生成倒排索引,并将索引进行加密以生成二级安全倒排索引。此外,数据拥有者需要选择其他可信实体并向其发送安全陷门。最后,数据拥有者使用加密算法对预上传的文档集进行加密,然后将加密文档集和安全索引上传到云服务器。 数据使用者是获取数据拥有者授权的可信实体。该可信实体能够接收由数据拥有者发送的安全陷门和相关密钥,当需要进行搜索操作时,根据搜索需求使用安全陷门生成搜索请求,然后发送至云服务器,并要求云服务器返回符合搜索请求的前k个文档。在云服务器返回所需密文文档集后,数据使用者使用密钥对密文文档集进行解密,从而获取所需明文文档集。 云服务器主要负责存储数据拥有者所上传的加密数据和加密索引,并对来自数据拥有者和可信实体的搜索请求进行响应。 在本文提出的方案中,云服务器模型为诚实且好奇模型,在方案执行的过程中,云服务器将忠实地执行方案中的步骤,但在执行方案步骤的过程中也会尽可能地获取用户数据中的隐私信息。本文中的方案需要满足的功能实现和安全特性如下: ①构建多级安全索引。数据拥有者需要利用LDA主题模型对原始文档集进行训练,构建一级安全主题索引和二级安全倒排索引,以满足用户在云服务器上的查询需求。多级索引进行加密处理,保证其安全性。 ②云服务器数据安全性。在将原始文档集上传至云服务器上,存储前数据拥有者应先对于明文状态的原始文档集进行加密处理,保证原始文档集在云服务器端的安全性。 ③安全陷门的安全性。数据拥有者在将安全陷门授权给数据使用者进行搜索时,即使在云服务器端,也不应能获取任何与关键词和索引相关的信息,保证安全陷门的安全性。 本文中方案的安全性定义采用文献[3]的定义,通过定义泄露函数来定义在本文方案执行中具体泄露的信息,通过敌手和可信实体,模拟器之间的交互性游戏来证明本文中的方案不泄露除泄露函数之外的其他信息。 定义3RealS1(K)为真实实验,其全过程均采用真实的方案算法,其中S1为模拟器,K为密钥,实验在执行密钥初始化算法后,根据敌手在该阶段所挑战的内容,使用本文方案中的真实算法生成对应的内容,并将生成的内容以密文的形式保存,实验最后输出一个比特b作为实验返回结果。 定义4IdealS2(K)为模拟实验,该实验中并不进行任何真实的方案算法运行,而是将真实算法方案中云服务器所能获取的信息作为输入生成随机数据,其中S2为模拟器,K为密钥,将生成的随机数据保存为密文信息,实验最后输出一个比特b′作为实验返回结果。 定义5若存在任意的模拟器,使得任意敌手都无法对上述2个实验所生成的密文信息进行区分,也就是说,敌手没有在多项式时间内以不可忽略的优势对交互对象进行分辨,则称该方案满足选择关键词安全性。 定义6选择明文攻击(chosen plaintext attack, CPA)在该攻击模型中,敌手除了知道加密算法外,还可以选定明文信息获得对应的密文,但是不能得知密钥的相关信息。 定义7CPA安全:若在选择明文攻击模型下,敌手无法获取更多额外的信息,则称该方案满足CPA安全。 给定一个基于语义的模糊关键词排序可搜索加密方案,A为敌手,S1、S2分别为2个模拟器。在密文生成阶段、多级安全索引生成阶段、陷门生成阶段中,令真实实验RealS1(K)的泄露函数为L1、L2、L3,其为2个实验互相共享的信息。基于语义的模糊关键词排序可搜索加密方案的安全性以敌手和挑战者之间的攻击游戏来定义。 密文挑战分为以下3个阶段: ①初始阶段:在这个阶段挑战者使用密钥初始化算法,密钥K为输出结果。 ②挑战阶段:在这个阶段由敌手A选择明文信息,将其发送给挑战者,然后挑战者使用密钥K完成真实实验RealS1(K)将明文信息加密,该执行阶段的泄露函数为L1,然后通过L1所包含的信息完成模拟实验IdealS2(K),最终从2个实验中随机选取一个结果b‴作为给敌手的返回值。 ③猜测阶段:敌手输出b″作为对结果b‴的猜测。 若完成上述游戏后,对任意敌手A,均存在一个模拟器S,使 (7) 式中p(K)是以K为输入的多项式,则基于语义的模糊关键词排序可搜索加密方案在选择明文攻击模型下是安全的。 构建安全陷门挑战分为以下3个阶段: ①初始阶段:在这个阶段挑战者使用密钥初始化算法,密钥K为输出结果。 ②挑战阶段:敌手A选择搜索关键词Q进行挑战。将关键词Q发送给挑战者,挑战者通过密钥K完成真实实验RealS1(K)生成安全陷门,该阶段实验的泄露函数为L1、L2。然后通过L1、L2所包含的信息完成模拟实验IdealS2(K),最终从2个实验中随机选取一个结果b‴作为给敌手的返回值。 ③猜测阶段:敌手输出b″作为对结果b‴的猜测。 两级安全索引挑战分为以下3个阶段: ①初始阶段:在这个阶段挑战者使用密钥初始化算法,密钥K为输出结果。 ②挑战阶段:敌手A选择安全主题索引进行挑战,挑战者接收该索引对应的泄露函数L1、L2、L3并使用密钥K进行真实实验RealS1(K),生成一级安全主题索引,再通过泄露函数L1完成模拟实验IdealS2(K)。最终从2个实验中随机选取一个结果b‴作为给敌手的返回值。 ③猜测阶段:敌手输出b″作为对结果b‴的猜测。 如果敌手猜出b‴的值的概率是可忽略的,则说明本文方案中多级安全索引构建方案和陷门生成的方案是选择关键词攻击安全的。 本文中提出的LDA-FMRSE主要包括8种算法:LDA-Train、GenKey、BuildIdxI、BuildIdxII、EncryptDocument、TrapDoor、SearchDocument和DecrypDocument。数据拥有者执行LDA-Train、GenKey、BuildIndexI、BuildIndexII、EncryptDocument算法,获得检索许可的数据使用者执行TrapDoor和DecrypDocument算法,而云服务器执行SearchDocument算法。 ①LDA-Train为文件主题模型训练算法。数据拥有者通过使用LDA主题模型对初始文档集进行训练,通过不同主题数目下困惑度的变化趋势确定主题数目,得到文档集的主题-关键词的概率分布矩阵Θ和文档-主题的概率分布矩阵Φ。 ②GenKey为数据拥有者执行的密钥生成算法。用户通过输入安全参数完成密钥的初始化,输出对称加密算法的密钥K1、K2,并随机生成m×m维的可逆矩阵M1、M2和一个随机生成的m维向量S(用于实现安全KNN算法),m为布隆过滤器的位数。算法步骤描述如下: 算法1:GenKey(1λ)→K 输入:安全参数λ和布隆过滤器的位数m 输出:密钥集合K={K1,K2,M1,M2,S} 步骤1:通过安全参数λ生成对称加密算法的密钥K1、K2。 步骤2:随机生成m×m维可逆矩阵M1、M2。 步骤3:随机生成一个m维向量S,S∈{0,1}m。 步骤4:得到密钥集合K={K1,K2,M1,M2,S}。 ③BuildIdxI为一级安全主题索引构建算法。该算法生成对应的m位主题布隆过滤器,根据主题-关键词的概率分布矩阵Θ获取主题的个数T和主题与关键词之间的对应关系,对应主题的每个关键词在经过波特词干提取算法处理后,通过对偶编码向量化。然后选取l个局部敏感哈希函数,进行散列处理后插入布隆过滤器,完成一级安全主题索引的构建。算法步骤描述如下: 算法2:BuildIdxI(T,Θ,M1,M2,S) →I1 输入:主题个数T,关键词的概率分布矩阵Θ,可逆矩阵M1、M2和随机向量S 输出:一级主题索引I1 步骤1:以主题个数T创建T个m位的布隆过滤器。 步骤2:从关键词的概率分布矩阵中抽取对应主题的关键词集合。 步骤3:将对应主题关键词集合中的关键词通过对偶编码向量化。 步骤4:选取l个局部敏感哈希将每个主题下的关键词进行散列插入对应主题布隆过滤器中。 步骤5:对得到的主题布隆过滤器通过安全KNN算法得到一级安全主题索引I1。 ④BuildIndexⅡ为二级安全倒排索引构建算法。该算法基于LDA-Train算法中生成的文档-主题的概率分布矩阵Φ,文档与主题的相关度由概率分布矩阵中的概率分布决定,并以此完成对主题-文档倒排索引的构建,然后使用对称加密算法的密钥K2对倒排索引进行加密生成主题-文档二级安全倒排索引,算法步骤描述如下: 算法3:BuildIdxⅡ(T,Φ,K2)→I2 输入:一级安全主题索引I1, 文档-主题概率分布矩阵Φ, 对称加密算法密钥K2 输出:二级安全索引I2 步骤1:根据文档-主题概率分布矩阵Φ中文档对应主题的概率分布大小对文档进行排序。 步骤2:生成倒排索引I2。 步骤3:使用对称加密算法密钥K2对倒排索引I2进行加密得到二级安全索引I2。 ⑤EncryptDocument为文件加密算法。数据拥有者基于对称加密算法对明文状态下的原始文档集进行加密处理生成密文文档集。算法步骤描述如下: 算法4:EncryptDocument(K1,D)→D′ 输入:对称加密算法密钥K1和明文文档集合D 输出:密文文档集合D′ 步骤1:使用对称加密算法密钥K1加密明文文档集合D。 步骤2:得到密文文档集合D′。 ⑥TrapDoor为陷门构建算法。用户通过陷门构建一个m位的布隆过滤器,将查询关键词经过波特词干提取算法后进行对偶编码向量化并使用l个局部敏感哈希散列插入布隆过滤器,然后将该陷门发送至云服务器。算法步骤描述如下: 算法5:TrapDoor(Q,M1、M2,S) →t 输入:关键词集合Q,随机可逆矩阵M1、M2和随机向量S 输出:安全陷门t 步骤1:创建一个m位的布隆过滤器。 步骤2:输入搜索关键词集合。 步骤3:将搜索关键词集合中的关键词通过对偶编码向量化。 步骤4:选取l个局部敏感哈希将每个搜索关键词进行散列插入布隆过滤器中。 步骤5:对布隆过滤器通过KNN算法得到安全陷门t。 ⑦SearchDocument为云服务器检索算法。通过用户对关键词使用陷门构造算法提交的安全陷门对一级安全索引进行安全内积计算,确认所属主题,然后将该主题下符合条件的前k个文件作为返回结果发送至用户。算法步骤描述如下: 算法6:SearchDocument(I1,I2,t,k,B)→D″ 输入:安全索引I1、I2,安全陷门t,要求返回的前k个文档 输出:加密文档集合D″ 步骤1:服务器先将用户提交的安全陷门对一级安全索引进行内积计算。 步骤2:根据安全内积的大小选择最大的一个为对应主题。 步骤3:查询该一级安全主题索引对应的二级倒排索引,返回符合要求的前k个文档。 步骤4:得到返回的加密文档集合D″。 ⑧DecrypDocument为用户解密算法。用户收到服务器返回的密文文档后使用对称加密算法对文件进行解密处理获取明文文档。 本文中提出的基于语义的模糊关键词排序可搜索加密方案对于返回结果的正确性分析包括精确关键词搜索分析和模糊关键字搜索分析,具体分析如下: ①针对关键词无拼写错误,即精确关键词的情况下,由于关键词在散列过程中均使用l个相同的哈希函数,因此在索引向量和搜索向量中相同关键词的散列位置都是相同的且为1,在执行搜索操作的安全内积计算时能够得到最大的安全内积值,从而得到搜索关键词在一级安全主题索引中所确认的主题,然后查询二级安全倒排索引返回满足条件的文档集合。 ②针对关键词出现拼写错误,即模糊关键词的情况下,若正确的关键词为w,输入的模糊关键词为w′。当w和w′的相似度较大且差异在一定范围内,即d(w,w′)≤r,其中r为局部敏感哈希函数的距离阈值,由局部敏感哈希函数的定义可知,若对于l个局部敏感哈希函数存在hi(w)=hi(w′),此时的情况与①中相同,将精确地返回最大的安全内积值,确认主题并返回文档集合。 而当d(w,w′)≤r且hi(w)≠hi(w′)时,此时产生哈希失误,从而降低安全内积计算结果。在d(w,w′)≤r时,两者之间发生哈希失误的概率R为 (8) 式中:j为发生哈希失误的次数;p为局部敏感哈希函数中的参数,通常调整为接近1的数,且发生哈希失误的概率会随着j的增大而减少。 而当d(w,w′)>r,说明模糊关键词与原关键词区别过大,则局部敏感哈希将其散列到相同的位置概率会非常低。 综上所述,本文方案能够以较高的概率得到较高的安全内积计算结果,从而确认关键词所属的主题并返回预期结果。 在基于服务器诚实且好奇的情况下,给出本文提出方案的安全性证明。将方案执行中产生泄露函数的步骤以敌手和用户模拟器之间的交互游戏的方式进行描述,若敌手在步骤交互中无法获取更多的相关信息,则本文提出方案的安全性得到证明。 方案的执行过程会泄露信息的步骤有生成密文阶段,生成多级安全索引阶段以及生成陷门阶段,在这3个过程中,定义3个泄露函数来描述这些过程中这2个实验所共享的信息。以下为泄露形式化定义: 主题集合T每个主题对应的唯一标识标记为ti,主题数量为|T|,文件集合F每个文件对应的唯一标识标记为fi,各阶段泄露函数所共享的信息如下: ①生成密文阶段。 密文文档C为原文档F进行加密所得到,密文大小为|C|,模拟实验IdealS2(K)可以得到真实实验RealS1(K)的相关信息包括C、|C|、ti,将以上信息记为L1 L1=(|T|,ti,C,|C|)。 (9) ②生成陷门阶段。 在生成搜索陷门过程中,模拟实验IdealS2(K)可以获取真实实验RealS1(K)所执行的关键词集合Q中的每一个元素qi,将信息记为L2 L2=(Q,qi)。 (10) ③多级安全索引阶段。 模拟实验IdealS2(K)可以获取真实实验RealS1(K)中关键词集合Q中每一个元素qi是否存在于主题ti中,将这些信息记为L3。 定理1在生成密文阶段、生成多级安全索引阶段、生成安全陷门阶段中的安全性满足CPA安全的,则本文提出的方案在随机预言机模型下满足受到自适应选择关键词攻击的安全性。 定理1表明,若以上泄露函数不泄露更多相关信息的情况下,本文提出方案在预言机模型下是安全的。 证明在整个方案执行的3个阶段中,构造一个执行多项式时间算法的模拟器与敌手进行交互,在该过程中,模拟器在执行真实实验RealS1(K)和模拟实验IdealS2(K)的情况下,敌手在多项式时间内能对收到的结果进行区分的概率是可忽略的。 ①生成密文阶段。 初始阶段:挑战者执行算法GenKey(1λ),输出密钥K。 挑战阶段:敌手选择明文信息F作为挑战对象,将F发送给挑战者,由挑战者执行真实实验RealS1(K)和模拟实验IdealS2(K)。 真实实验RealS1(K):对明文信息集F={f1,f2,…,fi}执行EncryptDocument(fi)算法得到密文信息集D′={D1′,D2′,…,Di′}随机输出Di′(其中0 随机生成参数b∈{0,1}若b=0,将Di′发送给敌手;若b=1,将Di″发送给敌手。 猜测阶段:敌手对b进行猜测,将输出结果记为b″。 密文加密采用CPA安全的加密方案,因此任何多项式敌手都无法对2个实验所输出的值进行区分,那么敌手获胜的概率是可忽略的。 ②生成陷门阶段。 初始阶段:挑战者执行算法GenKey(1λ),输出密钥K=(K1,K2,M1,M2,S),M1、M2分别为随机m维可逆矩阵,S∈{0,1}m。 真实实验RealS1(K):挑战者输入关键词Q,执行算法TrapDoor(Q,M1,M2,S),输出真实陷门值t。 模拟实验IdealS2(K):根据泄露函数L1、L2,根据以下步骤生成模拟安全陷门t′。 ②执行TrapDoor(Q′,M1′,M2′,S′),输出模拟陷门t′。 随机生成参数b∈{0,1},若b=0,将t发送给敌手;若b=1,将t′发送给敌手。 猜测阶段:敌手对b进行猜测,将输出结果记为b″。 由于查询关键词的加密算法和密钥K都具有伪随机性,因此任何多项式敌手都无法对2个实验所输出的值进行区分,那么敌手获胜的概率是可忽略的。 ③生成多级安全索引阶段。 初始阶段:挑战者执行算法GenKey(1λ),输出K=(K1,K2,M1,M2,S),M1、M2为随机m维可逆矩阵,S∈{0,1}m。 挑战阶段:敌手选择包含关键词W的一级安全主题索引进行挑战。将该索引发送给挑战者,挑战者执行真实实验RealS1(K)和模拟实验IdealS2(K)。 真实实验RealS1(K):挑战者输入关键词W,执行算法BuildIdxI(T,W,M1,M2,S),输出真实的一级安全索引I1。 模拟实验IdealS2(K):根据泄露函数L1、L2、L3得到的信息按以下步骤生成模拟一级安全索引I1′。 步骤1:初始化w个空向量Wti。 步骤2:任意qi∈Q,若qi在ti中,则通过对偶编码将qi′向量化为vi′,令Wtj′=Wtj′+v′,其中1≤j≤w。 步骤3:令向量Wtj′中所有大于1的元素均为1。 步骤4:执行BuildIdxI(T,W,M1,M2,S),输出一级安全索引的模拟值I1′。 随机生成参数b∈{0,1},若b=0,将I1发送给敌手;若b=1,将I1′发送给敌手。 猜测阶段:敌手对b进行猜测,将输出结果记为b″。 由于安全索引I1的生成算法和密钥K都具备伪随机性,而安全索引I2采用CPA安全的对称加密方案,因此任何多项式敌手都无法对2个实验所输出的值进行区分,那么敌手获胜的概率是可忽略的。 在以上3个阶段中,对任意多项式敌手来说,都无法对实验RealS1(K)和实验IdealS2(K)的输出进行区分,即存在可忽略概率negl(k),使得 Pr[RealS1(K)=1]-Pr[IdealS2(K)=1]≤negl(k), (11) 式中:K为算法GenKey(1λ)生成的密钥;k是安全参数;negl(k)表示概率可忽略。综上,本文中提出的基于语义的模糊关键词排序可搜索加密方案在随机预言机模型下满足自适应选择关键词攻击安全。 为了对本文方案进行验证,将本文方案与基于TF-IDF模型的方案进行对比。实验硬件环境为一台处理器为IntelCore(TM)I7-9700,内存为16 GB的台式电脑。开发环境为Pycharm,方案使用Python语言实现。 实验中从p-stable的LSH家族中选取的LSH函数,个数为10,一级安全主题索引和搜索陷门的长度m均为8 000。使用测试数据集为从20newsgroups标准数据集中随机选择的1 000篇文档。该数据集是国际标准数据集,常常被用于文本分类、文本挖掘和信息检索研究。其中文档长短不一,语言为英文,适合完成对关键词的向量化处理。该数据集包含20个不同的新闻类别,其中的文档与主题之间具备语义相关性,符合实验的需要。 主题数目的选取直接影响到关键词和主题之间的语义关系,确认主题个数主要通过困惑度[19]进行判断,困惑度越低,说明主题文本分类越清晰。困惑度的计算方式为 (12) 式中:D为语料库文档集;M为文档集的大小;p(wd)表示文档关键词wd的出现概率。不同主题数目的困惑度变化趋势如图2所示。由图2可见,困惑度的变化在主题数目大于13后呈上升趋势,故选取13作为总文档集的主题数目。 图2 不同主题数目的困惑度变化趋势Fig.2 Trend of perplexity with different number of topics 本文对语义准确率的描述采取文献[22]的方式,首先假设用户每次构造的安全陷门中所有的关键词都属于同一主题, 并且不同主题的文档不存在相关性。若以一个确定主题下的词语作为关键词,且返回的文档也属于同一主题,则视为正确返回结果,故将用户检索得到的文档的语义准确率使用查准率P来衡量,计算方法如下: (13) 式中:nTP为返回的文档中满足用户检索意图的文档数目;nFP为不满足用户检索意图的文档数目,实验选取了属于同一主题下的5个单词作为搜索关键词,同时在不同的总文档数目下分别执行了20次搜索,其中选用的搜索关键词不尽相同。通过这个实验,评估了本文方案在关键词字符输入不存在错误的情况(latent dirichlet allocation multi-keyword ranked searchable encryption, LDA-MRSE)、其中一个搜索关键词输入出现一个字符错误的情况(LDA-FMRSE)和传统的(term frequency inverse document frequency-multi-keyword ranked searchable encryption, TFIDF-MRSE)方案3种状况下返回符合要求的前50个文档的检索准确率。不同总文档数目下,各方案的语义准确率变化趋势如图3所示。 图3 不同总文档数目下各方案的语义准确率变化趋势Fig.3 Trend in semantic accuracy of schemes with different total document numbers 实验结果表明,随着总文档数目的增大,本文方案的语义准确率始终高于采取TF-IDF模型的搜索方案。基于TF-IDF的方案在返回文档时仅能考虑到搜索关键词与存在该搜索关键词的文档之间的关系。而本文方案考虑了关键词之间的潜在语义特征,对文档整体进行语义分析,因此具备更高的语义准确率。本文方案语义准确率的主要影响因素是局部敏感哈希函数在关键词散列时所产生的精度损失,从而导致搜索时未能确定正确的主题,否则语义准确率还将进一步上升。本文方案在主题模型训练时通过对关键词使用波特词干提取算法将同一关键词的不同词性进行归并,从而减少了一部分的精度损失,但即使在存在精度损失的情况下,本文的方案相比TF-IDF模型的搜索方案仍然具备更高的语义准确率,具备更好的表现。 对本文方案与基于TF-IDF模型的方案在搜索阶段的时间开销进行分析,所有实验结果均为运行10次算法后的平均值。 在搜索执行时间方面,在不同总文档数目下,本文方案与TFIDF-MRSE方案的搜索时间进行对比,不同文档总数目下各方案搜索时间变化趋势如图4所示。本文方案在总文档数为1 000的情况下,采用不同关键词个数和使用不同LSH个数执行搜索时搜索时间变化趋势如图5。 图4 不同文档总数目下各方案搜索时间变化趋势Fig.4 Trends in search times for schemes with different document totals 图5 不同关键词数目下各方案搜索时间变化趋势Fig.5 Search time trends for schemes with different numbers of keywords 从图4可见,本文方案的搜索时间远少于基于TF-IDF的搜索方案,主要原因是基于TF-IDF的方案以文档为单位构建索引向量,在执行搜索过程中带来大量的安全内积计算次数,其索引向量和搜索向量的维数为总文档集的所有关键词个数,规模随着总文档集文档数目增大而增大,从而导致搜索时间消耗的增大。而本文方案的搜索时间虽然也随总文档集文档数目的增大呈线性关系,但增长速度明显低于基于TF-IDF的搜索方案。 从图5可见,关键词的个数和使用LSH的个数对本文方案的搜索执行时间基本没有影响,因为关键词和LSH主要被应用于构建一级安全主题索引和安全陷门,本文方案在构造安全陷门时将所有输入的关键词进行散列后插入在到一个布隆过滤器内与安全主题索引进行安全内积计算,此时的计算次数仅与主题数目有关。而主题的数目远远小于文档集中的文档数目,并且索引向量和搜索向量的维数不随总文档集文档数目的增大而增大,故相比基于TF-IDF的搜索方案具有更低的搜索开销。 在可搜索加密方案中,其检索效率主要由索引构造方案决定,索引构造方案影响索引的规模以及搜索的时间复杂度。将本文提出的方案与其他密文检索方案进行对比,不同方案理论比较结果见表1,其中,W为以文档为单位进行匹配时的关键词数量,w为文档内关键词集中后的数量,f为Bloom过滤器的大小,g为文档集中所包含的文档总数,h为安全陷门匹配到的关键词数量,q为文档集经过训练所确定的主题个数,φ为训练得到的每个文档的主题分布,在通常情况下q≪g,h≪w。 表1 不同方案理论比较结果Tab.1 Theoretical comparison of different solutions 从表1可见,与传统的线性索引相比,平衡二叉树索引的检索效率是最高的。不论是线性索引或是以文档为索引单位使用二叉树建立索引,其检索效率都取决于文档的个数,而本文通过将文档进行主题建模并采用多级索引,将文档与关键词分隔开,检索的效率仅取决于主题的个数,由于主题的个数远小于文档个数,因此有效保证了搜索的效率。 随着可搜索加密技术的不断发展,基于TF-IDF模型的传统排序可搜索加密方案忽视用户检索语义意图,因此已经无法满足用户的检索需求。本文在保证云服务器上文档的安全性的基础上,提出了一种基于语义的模糊关键词排序可搜索加密方案,在实现相关语义检索的同时支持关键词的模糊搜索。该方案引入主题模型,从语义上分析使用者的潜在搜索意图,利用主题模型对原始文档进行训练,解决了传统方案中对语义的忽视问题,通过构造关键词与主题之间的相关性,对传统方案中检索关键词与文档之间的关联性进行替换,针对现有语义检索方案不支持模糊查询的限制,使用局部敏感哈希和布隆过滤器技术实现了基于语义的模糊关键词排序搜索。方案构建多级安全索引,实现关键词与具体文档的分离,进一步提升了隐私保护效果。与以文档为单位建立索引的传统方案相比,本文方案在检索效率上也有所提升。未来研究将进一步优化索引结构和提高语义精确度,以进一步提升检索效率和查询准确率。1.2 布隆过滤器

1.3 局部性敏感哈希

1.4 安全KNN技术
1.5 TF-IDF模型
2 系统模型与问题描述
2.1 系统模型

2.2 问题描述
2.3 安全性定义
3 方案构造与分析
3.1 具体构造及主要算法
3.2 方案正确性分析
3.3 方案安全性证明

4 实验分析
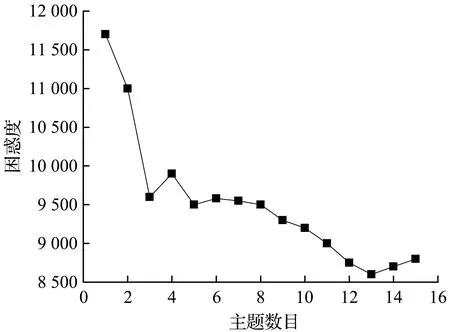
4.1 主题数目选取
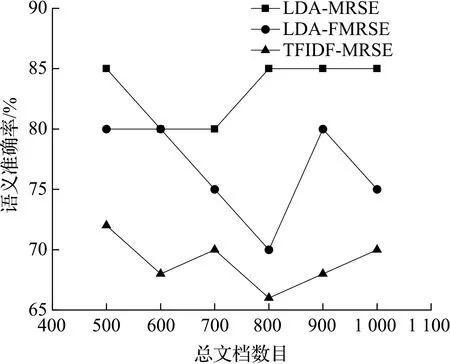
4.2 语义准确率
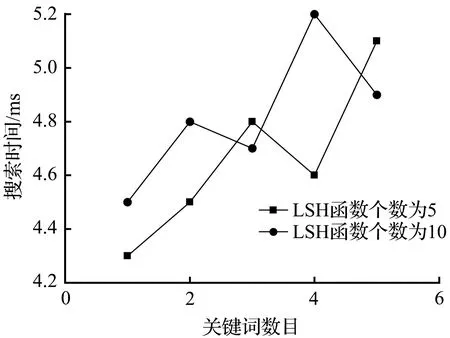
4.3 时间效率

4.4 方案性能

5 结论
猜你喜欢
客联(2022年3期)2022-05-31中国新闻周刊(2021年26期)2021-07-27太原科技大学学报(2019年3期)2019-08-05阅读与作文(小学高年级版)(2019年2期)2019-03-27信息安全研究(2016年4期)2016-12-01信息安全研究(2016年10期)2016-02-28电子设计工程(2015年17期)2015-02-27华东师范大学学报(自然科学版)(2014年1期)2014-04-16作文与考试·高中版(2008年12期)2008-07-01
