
基于动态集成选择算法的信用卡审批异常检测
2023-11-09 09:57:12程建华庞梦兰
合肥学院学报(综合版) 2023年5期
程建华,庞梦兰
(安徽大学大数据与统计学院,合肥 230601)
随着中国经济的快速发展,信用卡市场规模也得到快速增长。截至2021年末,中国的信用卡发行量已达8亿张。随着交易次数的增加,利用信用卡进行欺诈行为不断增多。尽管欺诈行为在整个信用卡交易中的比例很低,但一旦发生,将会给各商业银行造成巨额经济损失。据中国银行业协会发布的《中国银行卡产业发展蓝皮书(2022)》数据显示,截至2021 年末,信用卡逾期半年未偿信贷总额达860.4 亿元,较上年增加2.6%。鉴于此,如何迅速、有效识别信用卡欺诈行为以防范风险,已成为银行风险控制领域的研究课题。
信用卡欺诈检测领域存在两个主要问题:首先,实际生活中,欺诈样本的数据标签获取困难,人工标记数据成本较高,而且已标记的样本数据量不足以反映真实的欺诈状况,在大多数情况下,商业银行面临的是没有标签的数据集;其次,信用卡交易数据存在类别极端不平衡的现象,即欺诈样本远小于正常样本。鉴于此,针对数据集中标签缺失的情况,本文通过挖掘客户特征中的潜在信息,对潜在风险较高的申请发出预警,识别“异常客户”,旨在从授信审批方面把好关,以此降低欺诈风险。
1 文献综述
国外在信用卡欺诈检测方面起步较早,早期的检测方法主要采用传统的统计分析方法。20 世纪90年代以来,学者们开始探索基于数据挖掘的信用卡欺诈检测方法,如决策树、神经网络、支持向量机等。随着人工智能技术的发展,一些学者将深度学习技术应用到信用卡欺诈检测领域:Jurgovsky 等[1]将欺诈检测问题转化为序列分类任务,使用长短期记忆神经网络进行预测,从而有效提高检测准确率;Fiore等[2]训练生成对抗网络(Generative Adversarial Networks,GAN)模型,利用该模型生成欺诈类样本,将这些样本与原始数据集合并,从而构建一种有效的欺诈检测机制。目前的欺诈检测研究大多是基于有监督的机器学习模型,但数据标签很难获取,而且已标记的数据样本量有限,无法反映出真实的欺诈情况,此外,信用卡交易类别的分布不平衡,给信用卡欺诈检测带来了挑战。
在数据样本仅包含特征而没有标签的情况下,异常检测可以通过对数据样本特征的分析揭示样本间的内在规律,以发现与一般行为或模式有显著差异的少数样本。[3]由于极难获得欺诈交易的标签,部分学者把欺诈样本视为异常点,并通过异常检测技术将其与正常样本分离。Van 等[4]利用无监督异常检测技术识别医疗保险索赔的欺诈样本,实验结果表明,通过异常检测技术可以检测出潜在的新型欺诈模式。Porwal 等[5]采用基于聚类的集成方法来获得每个数据样本的异常分数,这种方法可以检测出大型数据集中的异常样本,并且能够对不断变化的欺诈模式具有较强的稳健性。采用无监督的异常检测方法识别欺诈样本更具有实际意义和价值,有效地解决了标签缺失的问题,此外还可以发现新的欺诈模式。
目前,处理不平衡数据的方法可以归纳为两类:一类是从数据层面通过欠采样或过采样的方法调整样本类别分布,另一类是以代价敏感学习和集成学习为代表的算法层面的处理方式[6]。基于单个机器学习分类算法进行不平衡数据的分类预测可能会导致一定的偏差,而集成学习将多样性、互相补充的多个基分类器融合成一个强分类器,利用该强分类器对不平衡数据进行分类,可以有效提升模型的准确率和稳定性。近年来,越来越多学者将Bagging、Boosting 等集成学习方法应用于不平衡数据集,李秀芳等[7]利用Bagging集成技术进行保险欺诈识别;卢冰洁等[8]将多个集成模型运用于车险欺诈识别;胡忠义等[9]通过K 均值聚类将样本划分为多个区域,在每个区域上进行多分类器集成,进行P2P 借贷样本的违约风险评估,这些研究结果都表明,集成模型在处理不平衡数据时比单个模型更有优势。
集成学习已被广泛应用于欺诈识别,但传统的集成学习采用的是静态集成,即构建一个基分类器集合,将所有分类器进行集成,而不同分类器对于不同待测样本的分类性能不尽相同,因此需要根据不同待测样本的特征来选择合适的分类器组进行集成,动态选择(Dynamic Selection,DS)正逐渐成为多分类器系统的一个研究热点,原理是并非基分类器集合中的每个分类器都是分类所有待测样本的专家,而是每个分类器是特定特征空间上的专家。[10]动态集成选择(Dynamic Ensemble Selection,DES)通过评估每个分类器在不同特征空间的分类能力,为待测样本选择最佳的分类器组进行集成。Wang 等[11]在无监督学习的框架下,提出了一种自适应的K近邻算法,基于一类分类器构建动态集成异常检测模型,实验结果表明其具有比单个模型和各种静态集成模型更优的检测性能。刘子华等[12]提出了基于动态能力区域策略的DES-DCR-CIER 算法,并将其应用于乳腺肿块诊断,实验结果表明相比于其他16 种算法,基于DESDCR-CIER 的诊断模型具有最优的综合性能。越来越多的研究结果表明,相较于传统的集成方式,动态集成选择技术具有更加优越的性能。DES首先针对大量的基分类器进行训练,然后动态地从训练集中选择样本组成待测样本的能力区域(Competence Region,CR),接着根据评价标准基于CR 评估各个分类器的性能,最后从中选择一组最优的分类器进行集成。其中,评价标准通常为分类准确率,但在数据集标签缺失的情况下,这一评价标准失效,从而无法使用动态集成选择算法。
本文提出一种以无监督异常检测算法为基分类器,融合无监督学习和动态集成选择的异常检测模型DES-HBOS,首先采用基于直方图的异常检测方法生成基分类器集合,根据异常得分集合构造训练集客户的伪标签,然后确定待测客户能力区域,使用Pearson 相关系数评估所有分类器的分类能力,最后选择一组较优的分类器进行集成,将其应用于信用卡授信审批异常检测。
2 动态集成选择
动态集成选择主要包括以下3个步骤:
(1)构建基分类器集合。目前,DES算法中生成基分类器的方法可以分为两类:同构分类器生成和异构分类器生成。[13]同构分类器生成是由同一学习算法得到的,根据数据集的划分方式不同可以分为2种:训练样本集的随机选取,例如Bagging;待选特征的随机选取,例如随机子空间和特征选择;此外,还可以通过调整分类器的参数得到不同的分类器,同构分类器通过调整数据集或参数来增加分类器的多样性。而异构分类器生成是由不同的学习算法应用于整个数据集得到的。
(2)对不同待测样本选择对应的最优分类器组。此阶段主要包括2 个步骤:1)确定待测样本的能力区域,假定CR内的样本与待测样本的特征有较高的相似度[14],即从训练集中选择一组与待测样本特征相似的样本,现有经典的DES 算法大多采用K 近邻算法来确定待测样本的CR,如KNORA(K-Nearest Oracles)、DES-KNN(Dynamic Ensemble Selection based on K-Nearest Neighbor)等;2)根据某一评价标准基于CR 评估分类器的性能,即采用CR 代表待测样本对分类器集合中的分类器进行性能评估,主要评价标准为分类准确率,分类准确率越高代表分类性能越好,说明分类器是该特征空间上的专家,将该分类器应用于与CR 特征相似的待测样本,如KNORA 算法选择至少能正确预测待测样本的CR 中一个样本的分类器,通过这种方式为待测样本选择最优的分类器组。
(3)分类器集成。将选择的分类器组进行集成,主要包括平均法、动态加权法等,其中多数经典的DES算法的集成方式为多数投票法,即采用多数分类器的投票结果。
3 基于动态集成选择算法的异常检测
信用卡欺诈风险主要是指信用卡持有者有目的的办理信用卡,并在信用卡办理成功后蓄意消费透支,并在还款日到来之前更改预留手机号等信息,出现拒不还款等状况,造成商业银行经济损失[15]。针对这一风险,商业银行主要是根据客户的特征信息建立风险防控模型,对其是否有可能进行欺诈行为作出评估,从授信审批入手,发现异常客户,以达到将欺诈风险降至最低。
本文设计的基于动态集成选择算法的信用卡审批异常检测模型DES-HBOS 主要包括以下四个部分:构造客户伪标签、确定能力区域、分类器性能评估、分类器集成,如图1所示。
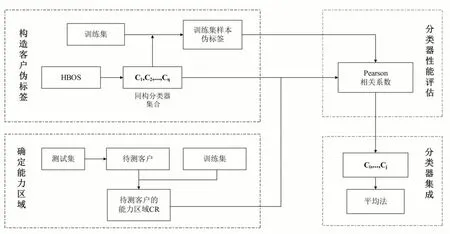
图1 DES-HBOS模型整体结构图
3.1 构造客户伪标签
3.1.1 HBOS模型
直方图方法(Histogram-based Outlier Score,HBOS)是Goldstein 等[16]提出的一种基于非参数统计的无监督异常检测算法,不依赖超参数,避免了超参数选择不当导致的偏差;基于特征间独立性的假设,该方法将对高维数据的处理拆解为多个单特征的计算,在互联网背景下,客户特征日益增多,对数据处理提出更高要求,而直方图方法对高维数据有较好的适应性,其快速计算的性能使得其对海量高维数据的处理非常高效。因此,本文采用HBOS作为识别异常客户的方法,其模型表达式如下
HBOS为每个特征构建单变量直方图,并将其标准化使得直方图最大高度为1,每个箱子的高度代表概率密度估计,概率密度大致呈“钟形曲线”,概率密度越低,则客户的这一特征值偏离大多数客户,异常得分越高。直方图可以反映出所有客户某一特征的分布情况,概率密度越小的特征值,越有可能异常,最终通过客户的所有特征综合判断异常情况。
3.1.2 生成伪标签
本文采用同构分类器生成的方式构造基分类器集合,以HBOS 为学习算法,改变参数即箱的个数得到一系列不同的基分类器,参数为10~50 之间的随机整数,构成基分类器集合C={C1,C2,...,Cη}。表示训练集表示待测集,其中每个客户有m个特征。所有基分类器在同一训练集下进行训练,得到训练集Xtrain的异常得分矩阵S(Xtrain),即
其中:Cj(Xtrain)(j=1,2,...,η)表示第个分类器在训练集上的异常得分向量,且经过标准化处理;表示训练集中第个客户在第个分类器下的异常得分。
本文通过平均所有分类器的输出结果来对训练集中的客户进行标记,训练集中客户的伪标签可表示为
3.2 确定能力区域
确定待测客户的能力区域CR。从训练集中选择与待测客户特征相似的客户构成CR,具有相似特征的客户有相似的行为趋势。一般地,“近朱者赤,近墨者黑”,传统的K 近邻算法(K-Nearest Neighbor,KNN)被用来判断相似性,采用欧式距离度量客户特征的相似程度,距离越近越相似。
Zhao 等[17]改进传统的KNN 算法,缓解了维数灾难问题,相比于聚类算法有更高的精确度,将待测客户xα的能力区域CRα定义为:
其中:Xtrain表示训练集:knnα表示与待测客户xα特征相似的客户集合。
通过以下步骤确定knnα。首先,为特征个数,随机构造组新的特征空间,维数在;其次在每组特征空间下,使用欧氏距离度量待测客户xα在训练集中的个最近邻客户,得到组个最“相似”客户;最后,出现次数超过t2的“相似”客户构成集合knnα。
3.3 分类器性能评估
不同分类器对于待测客户的分类能力有所差别,动态集成中的“动态”是指进行集成的分类器组不是固定的,CR内的客户与待测客户的特征相似,采用CR代表待测客户对所有分类器进行性能评估,找到最适合待测客户的分类器组。通过动态的方式提高分类器组对待测客户的异常检测能力。
异常得分可以转化为二元变量,再通过分类准确率评估分类器性能。但定义阈值很有挑战,使用相似度评估分类器的异常检测能力使结果更加稳定。本文采用Pearson相关系数进行相似度评估。对于待测客户xα,确定其在训练集中的“相似”客户集CRα,根据target(Xtrain)得到CRα的伪标签target(CRα),将分类器Cj(j=1,2,...,η)在CRα上的标准化异常得分表示为Cj(CRα),计算target(CRα)与Cj(CRα)的Pearson相关系数ρα,j,如下:
其中:Cov为协方差函数;Starget表示target(CRα)的标准差;表示Cj(CRa)的标准差。
使用ρα,j评估各分类器在CRα上的异常检测能力,具有最大ρα,j的分类器Cj被认为是CRα上性能最好的分类器。
3.4 分类器集成
在缺少训练集标签的情况下,仅选择一个分类器的风险较高,通过集成的方式为待测客户选择一组分类器,可以降低单个分类器过拟合的风险,使检测结果更加可信。集成方式主要包括平均法、动态加权法等,其中最经典的集成方法是多数投票法,即采用多数分类器的投票结果。
类似于多数投票法,对于某一待测客户,基于CR 对所有分类器的异常检测能力进行评估得到Pearson 相关系数,将其绘制成具有等间隔的直方图,选取频率最高的间隔内的分类器作为分类器组,平均这组检测器的异常得分得到该待测客户的异常得分,异常得分越高,风险系数越大。将待测客户的异常得分降序排序,设定一个异常比例,排名靠前的待测客户被认为是异常的,系统将发出预警信息。
4 实验结果与分析
4.1 数据描述
本实验的数据集credictcard 是Worldline 和ULB 的机器学习小组在合作大数据挖掘和欺诈行为识别研究期间,对欧洲持卡人2013 年9 月某两天的信用卡客户数据进行收集得到的,来源于Kaggle 网站。在284 807 个客户中,欺诈客户有492 个,占所有客户的0.172%,由于保密问题,原始数据没有提供背景信息,脱敏后的原始数据的客户特征V1,V2,...,V28经过PCA 变换得到,V1,V2,...,V28相互独立,“Acount”为金额,“Class”为样本标签,0 表示正常客户,1 表示欺诈客户。在模型训练的过程中不使用样本标签,“Class”列的数据信息仅用于最终的模型性能评估。
4.2 实验参数设置
实验环境为Windows10-64bit,Intel Core i5 处理器,8GB 运行环境和Python3.8.5 语言,在Jupyter Notebook上实现。
本实验选择基于直方图的方法(Histogram-based Outlier Score,HBOS),K 近邻(K-Nearest Neighbor,KNN),一类支持向量机(One-Class Support Vector Machine,OCSVM),局部异常因子(Local Outlier Factor,LOF),主成分分析(Principal Component Analysis,PCA)、孤立森林(Isolation Forest,IForest)这6 种在异常检测领域应用广泛且效果较优的分类器作对比,算法的重要参数设置如表1 所示,其余参数使用Python3.8的sklearn库中的默认参数。

表1 模型重要参数设置表
本实验采用小批量数据集,前14 个数据集的数据量为20 000,最后一个数据集的数据量为4 807,将每个数据集按照7:3的比例划分为训练集和测试集,随机种子数设置为42。DES-HBOS 的算法参数设定如下:箱的个数n_bins为10~50之间的随机整数,异常比例contamination设定为0.01,经过参数调优过程,确定基分类器数量η为20。
4.3 评价指标
异常检测结果的评价标准:精确率(Precision)、召回率(Recall)、F1以及AUC,这些指标常用于不平衡分类问题的模型评估,值越大,代表模型的分类效果越好。将所有客户根据其真实类别和预测类别划分得到混淆矩阵,如表2所示。

表2 信用卡客户的混淆矩阵
其中:TN表示被正确分类的正常客户;FP表示被错误分类的正常客户;FN表示被错误分类的欺诈客户;TP表示被正确分类的欺诈客户。
具体评价方式如下:
(1)精确率(Precision)表示被正确分类的欺诈客户占所有预测欺诈客户的比例,公式如下
(2)召回率(Recall)表示被正确分类的欺诈客户占所有欺诈客户的比例,公式如下
(3)F1表示精确率和召回率的调和平均值,公式如下
(4)AUC 表示ROC(Receiver Operating Characteristics)曲线下方的面积,介于0 到1,值越接近1,说明模型的分类性能越优。
4.4 消融实验
考虑DES-HBOS 中的基分类器数量η对模型性能的影响,η太大或太小都会影响模型性能,因此本实验将η设置为10,20,30,40,50 进行实验,探究η对模型性能的影响,Recall 和AUC 是DESHBOS在15个测试集上的平均值,绘制折线图如图2所示。通过图2可以看出基分类器数量对模型性能的影响较小,Recall 随η的增加先小幅增加而后降低,AUC 相对稳定,基本在0.95左右波动,主要原因是η=10时,集成分类器数目略少,模型性能较弱,随着η增加,分类器多样性增加,模型性能有所增强,Recall 和AUC 值都有增加,但是η>20 时,Recall 值先保持不变而后下降,AUC 值小幅下降但基本稳定,可能是分类器集合中性能较弱的分类器增加导致模型整体性能下降,但因为DES-HBOS择优选择分类器,所以模型性能相对稳定。
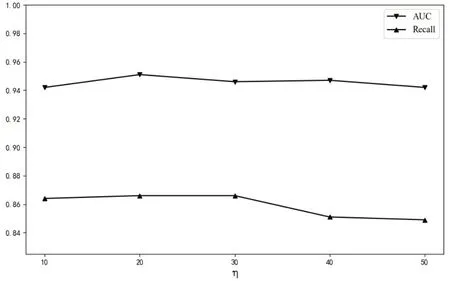
图2 Recall和AUC关于η变化图
当η=20时,模型性能较优,且分类器数量少使得模型运行时间短,因此本实验将η的值设定为20。
4.5 对比实验
本实验使用6 种不同的算法与DES-HBOS 进行对比实验,包括单分类器算法HBOS,KNN,OCSVM,LOF,PCA和静态集成算法IForest。在模型训练过程中,7个模型在15个数据集上都是基于同一测试集进行评估,并将7个模型在15个测试集上的各项指标值进行简单平均,实验结果如表3所示。
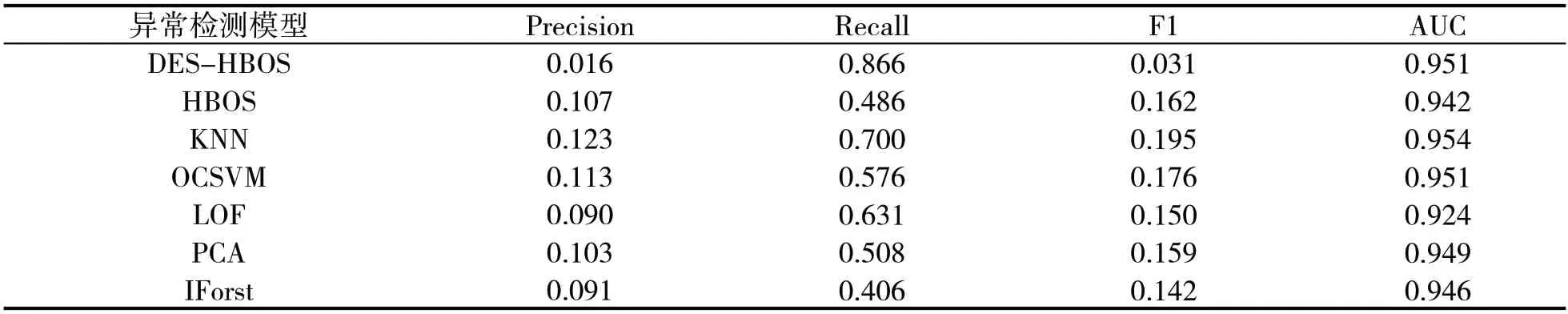
表3 模型对比结果
通过表3 可以发现,DES-HBOS 相比于其他5 种单分类器,Recall 均有较大提升,但Precision 降低即模型的精准度降低。对比5种单分类器算法,KNN的表现最好。对比DES-HBOS、5种单分类器和静态集成的实验结果,可以看出DES-HBOS 和5 种单分类器普遍优于后者,这可能是因为在集成过程中强分类器受到弱分类器的影响,使得静态集成算法不如单分类器算法和DES-HBOS算法。
考虑实际情况,Recall 为商业银行最值得关注的指标,它反映了被检测出来的欺诈客户占欺诈客户的比例,欺诈客户带来的损失成本很高,Recall 的提高可以极大减少损失成本;Precision 降低代表模型将更多正常客户认定为异常客户,导致精准度降低,这种错误只是造成机会成本损失,二者损失不等价,因此Recall的提升能帮助商业银行减少高额损失。
在数据集标签缺失的情况下,本文提出的DES-HBOS 能相对有效地检测信用卡交易中的异常客户,从授信审批方面把好客户准入关,以此降低欺诈风险。此外,这一模型检测出的异常客户需由商业银行的专业人员进行审查,为不同客户群制定差异化的风控策略,通过技术防控和人工防控相结合的方式降低风险,以起到防范预警的作用。
4.6 多个数据集对比实验
4.6.1 数据描述
为了验证DES-HBOS 在不平衡数据集上的通用性,从UCI repository 和KEEL 数据库中选取了4 个公开数据集,下面简单介绍一下这4个数据集。
Breast Cancer Wisconsin(BCW):UCI repository的美国威斯康星州乳腺癌原始数据集,该数据集有699个病例,包括线束厚度、细胞大小、细胞形状、边缘附着力、单个上皮细胞大小、裸核、纯白染色质、正常核苷酸和有丝分裂这9 个特征,类别0 表示良性乳腺肿块,类别1 表示恶性乳腺肿块,恶性乳腺肿块有241例,不平衡率为1.9。
Ecoil:UCI repository的蛋白酶裂解位点预测数据集,该数据集有336条肽链,包括Mcg、Gvh、Lip、Chg、Aac、Alm1和Alm2这7个蛋白质序列特征,类别0表示非裂解位点上下游的氨基酸构成的肽链,反之为类别1,类别1包含77条肽链,不平衡率为3.36。
Vowel0:KEEL的元音识别数据集,有988条数据,包括TT、SpeakerNumber、Sex、F0、F1、F2、...、F9这13个特征,类别0为正样本,类别1为负样本,有90条负样本数据,不平衡率为9.98。
Vehicle0:KEEL 的车型识别数据集,该数据集有846 条数据,包括Compactness、Circularity 等18 个车辆轮廓特征,类别0为非Van类型的车辆,类别1为Van类型的车辆,类别1有199辆,不平衡率为3.25。
4.6.2 实验结果分析
在4 个公开数据集上将DES-HBOS 与HBOS 的异常检测效果进行对比,异常比例设定为0.1,实验结果如表4所示。DES-HBOS的Recall均较高,提升了3.1%~19.4%,能将更多的真实异常点识别出来;然而从Precision 来看,两个模型的精准度较为接近;综合考虑这两个指标可以使用F1,F1 越大代表检测效果越好,DES-HBOS的F1在这4个数据集上均高于HBOS,提升了3.5%~11.8%。综上所述,DES-HBOS的异常检测效果优于HBOS。

表4 多个数据集异常检测结果对比
t-SNE(t-Distributed Stochastic Neighbor Embedding)是Van 等[18]提出的一种数据降维与可视化技术,将高维空间数据通过t-SNE 技术投影到2维或3维空间进行可视化。本实验使用t-SNE 技术将高维空间数据投影至2维平面,图3是DES-HBOS 在数据集BCW 和Vowel0上的异常检测结果,左侧是真实异常点分布情况,右侧是模型检测到的异常点分布情况。数据集BCW 的Precision 为1,模型检测到的异常点均为真实异常点,而Recall 只有0.346,即大部分真实异常点没有被检测出来;数据集Vowel0 的Recall 为0.71,模型将71%的真实异常点都识别出来了,而Precision 只有0.5,即模型检测到的一半异常点是真实异常点。
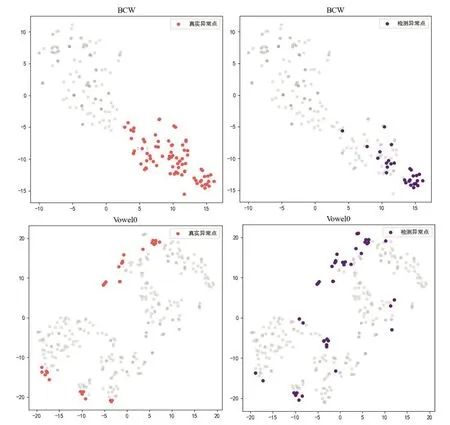
图3 数据集BCW和Vowel0的异常检测结果
对比2个数据集可知,BCW 和Vowel0的真实异常比例分别为34.48%和9.11%,在样本标签缺失的情况下,对数据集本身异常比例的不了解将会对检测结果造成影响,因此在异常检测之前,需要根据经验法则设定模型的异常比例,可以使检测结果更加准确。
5 结语
针对数据集标签缺失且类别分布极不平衡的信用卡欺诈检测问题,本文提出一种基于动态集成选择算法的信用卡审批异常检测模型。为了解决标签缺失问题,利用无监督异常检测算法构造训练集客户的伪标签,并为了缓解类别分布极不平衡的问题,确定待测客户的CR,根据Pearson 相关系数采用CR 代表待测客户对分类器集合中的分类器进行性能评估,将分类性能优的多个分类器融合之后得到一个强分类器。在真实信用卡客户数据集和4个不平衡数据集上进行实验,对比其他模型,DES-HBOS的Recall均有提高,能将更多的真实异常点识别出来。在未来的工作中,可以考虑对待测样本能力区域确定方法进行探究,使得能力区域与待测客户特征更相似,以便找到更优的分类器组。
猜你喜欢
眼科新进展(2023年9期)2023-08-31 07:18:36
眼科新进展(2022年12期)2022-12-29 06:00:50
中国外汇(2019年10期)2019-08-27 01:58:04
电子测试(2018年1期)2018-04-18 11:52:35
瞭望东方周刊(2017年35期)2017-09-22 21:18:36
中国防伪报道(2016年10期)2016-11-21 06:39:00
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
公民与法治(2016年24期)2016-05-17 04:21:39
公民与法治(2016年6期)2016-05-17 04:10:39
